
1. this, this()
this는 자기 자신을 가리키는 참조 변수, this()는 스스로의 인스턴스 생성자이다.
this는 어떤 클래스가 인스턴스화 되었을 때, 생성된 인스턴스가 저장된 메모리 주소를 가리키는 참조 변수이다.
[this의 사용 사례]
- 자기 자신 참조
- 생성자 안에서 다른 생성자를 호출
- 인스턴스 자신의 주소 반환
각 사용사례에 대한 예시를 같이 살펴보자.
- 자기 자신 참조
class Nayeon {
private String name;
private int age;
private String gender;
public Nayeon(String name, int age, String gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
}이렇게 인스턴스의 필드/멤버에 접근할 때에, this를 사용하여 명시적으로 나타낼 수 있다. 이는 해당 필드가 동일한 이름의 다른 변수와 혼동되지 않게 하고, 다른 변수의 이름 역시 가장 직관적인 형태로 유지할 수 있다.
만약 this 키워드가 없다면, 필드 변수와 이름이 겹치지 않도록 함수 인자 변수들의 이름을 변경해주어야 했을 것이다.
// this를 사용하지 않는 경우 코드
class Nayeon {
private String name;
private int age;
private String gender;
public Nayeon(String _name, int _age, String _gender) {
name = _name;
age = _age;
gender = _gender;
}
}- 생성자 안에서 다른 생성자 호출
class Nayeon {
private String name;
private int age;
private String gender;
public Nayeon(String name, int age, String gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
public Nayeon(String name, int age) {
this.name = name;
this.age = age;
}
}Nayeon 클래스의 생성자를 오버로딩 하여 name, age만을 인자로 갖는 생성자를 추가로 정의했다고 해보자. 두 생성자의 로직이 매우 비슷한 것을 확인할 수 있다. 이런 경우 this()를 통해 코드를 더 간결하게 작성할 수 있다.
class Nayeon {
private String name;
private int age;
private String gender;
// 1번 생성자
public Nayeon(String name, int age, String gender) {
// 2번 생성자 호출
this(name, age);
this.gender = gender;
}
// 2번 생성자
public Nayeon(String name, int age) {
this.name = name;
this.age = age;
}
// 3번 생성자
public Nayeon() {
// 1번 생성자 호출
this("nykoh", 24, "female");
}
}위 사례에서 1번 생성자가 2번 생성자를 호출함으로써 더 간결하게 코드를 작성할 수 있다.
또한 3번 생성자가 1번 생성자를 호출한 것처럼, 인자 값이 없거나 일부만 존재하는 경우에 default 값을 지정해줄 수도 있겠다. 매개변수가 없는 생성자의 경우, this() 호출문이 가장 위에 위치해야 한다.
[왜 this() 호출문이 가장 먼저 와야 할까?]
이는 Java 언어 설계에 의한 것이다.
Java는 초기화 시 다른 생성자가 초기에 호출될 수 있도록 하여 어떤 객체가 초기화 되었는지, 어떤 필드가 초기화 되지 않았는지 명확히 알 수 있도록 한다.
결론: 코드의 가독성, 일관된 객체의 초기화를 위한 Java 설계에 의한 것이다.
- 인스턴스 자신의 주소 반환
인스턴스의 메소드에서 this를 반환한다는 것은, 자기 자신을 반환하는 것과 같다. 이러한 사용 사례는 객체 생성에 관여하는 빌더 패턴에도 사용될 수 있다.
// Nayeon 클래스를 생성하는 NayeonBuilder 클래스
class NayeonBuilder {
private String name;
private int age;
private String gender;
public NayeonBuilder(String name) {
this.name = name;
return this;
}
public NayeonBuilder(int age) {
this.age = age;
return this;
}
public NayeonBuilder(String gender) {
this.gender = gender;
return this;
}
public build() {
return new Nayeon(name, age, gender);
}
}위 코드는 Nayeon 클래스를 생성하는 Builder 클래스이다. 필드는 Nayeon 클래스 필드와 동일하며, 메소드로 각각의 필드에 값을 할당하는 생성자를 갖는다.
이러한 빌더 패턴을 사용하면, 인스턴스 필드 값을 각각 다른 시기에 할당할 수 있다는 점에서 보다 유연한 객체 생성이 가능하다. 또한 직접 생성자를 사용하는 것보다 어떤 필드에 어떤 변수가 대입되는지 명확히 판단할 수 있다.
각 생성자에서 this를 반환하는 것은, 하나의 빌더 클래스에 대해 여러 번의 생성자(또는 메소드) 호출이 가능하도록 한다.
...
// Builder를 사용한 객체 생성
Nayeon nayeon = new NayeonBuilder()
.name(name)
.age(age)
.gender(gender)
.build();
...위처럼 생성자를 연속적으로 여러 번 호출하면서도 모두 다른 생성자를 통해 필드 값을 하나씩 초기화할 수 있는데, 이런 사용 사례를 method chaining 이라고 한다.
이 때 생성자 호출이 여러번 일어나더라도, 각 생성자는 자신의 인스턴스를 그대로 반환하기 때문에 필드 초기화 연산은 모두 하나의 빌더 인스턴스에 대해 이루어지게 된다.
2. super, super()
this가 자기 자신 인스턴스에 대한 것이라면, super는 부모에 대한 것이다.
이 때 부모라는 것은, 클래스 간의 연관 관계인 상속으로 정의될 수 있는 관계이다. 클래스 A가 클래스 B를 상속받는다면, 클래스 B는 부모, 클래스 A는 자식에 해당한다. 지금까지 보았던 클래스들을 통해 상속이 무엇인지 알아보자.
class Nayeon {
private String name;
private int age;
private String gender;
public Nayeon(String name, int age, String gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
}Nayeon 클래스로 돌아왔다. Nayeon은 사람이므로 사람이 공통적으로 갖는 속성들을 필드로 갖고 있다. 만약 Nayeon 말고 여러 사람들에 대한 클래스를 정의한다면, 그들도 공통적으로 name, age, gender 필드와 그에 관한 메소드들을 갖고 있을 것이다. 이런 경우, 공통된 특성들을 상위 개념에 해당하는 클래스에 정의하여 보다 구체적인 클래스들이 물려받게 하는 상속을 사용할 수 있다. 상속은 단순히 공통된 특성을 분리하여 코드 중복을 줄이는 것 뿐만 아니라 클래스 간의 연관 관계를 표현하는 방법이라는 의미가 있다.
class Person {
private String name;
private int age;
private String gender;
protected Nayeon(String name, int age, String gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
...
//getter, setter를 통해 private 필드에 접근
}위와 같은 Person class가 존재할 때,
class Nayeon extends Person {
public Nayeon(String name, int age, String gender) {
super(name, age, gender);
}
}위와 같이 Nayeon class를 나타낼 수 있다.
여기서 super()은 Person의 생성자 로직을 그대로 수행한다. this()가 자기 자신에 대한 생성자라면, super()은 부모 클래스의 생성자인 것이다.
3. Generic Type
Geneneric Type이란 말 그대로 타입을 일반화한 것이다.
Object
Java에서 모든 객체의 조상은 Object 클래스이다.
따라서 여러 객체 타입을 Object로 일반화할 수 있을 것 같기도 하다.
아래와 같은 코드가 있다.
List list = new ArrayList();
list.add(“hello”);
String str = list.get(0);
System.out.println(list);얼핏 보기에는 별 문제가 없어 보인다. 실제로 1~2번째 줄은 정상적으로 컴파일되지만, 3번째 줄에서 에러가 발생한다.
이유는 list가 관리하는 원소 타입이 Object이기 때문이다.
Java에서 자식 객체는 부모 객체의 역할로 대체될 수 있지만, 부모 객체에서 자식 객체의 역할로 대체되려면 명시적인 타입 캐스팅이 필요하다. 즉, Object에서 String으로 변환하는 코드가 필요한 것이다.
// 수정한 코드
List list = new ArrayList();
list.add(“hello”);
String str = (String)list.get(0);
System.out.println(list);그러나 위같은 코드를 작성하면, 리스트 원소의 타입 캐스팅에 대한 책임이 프로그래머에게 있기 때문에 프로그래머가 직접 원소 안의 타입에 대해 인지하고 캐스팅 코드를 작성해야 한다.
만약 다른 타입으로 잘못된 캐스팅이 이루어지기라도 하면, ClassCastException이 발생하여 프로그램이 중단될 것이다.
Generic
class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable,
java.io.Serializable
{
transient Object[] elementData;
private int size;
...
/**
add element
**/
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
/**
get element
**/
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
}위 코드는 java.util.ArrayList의 구현 코드를 간소화한 것이다.
클래스 이름 뒤에 있는 <E>가 바로 제네릭 타입이다. ArrayList에 저장되는 원소들의 타입을 E라고 나타낸 것이다.
밑에 원소를 추가하는 add, 특정 인덱스 값의 원소를 반환하는 get 메소드를 보자. add에서 추가할 원소를 인자로 전달 받을 때에도 타입을 E로 명시하고, 원소 값을 조회할 때에도 E 타입의 변수를 반환하는 것을 볼 수 있다.
이렇게 제네릭 타입을 사용하면, Object를 사용하지 않고 타입 캐스팅 코드 작성 없이 일반화된 타입 값을 적용하는 코드를 작성할 수 있다.
// 제네릭 타입을 포함하는 클래스의 사용
ArrayList<String> titles = new ArrayList<>();
titles.add("The Little Prince");
System.out.println(titles.get(0));4. final, static, static final
final은 그 대상이 수정될 수 없도록 제한하는 키워드이다.
final
[변수]
값이 수정될 수 없는 만큼, final 변수의 초기화는 필수적이다. 그러나 클래스의 필드인 경우 생성자를 통한 초기화, static block을 통한 초기화까지 허용한다.
만약 final 변수가 특정 객체를 참조하는 참조 변수라면, 그 객체의 내부 필드 값은 변경될 수 있다. 즉 final 변수가 참조하는 객체는 그대로 유지되어야 하지만, 그 객체의 필드 값과 같은 상태는 변할 수 있다. 이는 final 변수가 참조형인 경우, 변수의 값은 참조되는 객체의 주소 값이기 때문이다.
[메소드]
메소드 단위에서의 final 키워드는, 해당 메소드가 오버라이딩 되지 못하도록 제한하는 기능을 한다. 메소드가 최초 선언 및 구현 된 그 상태로만 사용될 수 있도록 하는 것이다.
[클래스]
final class는 상속될 수 없다는 특징이 있다.
final 키워드가 적용되는 위 세가지 사례로부터, final은 근본적으로 그 대상을 불변으로 만드는 키워드인 것을 다시 확인할 수 있다.
static
static은 객체가 아닌 클래스에 고정되는 변수 또는 메소드를 지정하는 키워드이다.
먼저 메모리의 구조를 살펴보자.
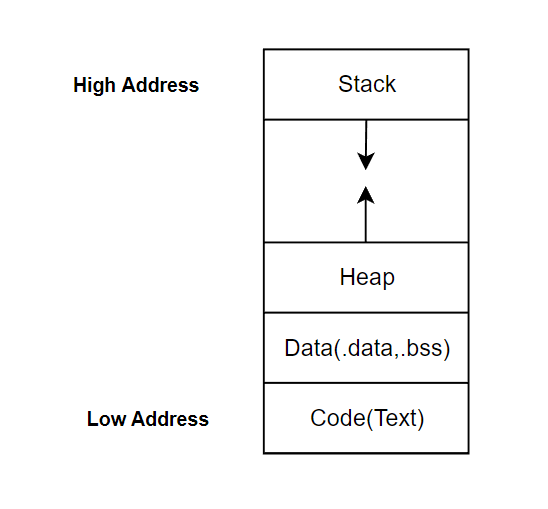
메모리는 위와 같은 구조로 이루어져 있다. 밑에서부터
- Code
실행되는 프로그램의 코드가 저장되는 공간이다. 프로그램 실행 시 CPU는 코드 영역에 저장된 명령어를 하나씩 처리한다. - Data (.data, .bss ...)
전역 변수와 정적 변수(static)이 저장되는 곳이다. 이 때 초기화된 변수는 .data로, 초기화 되지 않은 변수는 .bss에 저장된다. - Heap
사용자에 의해 관리되는 임시 메모리 영역이다. 사용자의 필요에 의해 프로그램 런타임에 메모리를 동적으로 할당한다. - Stack
함수의 호출에 관한 메모리 영역이다. 함수의 지역 변수, 매개 변수가 저장되는 Activation Record가 push되고, pop 된다. 함수가 중첩되어 호출될 때마다 push, 함수 하나의 실행이 끝날 대마다 pop 된다.
static 변수와 메소드는 프로그램 실행 시점에 메모리의 Data, 그 중에서도 static 영역에 적재된다. 런타임에 생성되는 객체들은 모두 Heap 영역에 저장된다. 즉, 가장 먼저 메모리에 적재되기 때문에 객체 생성 여부와는 상관 없이 static 변수와 메소드에 접근할 수 있다.
static의 특징을 정리하면 아래와 같다.
- 메모리에 고정적으로 할당된다.
- 객체 생성 없이 사용할 수 있다.
- 프로그램 시작 시 static 영역에 적재되고, 프로그램 종료 시에 할당 해제 된다.
- static 메소드 안에서는 인스턴스 변수에 접근할 수 없다.
[static과 this]
위와 같이, static은 프로그램 시작 시 가장 먼저 적재되기 때문에 인스턴스 변수나 메소드에 접근할 수 없다는 특징이 있었다. 같은 이유로 static 메소드에서 인스턴스의 참조형 변수인 this에도 접근할 수 없다. static에서 인스턴스 멤버 또는 인스턴스 참조형 변수에 접근하는 시점에 해당 객체가 생성되었다는 사실을 보장할 수 없기 때문이다.
같은 이유로 static 메소드에서는 this를 사용할 수 없다.
static final
static fina은 고정적이고 최종적인 상수를 정의하는 키워드이다.
static이 고정된 멤버를 정의한다면, final은 수정될 수 없는 최종적인 상수를 정의한다. 상수를 선언할 때 사용한다.
5. SOLID
SOLID 원칙이란, 객체 지향적인 설계를 위해 준수해야 하는 5가지 원칙이다.
클래스 내부의 응집력은 높이고, 클래스 간의 결합력은 낮추는 데에 초점을 맞춘다.
SRP
단일 책임 원칙, Single Responsibility Principle
단일 클래스는 하나의 역할, 책임만을 수행해야 한다는 원칙이다.
이는 클래스를 변경하는 이유도 오직 하나뿐이어야 함을 의미한다.
각 클래스들의 책임을 명확히 분리함으로써, 연쇄적으로 변경사항이 전파될 가능성을 제거하는 것이다.
책임을 분배한다는 일은 간단하게 느껴지는 일이지만, 시스템이 복잡해지고 규모가 커질 수록 잊기 쉬운 원칙 중 하나이다.
OCP
개방 폐쇄 원칙, Open-Closed Principle
개방 폐쇄 원칙이란, 확장에는 열려 있고 변경에는 닫혀 있다는 뜻이다.
데이터베이스와 JDBC 드라이버의 구조가 대표적인 OCP 사례이다.
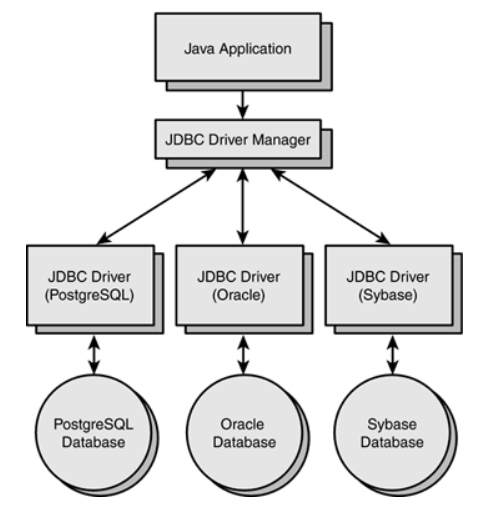
위 그림에서는 Java Application이 하나의 상위 JDBC Driver Interface에 의존하고, 상위 JDBC 드라이버 인터페이스에서 여러 종류의 JDBC 드라이버를 통해 각각 다른 종류의 데이터베이스를 사용하고 있다.
이렇게 하나의 상위 개념을 두고, 여러 하위 개념들이 상위 개념을 따르면서도 각각의 특성에 맞게 구현하는 것이 바로 OCP의 원리이다.
만약 상위 JDBC 드라이버가 없었다면, Java Application은 PostgreSQL, Oracle, Sybase 데이터베이스를 사용하기 위해 세 개의 JDBC 드라이버에 모두 의존했어야 한다. 이런 경우 어떤 문제점이 있을까?
인터페이스가 아닌, 각각의 JDBC 드라이버에 직접 의존한다고 해보자. 만약 Java Application에 MySQL 데이터베이스를 추가로 사용해야한다면 어떨까?
Java Application에
JDBC Driver(MySQL)에 관련된 코드를 추가하고, 해당 드라이버와 MySQL DB를 연동해야 한다. 즉, 하위 개념인 JDBC Driver와 DB가 추가됨에 따라 그 변경 사항이 Java Application까지 전파되는 것이다.
그러나 위의 그림처럼 JDBC Driver Interface를 통해 하위 JDBC 드라이버와 DB들에 연동된 상태에서 MySQL을 추가로 도입한다고 해보자.
이런 경우, JDBC Driver Interface에서 JDBC Driver (MySQL)을 연동하는 부분만 일부 수정하면 된다. 그 변경 사항이 Java Application까지 전파되지 않는 것이다.
이렇게 유연한 확장을 지원하면서도 변경 사항을 최소화 하는 것이 OCP의 사용 이유이다. OCP의 키워드는 유연성!
Template Method Pattern
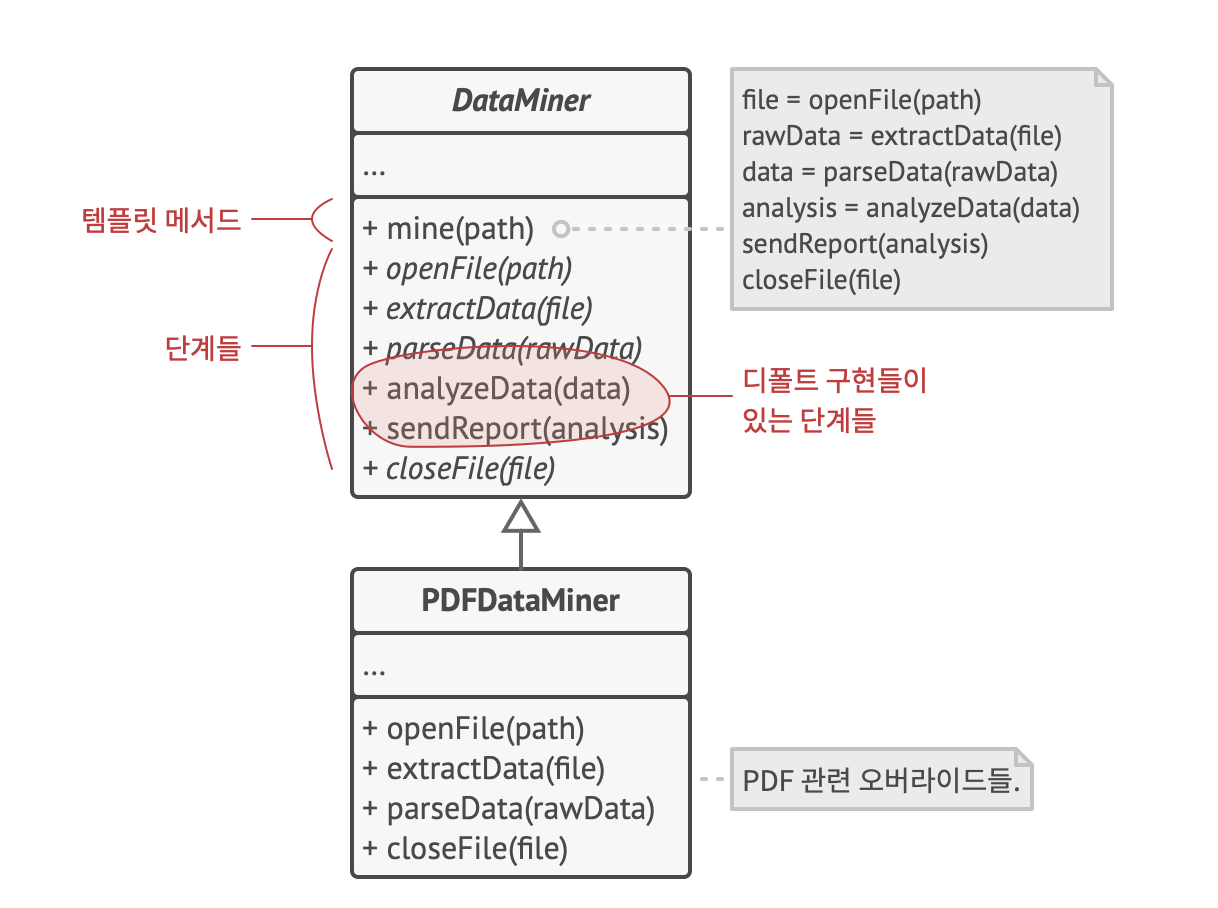
이런 OCP 원칙을 준수하는 디자인 패턴으로는 Template Method Pattern이 있다. 템플릿 메소드는 문제 해결을 위한 알고리즘을 단계 별로 구분하고, 추상 클래스로 정의한다. 추상 클래스를 상속 받는 다양한 구체 클래스들이, 그 특성에 맞게 오버라이딩할 수 있다. PDFDataMiner 외에도 WordDataMiner, HangeulDataMiner 등이 DataMiner를 상속 받아 메소드들을 오버라이딩 할 수 있을 것이다.
이러한 템플릿 메소드 패턴을 사용하면, 중복되는 코드를 줄이고 OCP 원칙을 준수함에 따라 확장이 용이하고 변경 사항을 가둘 수 있다.
LSP
리스코프 치환 원칙, Liscov Substitution Principal
리스코프 치환 원칙이란, 상속 관계에서 하위 클래스가 상위 클래스를 완전히 대체할 수 있어야 한다는 원칙이다.
이는 하위 클래스가 상위 클래스를 상속함에 있어서 올바른 상속을 통해 하위 클래스의 확장이 온전히 상위 클래스의 속성을 따르게 하기 위함이다.
위에서 언급했듯이, 상속은 단순히 상위 클래스의 속성을 물려받는 것을 넘어서 상위 클래스와 하위 클래스의 의미적인 연관 관계가 성립하는 것이다. 리스코프 치환 원칙을 준수하기 위해서는, 더 큰 범주의 포괄적이고 추상적인 상위 클래스로부터 더 작은 범주의 구체적인 하위 클래스가 상속 받아야 한다.
(ex.
Square -extends-> Rectangle
Square -extends-> Shape
)ISP
인터페이스 분리 원칙, Interface Segregation Principal
용도에 맞는 기능들만을 제공하도록 인터페이스를 분리하라는 원칙이다.
어떻게 생각하면, SRP가 클래스에 대한 원칙이었다면 ISP는 인터페이스에 대한 원칙이라고 볼 수 있다.
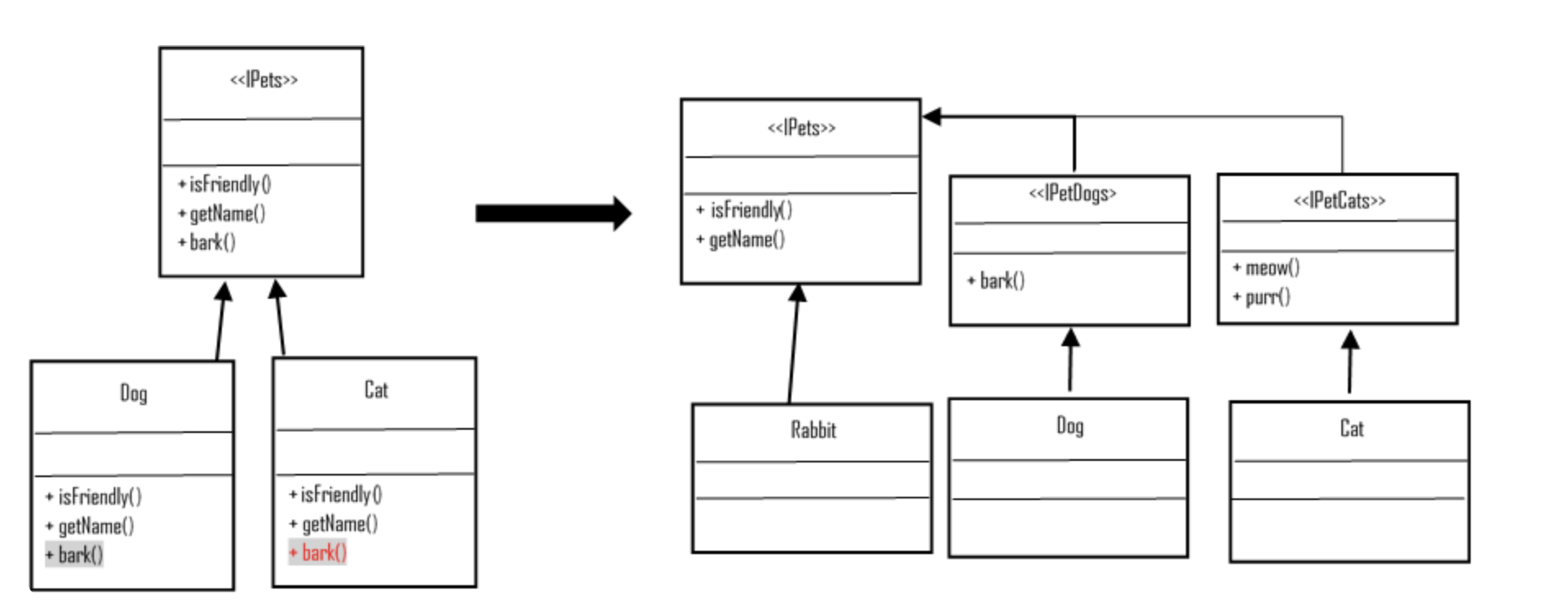
만약 위 그림의 왼쪽 경우처럼 IPets라는 인터페이스에서 bark() 메소드를 구현하고 있다면, IPets 인터페이스를 구현하는 Cat 클래스에서는 요구되지 않는 bark() 메소드를 강제로 구현해야 한다. 인터페이스에서 정의된 모든 메소드는 이를 상속 받는 하위 클래스에서 구현되어야 하기 때문이다.
이에 오른쪽처럼 IPets 인터페이스에는 모든 반려 동물이 갖고 있는 근본적이고 공통적인 행위에 대한 메소드만 정의하고, 해당 인터페이스를 보다 구체적인 IPetDogs, IPetCats가 상속하게 하여 인터페이스를 분리할 수 있다.
이렇게 하면, 각 동물의 특성에 맞는 보다 구체적인 인터페이스를 클래스들이 상속하게 함으로써 보다 용도에 맞는 구현이 가능하다.
DIP
의존 역전 원칙, Dependency Inversion Principal
어떤 클래스 A가 다른 클래스 B를 필요로 하여 B의 객체를 참조하는 경우, 클래스 A는 클래스 B를 의존하는 관계이다. 의존 역전 원칙이란, 상속 관계에 있는 클래스 또는 인터페이스에 대해 비교적 추상적인 상위 클래스/인터페이스에 의존하라는 원칙이다.
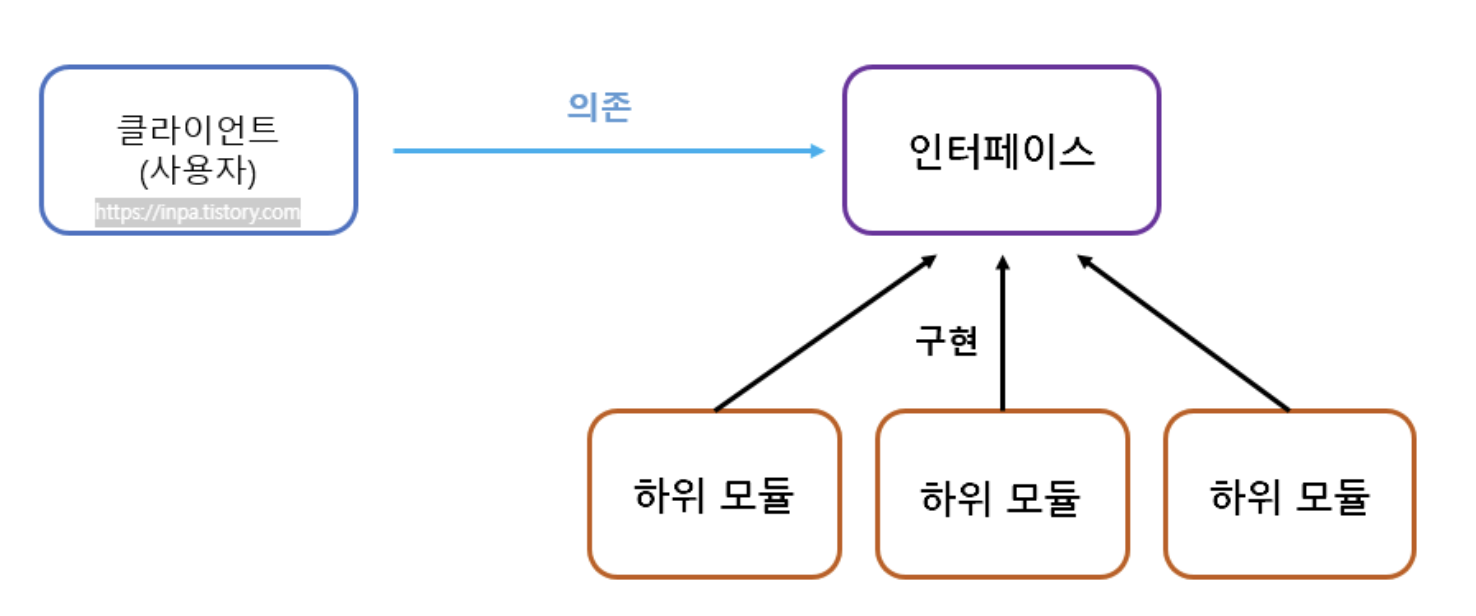
보다 추상적인 고수준의 모듈에 의존하면 어떤 것이 좋을까?
OCP 원칙과 같은 이유로 변경 사항이 모듈에 의존하는 클라이언트 단까지 전파되지 않는다는 점이다.
실제 사용 관계는 변하지 않지만, 추상적 모듈을 통해 메세지를 주고 받으면서 의존 관계를 최대한 느슨하게 한다. 필요한 클래스에 의존은 하되, 발만 걸쳐놓고 언제든지 빠져나올 수 있을 정도로만 의지하는 것...! 참조하는 클래스 객체가 무슨 일을 하는지는 알고 있지만 그 일을 어떻게 처리하지는 모르도록 하는 것...!이 DIP이다.
6. Spring DI
Spring은 세가지 핵심 프로그래밍 모델인 AOP, DI, IOC를 지원한다. 이 때 DI란 Dependency Injection으로, 객체를 직접 생성하지 않고 스프링 프레임워크에서 객체를 생성하여 주입해주는 메커니즘을 말한다.
그렇다면 스프링에서 생성하고 관리하는 객체들을 어떻게 각 클래스에 가져와서 참조할 수 있을까? 아래와 같은 3가지 방법으로 의존성을 주입받을 수 있다.
- Constructor Injection (생성자 주입)
- Field Injection (필드 주입)
- Setter Injection (지정자 주입)
// DI를 적용하지 않은 코드
@Service
public class DemoService {
private final LineRepository repository;
public DemoService() {
this.repository = new DemoRepository();
}
...
}위와 같은 서비스 클래스가 있다고 해보자.
해당 서비스 클래스는, DB의 데이터에 접근하기 위해 DemoRepository 클래스를 참조해야 한다.
DI를 적용하지 않는다면, 이렇게 필요로 하는 클래스의 객체를 생성자를 통해 직접 생성하고, 초기화 해야 한다.
이렇게 직접 객체를 생성하고 참조하는 방법은, 두 클래스 간의 의존성이 높아지는 만큼 유지 보수 측면에서 불편한 점이 많다.
Constructor Injection
// Constructor Injection
@Service
public class DemoService {
private final LineRepository repository;
public DemoService(DemoRepository demoRepository) {
this.repository = demoRepository;
}
...
}위와 같이, 생성자의 매개 변수로 주입 받으려는 객체를 전달 받아 클래스 안의 final 필드로 주입한다. 이러한 방법을 생성자 주입이라고 한다.
Field Injection
// Field Injection
@Service
public class DemoService {
@Autowired
private DemoRepository repository;
public DemoService() {
}
}위와 같이, 필드 위에 @Autowired 어노테이션을 명시하여 객체를 주입 받는 방법을 필드 주입이라고 한다.
Setter Injection
// Field Injection
@Service
public class DemoService {
public DemoService() {
}
@Autowired
public void setRepository(DemoRepository demoRepository) {
this.repository = demoRepository;
}
}주입 받으려는 객체에 대한 지정자를 정의하고, @Autowired 어노테이션으로 명시하는 방법이 지정자 주입이다.
Why? Constructor Injection
스프링 공식 문서에서 가장 권장하는 의존성 주입 방식은 생성자 주입이다.
그렇다면 왜 생성자 주입을 사용해야 할까?
[SRP]
첫번째로 단일 책임의 원칙 때문이다. 만약 Field Injection을 사용한다면, 의존성 주입이 매우 쉬워 무분별한 주입이 발생할 수 있다. 이런 경우 클래스가 의존성 주입을 통해 범용적인 기능을 수행할 여지가 있다.
[Immutability]
두번째로 불변성을 보장한다는 것이다. 오직 생성자 주입을 통해 final로 객체를 주입받을 수 있다. final로 정의된 객체는 변경될 수 없으므로, 불변성을 보장한다.
[NPE]
생성자 주입을 통해 전달 받은 객체는 생성자를 통해 초기에 할당된다. 이에 null 상태일 때 주입된 객체를 참조하는 NPE(Null Pointer Exception) 문제가 발생하지 않는다.
7. record class
record는 불변 객체를 생성하는 특수한 클래스이다.
public final class Student {
private final String name;
private final nt age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}위와 같은 불변 클래스 Student가 있다.
public record Student(String name, int age) {
}Student 클래스를 record로 작성한 것이다.
record 클래스는 컴파일러가 컴파일 타임에 자동으로 코드를 추가해주기 때문에, 위와 같이 간략하게 구현이 가능하다.
record 클래스로 자동 구현되는 내용은 아래와 같다.
- 필드 캡슐화
- 생성자 메서드
- getters 메서드
- equals 메서드
- hashcode 메서드
- toString 메서드
record는 불변 클래스와 관련 기능들을 자동 생성해주는 클래스이기 때문에, DTO(Data Transfer Object)를 나타내는 데에 용이하다.
Entity record
그렇다면 entity를 record 클래스로 구현할 수 있을까?
그럴 수 없다. ❌
JPA의 entity는 지연 로딩된다. JPA는 지연 로딩에 있어서 entity 객체를 상속하는 proxy 객체를 생성하는데, record는 상속이 불가능한 불변 객체이므로 proxy 객체가 생성될 수 없다.
...
지금까지 기초적인 Java, OOP, Spring에 대한 조각 개념들을 정리하였다. 🍀
