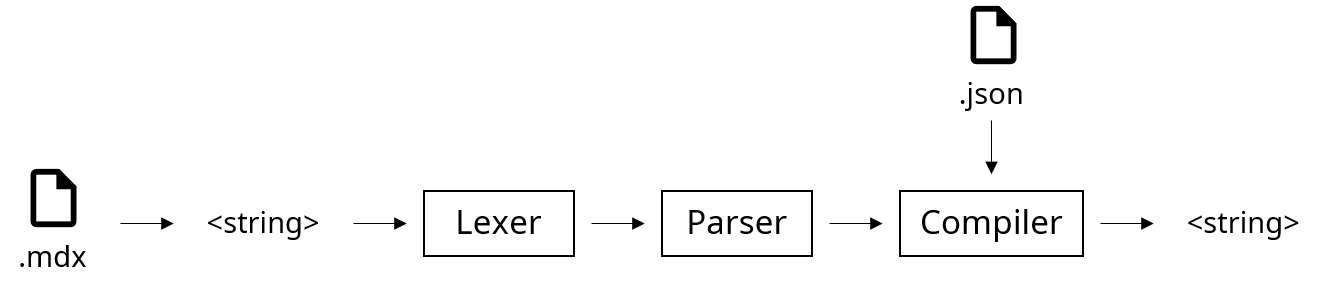
프로젝트를 생성하며 목표로 잡았던 첫 기능을 오늘 끝냈는데 목표로 했던 기능은 다음과 같다.
// hello.mdx
Hello, ${name}
// hello.json
{ "name": "World" }
> dot-mdx hello.mdx hello.json
Hello, World구현 방법
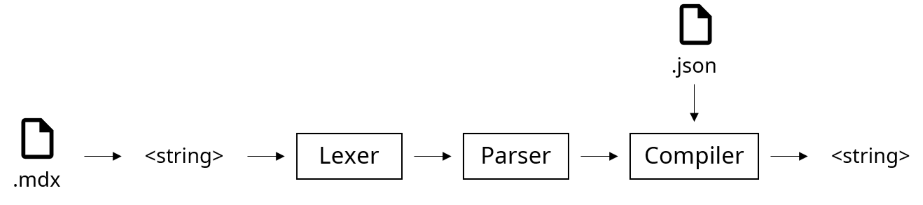
- 파일의 내용을 Lexer가 Regex을 통해 토큰 목록을 생성한다.
- 만들어진 토큰 목록을 Parser가 AST를 생성한다.
- Compiler가 AST를 방문하며 결과물을 출력한다.
Lexer 동작 원리
파일 내용의 첫 문자부터 Regex를 이용하여 아래의 순서대로 다음 토큰에 맞는지 확인하도록 했다.
- L_Block ('${')
- R_Block ('}')
- Identifier (블록 내 문자열)
- NewLine ('\n')
- Text (블록 밖의 문자열)
각 토큰별 Regex 패턴에 일치하면 매치 결과를 얻을 수 있는데
이에 따라 토큰을 생성하고 해당 토큰 다음 위치로 이동하여 이 과정을 반복하도록 했다.
private scan(type: TokenType, regex: RegExp) {
let captures;
if ((captures = regex.exec(this.input))) {
const length = captures[0].length;
let token: Token;
if (captures.length > 1) {
// 패턴에 Capture Group가 있는 경우 (Identifier, Text)
const value = captures[1];
token = <Token>{ type, value, line: this.lineNo };
} else {
token = <Token>{ type, line: this.lineNo };
}
this.move(length); //
return token;
} else {
return null;
}
}앞선 과정으로 Hello, ${name} 문자열을 처리하게 되면 다음 토큰 목록을 얻을 수 있다.
[
<Token>{ type: TokenType.Text, value: "Hello, ", line: 1 },
<Token>{ type: TokenType.L_Block, line: 1 },
<Token>{ type: TokenType.Identifier, value: "name", line: 1 },
<Token>{ type: TokenType.R_Block, line: 1 },
<Token>{ type: TokenType.EOS },
]Parser 동작 원리
앞서 Lexer를 통해 토큰 목록을 얻었다면 토큰을 통해 다음과 같은 트리를 생성한다.
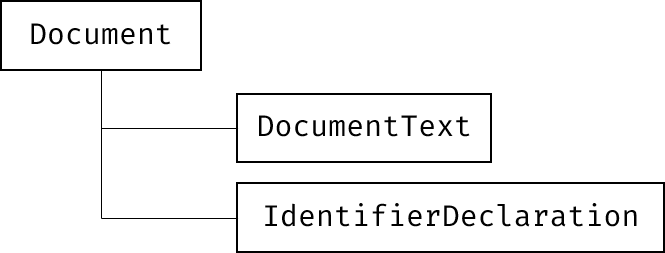
트리는 토큰 목록을 순차적으로 탐색하며 생성하게 되며
블록을 처리할 떄는 아래의 순서로 처리하도록 했다.
- 토큰 타입이 L_Block 일때 다음 토큰으로 이동한다.
- 다음 토큰의 타입이 Identifier 이라면, 그 다음 토큰의 타입을 확인한다.
- Identifier 다음 토큰이 R_Block이라면 IdentifierDeclaration 노드를 생성하여 리턴한다. 그렇지 않다면 오류를 발생시킨다.
Compiler 동작 원리
Parser에서 만든 AST를 탐색하며 결과를 생성하는데 컴파일 시 Json 형식으로 이루어진 문자열을 읽어 IdentifierDeclaration 노드를 변환하도록 했다.
private transformIdentifierDeclaration(node: IdentifierDeclaration) {
this.append(this.data[node.name]);
}다음 목표
마크다운 문서를 만들면서 반복되는 내용에 대해 다른 파일에서 가져오는 것을 필요하다 생각했기에 이 기능이 다음 목표이다.
// hello.mdx
${include header}, World
// header.mdx
# Hello
> dot-mdx hello.mdx
# Hello, World