
다음 선행 지식이 있으면 이해하기 더 쉬울거에요 😁
- 1). StateFlow/MutableStateFlow 기초 지식
- 2). MutableStateFlow 의 setValue 와 update 를 사용해본 경험
- 3). 멀티스레드 환경에서 공유자원, 임계영역, 레이스컨디션 기본 CS 개념
- 참고 영상). 쉬운코드님의 동기화, 경쟁 조건, 임계 영역 강의
StateFlow는 Kotlin Coroutine에서 제공하는 관찰 가능한 상태 홀더(StateHolder)이다. 안드로이드에서는 주로 ViewModel에서 UI 상태를 표현하는 용도로 쓰이며, 상태 변경은 MutableStateFlow를 통해 이뤄진다.
private val _uiState = MutableState<UiState>(UiState.IDLE)
val uiState = _uiState.asStateFlow()MutableStateFlow 는 상태를 변경하기 위해 setValue와 update 2가지 함수를 제공한다.
// setValue 방식
_uiState.value = newState
// update 방식
_uiState.update { currentState ->
currentState.copy(...)
}얼핏 보면 비슷해 보이는 이 두 함수는 내부 동작 방식과 사용 시나리오가 아예 다르다.
잘못 사용하면 멀티스레드 환경에서 Race Condition이 발생할 수 있고, 예상치 못한 버그를 만날 수 있다.
이번 포스팅에서는 setValue와 update의 내부 구현을 뜯어보고, 각각의 차이점과 실무에서 어떤 기준으로 사용해야 하는지 정리해보려 한다.
1). MutableStateFlow 의 두 가지 업데이트 방식
안드로이드 개발자에게 친숙한 StateFlow + ViewModel을 활용한 예시로 update와 setValue의 차이를 알아보겠다.
상품(Product) 상태를 ViewModel의 StateFlow로 관리하는 코드다.
class ProductViewModel() {
private val _uiState = MutableStateFlow<ProductState>(UserState.idle())
val uiState: StateFlow<ProductState> = _uiState.asStateFlow()
}주문할 상품의 개수(count)를 변경하기 위해서 setValue와 update 두 가지 방식을 사용할 수 있다.
// ProductViewModel.kt
fun increaseProductBySetValue() {
viewModelScope.launch {
val count = _uiState.value.count
_uiState.value = _uiState.value.copy(count = count + 1)
}
}
fun increaseProductByUpdate() {
viewModelScope.launch {
_uiState.update { currentUiState
val count = currentUiState.value.count
currentUiState.copy(count = count + 1)
}
}
}언듯 보기에는 두 함수의 차이는 없어보인다.
실제로 싱글스레드 환경에서는 두 함수 모두 정상적으로 동작하며 결과도 같다.
하지만, 멀티스레드 환경일 경우에는 두 함수의 동작이 달라진다.
두 함수를 싱글스레드와 멀티스레드 환경에서 각각 실행해보며, 그 차이를 직접 확인해보자.
2). 싱글스레드 vs 멀티스레드 환경에서의 동작 차이
테스트의 편이성을 위해 ACC ViewModel 이 아닌 테스트용 ViewModel을 사용했다.
실제 ViewModel 의 코루틴 동작에는 큰 차이는 없다.
- 참고 1). 예제 코드 깃허브
- 참고 2). 코루틴 테스트가 익숙치 않다면 kotlin Coroutine: 코루틴 테스트 쌩기초 탈출하기 💪 를 봐주세요
✅ 싱글스레드 환경
@Test
fun `싱글 스레드 환경에서 setValue 는 데이터 상태이상이 없다`() = runTest {
// given
val viewModel = ProductViewModel(backgroundScope)
// when
repeat(100_000) {
viewModel.increaseProductBySetValue()
}
runCurrent()
// then
viewModel.uiState.value.count shouldBe 100_000
}
@Test
fun `싱글 스레드 환경에서 update 는 데이터 상태이상이 없다`() = runTest {
// given
val viewModel = ProductViewModel(backgroundScope)
// when
repeat(100_000) {
viewModel.increaseProductByUpdate()
}
runCurrent()
// then
viewModel.uiState.value.count shouldBe 100_000
}✅ 싱글스레드 환경에서는 setValue 와 update 모두 100_000번의 카운트 증가 연산을 수행해도 정확히 100_000 이라는 결과를 반환한다.
⚠️ 멀티스레드 환경
@Test
fun `멑티 스레드 환경에서 setValue 는 데이터 상태 이상이 발생할 수 있다`() {
runBlocking {
// given
val viewModelScope = CoroutineScope(Dispatchers.IO)
val viewModel = ProductViewModel(viewModelScope)
// when
repeat(100_000) {
viewModel.increaseProductBySetValue()
}
viewModelScope.coroutineContext.job.children.forEach {
it.join()
}
// then : ⚠️ 100_000 가 아닌 40114, 59001 와 같은 값이 나옴
viewModel.uiState.value.count shouldNotBe 100_000
}
}
@Test
fun `멀티 스레드 환경에서 update 는 임계영역을 보호하여, 데이터 상태 이상이 발생하지 않는다`() {
runBlocking {
// given
val viewModelScope = CoroutineScope(Dispatchers.IO)
val viewModel = ProductViewModel(viewModelScope)
// when
repeat(100_000) {
viewModel.increaseProductByUpdate()
}
viewModelScope.coroutineContext.job.children.forEach {
it.join()
}
// then : ✅ 정확히 100_000이 나온다.
viewModel.uiState.value.count shouldBe 100_000
}
}멀티스레드 환경에서 해당 테스트를 실행하면 싱글스레드 환경과는 다른 결과가 나온다.
update사용 시: ✅ 100,000setValue사용 시: ⚠️ 90,114, 59,001 등 100,000보다 작은 값
setValue 사용 시, 공유 자원인 uiState 를 조작하는 임계 영역에 여러 스레드가 동시에 접근하면서 레이스 컨디션이 발생하기 때문이다.
반면, update 에서는 여러 스레드가 동시에 uiState 에 접근해도, 하나의 스레드만 uiState를 변경하도록 보장하는 동기화를 시켜주어 안정적으로 값을 갱신한다.
뭐지..? 왜 update만 동기화를 보장하는걸까?
update는 일반적으로 사용되는 상호배제 동기화 기법인 Lock(Mutex, Monitor 등)이 아닌, CAS 연산을 활용한 Lock-Free 알고리즘으로 상태를 안전하게 보호한다.
update의 내부 동작 원리를 이해하려면 원자적 연산과 CAS 연산에 대한 배경지식이 필요하다. 먼저 이 개념들부터 살펴보자 💪
원자적 연산과 CAS 연산에 대한 배경지식이 있으시다면 4. MutableStateFlow update 내부 구현 분석 챕터로 바로 넘어가셔도 됩니다~
3. 배경 지식: 원자적 연산과 CAS
3-1). 원자적 연산(Atomic Operation)이란?
원자적 연산(Atomic Operation)은 더 이상 쪼갤 수 없는 최소 단위의 연산이다. 멀티스레드 환경에서도 원자적 연산 도중에 다른 스레드가 끼어들 수 없음을 보장한다. 덕분에 멀티스레드 환경에서도 데이터 상태를 안전하게 변경할 수 있다.
✅ 원자적 연산의 예시
i = 1단순 대입 연산은 하나의 연산으로 보장되므로 다른 스레드가 중간에 끼어들 수 없다.
따라서, 단순 대입 연산을 원자적 연산이라 한다.
❌ 원자적이지 않은 연산의 예
i = i + 1얼핏 하나의 연산처럼 보이지만, 실제로는 세 개의 연산으로 나뉜다:
- 1). x의 현재 값을 읽는다 (READ)
- 2). 읽은 값에 1을 더한다 (COMPUTE)
- 3). 계산된 값을 x에 다시 저장한다 (WRITE)
CPU 입장에서 i = i + 1은 하나의 원자적 연산이 아니다.
읽기·계산·저장 세 단계로 분리되기 때문에, 멀티스레드 환경에서 여러 스레드가 동시에 실행하면 Race Condition이 발생할 수 있다.
[ Race Condition이 발생하는 상황 ]
아래 과정은 Thread A와 Thread B가 동시에 i = i + 1 연산을 수행하는 상황이다.
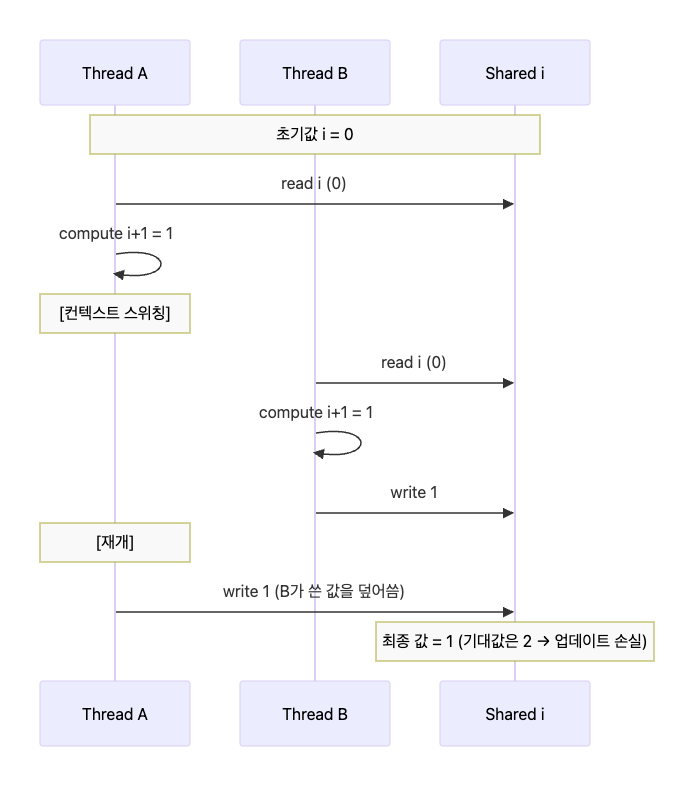
- Thread A가 i를 읽는다 (i = 0)
- Thread A가 +1 연산을 수행한다 (0 + 1 = 1)
- Context Switching → Thread B로 전환
- Thread B가 i를 읽는다 (i = 0)
- Thread B가 +1 연산을 수행한다 (0 + 1 = 1)
- Thread B가 연산 결과를 i에 저장한다 (i = 1)
- Context Switching → Thread A로 전환
- Thread A가 연산 결과를 i에 저장한다 (i = 1)
결과: i = 1 (기대값: 2) ⚠️ 데이터 상태 이상 발생
두 스레드가 각각 +1 연산을 수행했지만, 최종 결과는 2가 아닌 1이 된다.
이는 i = i + 1 가 원자적이지 않기 때문에 데이터 상태 이상이 발생했고, 이를 Race Condition이라 한다.
3-2). 원자적이지 않은 setValue()의 문제점
fun increaseProductBySetValue() {
viewModelScope.launch {
val count = _uiState.value.count
_uiState.value = _uiState.value.copy(count = count + 1)
}
} 앞서 살펴본 increaseProductBySetValue() 메서드도 원자적이지 않다.
이 함수는 다음과 같이 여러 단계로 나뉜다:
- 1). _uiState.value를 읽어온다
- 2). 읽어온 값의 count를 변수에 할당한다
- 3). 읽어온 값의 count에 1을 더한다
- 3). 새로운 객체를 생성한다 (copy)
- 4). 생성된 객체를 _uiState.value에 할당한다
increaseProductBySetValue()는 위와 같이 5단계로 쪼개지기 때문에 원자적 연산이 아니다.
멀티스레드 환경에서는 여러 스레드가 이 5단계 중간에 끼어들 수 있고, 그 결과 Race Condition이 발생한다. 이것이 해당 함수를 100,000번 실행했음에도 90,114 나 59,001 값이 나온 이유다.
그럼, 이제 CAS(Compare-And-Set)이라는 원자적 연산을 배우고 이를 활용하여 멀티스레드 환경에서도 안전하게 값을 갱신하는 방법을 알아보자.
3-3). CAS(Compare-And-Set) 연산
CAS(Compare-And-Set) 연산은 현재 값(current)이 기대한 값(expect)과 같으면 새 값(new)으로 바꾸는 원자적 연산이다.
CAS 연산은 Lock(Mutex, Monitor)을 사용하지 않고도 멀티스레드 환경에서 안전하게 공유자원을 갱신할 수 있는 기법이다. Java의 AtomicInteger가 대표적인 예시이다.
val count = AtomicInteger(1)
// ✅ CAS 성공: current(1) == expect(1) → count를 2로 갱신
count.compareAndSet(1, 2) // true 반환
// ❌ CAS 실패: current(2) != expect(1) → count 값 갱신 X
count.compareAndSet(1, 3) // false 반환근데, compareAndSet도 아래와 같이 여러 단계로 나뉘는 것 아닌가?🤔
CAS 연산도 논리적으로는 두 단계로 나뉜다.
- 1). current 값을 메인 메모리로부터 읽어온다.
- 2). current 값이 expect 와 같으면 new 값으로 바꾼다.
하지만 중요한 차이점이 있다.
CAS 연산은 이 두 단계를 CPU 하드웨어 차원에서 하나의 원자적 연산으로 제공한다.
CPU가 특별한 명령어를 통해 위 두 과정을 원자적으로 처리하기 때문에, CAS 연산 도중에는 다른 스레드가 절대 개입할 수 없다.
즉, CAS 연산은 소프트웨어 레벨의 여러 명령어가 아닌, 하드웨어가 보장하는 단일 원자적 연산이다.
3-4). CAS Lock-Free 알고리즘
이번에는 CAS 연산을 활용해 i = i + 1과 같은 비원자적 연산을 안전하게 수행하는 방법을 살펴보자.
val current = AtomicInteger(current)
fun increaseSafely() {
while (true) {
val expect = atomicInteger.get() // 예상 값
val update = expect + 1 // 변경할 값
// ✅ current 가 expect과 동일할 때만 update로 변경
if (current.compareAndSet(expect, update)) {
return
}
}
}갑자기 while 문이 나와서 당황할 수 있는데.. 🤯
이는 +1 연산과 CAS 연산 사이에 다른 스레드가 끼어들 때, 실패 처리 후 재시도하기 위함이다.
글로는 이해하기 매우 어렵기 때문에, 그림을 통해 이해해보자.
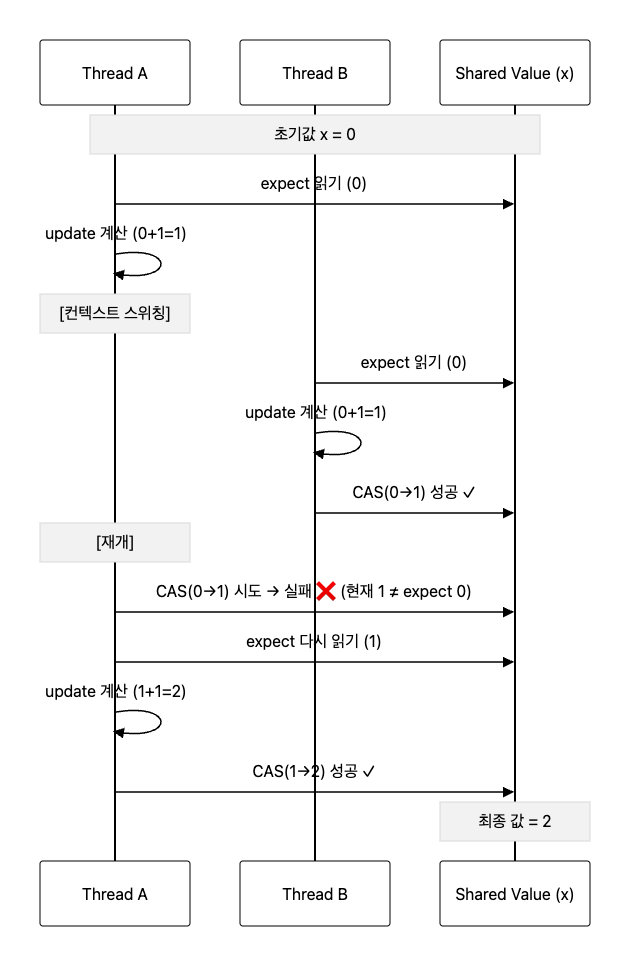
- Thread A가 expect 값을 읽는다. (expect = 0)
- Thread A가 +1 연산 수행, 결과를 update에 저장 (update = 1)
- Context Switching → Thread B로 전환
- Thread B가 expect 값을 읽는다 (expect = 0)
- Thread B가 +1 연산 수행, 결과를 update에 저장 (update = 1)
- Thread B: expect(0) == current(0) → update = 1 할당 → ✅ CAS 성공
- Context Switching → Thread A로 전환
- Thread A: expect(0) ≠ current(1) → ❌ CAS 실패
- Thread A는 다시 while 루프를 돌아 1, 2번 과정 진행 (expect=1, update=2)
- Thread A: expect(1) == current(1) → update(2) 할당 → ✅ CAS 성공
최종 결과: current = 2 ✅
이렇게 CAS Lock-Free 알고리즘은 CAS 연산 실패 시 루프를 돌며 재시도한다.
Syncronized 와 같은 Lock 없이 데이터를 안전하게 변경할 수 있어 Lock-Free하다고 한다.
4. MutableStateFlow update 내부 구현 분석
4-1). update 함수의 CAS Lock-Free 구현
MutableStateFlow 의 update 내부 코드를 살펴보자
public inline fun <T> MutableStateFlow<T>.update(function: (T) -> T) {
while (true) {
val prevValue = value
val nextValue = function(prevValue)
if (compareAndSet(prevValue, nextValue)) {
return
}
}
}update는 위 3-4). CAS Lock-Free 알고리즘
챕터의 increaseSafely() 예제와 거의 똑같다. 다른 점은 아래 두가지이다:
- 1).
+1 연산대신function()람다를 실행한다 - 2). AtomicInteger의 compareAndSet이 아닌 MutableStateFlow의 compareAndSet()을 사용한다
즉, update함수는 CAS Lock-Free 알고리즘을 통해 멀티스레드 환경에서도 안전하게 value 값을 갱신하는 점을 알 수 있다.
동작 과정을 정리하면:
- 현재 value를 읽는다 (prevValue)
- 람다 함수를 실행해 새 값을 계산한다 (nextValue)
- CAS 연산으로 prevValue를 nextValue로 변경 시도
- 성공하면 종료, 실패하면 1번부터 다시 반복
이 방식으로 여러 스레드가 동시에 update를 호출해도, 각 스레드의 변경사항이 모두 안전하게 반영된다.
4-2). compareAndSet 내부 동작
그럼, MutableStateFlow 의 compareAndSet이 어떻게 구현되어 있는지 살펴보자
// StateFlowImpl.kt
private val _state = atomic(initialState) // T | NULL
override fun compareAndSet(expect: T, update: T): Boolean =
updateState(expect ?: NULL, update ?: NULL)
private fun updateState(expectedState: Any?, newState: Any): Boolean {
var curSequence: Int
var curSlots: Array<StateFlowSlot?>? // benign race, we will not use it
synchronized(this) {
val oldState = _state.value
if (expectedState != null && oldState != expectedState) return false // CAS support
if (oldState == newState) return true // Don't do anything if value is not changing, but CAS -> true
_state.value = newStateMutableStateFlow의 실구현체인 StateFlowImpl 코드이고, updateState 함수에서 CAS 실패/성공 처리를 해주고 있다.
CAS 실패 처리
synchronized(this) {
val oldState = _state.value
if (expectedState != null && oldState != expectedState) return false // ❌ CAS 실패현재값(oldState)이 기대값(expectedState)과 다르면 false를 반환해 CAS 연산 실패를 처리한다.
CAS 성공 처리
synchronized(this) {
...
// ✅ CAS 성공
// 참고로 아래 조건문 때문에 StateFlow 에 같은 값이 들어오면 변경 이벤트를 구독자에게 방출하지 않는 특성이 여기서 나온다.
if (oldState == newState) return true
_state.value = newStateCAS 연산에 성공하면 값을 newState로 값을 갱신한다.
update 내부 코드가 이렇게 멀티스레드 환경에서도 상태를 안정적으로 업데이트해주는 것을 확인할 수 있었다. 그럼 내부 코드를 보면서 생길 수 있는 궁금증들에 대해 정리해보자.
4-3). 🤔 compareAndSet을 왜 synchronized로 구현했을까?
MutableStateFlow 의 compareAndSet() 는 syncronized 모니터 락을 활용하여 CAS 연산을 구현하고 있다.
나는 Java의 Atomic API처럼 CPU가 제공하는 실제 원자적 연산을 기대했는데, synchronized를 사용해서 조금 의외였다. 아마 단순히 value 업데이트뿐만 아니라 구독자들에게 이벤트를 방출하는 코드도 함께 처리해야 하기 때문인 것 같다.
실제로 updateState 메서드는 값 변경 외에도:
- 시퀀스 번호 증가
- 구독자 슬롯 관리
- 변경 이벤트 알림
등의 작업을 함께 수행하기 때문에, 이 모든 작업을 안전하게 처리하기 위해 synchronized를 사용한 것으로 개인적인 추측을 해본다.
혹시 이에 대해 더 정확한 이유를 아는 분은 댓글로 알려주시면 감사하겠다! 🙏
4-4). 🤔 Update 는 왜 상호배제 Lock 이 아닌 CAS로 구현했지?
CAS Lock-Free 알고리즘과 상호배제 Lock은 각각 아래와 같은 특징을 갖는다:
- CAS(Compare-And-Set)는 실패 시 while 루프를 돌며 재시도하기 때문에 CPU 자원을 소모하지만, 충돌이 적고 연산이 매우 짧을 때 유리하다.
- 상호배제 Lock은 OS 차원의 컨텍스트 스위칭 비용이 발생하지만, 복잡한 연산이나 긴 임계 구역 처리에 적합하다.
update는 간단한 상태 변경에 사용하는 함수이므로, 이런 특성에 맞춰 CAS Lock-Free 방식을 채택한 것으로 유추해볼 수 있다.
5. update 함수 사용 시 유의점
5-1). 무거운 작업을 넣으면 절대 안된다
update 함수는 앞서 살펴본 것처럼 내부적으로 CAS Lock-Free 알고리즘으로 구현되어 있다.
CAS 연산은 나노초(ns) 단위의 짧은 연산에 최적화되어 있기 때문에 update{} 람다 블록 안에 서버 통신이나 무거운 CPU 작업을 넣으면 절대 안 된다. 반드시 가벼운 상태 갱신만 수행해야 한다.
만약 update 블록 내에 무거운 작업을 넣으면 다음과 같은 문제가 발생할 수 있다:
- CAS 실패 시 무거운 작업이 반복 실행되어 심각한 성능 저하 초래
- 여러 스레드가 경쟁하면서 CPU 자원을 과도하게 소모
- 응답 지연으로 인한 ANR 발생
❌ 잘못된 사용 예시
// ❌ Bad
_uiState.update { prevState ->
// 복잡한 CPU 계산 절대 금지 ❌
val data1 = cpuIntensiveTask()
// IO 작업 절대 금지 ❌
val data2 = repository.getData2()
prevState.copy(data1 = data1, data2 = data2)
}✅ 올바른 사용 예시
// ✅ Good
val data1 = cpuIntensiveTask()
val data2 = repository.getData2()
// update는 간단한 상태 변경만!
_uiState.update { prevState ->
prevState.copy(data1 = data1, data2 = data2)
}무거운 작업은 update 밖에서 처리하도록 하자!
5 - 2). 새로운 객체 생성 시에는 setValue를 사용하자
가끔 update 함수를 아래와 같이 새로운 객체를 생성해서 사용하는 경우를 볼 수 있었다.
// ❌ Bad
_uiState.update {
UiState(...)
}update 함수는 이전 상태값을 기반으로 상태를 갱신할 때 사용하는 함수다.
새로운 값을 할당할 때는 setValue를 사용하는 것이 더 적절하다.
// ✅ GOOD - 새로운 객체 할당은 setValue 사용
_uiState.value = UiState(...)
// ✅ GOOD -이전 상태 기반 업데이트는 update 사용
_uiState.update { prevState ->
prevState.copy(count = prevState.count + 1)
}이렇게 용도에 맞게 구분해서 사용하면 코드의 의도가 더 명확해진다.
6). ⭐️ 실무 관점에서 setValue vs update
실무에서 setValue와 update를 무분별하게 섞어 쓰는 경우를 정말 많이 봤다.
이로 인해 팀 내에서 코드의 의도가 모호해지고, 멀티스레드 환경에서는 예기치 않은 상태 불일치가 발생하기도 했다.
그래서 나는 다음과 같은 기준으로 두 함수를 명확히 구분해 사용하자고 제안했고,
이 기준은 현재 우리 팀의 컨벤션으로 정착되었다.
나는 멀티스레드 환경과 무관하게 아래 기준에 따라 update 와 setValue 함수를 사용하고 있다.
6-1). 새로운 값을 할당하는 경우 → setValue 사용
멀티스레드 환경에서 setValue 쓰면 위험하지 않나?
이전 상태값을 기반으로 업데이트하는 경우에만 위험하다. 아래처럼 단순히 새로운 State를 만들어서 할당하는 경우는 안전하다.
_uiState.value = UiState(...)StateFlowImpl의 setValue도 내부적으로 updateState에서 synchronized 모니터락을 걸고 있기 때문에, 단순 할당은 안전하게 처리된다.
private class StateFlowImpl<T>(
...
private val _state = atomic(initialState) // T | NULL
public override var value: T
get() = NULL.unbox(_state.value)
set(value) { updateState(null, value ?: NULL) }
private fun updateState(expectedState: Any?, newState: Any): Boolean {
...
synchronized(this) {
...
_state.value = newState6-2. 토글과 같이 이전 상태값을 기반으로 업데이트하는 경우 → update 사용
멀티스레드 환경이 아닐 경우에 update를 사용하면 CPU 낭비 아닌가요?
싱글스레드 환경에서는 update 를 활용하여 원자적으로 처리하지 않아도 된다.
싱글스레드 환경에서는 CAS 연산의 실패가 일어나지 않기 때문에 compareAndSet이 false를 반환할 일이 없어 while 루프가 한 번만 실행된다.
참고로, 간단한 성능 테스트 해본 결과 싱글 스레드환경에서 setValue 와 update 의 성능 차이는 없었다.
_uiState.update { preState ->
preState.copy(...)
}오히려 update를 사용하면 이전값을 람다 파라미터로 받을 수 있어 가독성 측면에서 더 뛰어나다고 생각한다.
7. 마무리
이번 포스팅에서는 MutableStateFlow의 setValue와 update의 차이점을 내부 구현까지 깊이 파헤쳐봤다.
지금까지 배운 내용을 정리하면:
[ 멀티스레드 안정성 ]
setValue함수는 원자적이지 않다 → value = value + 1 같이 이전값을 기반으로 값을 갱신하는 패턴은 안전하지 않다.update함수는 CAS 루프 기반이므로 멀티스레드 환경에서도 안전하게 동작한다.
[ 사용 기준 ]
- 새로운 값 할당 → setValue
- 이전값 기반 업데이트 → update
[ update 사용 시 주의사항 ]
- update 블록 내에는 반드시 가벼운 연산만 넣을 것
- 무거운 작업은 블록 외부에서 처리 후 결과값만 반영
해당 포스팅을 읽고 나서 독자들의 팀원들과 함께 setValue 와 update 의 일관된 사용 기준을 정해보길 권한다.
단순히 "멀티스레드 환경에서는 update를 써야 한다"고 외우는 것보다, 각 함수의 내부 동작 원리를 이해하고 팀의 상황에 맞게 선택해서 사용하는 것이 훨씬 중요하다.
