Convolution
수식으로
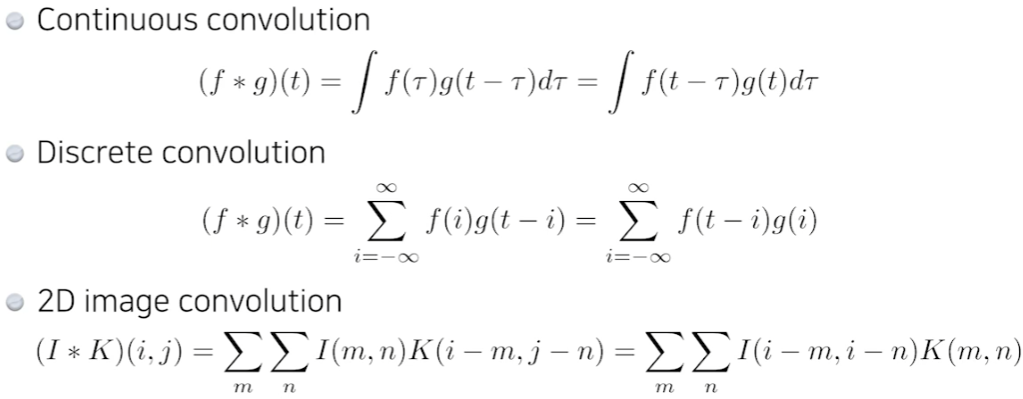
역할
원하는 feature를 뽑을 수 있다.
가령, 모든 kernel의 값이 1/9인 (3,3) kernel을 사용했다고 하자. 그러면 평균을 구하는 convolution 연산이 된다.
tensor
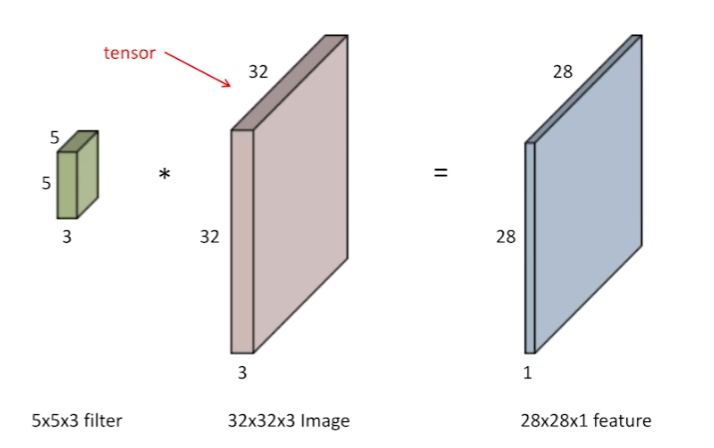
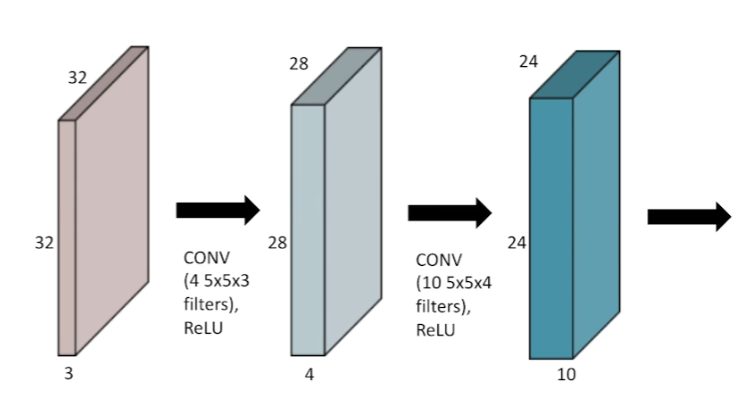
channel이 3개인 RGB이미지를 가정해보자. 이 이미지에 (5,5) filter를 적용한다고 하면, 3개의 channel을 가진 filter를 적용한다고 생각하면 된다.
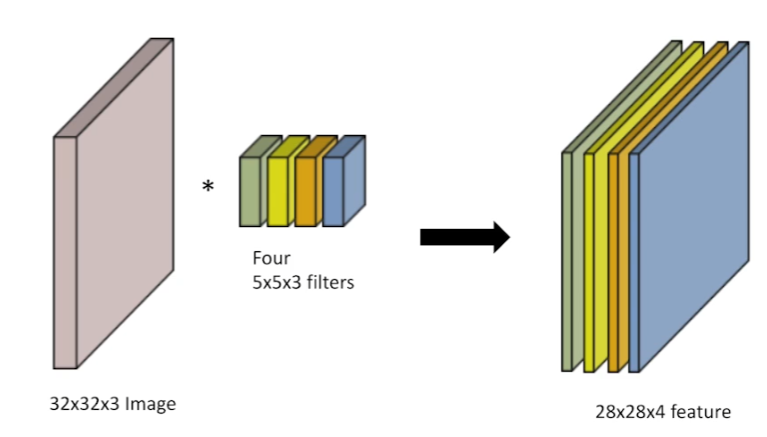
가령, 위와 같이 RGB 이미지에 (5,5,3) filter를 4개 적용한다고 하면 channel이 1개인 (28,28) feature가 4개 나올 것이다.
Stack of convolution
MLP처럼 stack을 할 때 non linear function을 통과시켜서 쌓는다.
Convolution and Neural networks
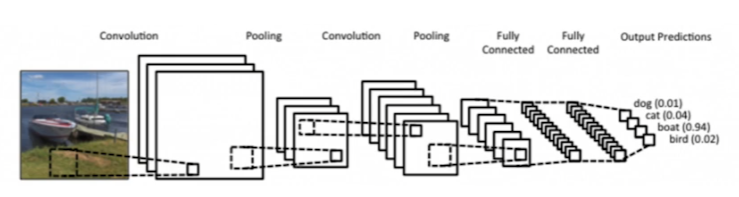
위 그림이 가장 고전적인 CNN이다.
Convolution and pooling layers: feature extraction
Fully connected layers: decision making(eg. classification, regression)
요즘은 Fully connected layer를 줄이는 추세이다.
왜냐하면 parameter의 수를 줄이기 위해서다. parameter 수가 많다면 학습이 어렵고 generalization performance가 떨어지기 때문이다.
Stride
kernel을 stride만큼 옮기면서 convolution 연산을 한다.
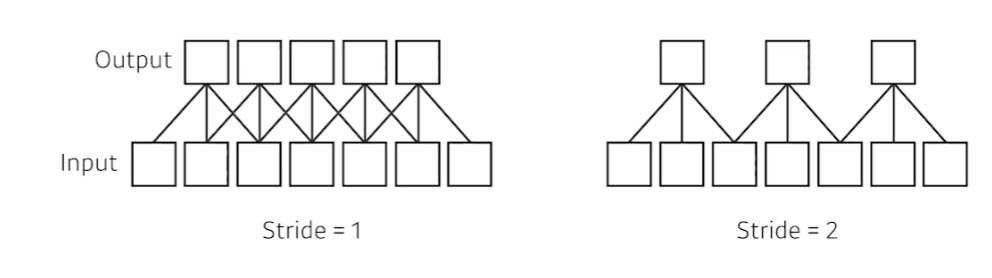
1d이기 때문에 stride의 값도 1d이다.
Padding
가장자리에 대해서는 convolution 연산이 불가능하다. 따라서, 임의의 값을 채워주고 이미지의 가장자리에 대해서 convolution 연산을 수행한다.
e.g., zero padding = 덧대는 부분을 0으로 채운다.
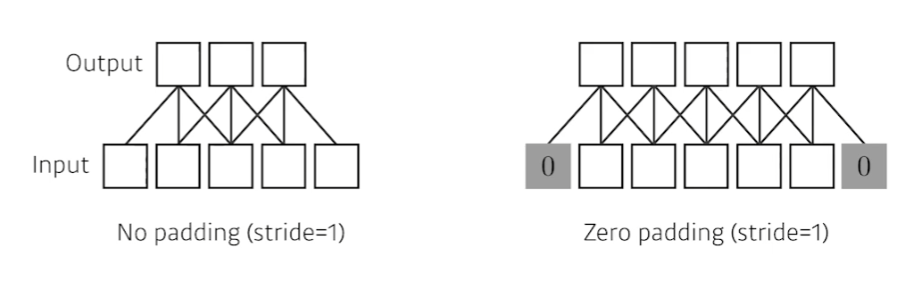
padding을 하면 input과 ouput의 spacial dimension을 맞출 수 있다.
Counting parameters
Convolution 연산의 parameters = kernel의 parameters
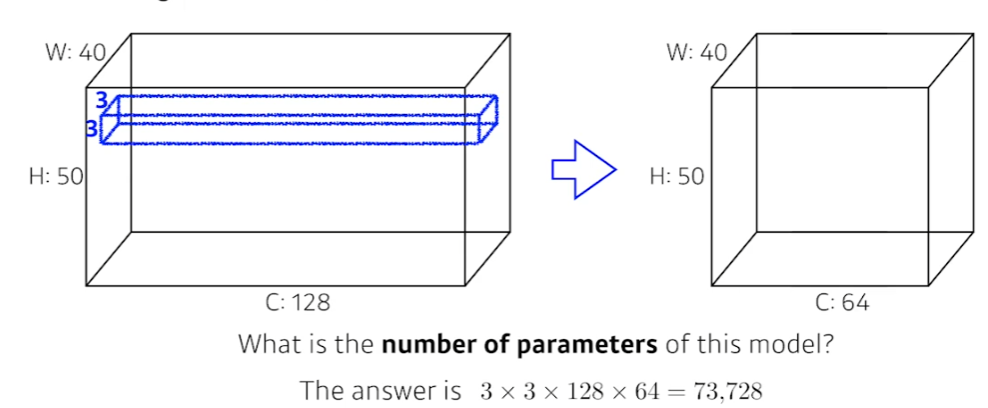
Padding(1), Stride(1), 3x3 kernel
- 3x3 kernel이라고 하지만, 앞서 서술했듯 kerenel의 channel은 input의 channel과 맞춰준다.
- 즉, (3,3,128) kenrel을 사용한다.
- 채널 수를 맞춰준 kernel과 input을 convolution하면 반드시 channel을 1개가 된다.
- output의 channel 수는 64이다.
- 따라서 (3,3,128) kernel이 64개 존재해야 한다.
이러한 과정을 통해서 대략적인 parameter의 수에 대해 감을 잡는 것은 중요하다!
Alexnet
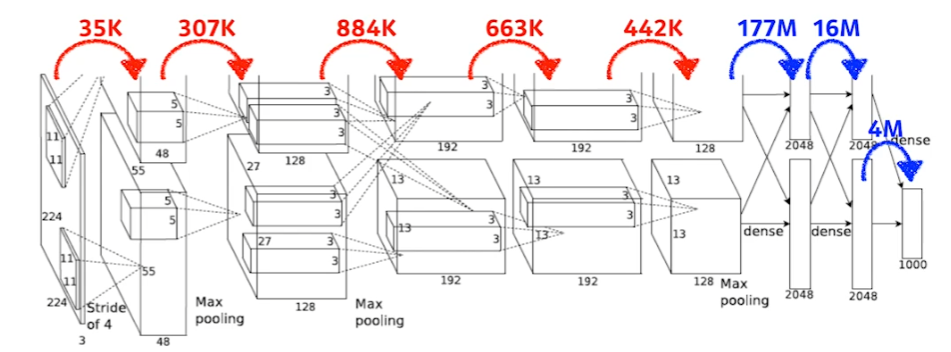
convolution 사이의 parameter 숫자와 dense layer 사이의 parameter 숫자가 매우 상이하다!!
이유는 아래와 같다.
- convolution은 어찌보면 같은 weight를 kernel이라는 요소를 통해서 공유한다.
- input 이미지의 어느 위치에 있는 요소든 상관없이 동일한 kernel을 사용한다.
- dense layer는 알고 있듯이 모든 node가 서로 다른 weight를 가지고 있다.
1x1 convolution
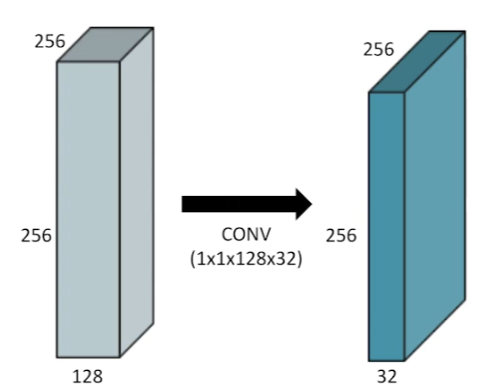
1x1 convolution은 영역을 볼 수 없다. 당연하다. 1x1의 영역에 대해서만 convolution 연산을 반복하는 kernel이기 때문이다.
하지만 아래와 같은 역할을 기대할 수 있다.
- channel(dimension) 감소
- depth가 증가할 때, parameter 감소를 기대
- e.g., bottleneck architecture
