Passage retrieal and Similarity Search
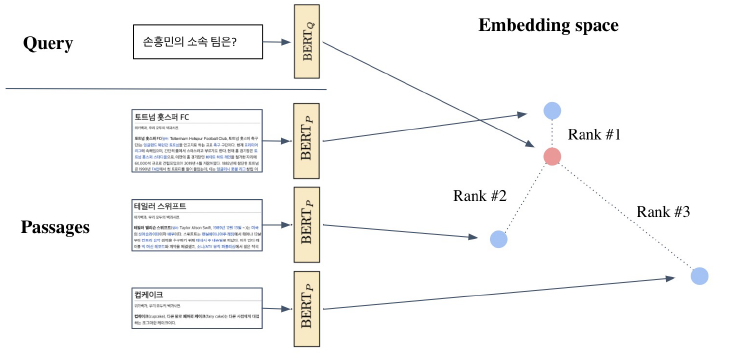
Passage와 query를 encoding해서 vector space로 보냈다면 아래의 방법들 중 하나를 수행한다.
- nearest neighborhood search
- inner dot production에서 highest dot product 결과만 search
위와 같이 similarity serach를 진행할 때, Passage의 수가 늘어난다면 query에 대해서 가장 similarity가 높은 passage를 찾는 것은 어려울 수도 있다. passage의 수가 수천만개가 된다면 brute force로 모든 경우의 수에 대한 inner product를 구하는 것조차도 매우 많은 cost가 들기 때문이다.
Nearest neighbor search
eucliden distance나 L2를 통해서 query vector와 가장 가까운 거리의 passage vector를 찾을 수 있다. 하지만 계산의 효율성을 고려하면 보통 inner dot product를 해서 similarity를 찾게 된다.
MIPS
Maximum Inner Product Search
개의 passage에 대해서 모든 inner product를 수행하면 되는 간단한 방법론이다. 문제는 passage가 매우 많을 때, 효율적으로 계산하는 방법론을 찾는 것이다.
실제로 검색해야 될 문서는 위키피디아를 기준으로는 약 5백만개이고, task에 따라서는 수십억, 조까지 늘어날 수도 있다. 이는 document 단위이고 passage를 paragraph 단위로 고려한다면 검색 대상은 더욱 늘어날 것이다.
즉, 모든 문서의 embedding을 brute force하게 검색할 수 없다.
Threshold of similarity search
- Serach speed
- query 당 유사한 passage vector k개를 찾는데 얼마나 걸리는지?
- Memory Usage
- Vector space 상의 모든 vector들이 어디에 저장될 것인지?
- 모두 RAM에 있다면 편하겠지만 사실상 불가능
- 모두 HDD에 있다면 매우 느릴 것
- Accuracy
- brute-force가 아니라면 accuracy를 희생해야 할 것인데 어느 정도까지 희생할 것인가?
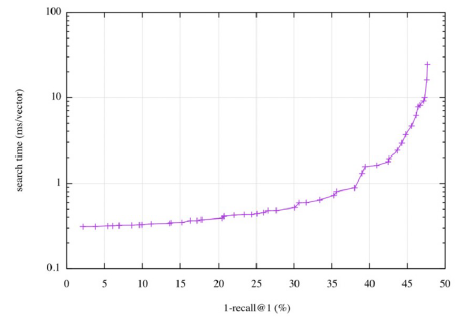
serach time과 recall은 보통 비례하게 된다. 즉, 정확한 검색을 위해서는 더 오랜 시간이 소몬된다.
이러한 threshold들에서 나타나는 문제들은 corpus의 크기가 커질수록 아래와 같이 구체화된다.
- 탐색 공간이 늘어나므로 검색이 어려워진다.
- 더 많은 memory space가 요구
- Sparse Embedding은 해당 문제가 더욱 심화
- compression으로 어느 정도 해소 가능

dimension = 768 일 때, 위키피디아 문서 수 정도인 10억개의 문서가 존재한다고 가정하면 필요하면 memory space는 3TB이다. 1조가 넘어가면 3PB이다.
대부분의 대회나 연습용 코드들에서 사용하는 corpus들이 miilion 단위라고 할지라도 3GB도 매우 크다.. compression을 통해 memory space를 효율적으로 사용하는 것은 필수적이다.
Approximating Similarity Search
Compression - SQ
Scalar Quantization.
통상적으로 4byte(int) size를 사용해서 vector를 표현한다. 하지만 실제로 4byte를 모두 사용하진 않는다. 따라서 사용되는 byte를 줄여서 vector 자체르 압축하는데, 이를 SQ라고 한다.
e.g.,) 4byte flaoting point -> 1byte unsigned integer
Pruning - IVF
Pruning(가지치기). Passgae retrieval에서는 clustering을 통해 cluster(군집) 형성함을 의미.
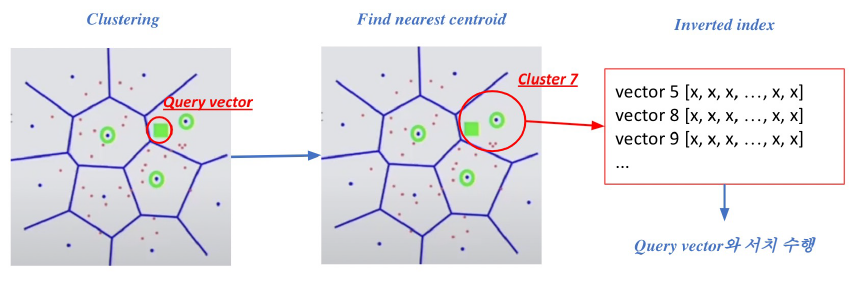
clustering이 잘 됐다면, MIPS를 매우 효율적으로 수행할 수 있다. 전체 데이터에 대해 brute-force해야 되는 문제를 cluster 개수 k보다 적은 m개의 인접한 cluster만 방문하는 문제로 변경할 수 있기 때문이다.
IVF(Inverted file). 검색해보니 Inverted index를 의미하는 것이다. https://cloudingdata.tistory.com/45
Retreival에서의 IVF는 cluster의 대표 vector인 centroid의 id에 해당 cluster의 모든 vector id르 가지고 있음을 의미한다. 즉, query에 가장 근접한 cluster centroid id를 찾는다면 빠르게 해당 cluster의 모든 vector들과 비교 연산이 가능하다.
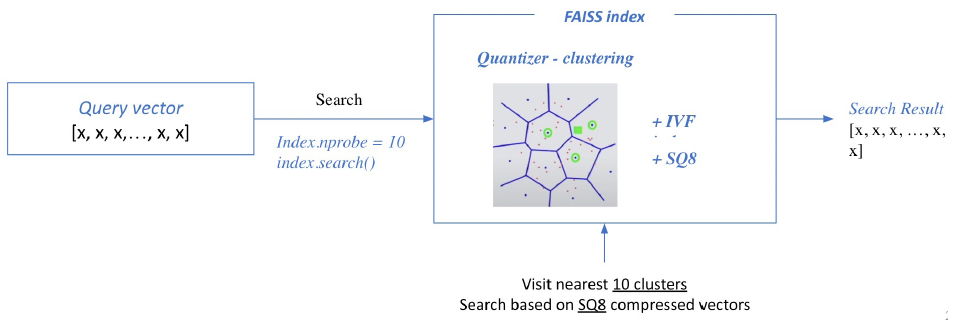
FAISS
Facebook에서 similarity search, clustering을 위해 만든 라이브러리다. 오픈소스다. large scale에 특화돼있고 C++로 만들어졌지만 python으로 wrapping되서 매우 빠르고 쓰기도 쉽다!
How to use
Train index and map vectors
- clustering
- passage의 clustering을 위해서 passage 데이터에 대한 학습이 필요하다.
- Scalar quantization
- 4byte floating point를 1byte integer로 변환할 때, 데이터의 max, min을 파악하고 변환한다.
- 보통 train data로 학습하지만 학습의 효율성을 위해서 train data에서 sampling해서 FAISS train data로 사용한다. origin train data가 크다면 1/40 정도로 sampling하기도 한다.
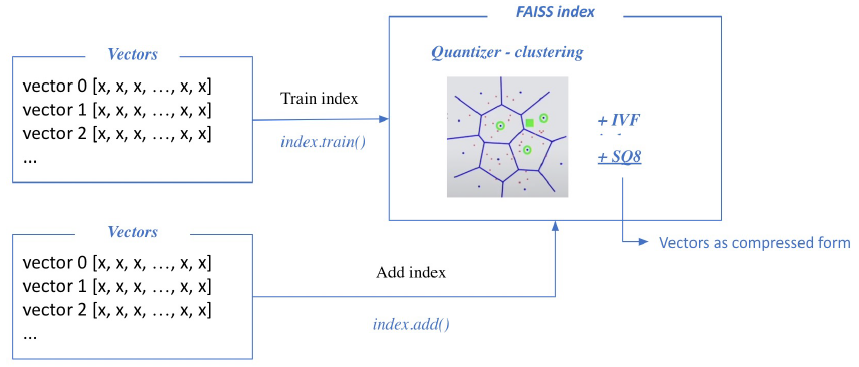
trian을 통해 cluster와 SQ 범위 정의되면 train data를 cluster에 SQ대로 투입.
Search based on FAISS index
- query가 들어온다면 train에서 정의한 cluster, SQ rule에 따라서 query를 reformat.
- 가장 가까운 cluster를 찾는다.
- cluster nearest top-k를 정한다.
Product Quantization
ref blog
실제로는 SQ말고 PQ를 많이 쓰기도 한다. SQ보다 compression을 더 잘한다고 한다.
