
Deployment
-
디플로이먼트가 레플리카셋을 만들고 레플리카셋이 정의된 개수만큼 파드를 만드는 구조이다.
-
이미지의 새로운 버전이나 새로운 이미지를 배포/교체 하는 것을 쉽게 해준다
= 배포 전략 -
쿠버네티스에서 지원하는 배포전략은 recreate와
rolling update( =roll out, Ramped) 두가지가 있다. -
쿠버네티스의 디플로이먼트는 default로 rolling update를 가진다.
- recreate, rolling update 말고도 수많은 배포방식이 있다.
< recreate >
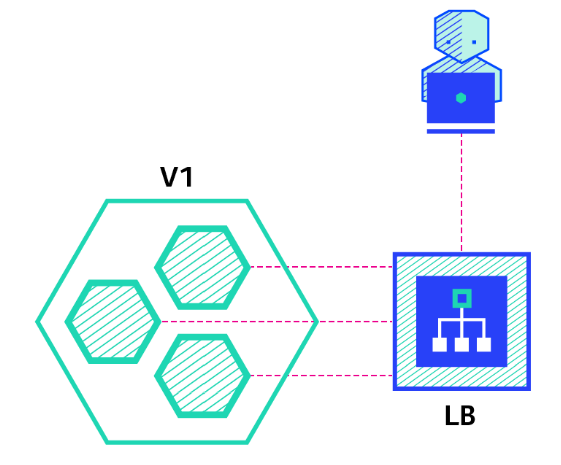
- 템플릿 수정을 통해 새로운 버전이 적용되면 기존의 레플리카셋을 지워버리고 디플로이먼트가 새로운 버전이 적용된 레플리카셋을 생성한다.
- 다운타임 : 몇초가 되었든 기존의 레플리카셋이 지워지고 새로운 레플리카가 생성되는 시간까지 서비스를 이용하지 못한다.
-> 접속된 클라이언트의 세션이 다 날라갈 수 있다.- planned 다운타임 : 게임에서 패치같은 경우이다.
-> recreate를 사용하게 되면 계획하게 된다. - unplanned 다운타임 : 조심해야할 다운타임이다.
- planned 다운타임 : 게임에서 패치같은 경우이다.
💡 네이버,구글 같은 포털사이트도 옛날에는 recreate를 사용했기 때문에 planned 다운타임이 있었지만 현재는 무중단 시스템을 구현했다.
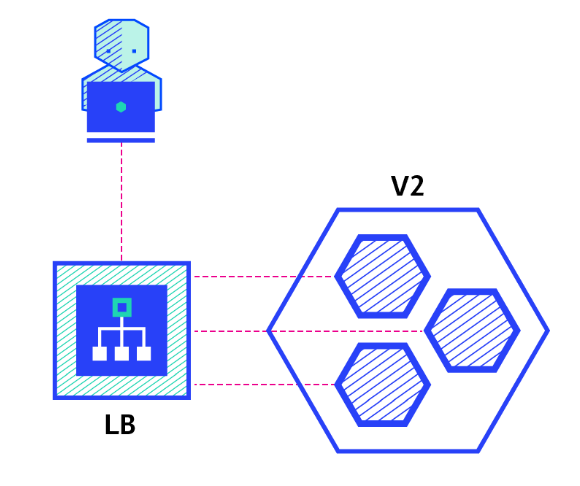
< rolling update >
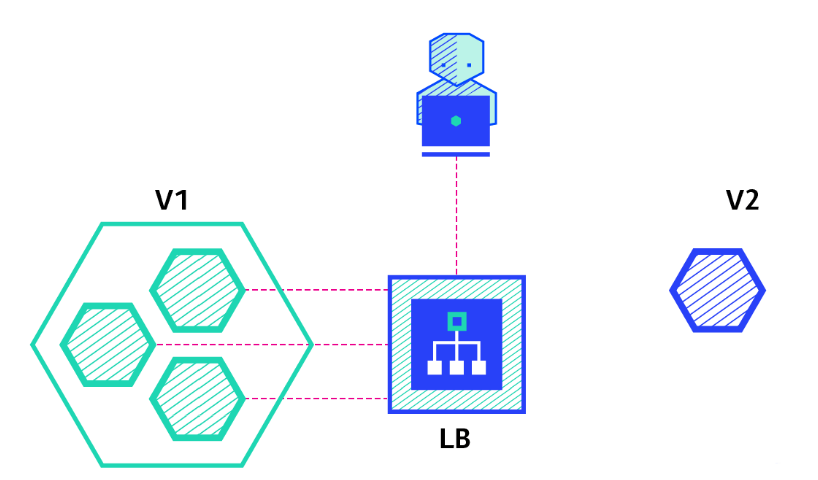
-> 템플릿 수정을 통해 새로운 버전이 적용된 레플리카셋을 만들어놓고 새로운 버전의 파드를 하나 생성
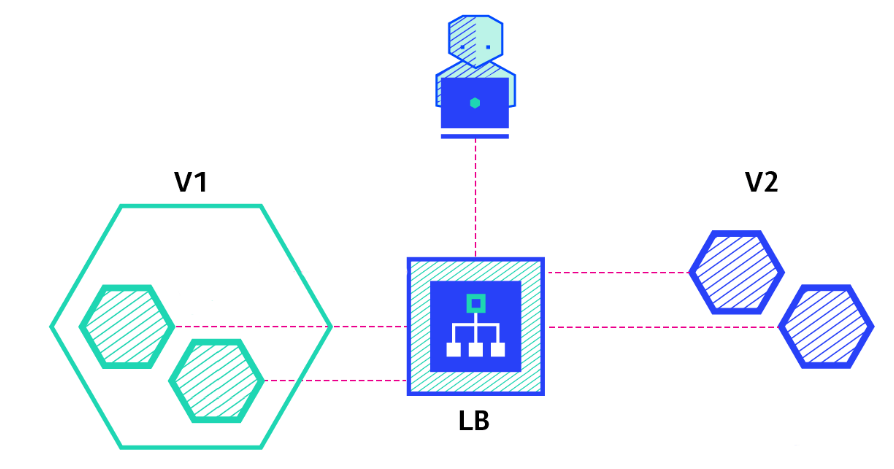
-> 이후 다시 새로운 버전의 파드를 생성 후 이전 버전의 레플리카셋의 파드를 제거해 나간다.
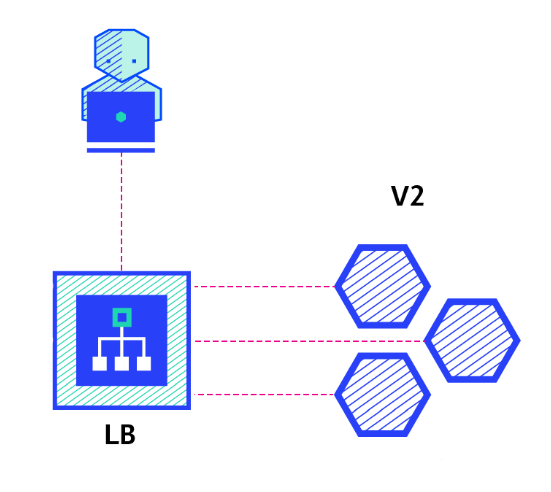
-> 이런식으로 새로운 버전의 레플리카셋을 생성한다.
- 무중단 시스템을 구현할 때 사용한다.
- 옮기는 과정에서 트래픽이 로드밸런서에 의해 나누어질 수 있기 때문에 기존의 버전과 새로운 버전을 사용하는 클라이언트가 나누어질 수 있다.
-> 개발자가 새로운 버전을 사용하는 사용자와 이전 버전을 사용하는 사용자의 차이가 없도록 고려해야 한다. - 블루/그린 배포같은 경우는 새로운 버전의 레플리카셋과 파드를 미리 다 준비해 놓고 다운타임없이 옮긴다. 이때 순간적으로 리소스가 두배가 필요하게 된다. 그렇기에 비용이 매우 비싸다.
= 물리적인 환경에서는 비용 때문에 매우 힘든 방식이다.
-> 하지만 rolling update는 파드 한개 생성 - 파드 한개 제거 의 구조로 진행되기 때문에 리소스가 많이 필요하지 않다.
1 . 디플로이먼트 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
labels:
app: myapp-deploy
spec:
strategy: # 배포전략
type: RollingUpdate # or recreate
rollingUpdate: # rolling update 선택시 옵션 선택
maxUnavailable: 1
maxSurge: 1
minReadySeconds: 20
replicas: 3
selector:
matchLabels:
app: myapp-deploy
template:
metadata:
labels:
app: myapp-deploy
spec:
containers:
- image: ghcr.io/c1t1d0s7/go-myweb:v1.0 # 버전 수정
name: myapp
ports:
- containerPort: 8080- image에 버전을 v2.0으로 수정한다.(= 새로운 버전을 배포)
kubectl replace -f myapp-deploy-v1.yaml # 새로운 버전으로 수정한 템플릿으로 교체 - replace는 기존의 리소스가 존재해야 사용 가능
- replace대신 apply사용 가능
-> apply는 replace, create 기능 둘다 가지고 있다 - edit으로도 수정이 가능하다 (patch도 가능)
kubectl set image < TYPE > < NAME > < CONTAINER_NAME >=< NEW_IMAGE >
-> 새로운 버전의 레플리카셋이 생성되고, 기존의 레플리카셋의 파드가 하나씩 없어지면서 새로운 버전의 레플리카셋에 새로운 버전의 이미지가 적용된 파드가 하나씩 생성되는 것을 확인할 수 있다.
리소스로 레플리카셋을 사용하면 템플릿에 버전을 변경후 replace를 하게되면 이미 생성되어있는 기존의 파드에는 영향이 없고, 새로운 버전의 레플리카셋이 생성이 되면서 앞으로 생성되는 파드에만 영향을 준다
-> 파드를 지우고 다시 생성하면 새로운 버전의 파드가 생성되기는 한다.
-> 하지만 파드의 개수가 많다면 새로운 버전을 배포하기 위해서 일일이 파드를 지우는 것은 비현실적이다,
-> 디플로이먼트를 사용하게 되면 기존의 파드(서비스,어플리케이션)에 새로운 버전을 배포/교체 하기 쉬워진다.
- maxUnavailable, maxSurge는 기본적으로 리소스의 25%로 설정된다. 만약 파드가 3개면 25%는 0.75이고 기본적으로 올림을 하기 때문에 1이 된다.
- maxSurge는 복제본 최대개수(replicas =3)에서 일시적으로 추가로 허용하는 개수를 지정한다.
- maxUnavailable은 기존 버전의 레플리카셋에서 지울수 있는 파드의 개수이다.
-> 만약 maxSurge가 0일때, 먼저 새로운 버전의 레플리카셋에서 파드를 생성하게 복제본 개수는 4개가 되기때문에 surge값에 위배된다. 따라서 먼저 maxUnavailable의 값만큼 지우고 새로운 버전의 파드를 생성한다. - 최종적으로 다 옮긴 후에 기존의 레플리카셋은 파드의 개수가 0인상태에서 특정시간만큼 남아있게된다.
-> 이것은 RollBack을 하기 위한 것으로, 배포후에 잘못되었다고 판단되면 돌아갈 수 있게한다.
kubectl rollout status deployment < delpoyment name >
# 배포가 잘되었는지 안되었는지 상태를 확인할 수 있다.
kubectl rollout history deployment < delpoyment name >
# 배포를 한 기록 확인, 개정판과(버전)과 변경사유를 볼 수 있다.
# history를 보고 rollback을 할 수 있다. 
-> 어노테이션을 추가해 변경사유를 기록해놓을 수 있다.
kubectl rollout undo deployment < delpoyment name > --to-revision 2
# = rollback 2 . 디플로이먼트 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
labels:
app: myapp-deploy
annotations: # 변경 사유 추가
kubernetes.io/change-cause: My Golang Web App Version 3
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
minReadySeconds: 20
replicas: 3
selector:
matchLabels:
app: myapp-deploy
template:
metadata:
labels:
app: myapp-deploy
spec:
containers:
- image: ghcr.io/c1t1d0s7/go-myweb:v3.0
name: myapp
ports:
- containerPort: 8080
readinessProbe:
periodSeconds: 1
httpGet:
path: /
port: 8080
- 쿠버네티스에서는 카나리 배포전략은 지원하지 않지만 비슷하게 만들 수는 있다.
- 다만 세련되지 않고, 억지느낌이기 때문에 주로 사용되지는 않는다.
StatefulSets
- 디플로이먼트나, 레플리카셋처럼 복제본을 제공한다.
- 디플로이먼트의 배포전략처럼 updateStrategy가 존재한다.
- 디플로이먼트와는 다르게, 스테이트풀셋은 각 파드의 독자성을 유지한다
- stateful상태라는 것은 상태를 저장하는 것. 즉, 고유한 상태가 존재해야 한다는 것이다.
-> sts로 만든 각 파드가 고유한 상태를 가지기 위해 각각의 스토리지(볼륨)를 부착한다.
-> 각 해당 볼륨은 pv-pvc연결을 가진다.

1 . 스테이트풀셋 생성
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myapp-sts
spec:
selector:
matchLabels:
app: myapp-sts
serviceName: myapp-svc-headless # 서비스 리소스를 연결한다
replicas: 2
template:
metadata:
labels:
app: myapp-sts
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 80801-1 . 서비스 생성
apiVersion: v1
kind: Service
metadata:
name: myapp-svc-headless
labels:
app: myapp-svc-headless
spec:
ports:
- name: http
port: 80
clusterIP: None # 헤드리스 서비스 특징
selector:
app: myapp-sts-> 헤드리스 서비스는 clusterip가 존재하지 않아 host로 서비스의 이름을 호출하면 서비스의 ip가 return되는 것이 아니라, 서비스와 연결된 파드의 ip가 return된다 = 파드에 직접 접근 가능
-> 반드시 연결하는 서비스는 헤드리스 서비스여야 한다.

-> 다른 리소스로 생성한 파드이름과 다르다는 것을 볼 수 있다.
-> 스테이트풀셋으로 만든 파드는 고유성이 존재하기 때문에 이름이 랜덤하게 생성되지 않고 0부터 순차적으로 생성된다.
-> 만약 파드를 삭제하고 다시 생성해도 삭제했던 파드가 생성되고, 똑같은 노드에 배치된다 = 순서와 고유성 보장
kubectl run nettool --image ghcr.io/c1t1d0s7/network-multitool -it --rm # 가상의 클라이언트 담당 파드 생성 
-> 스테이트풀셋과 헤드리스 서비스를 결합하면 파드의 이름을 통해 접근할 수 있다.
StatefulSet의 Volume
1 . Volume을 부착한 스테이트풀셋 생성
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myapp-sts-vol
spec:
selector:
matchLabels:
app: myapp-sts-vol
serviceName: myapp-svc-headless
replicas: 2
template: # 파드의 템플릿
metadata:
labels:
app: myapp-sts-vol
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
volumeMounts:
- name: myapp-data
mountPath: /data
volumeClaimTemplates: # pvc의 템플릿
- metadata:
name: myapp-data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
storageClassName: nfs-client # 사전에 설치한 스토리지 클래스 설정 -> 파드의 템플릿과 pvc의 템플릿을 작성해줘야 한다.
-> sts가 파드의 템플릿에 따라 파드를 만들고 replica개수에 따라 동일한 파드 두개를 생성한다. 그리고 pvc템플릿에 따라 두개의 pvc를 만들고 각 파드에 연결한다. 지정한 스토리지 클래스에 의해 동적 프로비저닝으로 각 pvc에 pv연결을 하고 pv연결을 통해 스토리지에 연결된다
kubectl scale sts myapp-sts-vol --replicas 3 # 파드의 개수 3개로 scale
kubectl get pv,pvc # pv,pvc 확인 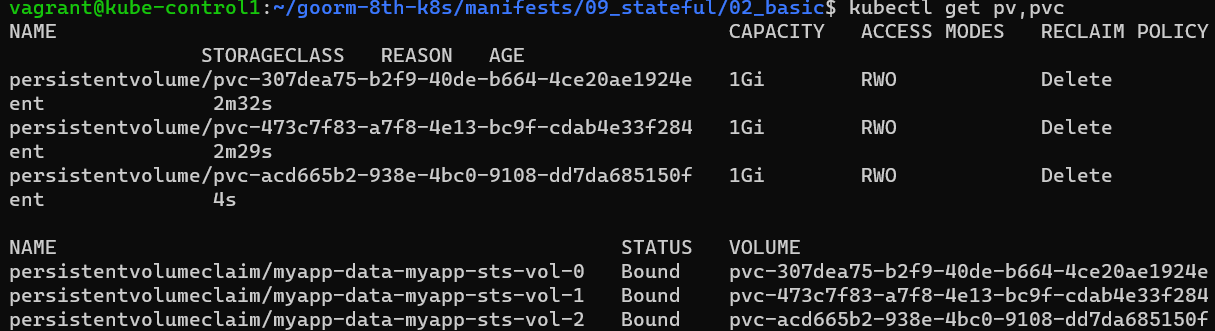
-> 3개로 늘리면 자동으로 추가된 하나의 파드에 pvc-pv연결이 생성된다.
kubectl scale sts myapp-sts-vol --replicas 2 # 파드의 개수 2개로 scale
kubectl get pv,pvc # pv,pvc 확인 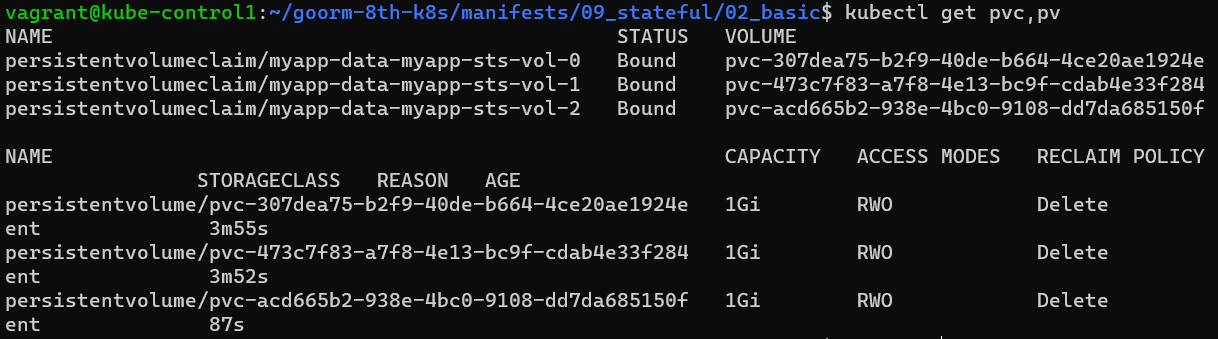
-> 파드를 다시 두개로 줄여도 기존의 pv-pvc연결은 세개를 유지한다.
-> 스테이트풀셋으로 생성한 파드는 고유한 속성을 가지고 이러한 고유한 속성을 볼륨에 저장한다. 따라서 파드를 지웠는데 pv-pvc연결도 없어지면서 데이터도 같이 날아간다면 이것은 고유한 속성을 유지하지 못하는 것이다.
= 파드를 지워도 볼륨은 그대로 존재한다
= 볼륨까지 지우기 위해서는 직접 삭제해야 한다.
= 만약 모든 파드를 지우고 새로운 스테이트풀셋으로 파드를 생성하면 기존의 남아있던 볼륨이 그대로 새로운 파드에 연결되어 데이터를 저장한다.
- 볼륨에 이전 파드의 데이터가 남아있는 상태에서 새로운 파드를 다시 볼륨에 연결했을 때 이전의 데이터에 의해 오류가 나는 경우가 있다. 따라서 이런 경우에는 반드시 볼륨까지 지우고 나서 새로 파드를 생성해야 한다.
kubectl delete pvc --all # 남아있는 볼륨(pvc) 모두 삭제 DB이중화
- 단순하게 스테이트풀셋을 이용하여 파드 두개(DB 서버) 생성하고 각각 pvc연결 해주어서 동일한 볼륨을 바라보게 하면
프라이머리 db와 secondary db가 같은 볼륨을 가리키므로 동기화가 되어서 DB이중화 구성이 될것이라고 생각하겠지만 잘못된 생각이다. 아래의 실습을 통해 DB이중화를 구현해 볼 것이다.
1 . 컨피그맵 구성
apiVersion: v1
kind: ConfigMap
metadata:
name: mydb-config
labels:
app: mydb
app.kubernetes.io/name: mydb
data:
primary.cnf: |
[mysqld]
log-bin
replica.cnf: |
[mysqld]
super-read-only 2 . 읽기위한 서비스 구성
apiVersion: v1
kind: Service
metadata:
name: mydb-read
labels:
app: mydb
app.kubernetes.io/name: mydb
spec:
ports:
- name: mysql
port: 3306
selector:
app: mydb
app.kubernetes.io/name: mysql3 . 쓰기위한 서비스 구성
apiVersion: v1
kind: Service
metadata:
name: mydb
labels:
app: mydb
app.kubernetes.io/name: mydb
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mydb
app.kubernetes.io/name: mydb4 . 스테이트풀셋으로 파드(DB서버) 생성
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mydb
spec:
selector:
matchLabels:
app: mydb
app.kubernetes.io/name: mydb
serviceName: mydb
replicas: 2
template:
metadata:
labels:
app: mydb
app.kubernetes.io/name: mydb
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
[[ -d /var/lib/mysql/mysql ]] && exit 0
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
ncat --recv-only mydb-$(($ordinal-1)).mydb 3307 | xbstream -x -C /var/lib/mysql
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup # primary와 replica를 동기화
image: gcr.io/google-samples/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mydb-0.mydb', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
mv change_master_to.sql.in change_master_to.sql.orig
fi
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mydb-config
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi5 . 결과 확인
kubectl run dbclient --image ghcr.io/c1t1d0s7/network-multitool -it --rm
# 가상의 클라이언트 파드 생성 및 접속
mysql -h mydb-0.mydb -u root -p
# 클라이언트가 원격으로 프라이머리 DB서버(파드)에 접속
# 원격 접속은 -h옵션 사용
CREATE DATABASE mydb
CREATE TABLE mydb.mytb (message VARCHAR(100))
INSERT INTO mydb.mytb VALUES ("hello workd")
# DB생성 및 데이터 입력
mysql -h mydb-1.mydb -u root -e 'SELECT * FROM mydb.mytb'
# 클라이언트가 원격으로 세컨더리 DB서버(파드)에 EXEC명령으로 테이블에 저장된 데이터 출력-> 프라이머리와 세컨더리 DB가 동기화 되어있기 때문에 프라이머리에서 입력했던 데이터가 세컨더리에 저장되어있는 것을 확인할 수 있다.
