* Program : 짜여진 코드들. 어떤 작업이 있고 해당 작업을 나타내는 실행 가능한 파일. 운영체제 위해서 동작할 수 있는 파일.
* Process
: 짜여진 Program 코드를 실행한 상태. 즉, Program을 실행하면 컴퓨터는 Process라는 실행흐름을 할당하여 작업을 처리하는 과정
[생활예시]
* 아침에 일어나서 씻고 준비를 한다.
* 역으로 걸어간다
* 지하철을 탄다
* 역에서 내려 출근을 한다.[컴퓨터의 예시]
- 프로세스란 운영체제에서 실행 중인 하나의 애플리케이션을 말한다.
- 사용자가 애플리케이션을 실행하면(프로그램을 실행하면) 운영체제로부터 실행에 필요한 메모리를 할당받아 애플리케이션의 코드를 실행한다.
- 프로세스란 이때 실행되는 애플리케이션을 말한다.
- 정리하면 프로그램(파일)을 마우스 더블 클릭으로 실행 시켰을 때, 이 실행 되고 있는 프로그램을 프로세스라고 한다.
- 프로그램은 다중 프로세스로 만들기도 한다.
- 예를 들어 크롬 브라우저를 두 개 실행하면, 두 개의 프로세스가 생성된다.
- 이렇게 하나의 애플리케이션은 여러 프로세스(다중 프로세스)를 만들기도 한다.
* Thread
: 짜여진 Program을 실행하는 Process를 구성하는 여러가지 작업단위들.
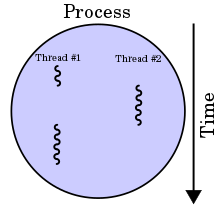
- 스레드는 사전적 의미로 한 가닥의 실이라는 뜻이다.
- 스레드는 이러한 프로세스 안에서 한 가지 작업을 실행하기 위해 순차적으로 실행되는 하나의 흐름이다.
- 한 가지 작업을 실행하기 위해 순차적으로 실행한 코드를 실처럼 이어 놓았다고 해서 유래된 이름이다.
- 하나의 스레드는 코드가 실행되는 하나의 흐름이기 때문에, 한 프로세스 내에 스레드가 두 개라면 코드가 실행되는 흐름이 두 개 생긴다는 의미이다.
- 이러한 형태의 스레드는 프로세스 내에서 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유합니다.
📌프로세스와 스레드의 영역
하나의 프로세스는 크게 코드영역(code), 데이터 영역(date), 스택 영역(stack), 힙 영역(heap) 4가지로 이루어져 있습니다.
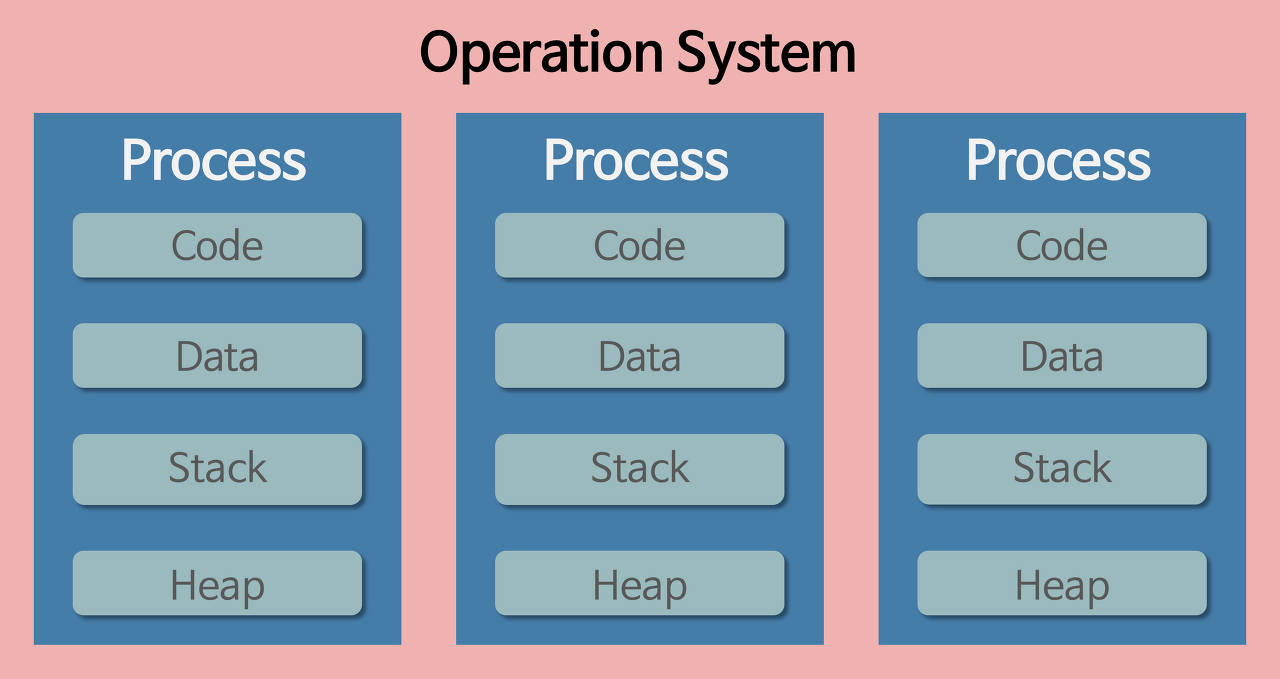
Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)
Data : 전역 변수, 정적 변수, 배열 등 (초기화된 데이터)
stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
Heap : 동적 할당 시 사용 (new(), mallock() 등)
📌[게임 예시]
하나의 프로그램이 실행될 때, 동시에 여러 가지 프로세스가 실행되는 경우들이 있습니다.
크레이지 아케이드라는 게임을 예를 들어보면,
-
게임을 하는 동안 물풍선을 맞고 물속에 갇히는 프로세스,
-
남은 게임 시간을 나타내는 프로세스,
-
다른 캐릭터들이 움직이는 프로세스 등 여러가지 프로세스들이
동시에 진행됩니다.
물풍선을 맞는 하나의 동작도 자세히 살펴보면,
-
물풍선을 맞아서 물안에 갇히는 동작을 구현하는 프로세스
-
물소리가 나는 프로세스
-
갇힌 시간으로부터 일정 시간을 계산하는 프로세스 등
- 그리고 이렇게 한 번의 사건이 발생해서 여러 가지 프로세스들이 실행될 때
우리 눈에는 동시에 진행되는 것처럼 보이지만,
실제로는 cpu는 프로세스 1을 어느 정도 하고 저장하고 프로세스 2를 진행하고 다시 돌아가며 여러 프로세스를 왔다 갔다 하는콘텍스트 스위칭(Context Switching)이 일어납니다.
- 반복이 많아지게 되면 CPU의 부담이 늘어나고, 중복된 자원들이 비효율적으로 관리됩니다.
그럴 때 사용하는 것이 바로멀티스레드입니다.
- 기본적으로 하나의 프로세스가 생성되면 하나의 스레드가 같이 생성되며, 이를 메인 스레드라고 부르며, 스레드를 추가로 생성하지 않는 한 모든 프로그램 코드는 메인 스레드에서 실행됩니다.
- 하나의 프로세스는 여러 개의 스레드를 가질 수 있으며 이를 멀티 스레드라고 합니다.
💡 멀티스레드의 구조를 보면 다음과 같이 Code, Data, Heap영역을 공유하고 있으며, Stack만 스레드 별로 가지게 됩니다.
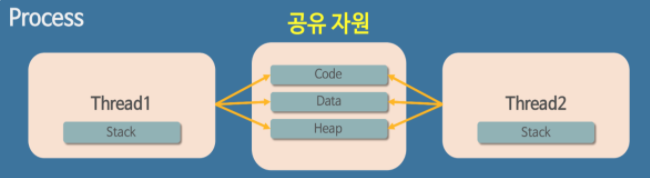
📌멀티 프로세스와 멀티스레드
📌 멀티프로세스
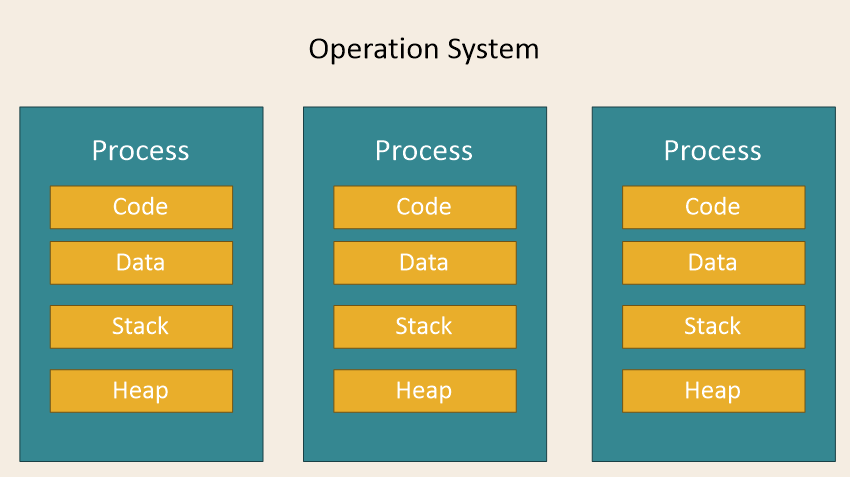
하나의 컴퓨터에 여러 CPU 장착 → 하나 이상의 프로세스들을 동시에 처리(병렬)
예시) 크롬창에 탭을 여러개 켜두고 한개는 네이버, 한개는 구글을 켜는것과 비슷한 느낌
- 여러 개의 프로세스 중 하나에 문제가 발생해도 다른 프로세스에 영향이 확산되지 않음
- 구현이 간단
- 각 프로세스들이 독립적으로 동작(자원이 서로 다르게 할당됨) 하기 때문에 안정적
- 멀티 스레드 보다 많은 메모리 공간과 CPU 시간을 차지
- 작업량이 많을수록 오버헤드가 발생하고 Context Switching으로 인한 성능 저하 우려
장점 : 안전성이 높음 (독립된 구조기 때문에)
단점 : 각각 독립된 메모리 영역을 갖고 있어, 작업량 많을수록 오버헤드 발생. Context Switching 으로 인한 성능 저하
📌 멀티스레드
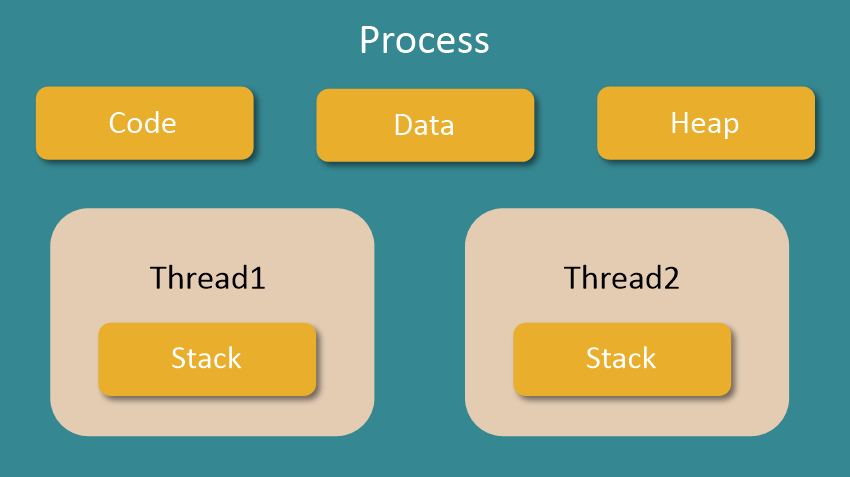
- 하나의 응용 프로그램을 여러 개의 스레드로 구성하여 각 스레드가 하나의 작업을 처리하도록 하는 것
- 좀 더 쉽게 말하자면, 프로그램을 여러 개 켜는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이다
예시) 버전관리 프로그램인 Git 의 브런치 기능과 유사함
📌장점
- 스레드 간의 자원(Code, Data, Heap)을 공유하고 있기 때문에 통신의 부담이 적어 응답 시간이 빠름
- Context Switching이 빠르다.
-> 스레드는 Context Switching시 Stack영역만 처리하면 되므로 스레드 간의 문맥 교환 속도가 빠릅니다. - 프로세스 생성 시 자원을 할당하는 시스템 콜이 줄어들어 자원 소모가 적고 자원을 효율적으로 관리할 수 있습니다.
- 프로세스 간 통신 방법에 비해 스레드 간의 통신 방법이 훨씬 간단합니다.
📌단점
- 여러 개의 스레드를 이용하는 경우, 미묘한 시간차나 잘못된 변수를 공유함으로써 오류 발생 가능
- 그래서 스레드 간에 통신할 경우에는 충돌 문제가 발생하지 않도록 동기화 문제를 해결해야 합니다.
- 단일 프로세스 시스템에서는 효과를 기대하기 어렵습니다.
- 스레드가 개별로 유기적으로 움직이고 있기 때문에 프로그램 테스트, 디버깅이 어려움
- 하나의 스레드의 오류로 전체 프로세스에 문제 발생
- 너무 많은 스레드 사용은 오버헤드를 발생
오버헤드(overhead)는 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 및 메모리등을 말합니다.
📌 멀티 프로세스 대신 멀티 스레드를 사용하는 이유
-
쉽게 말하자면, 프로그램을 여러 개 켜는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이다.
-
자원을 효율성 증대, 처리 비용 감소, 응답 시간 단축
-
프로세스 생성 시 자원을 할당하는 시스템 콜이 줄어들어 자원 소모가 적고 자원을 효율적으로 관리할 수 있습니다.
-
또한 프로세스의 경우 Context Switching 시 CPU 레지스터, RAM과 CPU 사이의 캐시 메모리가 초기화되기 때문에 오버헤드가 큰 반면,
-
스레드는 Context Switching시 Stack영역만 처리하면 되므로 스레드 간의 문맥 교환 속도가 빠릅니다.
-
그리고 프로세스의 경우 프로세스 간의 통신을 위해서는 IPC를 통해서 통신을 해야 하지만, 스레드의 경우 스레드 간의 자원 공유가 간단하기 때문에 시스템 자원 소모가 작습니다.
📌결론
속도감과 자원 절감 -> 멀티 스레드
안정성 - > 멀티 프로세스
