쉬는 김에 적어보는 블로그의 두번째, Simple grammar parser 제작기입니다.
원래는 작업한지 오래되어 생각도 없었던 주제이지만 친구의 요청으로 적어봅니다. (보고있나 변교수 ㅋ)
상황
흔한 일이지만, 회사에서 머신러닝 모델링을 하려다보니 학습시킬 데이터가 부족한 상황에 부딪히게 되었습니다. (혹시 몰라 디테일은 최대한 빼고 적습니다. 예시는 전부 만든 케이스입니다.)
기획자와 논의하여 Rule-base 시스템으로 seed 로 쓰일 feature를 선 생성하고 접근하는 방향으로 계획하여 작업을 시작했습니다.
최초엔, 사내에 존재하던 데이터의 카테고리 분류 및 제목에 쓰인 특정 키워드의 존재 기준으로 feature를 부여하는 것으로 이야기가 되었습니다.
| Category | Title | Contained Keyword | Granted Feature |
|---|---|---|---|
| A | 이걸로 사도 될까? 엘든링 PS4 노멀(슬림) 버전 정식판 첫 플레이 | PS | 콘솔게임 |
| A | 아시안 게임에 나가게 될 LCK 최강 멤버는 ? | LCK | League of Legends |
| B | 새벽 감성 노래 모음 | 감성 | Ballad |
당연하게도... 단일 키워드 존재 여부 정도로는 표현할 수 없는 애매한 기준이 많았고, 다중 키워드의 존재 여부 및 특정 키워드가 존재하지 않는 경우까지로 룰을 확대할 수 있는지 문의가 들어왔습니다. (아, 첨엔 하나면 될 거 같다면서요! ㅋㅋ)
관련 문의를 받고서 곰곰히 생각해보니... 어짜피 키워드에 Synomym(동의어) 처리도 없고하여 단순 존재/미존재 키워드 리스팅으로는 이후 비슷한 요구를 많이 받게될 것으로 생각되었습니다. 차라리 그러면, 키워드 처리 관련해서 여러 케이스를 받을 수 있는 간단한 문법을 만드는 방향으로 하자고 논의하고 정리하였습니다.
목표 문법
Keyword Rule: (PS or "Play Station") and !("X Box" or "X Box X" or XBX)
=> 이런 경우 ("플스" 키워드가 들어있고, "엑스박스" 키워드가 없으면),
"Console, Play Station" feature 부여
위의 예시 문법에서와 같이 괄호, or, and, !(==not) 의 연산자를 사용할 수 있는 문법을 구현하여 (메모리가 허용하는 한) 갯수의 제한없는 키워드 관련 룰을 구성할 수 있도록 하는 목표로 parser, evaluator를 작성하였습니다.
Parser
이 parser를 구현하기 위해 컴파일러론 수업에서 배운 지식들이 활용되었습니다.
compiler는 단순하게 말하면, 하나의 언어를 다른 언어로 변환하는 번역기입니다. 이를 위해 굉장히 간단히 표현하면 아래의 형태를 갖습니다.
Compiler

- Source langauage - 번역해야하는 원본 언어로된 코드입니다. C 언어 등을 생각하면 됩니다.
- Scanner - Lexical analyzer 라고도 불립니다. 원본 코드를 문법이 정의하는 최소단위 token들로 분리합니다. 프로그램 언어의 명령어, 예약어 등이 여기에 해당합니다. C 언어를 예로들면 "for", "if", "&&", "||", "(", ")", "+" 등 입니다.
- Parser - Token 들로 문법에 맞춰 tree를 구성합니다. "3 + 4" 같은 구문이 있다면,
+"를 root node로 그 아래 "3", "4"라는 child node 가 구성되는 식입니다. 이 결과물은 AST(Abstract Symbolic Tree)라고 불립니다. - Code generator - AST에 맞추어 Target language 를 생성합니다.
- Target language - C 언어 예시의 경우 어셈블리에 해당합니다.
위의 설명은 굉장히 간략화된 설명입니다. 실제로는 중간에 Optimizer 나 Intermediate code generation 을 하기도 하는 등 복잡한 형태를 갖습니다. 하지만 위의 Keyword rule 문법을 구현하기 위해서는 scanner, parser, evaluator (code generation이 필요한 것이 아니라 해당 룰의 적용 시 true/false 결과가 필요하므로) 3가지만이 필요합니다.
BNF
이런 문법을 표현하기 위한 방법으로 BNF가 존재합니다. 이 형태로 표현하게 되면 parser를 작성하는데 여타 라이브러리나 오픈소스들의 도움을 많이 얻을 수 있습니다.
BNF의 간단한 정의는 아래와 같습니다.
<symbol> ::= __expression__- symbol은 terminal(scanner의 token. 문법에서의 최소 단위) 혹은 symbol의 나열로 표현될 수 있습니다.
- ::= 연산자의 의미는 왼쪽의 symbol이 오른쪽의 expression 으로 대체되어야 함을 나타냅니다.
- expression은 | 연산자를 통해 다중 표현이 가능합니다. (or 의 의미)
이 BNF를 이용하여 위의 Keyword rule을 표현하는 문법을 표현해보면 이렇게 됩니다.
<top_expr> ::= <or_expr>
<or_expr> ::= <and_expr> ("or" <and_expr>)*
<and_expr> ::= <not_expr> ("and" <not_expr>)*
<not_expr> ::= "!" <bracket_expr> | <bracket_expr>
<bracket_expr> ::= "(" <or_expr> ")" | <keyword>keyword 는 terminal로서, 쌍따옴표("")에 쌓여있는 문자열 혹은 예약어인 '(',')','!' 및 띄어쓰기를 포함하지 않은 일련의 문자열로 표현될 수 있습니다. (BNF로는 표현이 힘들어 적지 않았습니다.)
또한 원래 BNF 표현법엔 *(반복)에 대한 표현법이 없지만, 좀 더 짧고 편하게 표현하기 위해 그냥 넣었습니다. (ExtendedBNF라는 표현법이 따로 존재하긴 합니다.)
위 문법을 조금 더 설명하자면, 최상위 표현은 or_expr 으로 표현될 수 있고,
or_expr는 "or"라는 토큰으로 연결된 and_expr의 sequence가 중복되어 나타날 수 있고,
and_expr는 "and"라는 토큰으로 연결된 not_expr의 중복 가능한 sequence로 표현됩니다.
not_expr는 "!" 토큰이 앞에 붙거나 안붙은 bracket_expr 으로 표현이 되고,
bracket_expr는 "(", ")" 로 쌓인 or_expr 혹은 keyword (terminal) 로 표현될 수 있습니다.
or - and - not - bracket(or로 loop) - keyword
이런 구성 순서로 생각하면 편합니다. terminal (문법구성 최소단위) 는 keyword 뿐입니다.
이렇게 하면, 다중으로 괄호를 사용할 수 있고, !(not)를 괄호 앞에, 혹은 키워드 앞에 붙여 사용하고, and/or을 다중으로 사용하는 문법을 구성할 수 있습니다.
Abstract Symbolic Tree
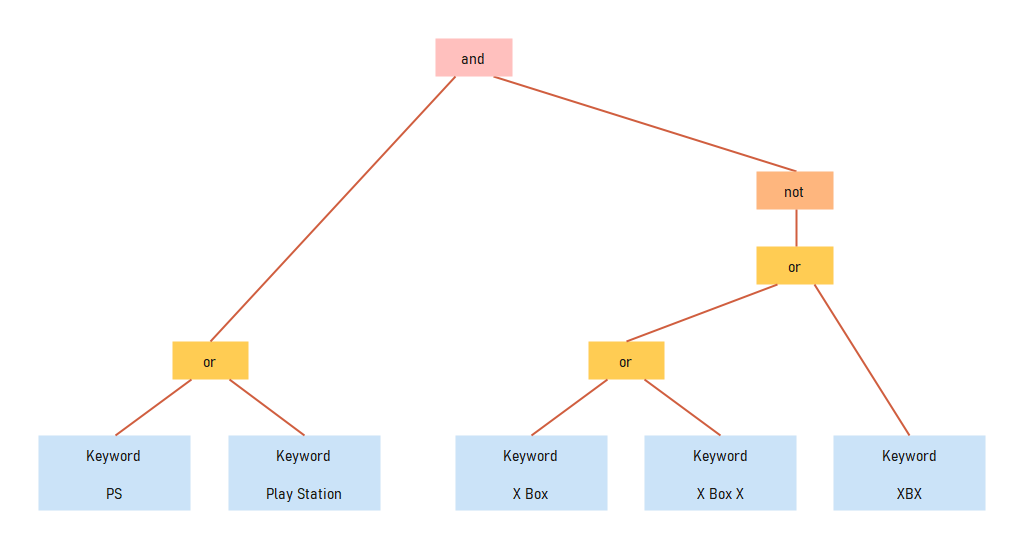
이 BNF 표현으로 만들려고 하는 최종 AST(Abstract Symbolic Tree) 결과물의 예시는 아래와 같습니다.
Keyword Rule: (PS or "Play Station") and !("X Box" or "X Box X" or XBX)
이런 룰이 있을 경우, 이런 트리 구조가 생성됩니다.
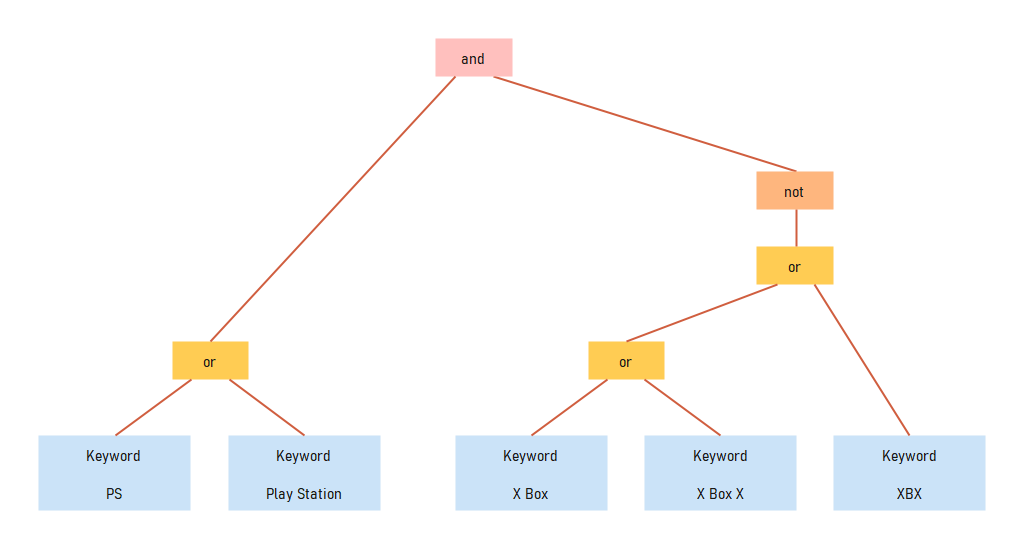
Operation priority
위의 BNF 표현의 구조로 parser 가 생성되고 이를 통해 AST가 생성되므로 operator 사이에는 우선순위가 생기게 됩니다. 수학에서 3 + 4 * 2 같은 수식이 있는 경우, *(곱셈)을 +(덧셈)보다 우선 계산한다는 룰이 있는 것과 마찬가지로 생각하면 이해가 쉽습니다.
!(not) > and > or
Parser가 !를 가장 말단에서, 그 다음은 and, or의 순서로 처리하므로 그 순서에 따라 AST가 생성되고 evaluation 시점엔 leaf node 부터 처리되므로 괄호없이 연산자들이 사용된 경우, 이 순서에 따라 연산은 처리되게 됩니다.
Scala parser combinators
이런 BNF 표현을 실제 parser로 구현해주는 라이브러리나 툴은 언어별로 굉장히 다양하게 있습니다. 가장 흔하게 볼 수 있는 것으로는 컴파일러론 수업 시간에 사용해봤을 Lex, Yacc가 존재하고, BSD license의 ANTLR 등이 있습니다.
하지만, 이번 구현에선 Scala의 combinator module을 사용하여 구현하기로 하였습니다. 사용 형태가 간단하여 코드가 짧아지기도 하고, 데이터 처리에 주로 spark를 사용하고 있어 같이 연동해서 로직을 구성해 사용하기도 좋았기 때문입니다. 사실 처음에 기획에 아이디어 제시할 때 부터, "이거쓰면 parser/evaluator 코드 짧게 금방 짤 수 있어서 좋겠는데?" 라는 생각이었긴 합니다. ㅎㅎ
scala 2.11 까진 기본 언어 라이브러리에 포함되어 있어 그냥 import 후 사용이 가능했으나 2.12 부터는 모듈 라이브러리로 분리되어 dependecy 추가 후 쓸 수 있습니다. 공식깃헙을 참조하여 추가하면 됩니다.
Simple example
import scala.util.parsing.combinator._
case class WordFreq(word: String, count: Int) {
override def toString = s"Word <$word> occurs with frequency $count"
}
class SimpleParser extends RegexParsers {
def word: Parser[String] = """[a-z]+""".r ^^ { _.toString }
def number: Parser[Int] = """(0|[1-9]\d*)""".r ^^ { _.toInt }
def freq: Parser[WordFreq] = word ~ number ^^ { case wd ~ fr => WordFreq(wd,fr) }
}
object TestSimpleParser extends SimpleParser {
def main(args: Array[String]) = {
parse(freq, "johnny 121") match {
case Success(matched,_) => println(matched)
case Failure(msg,_) => println(s"FAILURE: $msg")
case Error(msg,_) => println(s"ERROR: $msg")
}
}
}이 코드는 공식깃헙 상의 간단한 예시입니다.
"johnny 121" 라는 문자열을 parsing 하면, WordFreq 클래스 형태의 AST를 받게되고 (tree 구성이 없는 단일 class instance 일 뿐이긴 합니다.), 이 클래스를 출력하면 "Word <johnny> occurs with frequency 121" 라는 문자열이 나오게 됩니다.
이 예시에서 중요한 BNF 표현 구현부는 SimpleParser 클래스입니다. scala combinator의 RegexParsers를 상속받아, "[a-z]+" 정규식 형태의 word와 "(0|[1-9]\d*)" 정규식 형태의 number 를 정의하고 이 두 symbol이 앞 뒤로 나오는 freq 라는 symbol을 정의하였습니다.
def freq: Parser[WordFreq] = word ~ number 까지의 구문은 BNF이고,
^^ 이후의 구문은 이런 표현에 맞는 경우 어떻게 처리할 것인가 하는 부분입니다.
여기에서는 AST의 node에 해당하는 WordFreq case class를 정의하여 내부 변수를 parsing 의 결과로 내부 변수인 work, count 가 채워진 케이스 클래스 인스턴스를 생성합니다.
이렇게 main 함수 내의 parse(freq, "johnny 121") 구문의 결과로 WordFreq 인스턴스가 리턴되면 println하여 "Word <johnny> occurs with frequency 121" 가 출력되고 종료되게 됩니다.
결론적으로, 보다 자유도 높은 정규식 형태를 이용해서, BNF에 해당하는 symbol 들을 정의하여 parser를 만들고 이런 구문이 있는 경우 어떤 동작을 할 것인지까지 한 클래스 내에서 전부 구현이 가능합니다! 개인적으로는 여타 툴보다 정말 쉽게 짧게 짤 수 있다고 생각합니다.
Keyword rule implementation
이제 이 combinator를 이용해서 keyword rule을 구현해보겠습니다.
먼저, AST 구조에 node 로 쓰일 case class 들을 정의하였습니다.
sealed abstract class ExprSymbol
case class Keyword(term: String) extends ExprSymbol
case class Or(left: ExprSymbol, right: ExprSymbol) extends ExprSymbol
case class And(left: ExprSymbol, right: ExprSymbol) extends ExprSymbol
case class Not(expr: ExprSymbol) extends ExprSymbol예상 가능하게 Keyword, Or, And, Not 으로 구성됩니다.
그리고 BNF 구문을 구현합니다.
class SimpleKeywordRuleParserEBNF extends RegexParsers {
def top_expr: Parser[ExprSymbol] = or_expr
def or_expr: Parser[ExprSymbol] = and_expr ~ ("or" ~ and_expr).* ^^ {
case left ~ list => list.foldLeft(left) {
case (left, "or" ~ right) => Or(left, right)
}
}
def and_expr: Parser[ExprSymbol] = not_expr ~ ("and" ~ not_expr).* ^^ {
case left ~ list => list.foldLeft(left) {
case (left, "and" ~ right) => And(left, right)
}
}
def not_expr: Parser[ExprSymbol] = (
"!" ~ bracket_expr ^^ { case "!" ~ list => Not(list) }
| bracket_expr ^^ (list => list)
)
def bracket_expr: Parser[ExprSymbol] = (
"(" ~ or_expr ~ ")" ^^ { case "(" ~ list ~ ")" => list }
| keyword ^^ { keyword: Keyword => keyword }
)
def keyword: Parser[Keyword] = (
"\"" ~ "[^\"]+".r ~ "\"" ^^ { case "\"" ~ value ~ "\"" => Keyword(value) }
| "[^ ()!]+".r ^^ (value => Keyword(value))
)
}keyword 관련 부분을 제외하고는 상기한 BNF 를 직접적으로 scala 문법에 따라 작성한 결과입니다. ^^ 이후 부분은 해당 문법의 결과로 어떤 case class를 instantiation하여 리턴하면 될 지를 나타내었습니다. 전체적인 구현코드는 여기를 참고해주세요. 테스트 코드는 여기에 있습니다.
실제로 이것만으로 keyword rule의 parser가 구현 완료되었습니다. scanner의 역할도 combinator가 직접 알아서 해줍니다. 이렇게 코드가 간결해질 때 개발자로서 신이 납니다. ㅎㅎ
그리고 또 다른 lexer, parser 제작 예시를 보고 싶다면 참조할만한 블로그입니다.
Building a lexer and parser with Scala's Parser Combinators
Evaluator
이제 남은 건 주어진 title에 주어진 keyword rule의 결과가 true인지 false인지를 확인하는 evaluator의 작성 뿐입니다. 예를 들면, 아래와 같은 Title과 Keyword rule이 있을 때, 적용 결과의 boolean 값을 알 수 있으면 이 rule이 통과됐는지 아닌지를 알 수 있습니다. 통과이면 해당 룰의 feature를 부여하고 아니면 다음 룰의 evaluation으로 넘어가게 됩니다.
Title: "이걸로 사도 될까? 엘든링 PS4 노멀(슬림) 버전 정식판 첫 플레이"
Keyword Rule: (PS or "Play Station") and !("X Box" or "X Box X" or XBX)
우린 이미 앞에서 만든 이 룰의 parser를 가지고 있고, 이를 이용해 룰을 AST로 만들 수 있습니다. 그럼 이 AST가 Title 문자열에 맞는지 확인하는 방법은? 어렵게 생각할 것 없이 DFS(Depth-First-Search) 로 해당 AST를 순회하면서 true/false 를 체크해 올라가 root node 의 최종 결과를 출력하면 됩니다.
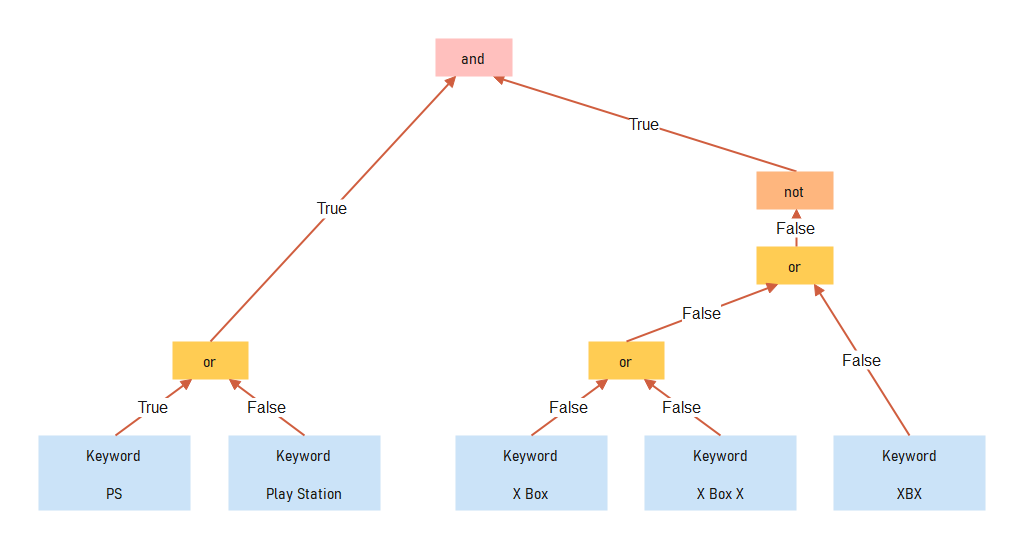
이 예시의 최종 결과는 true입니다.
구현체는 아래와 같습니다.
class SimpleKeywordRuleEvaluator extends Serializable {
def eval(ast: ExprSymbol, targetStr: String, keywordEvalFunc: String => Boolean = null): Boolean = {
val defaultKeywordEvalFunc = {keyword: String => targetStr.contains(keyword)}
if (keywordEvalFunc == null) {
exprSymbolTraversal(ast, defaultKeywordEvalFun)
} else {
exprSymbolTraversal(ast, keywordEvalFunc)
}
}
def exprSymbolTraversal(partialAST: ExprSymbol, keywordEvalFunc: String => Boolean): Boolean = {
partialAST match {
case node: Or =>
val leftRet = exprSymbolTraversal(node.left, keywordEvalFunc)
// Shortcut for "Or" operation
if (leftRet)
return true
exprSymbolTraversal(node.right, keywordEvalFunc)
case node: And =>
val leftRet = exprSymbolTraversal(node.left, keywordEvalFunc)
// Shortcut for "And" operation
if (!leftRet)
return false
exprSymbolTraversal(node.right, keywordEvalFunc)
case node: Not =>
!exprSymbolTraversal(node.expr, keywordEvalFunc)
case node: Keyword =>
keywordEvalFunc.apply(node.term)
case notImplemented =>
throw SimpleKeywordRuleEvaluationException(s"Not implemented AST node. Class name: ${notImplemented.getClass.getName}")
}
}
}ast와 targetStr(Title 문자열)을 받아 exprSymbolTraversal method를 계속 recursive call 합니다.
- Keyword symbol의 경우엔 targetStr 에 해당 keyword가 존재하는지 여부를 체크하여 리턴
- Not symbol의 경우엔 child의 결과를 반전하여 리턴
- And symbol의 경우엔 left/right child의 결과가 둘 다 true 면 true 리턴
- Or symbol의 경우엔 left/right child의 결과가 둘 중 하나라도 true 면 true 리턴
이 행동들을 root node에 도달할 때까지 반복하면 됩니다. 다만 And의 경우, left의 결과가 false 면 right를 순회하지 않아도 되기에 속도 최적화를 위해 shotcut이 적용되었습니다. (Or의 경우도 마찬가지로 left가 true면 right를 볼 필요가 없습니다.)
약간 특이사항으로 keywordEvalFunc 함수를 패러미터로 받아서 사용하되, 없으면 디폴트로 defaultKeywordEvalFunc 을 사용하도록 하였습니다. 이는 targetStr에 keyword 존재여부를 매번 스캔으로 확인하면 rule의 keyword 갯수만큼 targetStr 문자열 스캔이 일어나므로 이후 최적화를 위하여 별도의 함수를 받을 수 있도록 패러미터를 파둔 것 입니다.
구현 이후
위와 같은 parser, evaluator를 빠르게 작성하여 좀 더 다양한 경우의 keyword rule을 작성할 수 있었습니다. 또한 scala 구현체인 덕에 spark 를 통한 분산처리가 가능하였습니다.
물론... 룰을 직접 만들어야 했던 분들의 노고는 컸습니다. 최종적으로 보니 룰이 2~3천여개에 달했습니다... ㅠ_ㅠ
1차 적으로 적용해보니 아무래도 시간이 꽤 걸려서 최적화로 evaluator 구현시 문제점이었던, 길이 N의 문자열에 M개의 키워드 첨부여부를 확인하기 위해서는 O(M*N) 만큼의 비용이 소모되었던 부분이 수정 필요하다고 판단하였습니다.
Aho–Corasick 알고리즘을 추가 구현하여 keywordEvalFunc 함수에 인가하여 사용하였습니다. 이 알고리즘은 각 키워드 길이를 m1, m2, m3, ...라고할 때, O(N+m1+m2+m3+...) 타임만에 길이 N 문자열에서 M개 키워드를 찾아낼 수 있는 알고리즘입니다. (아는 한, 문자열 패턴 찾기 최고의 깡패...)
최종적으로 3억개 넘는 데이터 전수에 Rule 적용 결과를 20분 정도만에 뽑아낼 수 있어 매일 단위 실행에 문제없다고 판단, 관련해서는 추가작업을 진행하지 않았습니다. (사용 서버 댓수는 70대 정도입니다.)
실제적으로 회사에서 일하다보면 이런저런 이유로 코드가 깔끔하게만 나오기가 힘든 경우가 많아서 작업한지 오래됐음에도 불구하고 기억에 꽤 길게 남아있는 케이스입니다. 가끔있는 이런 경우가 개발뽕을 맞게해서 이런 맛에 개발자로 계속 살게 하는 것 같습니다. ㅎㅎ
