(3주차 목표)
Python basic, Web scraping basic, mongoDB/pymongo
파이썬 기초
1) 숫자 더하기
a = 2
b = 3
print(a+b) % 52) 문자열 더하기
a = 'yejin'
b = 'shin'
print(a+b) # yejinshin3) List
a_list = ['사과','배','감']
print(a_list[1]) # 배, python은 0부터 시작.
a_list.append('수박')
print(a_list) # ['사과','배','감','수박']4) Dictionary
a_dict = {
'name' : 'bob',
'age' : 27
}
print(a_dict['name']) # bob5) Function
def sum(a,b) :
print('더하자!')
return a+b
result = sum(1,2)
print(result)
# 더하자!
# 3
def is_adult(age) :
if age > 20 :
print('성인입니다')
else :
print('청소년입니다')
is_adult(15)
# 청소년입니다6) For
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
for aaa in fruits :
if aaa == '사과':
count += 1
print(count)
# 2
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
for person in people :
if person['age'] > 20 :
print(person['name'])
# carry
# ben패키지 사용해보기
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for row in rows :
gu_name = row['MSRSTE_NM']
gu_mise = row['IDEX_MVL']
if gu_mise < 60 :
print(gu_name)
# 한 줄씩 찍히게 됨
설명 : requests라는 라이브러리를 쓰고 싶어서,
네가 쓰라는데로 r = requests.get ... rjson ... 썼어.
이제 rjson을 가지고 내가 요리를 해볼게.크롤링/웹스크래핑 기초
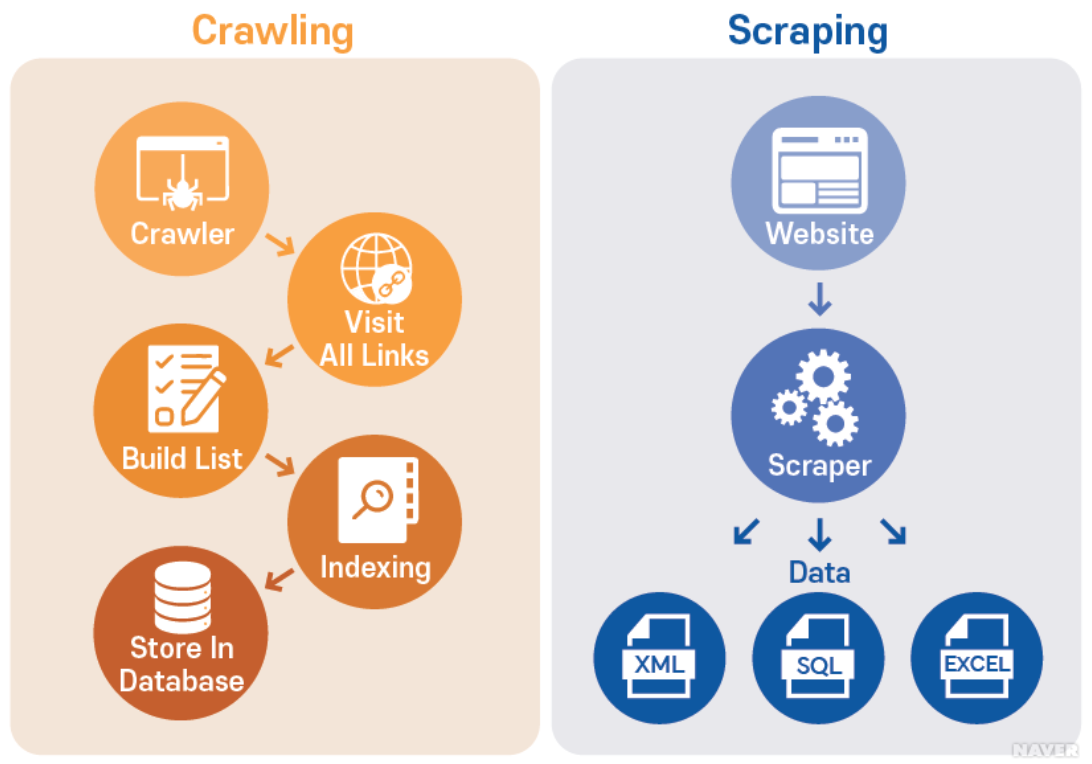
크롤링 : 크롤링을 위해 개발된 소프트웨어를 크롤러(crawler)라 한다.
크롤러는 주어진 인터넷 주소(URL)에 접근하여 관련된 URL을 찾아내고,
찾아진 URL들 속에서 또 다른 하이퍼링크(hyperlink)들을 찾아 분류하고 저장하는 작업을 반복함으로써
여러 웹페이지를 돌아다니며 어떤 데이터가 어디에 있는지 색인(index) 을 만들어 데이터베이스(DB)에 저장하는 역할을 한다
스크래핑 : 크롤링과 유사 개념으로 소프트웨어를 통해 대상 웹사이트와 같은 데이터 소스에서
데이터 자체를 추출하여 특정 형태로 저장하는 스크레이핑(scraping)이 있다.
빅데이터 분석에서는 크롤링을 통해 필요한 데이터가 어디 있는지 알아내고,
이를 스크레이핑을 통해 수집, 저장하여 분석에 사용하는 것처럼 두 기술을 결합하여 사용하기도 한다.
* 출처 : [네이버 지식백과] 크롤링 [crawling] (용어로 알아보는 우리시대 DATA)1) 크롤링 기본 셋팅
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# header에서 call을 날리는데, 마치 browser에서 콜을 날린 것처럼(사람인 것처럼) 해주는 것.
# 아래 headers=headers 참고.
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup)2) beautifulsoup 쓰는 방법
beautifulsoup(bs4) : html은 가져왔는데 그 안에서 내가 찾는 제목을 쉽게 찾기 위한 라이브러리
* 원하는 곳 > 검사 > copy > copy selector
* 네이버 영화 페이지에서 제목 가져오기
예시 1 - 하나만)
title = soup.select_one('copy selector 복사한 값')
print(title) # 그 태그가 찍힘
print(title.text) # 그 태그에서 우리가 원하는 텍스트 부분 나옴
print(title['(예를 들어) href']) # href 안에 값이 나옴
예시 2 - 여러개)
movies = soup.select('#old_content > table > tbody > tr') # 중복되는 앞부분
for movie in movies :
a = movie.select_one('td.title > div > a') # 중복되는 뒷부분
if a is not None : # a == None
print(a.text) # 영화 제목들이 순서대로 나옴
* 네이버 영화 페이지에서 순위, 평점, 제목 가져오기
앞에서 봤던 것과 마찬가지로 검사를 누르고 print()로 확인하면서 원하는 값들을 뽑아내면 된다.
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies :
a = movie.select_one('td.title > div > a')
if a != None : # = a is not None
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt'] # 앞에서 이미 붙인 부분을 제외한 뒷부분을 넣어주고 print(rank) 했더니 원하는 값이 'alt'에 들어있었기 때문에, ['alt']를 해준다.
star = movie.select_one('td.point').text # 앞에서 이미 붙인 부분을 제외한 뒷부분을 넣어주고 원하는 부분인 text만 뽑아줌.
print(rank, title, star)Data Base(DB) 개괄
1) 들어가기 전에
Q1 : DB는 왜 쓰는 것일까?
A1 : 나중에 잘 찾기 위해서
Q2 : 교보문고에 가서 책을 찾는다고 하면?
A2 : 꽂혀진 방법대로 찾아야 쉽게 찾을 수 있겠쥬? (섹션 → 출판사 → 제목)
따라서, DB에도 Index라는 순서로 데이터들이 정렬되어 있다2) DB의 두 가지 종류
SQL : 칸을 정해놓고 순서대로 쌓는 것
NoSQL : 칸이 정해져 있지 않고 들어오는 대로 쌓는 것
* standard language for storing, manipulating and retrieving data in databases
NoSQL의 대표적인 것이 mongoDB3) DB의 실체에 관하여
DB는 특별한 컴퓨터일까?
NO! 아주 간단하게, 우리가 쓰는 프로그램과 같은 것이다.
즉, 내 컴퓨터에 게임을 설치하는 것처럼 DB도 설치할 수 있는 것이다.
그런데 이마저도 요새 cloud 형태로 제공해주는 곳들이 많은데,
유저가 몰리거나/ DB를 백업해야 하거나/ 모니터링 하기가 쉽기 때문이다
그래서, 우리도 최신 클라우드 서비스인 'mongoDB Atlas'를 사용해 볼 것!mongoDB/pymongo
pymongo 라이브러리의 역할
: mongoDB 라는 프로그램을 조작하려면, 특별한 라이브러리인 pymongo가 필요하다!1) 패키지 설치하기
pymongo, dnspython2) mongDB 연결하기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:sparta@cluster0.4n13d.mongodb.net/Cluster0?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
# 나같은 경우에는 맥북이어서인지 보안 때문에 certifi를 추가적으로 설치해줘야 실행되었음.3) pymongo로 DB 조작하기
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})4) 웹스크래핑 결과 저장하기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:sparta@cluster0.4n13d.mongodb.net/Cluster0?retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies :
a = movie.select_one('td.title > div > a')
if a != None : # = a is not None
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
doc = {
'title':title,
'rank':rank,
'star':star
}
db.movies.insert_one(doc)
5) 웹스크래핑 결과 이용하기
① 영화제목 '가버나움'의 평점 가져오기
movie = db.movies.find_one({'title':'가버나움'})['star']
② '가버나움'의 평점과 같은 평점의 영화 제목들을 가져오기
all_movies = list(db.movies.find({'star':movie},{'_id':False}))
for movie in all_movies:
print(movie['title'])
③ '가버나움' 영화의 평점을 0으로 만들기
db.movies.update_one({'title': '가버나움'}, {'$set': {'star': '0'}})(3주차 소감)
mongoDB에 데이터를 저장하고 싶은데 계속 실행이 안되서 헤맸었다.
하지만 슬랙에 물어보니 친절하게 답변해주셔서 쉽게 해결할 수 있었음! 애용해야겠다.
(참고 사이트)
크롤링/웹스크래핑 몹시 헷갈릴 때 : https://kamang-it.tistory.com/entry/PythonCrawlingScraping%ED%81%AC%EB%A1%A4%EB%A7%81%EA%B3%BC-%EC%8A%A4%ED%81%AC%EB%9E%98%ED%95%91-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%EC%9B%90%EB%A6%AC1
옍