SQL Query 문법 정리
SQL or Query

나무위키 처럼 수시로 업데이트 예정
마지막으로 업데이트 날짜 : 2023-03-29
php 쿼리 수행시 사용되는 내장함수
sql_query => 쿼리를 수행한다는 의미 / 결과값은 object 즉 객체로 온다
sql_fetch => 값처리/ 하나뽑기 / 결과값은 array 즉 배열로 나온다
sql_fetch_array => 값처리 / 여러개뽑기 -for, while 추가사용
SQL SELECT AS
SQL ' AS' 는 테이블 열 또는 테이블에 임시로 새 이름을 지정하는 데 사용됩니다.
쿼리 결과를 쉽게 표시하고 개발자가 테이블 열 또는 테이블 자체의 이름을 영구적으로 바꾸지 않고도 결과에 더 정확하게 레이블을 지정할 수 있습니다.
select 구문을 다음과 같이 살펴보겠습니다.
SELECT Column_Name1 AS New_Column_Name, Column_Name2 As New_Column_Name FROM Table_Name;
여기서 Column_Name은 원래 테이블의 열 이름이고 New_Column_Name은 특정 쿼리에 대해서만 특정 열에 할당된 이름입니다. 이는 New_Column_Name이 쿼리에 할당될 임시 이름임을 의미합니다.
여기에 where 까지 붙여서
SELECT Column_Name1 AS New_Column_Name, Column_Name2 As New_Column_Name FROM Table_Name; WHERE id="0"
이렇게 적으면 Table_Name 에서 id=0 인 row들로 범위를 줄일수 있습니다.
select 문
출처: https://coding-factory.tistory.com/81
SELECT 컬럼명 FROM 테이블명
테이블명에 해당하는 테이블의 칼러명에 데이터를 불러오는 구문
모든 칼럼을 불러오고 싶을때는 컬럼명 부분에 "*" 을 넣으면 된다.
SELECT 컬럼명 FROM 테이블명 WHERE 조건
WHERE 구문을 추가해서 WHERE절 뒤에 오는 조건이 참인 데이터만 불러옵니다.
[컬럼명 = 값] 으로 적을경우 컬럼 명의 값이 지정한 값인 데이터 행의 데이터만 불러옵니다.
SELECT 컬럼명 FROM 테이블명 WHERE 조건 ORDER BY 컬럼명 ASC or DESC
ORDER BY 뒤에 오는 칼럼명을 기준으로 대하여 불러오는 데이터를 정렬합니다.
ASC 는 오름차순, DESC 는 내림차순 입니다. 기본값은 오름차순 입니다.
SELECT 컬럼명 FROM 테이블명 WHERE 조건 ORDER BY 컬럼명 ASC or DESC LIMIT 개수
LIMIT 구문을 추가하여 데이터행이 많을 때에는 LIMIT절의 갯수만큼 데이터를 부러옵니다.
다중테이블 사용시 쓰이는 쿼리
join 문
UPDATE tablea a
INNER JOIN tableb b
ON a.키워드=b.키워드
SET a.검색량=b.검색량
WHERE b.검색량 > 100위의 예는 A테이블과 B테이블을 조인해서 B테이블의 검색량이 100 이상인 것만 A테이블의 검색량을 업데이트 하는 구문입니다.
update, inner join , on, set, where 의 사용예시
- 수정되는 내용 : A테이블의 특정 컬럼의 값을 B 테이블의 특정 컬럼들의 값으로 바꾼다. 조건은 기간이 2022-01-01 부터 2022-01-31 인 것으로.
$sql =
"UPDATE [테이블이름]a INNER JOIN [테이블이름] b
ON a.[어떤컬럼id]=b.[어떤컬럼_id] SET a.[변경하고자하는 컬럼값]=b.[참고하고자 하는컬럼값], a.[변경하고자하는 컬럼값2]=b.[참고하고자 하는컬럼값2]
WHERE b.[time] BETWEEN '2022-01-01' AND '2022-01-31'"
위 $sql 문 내부를 부분부분 나눠서 해석하자면
- "UPDATE [테이블이름1] a INNER JOIN [테이블이름2] b
- 우선 내용을 바꾸고자 하고자하는 주체인
[테이름이름1] a를 먼저 적는다. 여기서 a 는 뒤에서 쉽게 사용되기 위해서[테이블이름1]을 a 로 대체한다 라는 느낌의 a로 생각하면 되겟다.
- 그리고 그 테이블에 join 하는 테이블을 정의해주기 위해서 동일한 형태로
[테이름이름2] b라는 이름으로 적는다
- ON a.[어떤컬럼id]=b.[어떤컬럼_id] SET a.[변경하고자하는 컬럼값]=b.[참고하고자 하는컬럼값], a.[변경하고자하는 컬럼값2]=b.[참고하고자 하는컬럼값2]
-
ON 절의 뒤에는
a.[어떤컬럼id]=b.[어떤컬럼_id]같을때 라는 의미로 사용된다
db 내용이라 상세히는 못적지만 예들들면 서로 다른 테이블이여도 같은 컬럼이 존재하고 그 컬럼이 값이 같다 라는 전제를 말하기 위함이다. 즉 두 컬럼은 테이블만 다른 곳에 각각 존재할뿐 같은 이름의 컬럼이자 같은 value 값을 가진 곳이라고 보면 된다. -
그리고 SET 은 update 문을 사용하기위한 최종목적인
a.[변경하고자하는 컬럼값]=b.[참고하고자 하는컬럼값]을 적는다.
a 특정 컬럼의 value 값을 b 의 특정 컬럼의 value 값으로 할당한다. 쉽게말해서 a 내용을 b 로 바꾸겟다 정도로 이해하면 된다.
- WHERE b.[time] BETWEEN '2022-01-01' AND '2022-01-31'"
- 모든 값들이 아닌 특정한 조건을 부여하기 위해 사용하였다. 여기서는
b테이블에 존재하는time이라는 컬럼값을 기준으로 진행하겠다는 의미이다.
select문 처리 순서
- 문법 순서 -
SELECT - 1
FROM - 2
WHERE - 3
GROUP BY - 4
HAVING - 5
ORDER BY - 6
- 실행 순서 -
FROM - 1
WHERE - 2
GROUP BY - 3
HAVING - 4
SELECT - 5
ORDER BY - 6
on절과 where 차이
대상 테이블
mysql> select * from test_a;
+------+------+
| num1 | num2 |
+------+------+
| 10 | 20 |
| 11 | 21 |
| 12 | 31 |
+------+------+
mysql> select * from test_b;
+------+------+
| num1 | num2 |
+------+------+
| 10 | 20 |
| 1 | 2 |
| 3 | 4 |
+------+------+- where 절에 조건 주었을 때
mysql> select *
-> from test_a LEFT JOIN test_b
-> on (test_a.num1=test_b.num1)
-> where test_b.num2=20;
+------+------+------+------+
| num1 | num2 | num1 | num2 |
+------+------+------+------+
| 10 | 20 | 10 | 20 |
+------+------+------+------+
1 row in set (0.00 sec)- on 절에 조건 주었을 때
mysql> select *
-> from test_a LEFT JOIN test_b
-> on (test_a.num1=test_b.num1 AND test_b.num2=20);
+------+------+------+------+
| num1 | num2 | num1 | num2 |
+------+------+------+------+
| 10 | 20 | 10 | 20 |
| 11 | 21 | NULL | NULL |
| 12 | 31 | NULL | NULL |
+------+------+------+------+
3 rows in set (0.00 sec)on 과 where 의 차이점은 join을 하기전에 실행되느냐 하고나서 실행하느냐에 차이도 있지만
지금예시로 알 수 있듯이
where 은 말그대로 select 문에 일치하는 데이터만을 불러와서 보여주었다면,
on 은 select 기준에 부합하지 않더라도 null 값의 형태를 띄면서 가져온다는 의미도 있따.
모든 테이블(table)에서 특정 컬럼(column) 찾기
MyDatabase의 모든 Table에서 'columnA'나 'columnB'를 찾으려면 다음의 query를 이용한다.
SELECT DISTINCT TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE COLUMN_NAME IN ('columnA', 'columnB')
AND TABLE_SCHEMA='MyDatabase';
예시로 내가 찾고싶은게 mb_id 라는 컬럼이라고 치면
SELECT DISTINCT TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE COLUMN_NAME IN ('mb_id')
AND TABLE_SCHEMA='데이터베이스 이름';
이런식으로 쿼리 실행하면 해당 컬럼이 사용되고 있는 모든 테이블들의 이름이 결과값으로 나온다
출처 : https://glshlee.tistory.com/49
--
replace
SELECT replace("전화번호가 적힌 컬럼 이름",'-','')
FROM "전화번호가 적힌 테이블 이름" where '전화번호가 적힌 컬럼이름'!='';전화번호에서 - 를 제거하고싶을 때 사용하는 replace 이다.
지금 사용하는 양식처럼 적으면 되고 where절 에 추가한 것은 전화번호가 있다면 - 를 빼겠다는 뜻이고 전화번호가 없다면 그냥 넘어간다는 조건문의 의미로 적은 것이다.
update
UPDATE * "원하는 테이블 이름"
"바꾸고자 하는 테이블의 컬럼 명" = replace('전화번호가 있는 컬럼','-','')
where b2b_buisness_num!=''
바꿔야될 컬럼 확인
SELECT [바꿀 컬럼 이름] FROM [바꿀 컬럼이 있는 테이블] where id='아이디값';
업데이트
UPDATE [바꿔야될 테이블] SET [바꿔야될 컬럼]=[바뀌게 내용] where id='아이디값'query
- 일반적인 테이블 전체 정보 보기 -
SELECT * FROM [조회하고자 하는 테이블 이름];- 그 테이블의 특정한 칼럼만 조회하고 싶을때 -
SELECT [특정 칼럼 이름] FROM [테이블 이름];like
1.
$sql_find_[인덱스 번호] = SELECT * FROM [테이블 이름]
WHERE [LIKE 로 찾을 내용이 있는 컬럼] LIKE '%[키워드(찾을 검색내용)]%';
2.
$sql_find_[인덱스 번호] = SELECT [인덱스 번호가 있는 컬럼] FROM [테이블 이름]
WHERE [LIKE 로 찾을 내용이 있는 컬럼] LIKE '%[키워드(찾을 검색내용)]%';
like는 간단히 말하면 지정된 키워드가 있는지 검색을 하기 위한 검색용 쿼리문이다.
LIKE 에 사용법에 대해 간단히 설명하자면 사용방법은 %를 사용해서
우선 이렇게 3가지로 나뉘어 지는데
-
'%키워드' --> 시작하는 내용이 이렇게 있는지
-
'키워드%' --> 끝나는 내용에 키워드가 있는지
-
'%키워드%' --> 내용중에서 시작과 끝 상관없이 키워드가 있는지
'%김덕' ==> '김덕' o // '김덕팔' x
'덕팔%' ==> '덕팔' o // '김덕팔' x
'%김덕팔%' ==> '김덕팔 은 나의 친구이다' o // '김덕자 는 나의 친구이다' x
위와같은 방식으로 해당하는 키워드가 있는지 확인하는 쿼리문이 like 이다.
여기서 내가 하고자 하는것은 특정한 컬럼의 벨류값에 김덕팔 이라는 이름이 있다면 그 이름이 있는 컬럼의 인덱스 번호가 뭔지 찾아보고 싶어서 작성한 형태가 2번째 쿼리문이고
단순히 특정 컬럼의 김덕팔이라는 이름이 있다면 그 row의 정보를 전부다 가지고 오고 싶을때는 1번처럼 작성하면 된다. (1,2번은 원하는 결과가 나오지 않을 확률이 높다)
특수한 상황이 아니라면 3번형태로 사용하는게 제일 무난하다
다중 like
$sql_find_[인덱스 번호] = SELECT * FROM [테이블 이름]
WHERE [LIKE 로 찾을 내용이 있는 컬럼명] LIKE '%[키워드(찾을 검색내용)]%' and
[LIKE 로 찾을 내용이 있는 컬럼명] LIKE '%[키워드 22(찾을 검색내용)]%' or
[LIKE 로 찾을 내용이 있는 컬럼명] LIKE '%[키워드 33(찾을 검색내용)]%' ;
예를들면 지금처럼 만약 한개의 컬럼에서 키워드 여러개가 중복되는 데이터를 찾고 싶을때
지금처럼 and 혹은 or 을 적은 후 like와 컬럼을 여러번 더 적고 사용할 수 있다.
not like
$sql_find_[인덱스 번호] = SELECT * FROM [테이블 이름]
WHERE [LIKE 로 찾을 내용이 있는 컬럼명] NOT LIKE '%[키워드(찾을 검색내용)]%' 어떠한 데이터를 찾을건데 여기서 만약 admin 혹은 test 등의 불필요한 자료는 빼고 나머지 데이터를
추출하고 싶을때 사용하는 쿼리다.
not in
$sql_find_[인덱스 번호] = SELECT * FROM [테이블 이름]
WHERE [NOT IN 으로 찾을 내용이 있는 컬럼명] NOT IN('test1','test2','admin3') 조회하고자 하는 데이터중에 특정한 컬럼을 제외하고 싶을때 사용한다.
not like 와 비슷하게 사용되지만 not like 는 해당하는 단어가 포함된 것을
제외하고 조회하지만, not in 은 정확히 일치하는 데이터만을 제외시킨다는 점이 다르다.
where (1)
- sql 구문중 사용되는 형식으로서 이 형식은 조건절이 여러개 추가될 수 있을때 사용된다
참고로 mysql 에서만 사용 가능하며 oracle 에서는 관계연산자가 부적합하다고 나온다.
다른 DB 에서 이러한 형태로 사용하고 싶다면 where ( 1=1)
로 사용하는게 좋다.
WHERE(1) 의 설명을 더 붙이자면,
php 에서
if (조건절)
{ 실행문 }
처럼
sql 에서도
select 실행문 where 조건절
같은 형태가 있고,
둘다 공통점은 조건절에 아무것도 없으면 에러가 난다는 부분이다.
이러한 에러를 내지 않고 사용하기 위해 사용하는게 바로 이 where (1) 이다
간단한 예로 while(1) { } 같은 형태로 사용할려고 쓰는 where 문이라고 생각하면 되겠다.
case when
- case when 역시 sql query 문에서 사용하는 if문 (조건문) 이라고 생각하면 되겠다.

CASE 표현식은 if 문 방식과 swith 문 방식으로 사용할 수 있다. 주로 if 문과 유사한 방식으로 많이 사용하지만 상황에 따라서 swith 문 방식으로 사용하면 쿼리문을 단순화시킬 수도 있을 듯하다.
- if 문 방식
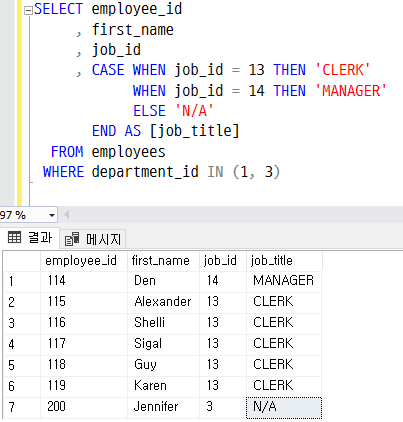
- switch 문 방식
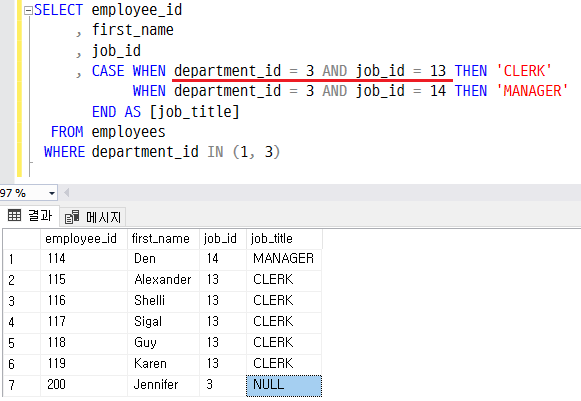
- 조건 여러개 부여하기
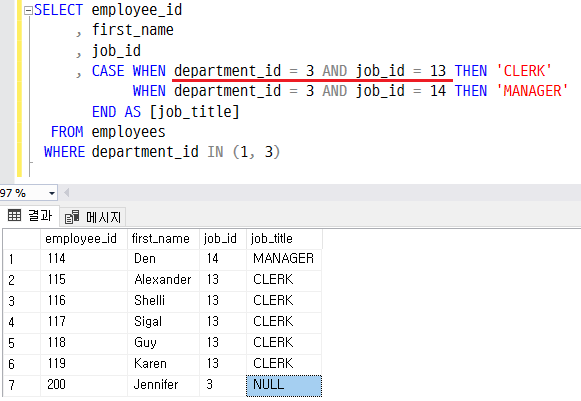
출처 : https://gent.tistory.com/435
order_by field
SELECT * FROM [테이블명] WHERE _id IN (2,1,3)
mysql 에서 쿼리를 짜다 보면 in 으로 던져준 순서대로 값을 얻어오고 싶을때가 있는데 보통은 id값 등으로 정렬이 되어서 나온다.
그럴때 같이 사용하면 좋은게 order_by field 이다.
SELECT * FROM [테이블명] WHERE _id IN (2,1,3) ORDER BY FIELD (_ID,2,1,3)
같은 형태로 사용할 수 있겟다.
기본적으로 order_by field 는 ( ) 에서 첫번째로 적은 컬럼을 , 다음에 있는 순서대로 정렬하는 식으로 사용하고 싶을때 사용된다.
group by
group by 는 동일한 값을 가진 컬럼을 기준으로 그룹별 연산을 적용한다.
having
group by 절에 의해 생산된 결과중 원하는 조건에 부합하는 데이터를 보조가 할때 사용
group by 와 having 에 대해서 설명을 조금 추가하자면,
where 절을 조금 변형해서 사용했다는 느낌이 든다.
상황에 따라서 where 절을 써도 같은 결과가 나올 수도 있지만,
where 절 만으로는 원하는 결과값을 내가 어려울때
그리고 조금더 복잡한 연산이 필요하다든가 하는 상황에서 그룹핑해서 사용해야될 때
주로 사용하는 것 같다.
1번
SELECT mb_hp, count(mb_hp) AS '중복사용된 횟수' from [테이블 이름]
group by mb_hp having count(mb_hp)>1 && count(mb_hp)<4; 2번
SELECT mb_hp, count(mb_hp) AS '중복사용된 횟수' from [테이블 이름]
where count(mb_hp)>1 && count(mb_hp)<4위의 두 쿼리문은 같은 의도로 작성되었다. 휴대폰 번호가 중복으로 사용 되었는지,
사용되었다면 사용된 번호는 어떤거고, 몇번이 사용되었는지를 찾아보기 위한 쿼리문인데
1번과 2번의 차이는 1번은 group by 를 사용하였고 2번은 where 절을 사용하였는데
2번은 실행자체가 되질 않는다.
그누보드 mysql 관련 주요 내장함수 사용법 예제입니다.
- sql_fetch() : 결과 데이터가 1줄일 때 배열로 저장
row = sql_fetch($sql);
echo $row['cnt'];
- sql_fetch_array() : 결과 데이터가 여러줄일 때 1줄씩 가져와서 출력
result = sql_query(row = sql_fetch_array(result)) { print_r2(row);
}
- sql_query() : insert, update, delete 등 실행
sql);
Mysql 특정값 제외하고 Select 하기. Not IN
Mysql 데이터를 Select 할때 일부 필드의 특정값 ( 복수 지정 가능)만 빼고 불러와야 하는 상황이 있는데요.
예를들면 ID라는 필드에 admin, admin1, admin2 라는 관리자 계정을 빼고 불러온다거나...
이런 경우 where 절에 not in 조건으로 지정할 수 있다.
select * from 테이블명 where 필드명 not in ('제외할문자1','제외할문자2'...등);
다음은 구누보드에서의 멤버 테이블 중 지정된 아이디를 제외하고 Select 하는 구문이다.
select * from g4_member where mb_id not in('admin','admin1','admin2');
위의 쿼리를 실행하면
g4_member 테이블에 mb_id 에서 admin, admin1, admin2 만 제외하고 데이터를 불러오게 됩니다.
where절: 부정연산자
- 같지 않음을 표현하는 연산자
!=
^=
<>
전부다 같은 의미라고 생각하면 된다.
(A와 B 값 사이에 있지 않다. )
=> NOT BETWEEN A AND B
list 값과 일치하지 않는다.
=> NOT IN (list)
NULL값을 갖지 않는다.
=> IS NOT NULL
id 값이 공백이 아닌
=> id != ''
=> id ^= ''
=> id <> ''
count
만약 특정 아이디의 게시물 작성자 수를 통계내고 싶은 쿼리르 짜고 싶다면
SELECT mb_id,count(po_id) as '아이디별 게시물 갯수' from ['테이블 이름']
where po_expire_date = '2023-01-26' and po_expired = 0 group by mb_id;지금처럼 사용 하면 된다. 핵심은 group by 인데 요걸 안써주면 그냥 모든 아이값을 더한 숫자와 모든 게시물 숫자를 더한 숫자가 출력되버린다.
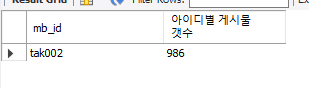
하지만 그룹바이를 추가하면
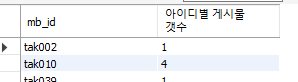
이렇게 내가 원하는 형태로 잘 나오는것을 확인할 수 있다.
참고 : https://galid1.tistory.com/609
정규식을 사용한 SQl
한글로된 결과 찾기
SELECT * FROM MEMBER
WHERE USER_ID REGEXP '[가-힣]';
한글로 시작하는 경우엔 '^[가-힣]'
모두가 한글로 구성된 경우만 검색할경우엔 '^[가-힣]+$'
insert into 문
- 사용되는 용도 : 특정한 데이터를 생성하고 DB 에 추가하려는 상황
즉, 주로 데이터 생성을 할때에 사용되는 sql문 중 하나이다.
기본 insert 문
INSERT INTO 테이블 이름 (열1, 열2, ...)
VALUE (값1, 값2 , ….)where 조건 추가 insert 문
INSERT INTO 테이블이름 ( 열1,열2,열3,열4 ….)
SELECT 테이블에 들어갈 값
FROM selct값을 구하기 위한 테이블
WHERE 조건foreign 키(외래키 있을시 데이터 생성)
해당 테이블에 추가 되는 자료는 내가 작성한 게시물 이라고 가정한다.
그리고 이 게시물은 외래키인 user 테이블의 학생의 id 값을 필요로 한다.
3번열의 값이 외래키로 연결되어 있는
INSERT INTO 테이블이름 ( 열1,열2,열3,열4 ….)
VALUE (
값 1,
값 2,
(SELECT 원하는값 FROM db의 외래키가 있는 테이블 WHERE 내가 원하는 조건,
값4
)기본적인 형태는 이렇게 작성해주면 되겠다.
그리고 위의 값을 실제 예시를 들기 위해 상세하게 적자면 이렇게 작성하면 된다.
INSERT INTO 테이블이름 ( 열1,열2,열3,열4 ….)
VALUE (
값1,
값2,
(SELECT user_id FROM db.user_table WHERE user_id = '1' ),
)그리고 만약에 외래키를 지정해줘야 할때 외래키가 없는데 정확히는 외래키로 지정할 value 값이 없을때에는 임의로 한개를 만들고 다시 실행하면 된다.
외래키가 있을때 데이터 수정
참고출처 : https://mangchhe.github.io/db/2022/01/22/PrimaryForeignKeyUpdate/
상황 : 만약 유저테이블에서 user_id 컬럼중 user_id가 7번인 사람을 8번으로 변경하고싶을때
그런데 user_id를 외래키로 사용하는 테이블이 3개가 있고
이 사람은 한개의 게시물을 작성했다는 가정으로 예들 들어보자.
1개는 게시물 테이블
2개는 게시물 테이블의 댓글,좋아요를 위해 나눠젼 각각의 테이블에
이 3가지 테이블에서 전부다 user_id 를 사용하고 있다는 가정
(쉽게 예를 들기 위해서 게시물은 1개만 작정했다고 가정하자.)해결과정 :
1. 외래키를 사용하는 해당 테이블로 가서 그 유저 아이디 값을 다른값으로 임시로 할당해놓는다
2. 이때 순서는 자식테이블 -> 부모 테이블 순서로 바꾸는게 핵심이다
3. 그래서 위 상황을 예로들면 제일먼저 바꿔야될 곳은 댓글, 좋아요 테이블에서 user_id를 변경
4. 그리고 게시물 테이블에서 다시 user_id를 변경해준다.
5. 이제 유저테이블에서 user_id가 7번인 사람을 외래키로 사용하는곳이 없기때문에 마음껏 바꿀 수 있다.
