데이터베이스는 관계형,비관계형 데이터베이스 두가지가 있다. 이번 포스팅에서는 관계형 데이터베이스에 대해서 다루어 볼 예정이다.
관계형 데이터베이스
최소 하나 이상의 테이블을 가지고있고 테이블은 Columns과 rows로 이루어져있다.칼럼은 속성, 로우는 레코드로 보면 될거같다. 칼럼은 순서에 따라 조직화되고 이러한 순서가 결국 구조화를 이루는 것이다. 이 순서안에서 속성 간 관계를 알 수 있고 따라서 우리는 SQL(Structured Query Language)라 부른다.순서,즉 관계가 구조화 되어있기 때문에 저장 및 관리 작업이 쉬워지고 복잡하고 임의적인 쿼리도 가능하다.
- OLTP : Online Transaction Processing, 빈번한 읽기 및 쓰기 작업이 요구되는 애플리케이션에 적합하며, 접근 중심의 작업에 용이하다. 따라서 대용량에 데이터에 신속한 접근을 위해 높은 수준의 메모리 용량을 지닌다.
- OLAP : Online Analytics Processing, 복잡한 쿼리 작업에 적합하며 높은 수준의 컴퓨트 및 스토리지 성능이 요구된다.
RDS
Amazon Relational Database Service, 관리형 데이터베이스 서비스로 클라우드 기반 관계형 데이터베이스다. 쉽게 말해 AWS에서 지원하는 관계형 데이터베이스라 생각하면 된다. AWS에서 지원하는 서비스로서 초기설정, 백업, 고가용성 유지, 패치 등의 작업을 사용자가 하지않아도 자동으로 해준다. 복원, 데이터 복구, 확장등의 업무도 자동 수행된다.
💡 5분마다 주기적으로 스냅샷을 생성해주며, replica에 대한 자동확장도 자동으로 수행해준다.
DB엔진
데이터베이스에 데이터를 저장,조직화,인출하는 소프트웨어이며,각 데이터베이스 인스턴스는 오직 하나의 엔진만 실행한다.
AWS는 6개의 엔진을 제공한다.
MYSQL
- 블로그,커머스 등 OLTP애플리케이션에 적합하며 ,스토리지엔진으로 InnoDB를 사용한다.
MariaDB
- MYSQL이 Oracle에 인수되면서 개방성 및 사용성에 제약이 생길 것을 우려해서 만든 MYSQL대체품이며, InnoDB사용을 권장한다.
Oracle
- 가장 널리사용 되는 DBMS로서,일부 애플리케이션은 오직 ORACLE 데이터베이스 기반으로만 실행된다.
PostgreSQL
- ORACLE 호환 오픈소스 데이터베이스며,ORACLE용으로 개발된 내부용 애플리케이션을 좀 더 저렴하게 실행가능하게 해준다.
Aurora
- Amazon에서 제공하는 MYSQL,PostgreSQL의 대체품으로서 스토리지의 쓰기 횟수를 감소시키는 가상화 스토리지 레이어를 이용해 좀 더 높은 수준의 쓰기 성능 제공. PostgreSQL과 MYSQL엔진 두개를 지원한다.
Microsoft SQL server
- RDS는 2012년부터 현재까지의 Microsoft SQL Server버전을 지원하며, EXPRESS,Web,Standard,Enterprise에디션 중 선택가능하다.
라이선스 계약
-
라이선스 포함 모델 : 인스턴스 사용료에 라이선스 비를 포함 한것으로 모든 엔진이 선택 가능하다.
-
자체 보유 라이선스 모델(BYOL) : 사용자가 엔진 실행에 필요한 라이선스를 직접 확보하도록 하는것으로 오직 ORACLE엔진만 선택 가능하다.
DB 인스턴스 클래스
RDS는 성능 요구 수준에 맞춰 다양한 DB인스턴스 타입을 제공한다. 일단 실행 후 성능 요구수준이 변경되면 이 타입을 변경 할 수 있다. 총 세가지 클래스가 있다.
-
스탠다드 DB인스턴스 : 대부분 사용자의 DB에 대한 요구 수준을 맞춘 클래스, db.m5가 대표적이다.
-
메모리 최적화 DB인스턴스 : 메모리에 훨씬 더 데이터를 많이 저장할 수 있도록 높은 메모리 성능을 가진 클래스, db.x1e가 대표적이다.
📌 내부 전용 고속 네트워크로 EBS 스토리지와 연결된다. -
성능 가속 DB인스턴스 : 개발,테스트,비상용화를 고려한 DB인스턴스이며 클래스, db.t3가 대표적이다.
수직적 확장/수평적 확장 (성능 향상)
-
수직적 확장 : 스케일업 이라고 부르며, DB는 그대로 둔 채 관련된 리소스만 추가하는 방법
-
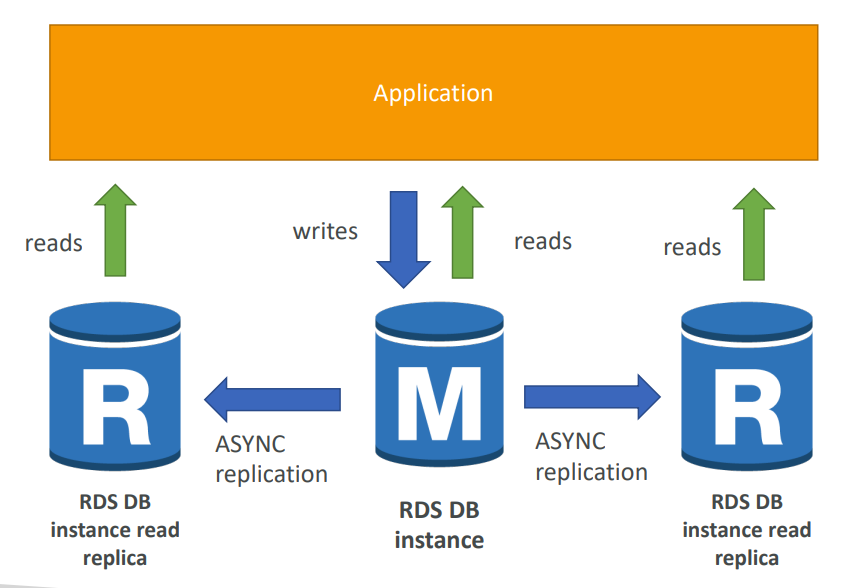
수평적 확장 : 스케일 아웃 OR 💡Replica 라고 부르며 , 인스턴스를 추가하는 방법이다.
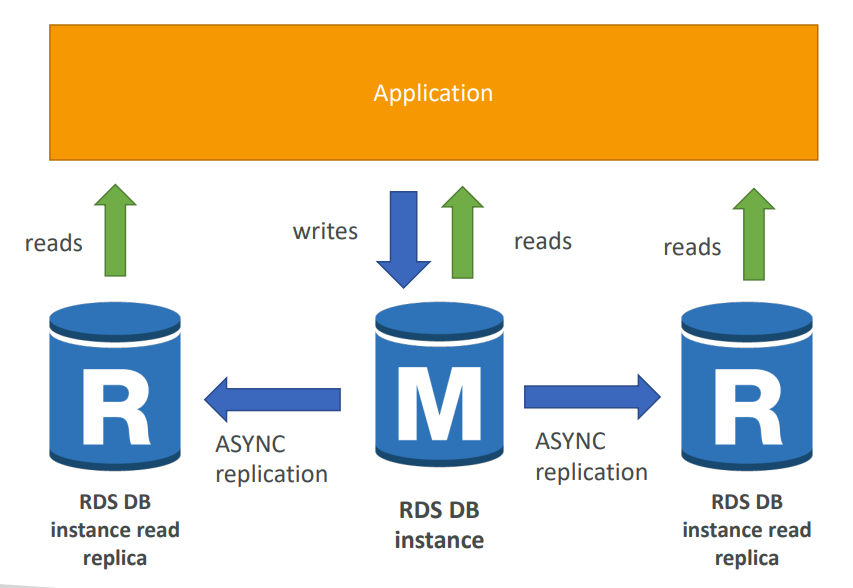
Aurora를 제외한 나머지 엔진은 5개의 replica를 지원하고 Aurora는 15개의 replica를 지원한다.
💡 USE CASE : 읽기 집약적인 워크로드,대규모의 쿼리, I/O작업이 많을 때 성능 향상을 위해 사용한다.EX ) 읽기 집약적인 쿼리를 하고 있는 보고서가 있을 때 Replica를 여러개 배포하고 리더 엔드포인트를 보고서에 연결하면, 보고서의 읽기 작업을 여러 곳으로 분산시켜서 작업할 수 있고, 현재 DB는 쓰기 작업에 좀 더 집중할 수 있다. 따라서 I/O성능이 향상되고, 트래픽의 과부하를 해결 할 수 있다.
📌 REPLICA는 AZ내 여러곳 , 리전 내 여러 AZ, 크로스 리전에 모두 배포가능하다.
📌 프라이머리 DB와 비동기적으로 데이터를 복제하기 때문에 데이터의 유실가능성이 있다.
📌Aurora는 다른 엔진보다 replica의 복제지연시간이 빠르다. (1초미만)
멀티 AZ (재해복구)
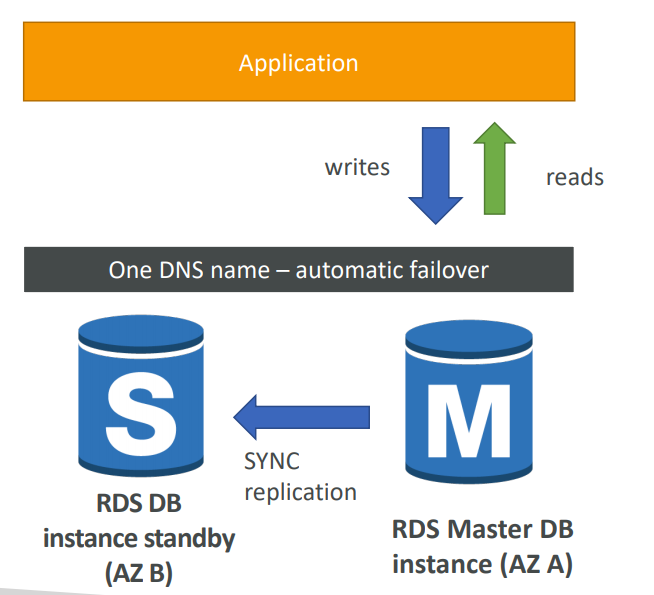
현재 리전에서 가동하고있는 DB인스턴스를 프라이머리 인스턴스라 한다. 이 인스턴스가 재해가 발생했을 때 멀티 AZ배포를 통해 복원력을 높일 수 있다.
aurora를 제외한 5개의 엔진
재해가 발생하면 다른 AZ에 배포한 대기 인스턴스를 CNAME(DB인스턴스의 정식 레코드 명칭)이 가르키도록 하여 대기 인스턴스를 프라이머리 인스턴스로 승격시키므로서 재해 복구를 한다.
📌 현재 다른 AZ에 최대 두개까지 대기 인스턴스를 배포할 수 있다.
📌 대기 인스턴스는 프라이머리 인스턴스를 동기적으로 복제하기 때문에 데이터가 유실되지않는다. 그냥 프라이머리 인스턴스와 똑같은 기능을 수행하는 인스턴스라 생각하면 된다.
Aurora
Aurora는 두가지 방식으로 재해복구를 한다.
또한 대기 인스턴스가 아닌 기존에 배포한 replica를 통해서 재해복구를 수행한다.
- 싱글 마스터 : 재해복구가 발생하면 프라이머리 인스터스의 엔드포인트를 가리키고 있는 replica를 프라이머리로 승격시킨다. 만약 replica가 존재하지않다면, 새 프라이머리 인스턴스를 생성한다.
- 멀티 마스터 : Replica를 포함한 모든 인스턴스가 DB를 기록할 수 있으며, 별도의 페일오버 작업이 없다. 쉽게 모든 인스턴스가 하나의 DB를 공유하면 기록한다고 생각하면 된다.
📌 기록하는 하나의 인스턴스가 실패해도 다른 인스턴스가 기록하면 되기때문에 💡지속적 가용성이라 부른다.
세가지 크로스리전 페일오버 방식
- 스냅샷을 이용한 페일오버
재해가 발생하면 다른 리전에 미리 만들어둔 스냅샷을 복제해서 이 스냅샷을 통해서 페일오버한다.
📌 RTO(목표 복구 시간) , RPO(목표 복구시점)가 매우 느리다. - 싱글 마스터/멀티마스터
다른 리전에 배포해둔 Replica를 프라이머리로 승격시켜 페일 오버 한다.
📌 RTO(목표 복구 시간) , RPO(목표 복구시점)가 빠르다.
📌 글로벌데이터베이스와 비교해 논리적 단위라고 생각하면 된다. - Aurora 글로벌데이터베이스
여러 리전에 걸쳐있는 DB라 생각하자.
걸쳐 있는 한 리전에 재해가 발생하면 걸쳐 있는 다른 리전으로 빠르게 페일 오버 한다.
📌싱글마스터/멀티마스터와 비교해 물리적 단위라고 생각하면 된다.
💡 가장 추천하는 방법이자 가장 빠르다.
DMS
기존 DB와 스키마를 자동으로 복사해서 다른 데이터베이스에 저장할 수 있게 해준다. 엔진이 다르거나 관계형/비관계형이 달라도 마이그레이션이 가능하다.
USE CASE : 온프레미스 환경에 있는 DB,S3에 있는 데이터를 AWS환경에 있는 DB,S3를 대상으로 마이그레이션 할 때
💡 만약 엔진이 다르다면, Schema Conversion Tool을 이용해 스키마를 동일하게 맞춘 후 DMS 가능하다.
마치며
지금까지 관계형 데이터베이스에 대해 포스팅해보았다. 가장 중요한 것은 성능향상이 목적이라면 REPLICA를, 가용성 향상이 목적이라면 멀티AZ를 고려한 후 요구사항에 맞게 세부사항을 설정하는 것이라 생각한다. 다음 포스팅에서는 비관계형 DB에 대해서 다루어 볼 예정이다.
