Phrase Retrieval in ODQA
Current limitation of Retriever-Reader ODQA
- Error propagation
- Reader가 아무리 뛰어나도 Retreiver가 제대로 된 context를 전달하지 못한다면 전체 프로세스의 성능이 떨어진다.
- Query-dependent encdoing
- query에 따라 answer span의 encoding이 달라진다.
- e.g., BERT retriever를 사용할 때 query와 context를 concat해서 모델의 결과를 얻기 때문에 query가 달라지면
- context와 concat된 embedding의 encoding을 매번 다시 해야한다.
- encoding 결과도 매번 달라진다.
Retriever-Reader 단계를 거치지않으면서 이러한 문제점들을 해결할 수 있는 방법론으로 제시된 것이 phrase retrieval이다.
Solution
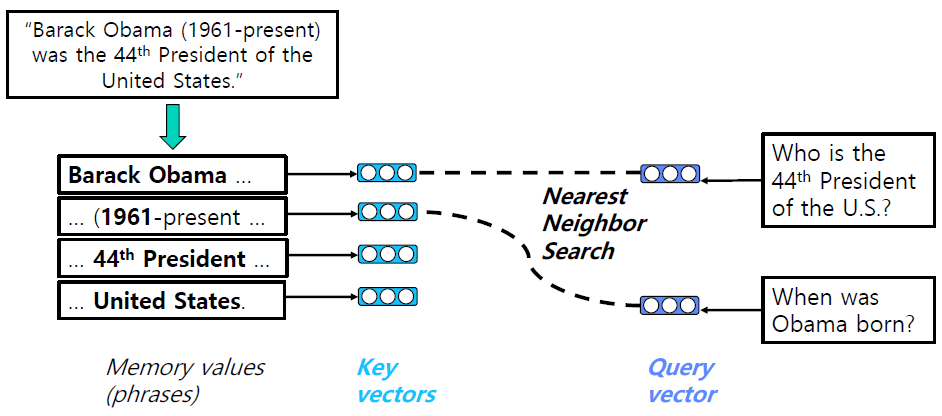
1. Context의 모든 phrase들을 enumeration(열거)한다.
2. phrase에 대한 embedding vector를 key로 하여 mapping한다.
3. query vector는 query가 들어올 때마다 계산.
4. queyr와 key vector를 비교하는 문제로 치환.
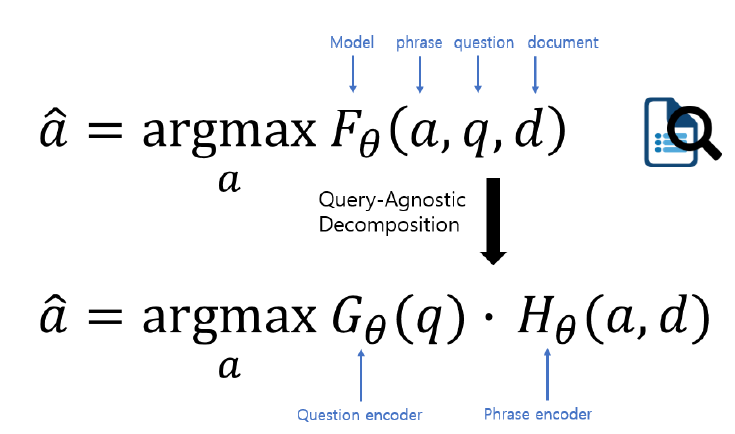
학습과정을 비교
- 기존의 방법
- phrase, question, document를 score 함수에 넣어서 모든 score 조합을 구한다.
- Retriever-Reader를 F라는 함수 하나로 표현한 것.
- F는 a(answer candidates), d, q를 넣으면 알아서 예측된 answer를 도출한다.
- query가 달라질 때마다 score 함수를 다시 계산해야한다.
- Phrase retrieval
- F 대신 Question encoder와 Pharse encoder의 조합으로 score 계산.
- H: a, d를 입력으로 받아 vector space로 보내고 이들간의 가장 유사한 vector를 찾는다. 내적을 하든, 거리 계산을 하든.
- H 함수의 결과들은 미리 모두 계산됨.
- 따라서 query의 입력이 발생할 때마다 Q함수만 계산하면 된다.
- 문제점
- F를 G, H로 분해할 수 있다는 가정 자체가 틀릴 수 있다.
- F를 수학적으로 분리하는 것이 아니라, G와 H를 정의하고 이것이 F를 최대한 근사하도록 노력하자.
Key Challenge
어떻게 phrase를 vector 상에 잘 mapping할 것인가?
-> Dense, sparse embedding을 둘 다 사용해보자.
Dense-sparse representation for Phrase
- Dense vectors: 통사적, 의미적 정보를 얻는데 효과적
- Sparse vectors: 어휘적 정보를 담는데 효과적
Concat
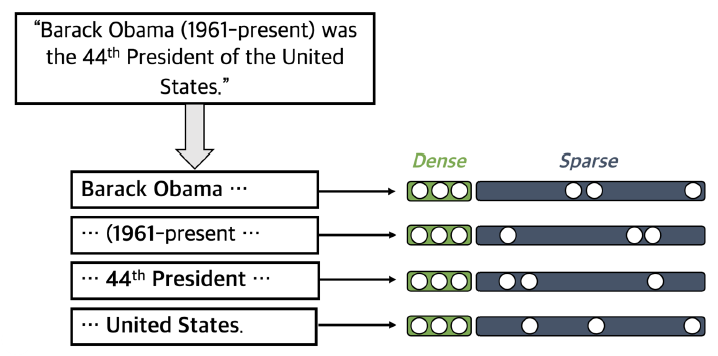
두 가지 방법을 합치는 방법은 phrase ODQA를 진행할 때, phrase 별로 dense, sparse embedding을 통해서 vector를 구하고 이를 concat하는 것이다.
Dense representation
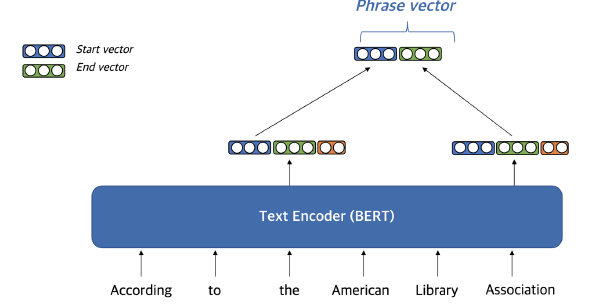
answer span의 start, end token에 해당하는 hidden state vector를 통해 phrase vector(dense vector)를 생성한다.
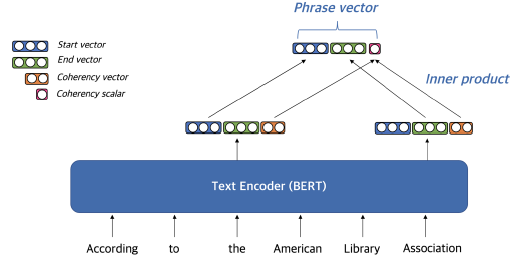
cohrency vector
- phrase가 문장 구성 요소에 해당하는지 나타낸다.
- 구를 형성하지 않는 phrase를 걸러내기 위해 사용
- start vector, end vector를 통해 계산
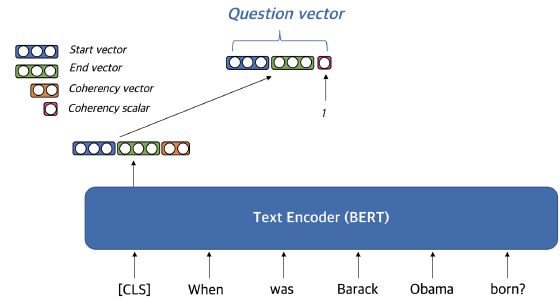
Question embedding - CLS token으로 생성
- 일반적인 문서 embedding과 동일
Sparse representation
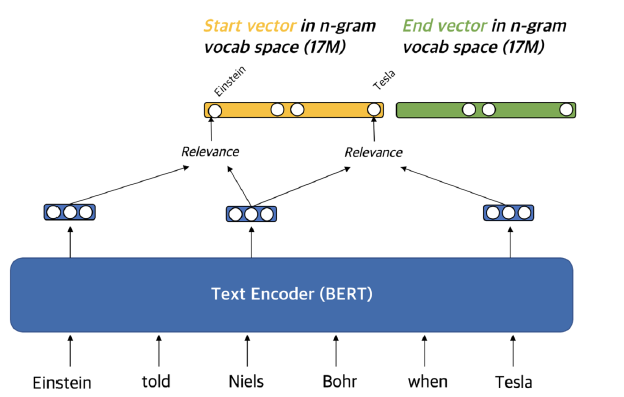
contextualized(문맥화된) embedding 활용해서 가장 관련성이 높은 n-gram으로 sparse vector 구성.
1. target으로 하고 있는 phrase의 주변 단어들과 유사성을 측정
2. 유사성을 각 단어에 해당하는 sparse vector에 넣어준다.
- TF-IFD와 유사하다. 다른 점은 phrase, sentence마다 weight가 dynamic하게 변한다.
- unigram, bigram도 활용해서 겹치는 정보들을 활용 가능
Scalability Challenge
wikipeida 데이터를 활용하면 보통 60bilion개의 phrase를 활용하게 된다. 이러한 거대 데이터에 접근해 indexing, searching을 하기 위해서는 scalability가 고려되어야 한다.
- storage: pointer, filter, scalar quantization 등을 통해 (240TB를 1.4TB까지 줄일 수 있다)
- search: FAISS 활용
- FAISS는 dense vector만 검색 가능하고 sparse vector는 검색 불가능.
- Phrase ODQA를 통해 Dense vector와 sparse vector를 합칠 것이므로, dense vector를 우선 검색해본다.
- sparse vector에 대해서 다시 score를 측정해 FAISS 검색 결과를 reranking
Results & Analysis
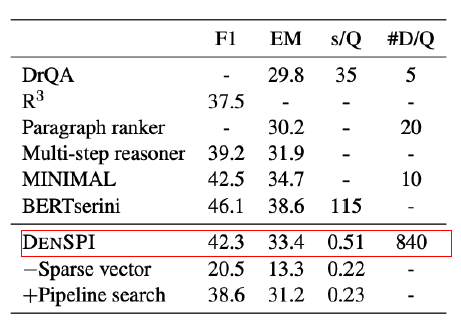
SQuAD에서 DrQA(Retreier-reader)보다 3.6% 성능향상이 있고, inference speed는 68배 빨랐다고 한다.

다른 Retriever-Reader보다 속도가 빨랐다. 또한 CPU 연산에 의존하기 때문에 GPU 연산이 필요없다는 장점 아닌 장점도 있다.
Limitation
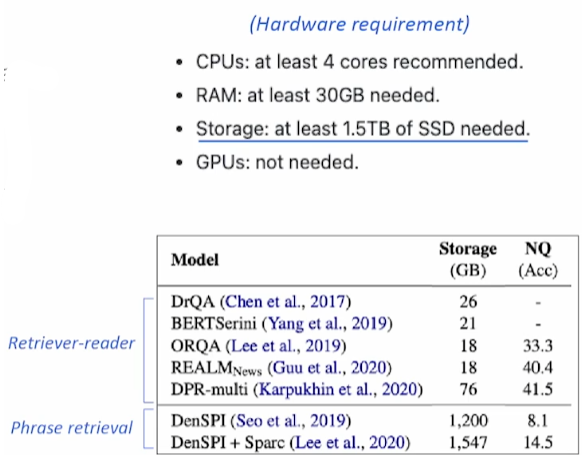
- RAM 용량이 많이 필요하다.
- 최신 Retriever-Reader 모델들 보다 성능이 낮다
- Natural Questions에서 성능이 낮았다.
- Decomposability gap(F 함수를 G, H로 분리)이 원인
Decomposability gap
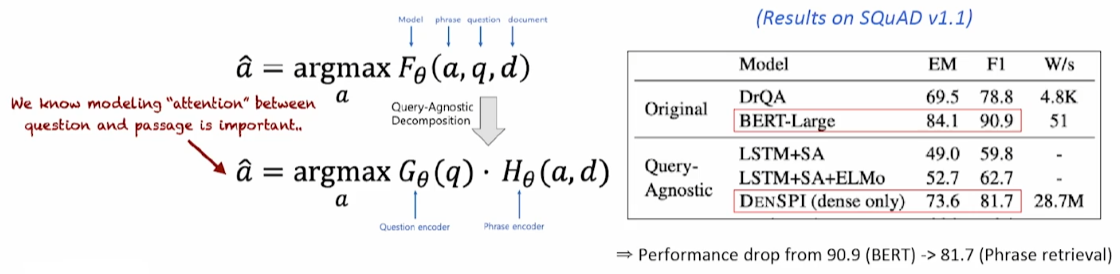
G, H를 통해 F를 근사하는 것 자체가 오류가 발생할 수 있다. 왜냐하면 F는 매우 복잡한 Retrieval-Reader를 나타내는 함수이기 때문이다. 따라서 필연적으로 G와 H를 통해 F를 근사하는게 정확하지 않다는 것이다.
