약 1달 동안 Flask로 REST Api 개발을 진행하다 배포를 끝내고 나서 db 서버가 죽어버리는 일들을 자주 마주하게 되었다. 분명히 테스트 할 때는 잘 돌아갔는데 말이다...
Flask 어플리케이션에서 데이터베이스에 접근할 때는 SQLAlchemy를 사용하였다. 사용한 이유는 가장 많은 사람들이 사용하는 것 같고 쉬워 보여서 채택하게 되었다.
완벽하게 과정들을 이해하고 쓴 것이 아니라서 처음 오류를 마주했을 때 막막하기도 했지만 오류를 수정하면서 확실하게 배워간다는 느낌으로 진행하게 되었다.
마주한 오류
- 배포하기 전 테스트에서는 pool에 연결들도 잘 반납되었었다.
- 프런트에 api를 연결하였을 때
internal server error, 500이 나왔다. - 그럴 때마다 서버가 죽었고, db에서
show processlist로 보니까 21개의 connection이 있었고, 서버는 뻗어있었다. - 서버 상에서 로그를 봤을 때 토큰을 decode하는 미들웨에서 뭔가 문제가 있다고 생각했다.
Docker 컨테이너를 돌리고 있던 인스턴스가 죽어버린 상황...
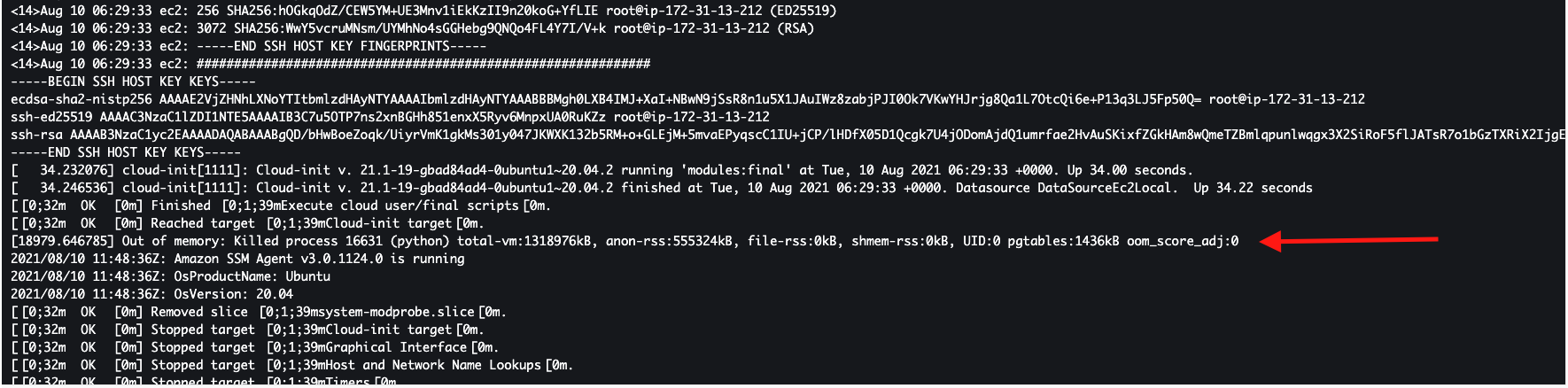
서버 로그에서 이러이러한 오류가 생겼다고 열변을 토하는 모습.
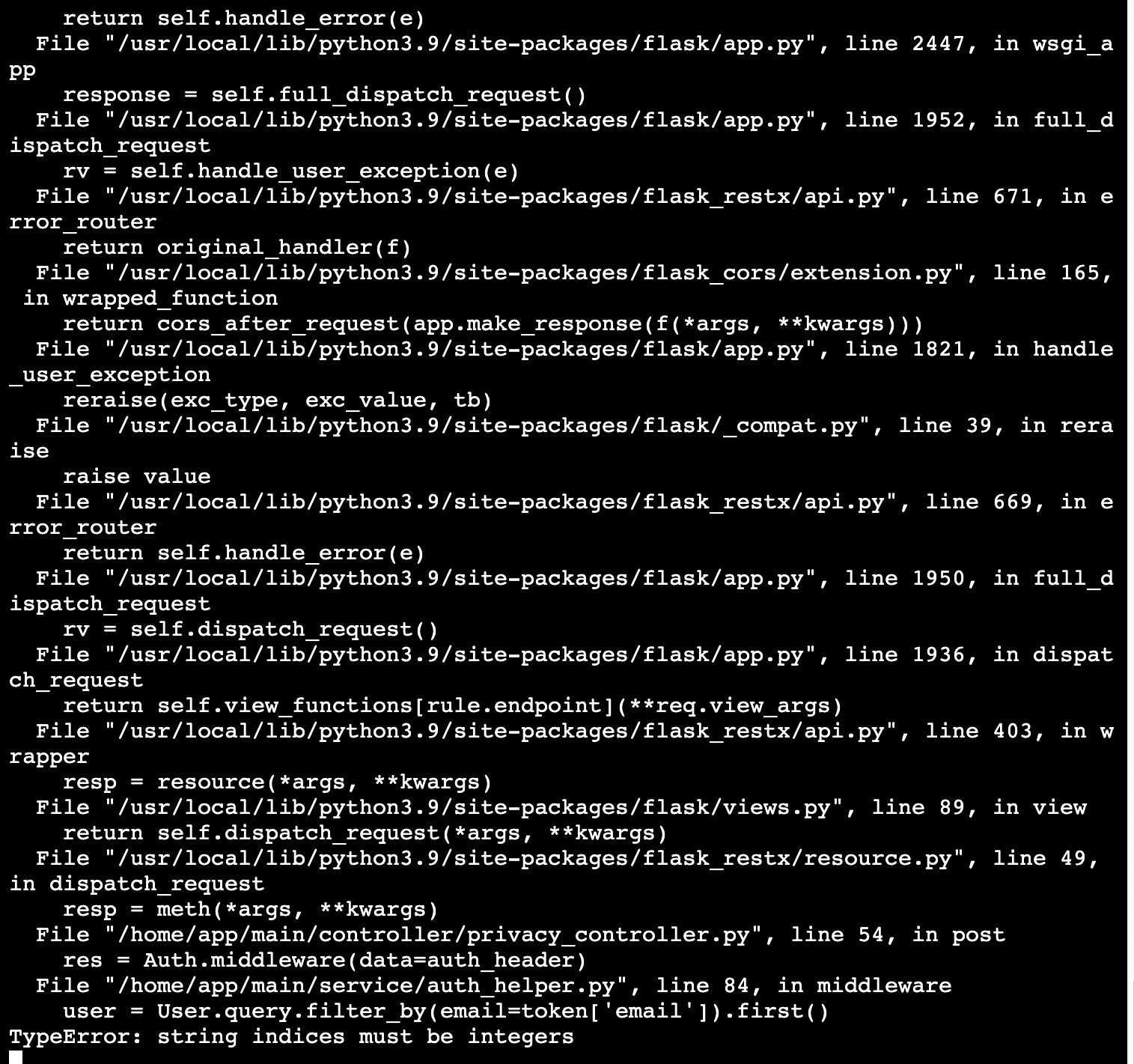
pool이 만원이라 새로운 요청을 입밴했던 모습.
사전 지식
왜 사용하나요?
connection pool은 연결이 요청 될 때마다 생성되는 것이 아니라 재사용됨을 의미한다.
쉽게 말해, 우리의 어플리케이션은 Flask api이고, MySQL db에 요청을 할 때 새 MySQL db 연결을 생성하고, 작업하고, 연결을 닫게 되는데, 모든 요청에 대해 연결을 생성하고, 연결을 닫는 과정을 반복되게 된다.
이 연결을 생성하고, 닫는 과정을 줄이기 위해 connection pool에 반납을 하게 되는 것이다. (캐싱 Caching)
큐 풀의 생애 주기
출처 : https://spoqa.github.io/2018/01/17/connection-pool-of-sqlalchemy.html
괄호 안의 상황은 제가 만든 어플리케이션에서의 상황입니다.
- 큐 풀이 처음부터 연결을 미리 만드는 것은 아닙니다. 일단 0개로 시작합니다.
- 요청이 들어올 때, 큐 풀에 유효 연결이 없으면 하나 생성합니다.
- 설정된
pool_size까지는 더 연결이 필요하지 않은 상황이라도 연결을 종료하지 않습니다.
(sleep으로 유지되는 이유) - 요청이 들어올 때,
pool_size까지 다 찼다 할지라도 유효 연결이 없으면 초과하여 하나 생성합니다.
(max가 20이라 21까지 생기는 이유) - 4번 이후부터는 오버플로 상황이기 때문에, 큐 풀은 적극적으로 오버플로를 방지하기 위해 새로 들어오는 연결을 종료하여
pool_size에 총연결 수를 맞춥니다.
(pool에 connection이 꽉 찬 이후에 서버는 요청을 받을 수 없음.) QueuePool이 관리하는 연결이pool_size+max_overflow까지 다 찬 상황에서 요청이 들어오면, 일단 기다리게 합니다. 기본값으로는30초를 기다립니다.
(서버가 터지는 이유)- 30초를 기다려도 반환되는 연결이 없다면
TimeoutError예외를 발생시킵니다.
(front 단에서 axios 요청을 보내 5초가 지나도 응답이 오지 않으면 연결을 끊게 되는데 이 때 사용자가 동일한 요청을 계속 보내면 예외가 계속 생성되는데 리턴을 30초동안 못 보내다가 그 이후에 리턴을 우다다다 하면서 서버 펑)
해결방법?
해결 방법은 다음과 같이 세웠다.
- 우선 현재 코드를 분석해서 현재 상태를 파악
- 모르는 부분 + 애매한 부분들을 검색해서 이해
- 그에 따른 해결책 세우기
문제 살펴보기
SQLAlchemy config 세팅값부터 보기로 했다. config는 다음과 같다.

flask 공식 문서 참고
flask-sqlalchemy-config

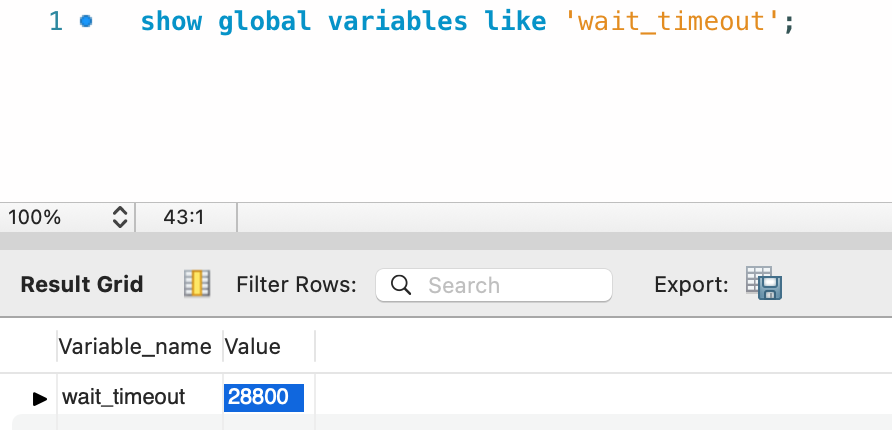
현재 서버에 정의된 timeout = 28800(8시간)
SQLAlchemy에서 default로 정의된 max_overflow = 10.
SQLAlchemy 공식 문서 참고
SQLAlchemy 1.4 Documentation


max_overflow-pool_size보다overflow될 수 있는 최대 개수.- 추가 connection이 pool_size로 넘어올 경우, 연결이 끊기며 거부된다.
- 'sleeping' connection은 pool_size를 넘지 않으며, 추가 요청의 개수는 pool_size + max_overflow를 따른다.
- max_overflow는 -1로 세팅될수 있으며, overflow limit이 없다는 뜻이다. (무한대)
정리
-
pool size = 20
최대 20개의 세션 연결 가능 -
pool recycle = 3600
pool에 세션을 끊지 않고 유지하는 시간 = 1시간 -
mysql 에 적용된 wait_timeout = 28800
활동하지 않는 커넥션을 끊을때까지 서버가 대기하는 시간 = 8시간.
그러나 위의 recycle이 3600이므로 1시간마다 갱신 -
max_overflow = 10 (default)
커넥션 요청 20 + 10개까지는 'sleep'되어있는 session이 사라지기를 기다림.
솔루션
- 제대로 세션을 반납시키자.
- config값을 변경하자.
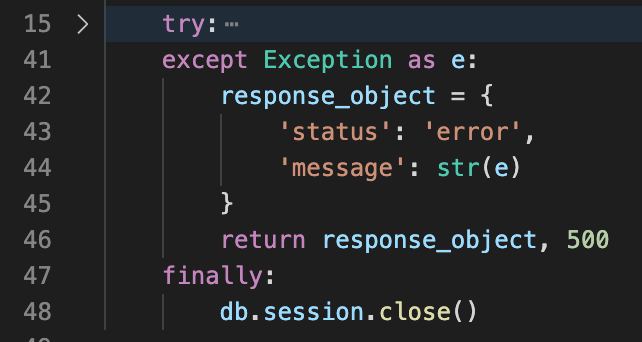
세션 반납
프런트 단에서 요청을 할 경우 에러 핸들링이 제대로 되어 있지 않은 경우가 좀 있었다. 모든 에러를 예상할 수 없기 때문에, Except 구문으로 에러를 찾아준다. 그리고 Finally 구문으로 세션은 어떠한 경우라도 반납하도록 코드를 수정하였다.
config 수정
pool size, max overflow의 default 값이 5, 10임을 참고하여 그 둘을 조정해주었다. 그리고 recycle시간을 30초로 하여 overflow 되는 일을 안만드려고 한다.

결론
사실 위에서 진행한 방법이 100% 맞다고 확신할 수는 없지만, 일단 코드를 수정한 이후로 서버가 다운되는 일은 없었다. (AWS EC2 프리티어 사용중) 틀린 설명이 있다면 댓글로 남겨주시면 감사하겠습니다.

안녕하세요 잘읽었습니다. 하나 문의 드릴것이 engine = create_engine('mysql+mysqldb://%s' % port_y, pool_recycle=3600) 이렇게 하는것과 app.config['SQLALCHEMY_POOL_RECYCLE'] 이렇게 하는것과 같나요?