
MySQL을 수강하기 전, DATABASE1을 먼저 수강해야 한다는 말에 DATABASE1부터 시작하려한다.
수업 소개
데이터가 중요한 이유는 데이터를 가공하여 많은 일을 할 수 있기 때문이다.
사용하기 위해선 데이터를 저장하고 꺼낼 수 있어야한다.
=> 이를 위한 첫번째 수단은 file이다. => 하지만 파일은 보안이나 성능에 한계를 가지고있다 => 이에 대한 한계를 극복하기 위해 나온 것이 database다.
database를 이욯하면 데이터를 안전하고 빠르고 편리하게 보관하여 사용할수있다
ex) MySQL, Oracle, SQL Server, PostgreSQL, MongoDB 등
목차
- 데이터베이스의 본질 (Create, Read, Update, Delete)
- 파일과 스프레드시트(엑셀)의 비교를 통한 데이터베이스 소개
- 통계에 기반해서 어떤 데이터베이스를 공부할지 스스로 파악하기
데이터 베이스의 본질
출처 영상
데이터베이스는 방대한 기능을 가지고있는 정보 '도구'다.
데이터베이스의 기능이 방대한 것은 데이터 관련해서 일어날 수 있는 일들이 많기 때문이다.
어떤 데이터베이스를 만나건 제일 먼저 해야할 것은
데이터베이스의 데이터를 어떻게 입력(input)하고 어떻게 출력(output)하는 가를 따져보는 것이다.
입력
Create (데이터 생성)
Update (데이터 수정)
Delete (데이터 삭제)
출력
Read (데이터 읽기)
CRUD
이 4가지 작업은 CRUD라고 부른다. 그 외 복잡한 기능들은 CRUD를 보좌하는 부가적인 기능들이다.file vs database
출처 영상
상상력을 발휘하여 우리가 작가라고 생각해보자.
데이터 베이스 제품들에 대한 설명 소개 글을 쓴다고 하면 제일 먼저 할일은 무엇일까
(음.. 아무래도 제목이지 않을까?🙄🤔)
파일의 목록이 1억개라고 상상해보고 노이즈 없이 특정 키워드가 포함된 파일만 골라내고 싶다고 가정하자.
우리는 스프레드 시트를 통해 이런 문제를 해결할 수 있다.
우선 정보들을 정리정돈하기 위해서 구조를 먼저 작성한다.
id, title, description, created, author, profile..

내가 작가 이름이 '김철수' 라는 사람의 글만 보고싶다고 한다면 author에서 '김철수'를 찾으면 될 것이다.
이는 스프레드시트에서는 Data > Filter > autofilter 를 통해 찾아낼 수 있다.
혹은 날짜의 순서를 바꾸고싶다면 컬럼 선택후 Data > Sort > extend selection > 정렬방법 선택
또는 칼럼을 Hide할 수 있는 기능이 있었다.
(스프레드 시트를 배우는 내용이 아니기때문에 가볍게 언급하고 넘어간다.)
데이터 가공의 이점
구조적으로 데이터를 저장할 때 얻을 수 있는 효과는 데이터를 가공하는 것이 훨씬 더 쉬워진다는 것을 볼 수 있다.파일에 비해 스프레드시트는 데이터베이스로 가는 길목에 있다고 할 수 있다. 스프레드시트를 일반적으로 데이터베이스로 보진않지만 넓게보면 데이터베이스적인 특성을 가지고있다.
전문적인 데이터베이스 소프트웨어는 프로그래밍적으로 동작하여 자동화할 수 있다는 이점이 있다.
수업을 마치며
DB-Engines Ranking을 통해 데이터 베이스 랭킹을 보자.
강의에선 2018 버전으로 나오기때문에 2022 버전을 위해 들어가보았다.
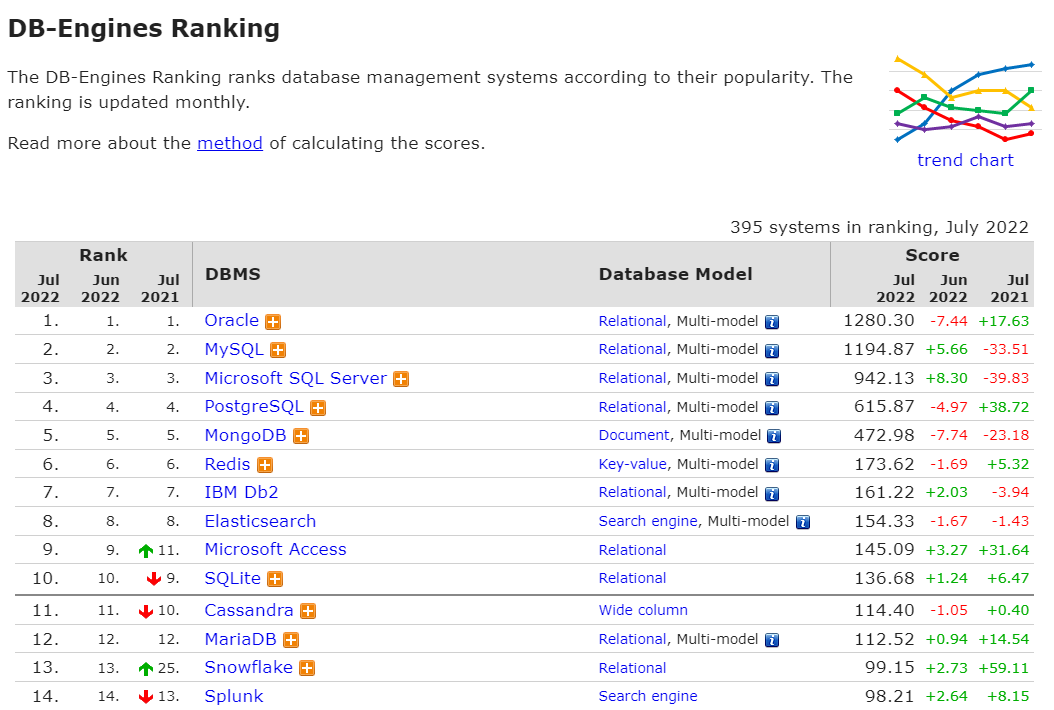
강의와 비교해보니 1~4위는 2018년과 다를게 없었다.
Oracle과 MySQL은 거의 비등한 순위를 갖고있었으며 (오라클과 MySQL은 비슷하기때문에 둘 중 하나를 배우면 둘다 사용할 수 있다고 한다.) 1~4위는 모두 관계형 데이터베이스이다.
데이터베이스 시장의 절대강자는 관계형 데이터베이스라 할 수 있다.
먼저 관계형 데이터베이스를 공부한 후, 관계형 데이터베이스가 아닌 것을 배우는 것을 추천한다고 한다.
두 개의 데이터베이스에 공통적인 특성과 다른 특성을 배울 수 있기때문이다.

Orale
데이터베이스 시장에서 오랫동안 절대강자로 있던 데이터베이스다. 주로 관공서 또는 큰 기업에서 쓴다 (값이 매우 비싸다. 천만원에서 억대까지😨) 오라클은 자금력이 있는 기업이나 정부에서 많이 사용하는 데이터베이스라 보면 된다. 그렇기에 많이 추천하는 데이터베이스는 아니라고 강의에선 언급했다.
MySQL
무료며 오픈소스다. 초심자가 관계형데이터베이스를 배우고싶다면 추천하는 데이터베이스다.
MongoDB
관계형 데이터베이스가 아니다. 다양한 종류의 데이터를 다루기위해서 배우는 것이 좋은 듯하다..gif)