데이터 엔지니어로 일하면서 옆에서 지켜본 빅데이터 처리 시스템의 발전 상을 간략하게나마 정리해보았습니다. 시스템들의 정확한 런칭 시점을 조사하거나 개발자의 의견을 듣고 적는 내용이 아니므로 개인적인 가설이 많이 들어가 있습니다.
사실 회사에서 신입들을 대상으로 설명을 해줄 때 "이런 내용으로 적힌 페이지 없나?" 하는 생각에 찾다가 못 찾아서, 회사 쉬는 김에 만들어보는 페이지입니다. 설명의 목적이 사내에서 많이 쓰이는 Hive에 대하여 이해도를 높이기 위한 빌드업이다보니 설명의 디테일이 Hive에 집중되어 있습니다.
크게 시간의 흐름을 따른 발전상을 이해하기 쉽게 적는 것이 목적이지만, 각 오픈소스 들의 발전 시점이 서로 곂쳐있거나 경쟁하거나 하는 경우들이 있어 명확하진 않습니다. 또한 디테일을 전부 적기는 힘들어 개념적으로 어떤 식으로 발전했는지에 집중하였습니다.
다중 서버 분산 처리

데이터 처리 컨셉을 크게 추상화하면, 프로세서가 인풋을 처리하여 아웃풋을 생성하는 것으로 설명할 수 있습니다. 기본적으로 CPU의 속도 향상 같은 물리적인 서버의 성능 증가에 따라 프로세싱 속도가 향상되었으나, 처리할 데이터 사이즈가 증가함에 따라 단일 프로세스로는 처리 속도 증가에 한계가 오기 시작하였습니다. 이를 개선하기 위한 아이디어로 프로세서의 갯수를 늘리는 병렬처리가 시작됩니다. 이 병렬처리는 단일 서버에서 Multi-threading 혹은 Multi-processing을 통하여 구현되었습니다.
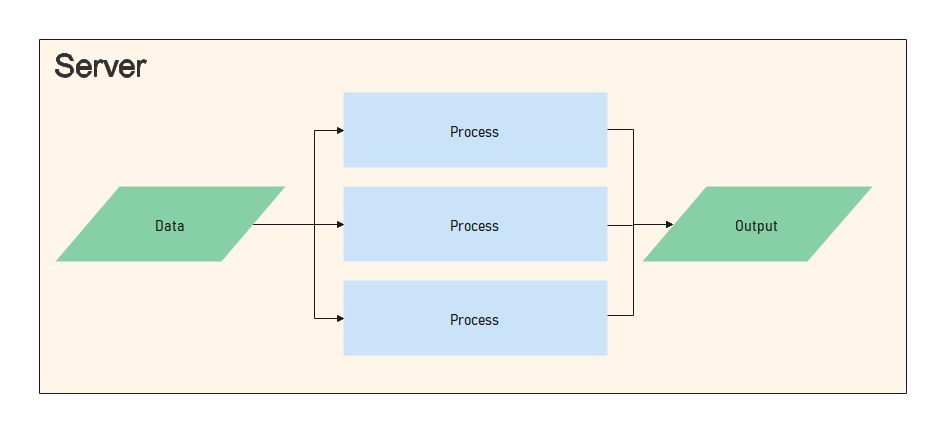
시간이 지남에 따라 더 많은 데이터를 더 빨리 처리해야할 필요가 생기게 되었습니다. 이를 해결하기 위해 프로세서의 갯수를 늘리는 아이디어의 연장으로 서버의 갯수도 늘게 됩니다.
단일 서버에서는 프로세스 간 통신이 필요한 경우 메모리나 디스크 등을 통해 가능했지만, 서버 간에는 이 통신을 주고 받는 방식에 대한 표준이 필요해졌습니다. 이 표준이 MPI (Message Passing Interface) 입니다. 또한 처리할 데이터가 한 대의 서버 안에 저장하기 충분하지 않은 경우, 대용량이 저장 가능하고 여러 대의 서버에서 네트워크로 접근 가능한 공용 스토리지가 필요하게 되었습니다. 데이터 저장을 위한 스토리지는 SAN (Storage Area Network) 등이 사용됩니다.
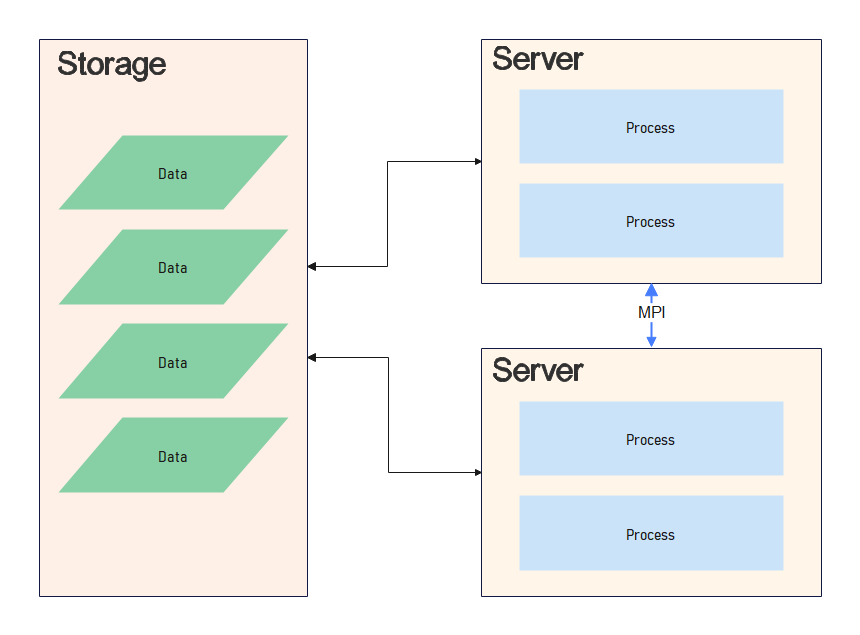
이 당시만 해도 처리해야할 데이터가 1개의 하드디스크의 용량은 이미 넘었기에, 디스크를 다중으로 연결한 SAN은 데이터를 각 블록으로 나누어 디스크에 분산 저장하였습니다. 이를 위해 복잡한 관리 시스템을 사용하게 되고 저장공간 당 가격도 점차 비싸졌습니다.
하지만 이후, 당연하게도 처리해야할 데이터의 양은 점점 더 늘어나게 되었습니다. 이제 데이터 처리에 있어 버틀넥(Bottleneck)은 기존의 프로세싱 속도에서 데이터를 프로세서에 전달하고 받아서 저장하는 과정에서 사용되는 네트워크 트래픽으로 넘어가기 시작합니다.
분산 처리 개념의 변화 - GFS(HDFS), MapReduce(Yarn)
위의 설명에서 얘기했듯이 데이터 분산처리에서의 버틀넥은 네트워크 트래픽이 되었습니다.
단순하게 생각하면, 처리해야할 데이터 볼륨이 1TB(TeraByte) 라고 했을 때 이 데이터를 읽기 위해 쓰이는 시간만 100Mbps ethernet 랜카드 한대의 속도를 기준으로 약 83,886초 = 약 23시간이 소요됩니다. (최근엔 기가비트 단위 랜카드가 일반적이지만 하둡이 시작되던 당시 많이쓰이던 100Mbps 카드를 기준으로 계산했습니다.)
구글은 자사의 검색을 위한 PageRank 알고리즘 계산에 있어 이런 한계에 일찍 부딪혔고, 이를 해결하기 위해 GFS (Google File System), MapReduce 라는 개념을 생각해내게 됩니다.
기본 아이디어는 단순합니다.
데이터를 프로그램에 던지는 것이 힘들면 프로그램을 데이터에 던지면 되지 않는가?
TB, PB 단위까지도 가는 데이터보다 프로그램의 용량은 아무리 높아도 1GB를 넘기가 쉽지 않습니다. 당연히 이렇게만 될 수 있으면 훨씬 빠른 프로세싱 속도를 얻을 것입니다.
다만 문제는 "이 아이디어를 어떻게 현실화 할 수 있을 것인가" 인데 구글은 이를 해결하기 위해 간단한 2가지 아이디어를 제시하였습니다.
- 데이터를 서버들에 분산하여 저장한다. (GFS)
- 이 서버들에서 Map-Reduce 라는 operation을 지원하는 프로그램을 실행한다. (MapReduce)
세부 과정을 조금 더 적어보면 이렇습니다.
- 데이터가 각 서버에 부분별로 분산되어 저장된다. (GFS)
- 실행할 프로그램을 각 서버에 전달한다.
- 프로그램이 해당 서버가 가지고 있는 데이터 부분에 대하여 프로세싱한다. (Map)
- 각 서버의 결과를 모아야 하는 연산이 추가로 필요할 경우, 네트워크를 통해 Key 별로 모아서 처리한다. (Reduce)
이 개념으로 데이터는 최초 저장 시에 분산되어 저장되고, 프로세싱 시엔 각 분산된 위치에서 자체 데이터를 최우선으로 연산 & 저장하여 문제가 되었던 네트워크 트래픽이 상당히 줄어들게 되었습니다. (혹여 Map이 처리해야하는 데이터 부분이 실행되는 해당 Map이 실행 중인 서버에 없을 경우 네트워크를 통해 다른 서버에서 끌어옵니다.)
또한 이 설계를 일반적인 PC나 웹 서버 급의 서버로 다량 분산 구성하여 사용할 경우, 기존의 전문 장비 대비 가격이 많이 절약되는 효과도 볼 수 있었습니다.
MapReduce
위에서 간략하게 설명한 MapReduce의 논리적인 개념은 이렇습니다.
Map(k1,v1) → list(k2,v2)
Reduce(k2, list (v2)) → list((k3, v3))
수식이 의미하는 바를 설명하면, Map function은 k1 (key1), v1 (value1)을 출력으로 받아서, k2,v2의 list 를 출력합니다. Reduce function은 k2, list(v2) 를 입력받아 (k3, v3)의 list를 출력합니다.
좀 더 이해가 쉽도록 예시로 흔하게 쓰이는 Word Count 프로그램을 기준으로 설명해보겠습니다.
Hello World
Hello Hadoop World
Goodbye
위의 문자열을 파일 시스템에 분산하여 저장한 후, 띄어쓰기 기준 각 단어의 갯수를 연산하는 과정을 도식화하면 아래 그림과 같습니다.
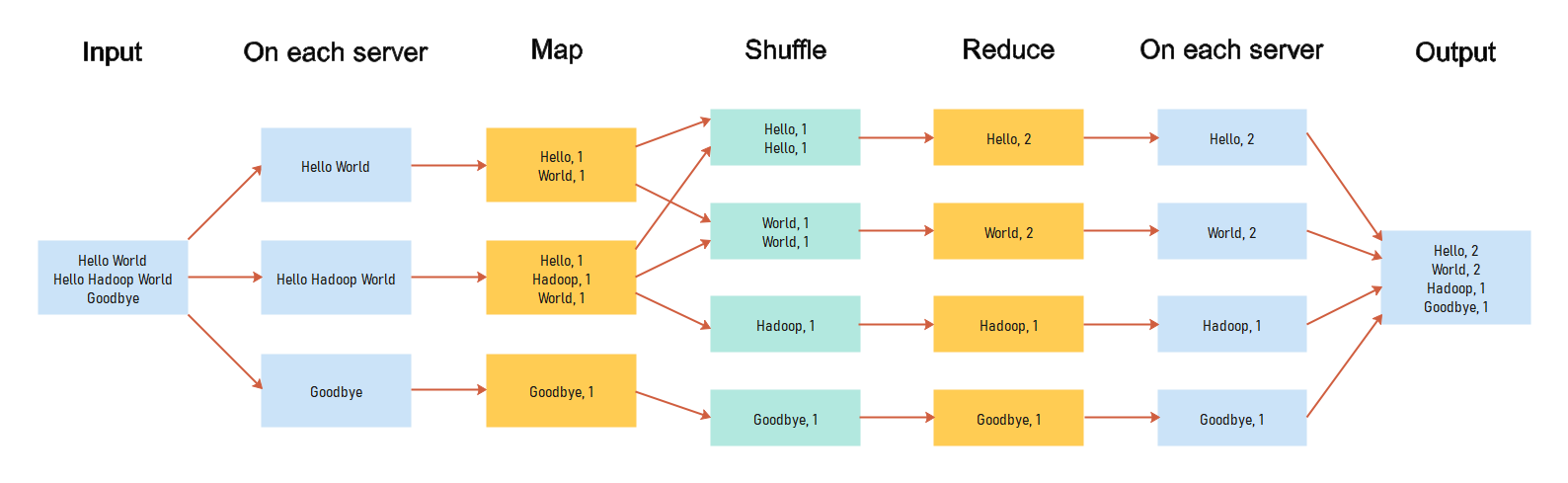
- 문자열을 담은 파일이 각 서버에 나뉘어 저장되어 있음
- Map function이 각 서버의 데이터를 기준으로 띄어쓰기(' ') 후 Word 별 Count를 결과로 냄 (이 때, 출력하는 Word가 k2, Count가 v2이고 v1은 최초의 input text입니다.)
- 동일한 Key의 데이터는 같은 곳으로 모임 (Shuffle 과정. MapReduce framework가 지원해주는 파트)
- Reduce function 에서 각 Word 기준 Count list 를 입력으로 받아 합산 후 (Word (k3), Count (v3)) 를 결과로 출력
위 작업을 실행하는 WordCount 프로그램의 코드는 아래와 같습니다. 하둡 공식 페이지에서 발췌하였습니다. MR 프로그램은 하둡 라이브러리의 Mapper와 Reducer 클래스를 상속받고 map, reduce 메서드에 원하는 로직을 구현하는 식으로 코딩합니다.
WordCount programimport java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
/* Combiner: Shuffle 과정은 네트워크를 소모하므로 Shuffle 직전 Map 결과를 1차적으로 Reduce 하는 Combiner를 추가 정의 */
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}이 WordCount 예시는 굉장히 간단한 예시입니다. 필요에 따라서는 Map-Reduce 과정을 여러번 거치거나, 하나의 Input에 대해서만 Map을 하는 것이 아니라 여러 Input을 대상으로 Map을 하는 식으로 구현하면 생각보다 다양한 요구 형태에 맞는 프로그램을 작성할 수 있습니다. (2개의 데이터를 각 key에 대하여 join 하는 프로그램이 여러 Map을 쓰는 예시 중 하나입니다.)
이런 내용을 담은 논문이 구글에서 2003년 (The Google File System), 2004년 (MapReduce: Simplified Data Processing on Large Clusters) 발표되었고, 이를 관심있게 본 Doug Cutting과 Mike Cafarella에 의해 2006년 Hadoop 프로젝트가 시작됩니다. (하둡이라는 이름은 더그 커팅의 아들이 가지고 놀던 코끼리 인형의 이름을 따왔다는 일화가 있습니다.)
이 하둡 프로젝트는 크게 GFS의 구현체인 HDFS (Hadoop Distributed File System), JobTracker (MapReduce 프로그래밍 모델 실행용 시스템. 근래엔 Yarn으로 새로 만들어짐)로 구성되어 있었습니다.
쓰다보니 반복 코딩이 많네? - Sawzall, Pig, Hive
하둡은 Java로 구현된 시스템이자 프레임워크이고 분산 파일 시스템 및 MapReduce 잡 실행을 해주는 시스템의 구현에 집중이 되어있다보니, 시스템 사용자들을 위한 편의 기능이 많지 않았습니다. MapReduce 프로그램들은 전부 Java로 직접 프로그램을 코딩하여 실행하는 형태를 가지고 있었습니다. 위에서 설명에 사용한 WordCount 같은 단순한 프로그램조차 결과를 내기 위해선 코딩 -> 빌드 -> 잡 실행 -> 결과 확인 이라는 복잡한 과정을 통해야만 했고, 이는 비슷한 역할을 하는 프로그램이 지속적으로 작성, 사용되는 상황을 가져옵니다. (간단히 상상해봐도 로그 데이터에서 특정 유저가 방문한 횟수 등의 단순 프로그램은 업무에서 자주 쓰입니다.)
Sawzall, Pig
이런 상황에서 구글은 내부적으로 Sawzall이라는 스크립트 언어를 개발하여 사용하였고, 야후에서 2006년 비슷한 역할의 Pig라는 프로젝트가 만들어집니다.
input_lines = LOAD '/tmp/my-copy-of-all-pages-on-internet' AS (line:chararray);
-- Extract words from each line and put them into a pig bag
-- datatype, then flatten the bag to get one word on each row
words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
-- filter out any words that are just white spaces
filtered_words = FILTER words BY word MATCHES '\\w+';
-- create a group for each word
word_groups = GROUP filtered_words BY word;
-- count the entries in each group
word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word;
-- order the records by count
ordered_word_count = ORDER word_count BY count DESC;
STORE ordered_word_count INTO '/tmp/number-of-words-on-internet';위 예시 코드에서 보이듯이 SQL 과 비슷한 느낌의 구문을 Line-by-line 으로 코딩한 후 실행(lazy evaluation)하는 방식입니다. 이렇게 스크립트로 코딩을 하면, 내부적으로 Java Mapreduce 프로그램으로 변환하여 실행합니다.
Hive
스크립트가 아닌 SQL 구문을 하둡에서 사용하고자 하는 생각으로 Facebook에선 Hive라는 프로젝트를 만들게 됩니다. 사용되는 쿼리가 SQL-92 표준을 전부 구현하지는 못하여 SQL-like query, HiveQL, HQL 등으로 불리지만 실질적으로 SQL 구문과 큰 차이는 없습니다.
SQL은 아무래도 기존에 데이터를 처리하던 직종에서 가장 익숙한 형태의 언어여서 현재까지도 하둡 환경에서 가장 많이 쓰이는 오픈소스 중 하나가 되었습니다.
SQL을 사용하려다보니 어떤 테이블이 어떤 HDFS 상의 파일들을 사용하는지, 해당 파일이 어떤 컬럼들로 이루어져 있는지, 파일 포맷이 뭔지 등의 세부정보를 시스템이 알아야할 필요가 생겼습니다. 이를 위해 Hive는 관련 정보를 가지고 있는 프로세스를 하나 가지고 있고, 이것이 Metastore(메타스토어)입니다. 기본적으로 이 Metastore 프로세스가 통신 가능하지 않으면 Hive는 동작할 수 없습니다.
Hive Design
Hive는 내부적으로 아래와 같은 디자인을 가지고 있습니다.
(하둡 영역은 v1.x 대를 기준으로 한 그림입니다. 따라서 최근 많이 쓰이는 v2.x, v3.x 와는 차이가 있습니다.)
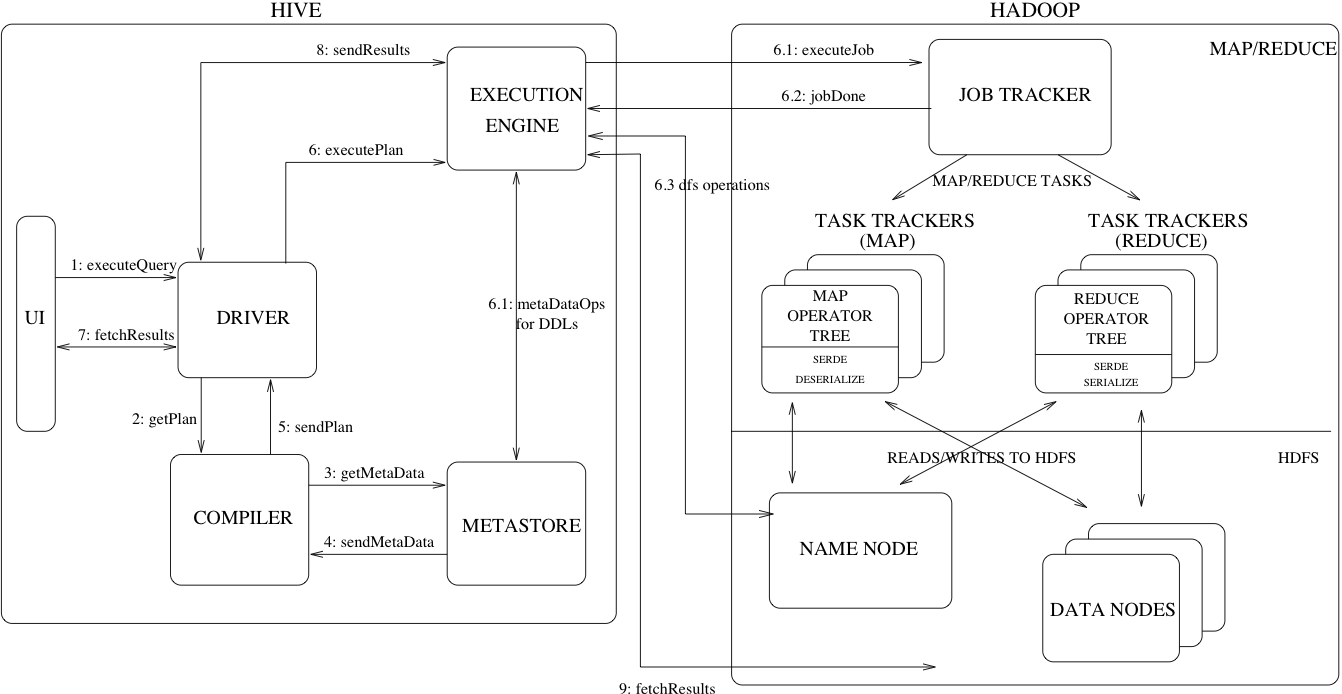
- 유저로부터 쿼리 입력
- Driver (Main program) 에서 Compiler 모듈 실행
- Compiler 모듈은 Metastore로부터 쿼리에 필요한 테이블 정보 수신
- Compiler 에서 Execution plan (Physical plan) 생성
- Execution engine을 통해 실행 후 결과를 받아서 유저에게 전달 (그림의 경우 engine은 MapReduce)
위의 프로그램 디자인에 덧붙여 Compiler 모듈 안에서 일어나는 일을 좀 더 자세히 써보면 아래와 같습니다. Hive의 쿼리가 실행되는 과정은 MySQL이나 Oracle 같은 DBMS(DataBase Management System)의 쿼리 실행 방식과 유사합니다.
Query -> Parsing -> Semantic Analysis -> Logical Plan Generation (with Optimization) -> Query Plan Generation -> Execute
- Parsing - 쿼리를 파싱하여 트리 구조의 AST(Abstract Symbolic Tree)로 변경합니다.
- Semantic Analysis - AST를 내부의 쿼리 표현법으로 변환합니다. select 구문의 * 가 어떤 컬럼들인지, 컬럼 타입엔 문제가 없는지, 암시적 타입 변환이 필요한지 등을 체크합니다. 또한 조회할 테이블의 파티션 정보도 조회하여 첨부합니다.
- Logical Plan Generation - 쿼리 실행에 필요한 논리적인 'filter', 'join', 'table scan' 등의 operator들의 트리 형태 표현으로 변환합니다. 최적화 할 수 있는 부분을 확인하여 변환하는 Optimization 과정도 이 때 실행됩니다.
- Query Plan Generation - Logical plan을 실제적인 MapReduce job 에서 실행하는 형태의 task 들로 변환합니다. 하이브의 최근 버전은 engine 이 MR (MapReduce) 외에 tez, spark 등이 가능하므로 설정에 맞춰 Execution plan (Physical plan)을 생성합니다.
이렇게 생성되는 Execution plan은 MySQL과 유사하게 explain 명령어를 통하여 확인할 수 있습니다. 이 명령어를 통하여 실제 MR 프로그램이 어떻게 실행될지를 확인할 수 있어 쿼리를 최적화하는데 도움을 받을 수 있습니다.
hive> explain select * from stud;
OK
Plan not optimized by CBO.
Stage-0
Fetch Operator
limit:-1
select Operator [SEL_1]
outputColumnNames:["_col0","_col1","_col2"]
TableScan [TS_0]
alias:stud
Time taken: 0.033 seconds, Fetched: 10 row(s)Hive System Architecture
최초엔 유저의 컴퓨터에서 SQL 쿼리를 파싱하여 직접 MR 프로그램으로 변환, 실행하는 형태를 취했던 하이브는 점차 DBMS(DataBase Management System)와 비슷한 형태로 발전해나가기 시작합니다.
이에 따라 직접 클라이언트에서 실행하는 방식이 아닌, 네트워크를 통하여 쿼리를 전달 & 실행하고 결과를 받아오는 기능을 지원하기 위하여 Hive server라는 프로세스가 추가되었습니다. 이 프로세스는 널리 쓰이는 DB 통신용 API 형식인 JDBC, ODBC를 지원합니다. 또한 자체 프로토콜 구현을 위해 Apache Thrift를 사용하였으므로, 이 Thrift client를 사용한 접근도 가능합니다. (사실 JDBC, ODBC driver도 내부적으론 이 Thrift client를 사용합니다.)
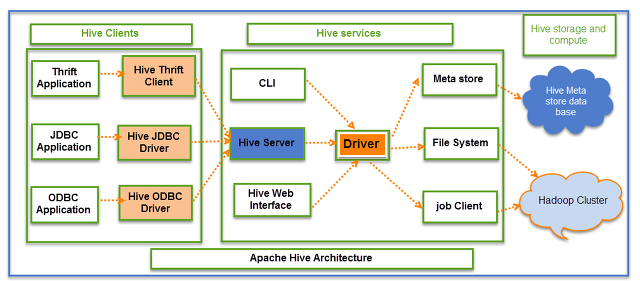
- CLI (Command-Line Interface) - 클라이언트에서 직접적으로 MR 프로그램을 실행시키는 최초 형식에 대응하는 툴입니다. 실행하면 SQL 구문을 넣을 수 있는 프롬프트가 뜹니다. 유저가 실행할 때만 뜨는 프로세스입니다.
- Hive server - JDBC, ODBC 등의 인터페이스로 쿼리를 받아서 실행 & 결과 전달 역할을 하는 프로세스입니다. 이 프로세스가 최초 구현됐을 때엔 한 번에 한 유저의 쿼리만을 받아서 처리할 수 있었고, 근래엔 멀티 유저, 멀티 세션을 지원하는 Hive server 2 만이 존재합니다.
- Hive Web Interface - 웹 형식의 쿼리 실행기입니다. 현 버전의 하이브에서는 삭제되었습니다. 최근엔 웹 상에서의 쿼리 환경은 Hue 등의 여타 오픈소스들을 많이 사용합니다.
이 외에도 하이브에서는 DBMS에서 지원하는 Authorization, Transaction 등의 기능을 지원하기 위하여 여러 작업들이 있었습니다. 아직 충분치 못 한 부분들도 많고 설정 및 구성에 따라 사용 가능/불가능한 기능들이 존재합니다.
1부를 마치며
적다보니 생각보다 어디까지 추가하고 짤라내야 할 지 고민을 많이 하게된 글이었습니다.
도입부에 상술했듯이 경험에 의존하여 흐름을 이해하기 쉽게 적으려 노력한 글이어서 오류가 있을 수 있습니다. 최대한 잘못된 내용을 넣지 않도록 노력하긴 했지만 오류가 존재할 수 있으니 너른 아량을 부탁드립니다.
