1. Why?
기상 알람 프로젝트를 진행하면서 Scheduler를 사용했습니다. 유저마다 기상 알람 시간이 천차만별이라고 예상되는데, 이를 위해 Scheduler를 매분마다 실행시켜 기상 알람을 보내는 것은 굉장한 리소스 낭비라고 생각했습니다.
때문에 Batch 작업을 통해 하루에 보내야 할 알람들을 미리 한 번에 가져와 성능을 개선하고자 Spring Batch를 도입하기로 했습니다.
개발에 앞서 Batch에 대한 학습 내용을 기록하고자 합니다.
2. Batch Processing이란 무엇인가?
컴퓨팅에서 여러 작업이나 데이터를 모아서 한꺼번에 처리하는 데이터 처리 방식입니다. 이는 실시간 처리와 대비되는 개념으로, 일정량의 데이터를 모아 한 번에 처리함으로써 대량의 데이터를 효율적으로 처리하고, 시스템 자원의 활용을 극대화하는 데 유용합니다. 배치 처리는 실시간 처리가 필요 없는 작업에 적합합니다.
3. Batch Processing을 왜 사용하는가?
-
효율성: 대량의 데이터를 한 번에 처리함으로써 시스템 리소스를 효율적으로 사용할 수 있습니다.
-
비용 절감: 피크 시간(유저가 주로 사용하는 시간대)을 피해 작업을 수행함으로써 컴퓨팅 비용을 줄이고 성능 저하를 방지할 수 있습니다.
-
일관성: 대량의 데이터를 일괄적으로 처리, 반복적인 작업을 동일한 방식으로 수행하므로 결과가 일관됩니다.
-
신뢰성: 자동화된 프로세스는 휴먼 에러를 줄이고, 시스템 오류를 쉽게 감지하고 수정할 수 있습니다.
-
시스템 부하 관리: 실시간 처리로 인한 시스템 과부하를 방지할 수 있습니다.
정리하자면, 대량의 데이터를 한 번에 처리함으로써 리소스를 효율적으로 사용할 수 있습니다. 또한 사람의 개입을 최소화하고 반복 작업을 보다 효율적으로 실행할 수 있기 때문에 일관성과 신뢰성을 얻을 수 있습니다.
4. Batch Processing이 어디에 쓰이는가?
-
금융 서비스
신용카드 청구서 생성: 월말에 고객의 모든 거래를 집계하여 청구서를 생성합니다. -
소매업
재고 관리: 매일 밤 판매 데이터를 분석하여 재고를 업데이트하고 발주 목록을 생성합니다. -
인사 관리
급여 처리: 월말에 직원들의 근무 시간, 휴가, 보너스 등을 계산하여 급여를 일괄 처리합니다. -
IT 운영
백업 및 아카이빙: 주기적으로 시스템 데이터를 백업하고 오래된 데이터를 아카이빙합니다.
로그 파일 정리: 시스템 로그 파일을 일정 주기마다 정리하여 디스크 공간을 확보하고, 로그 데이터를 분석합니다.
5. Spring Batch란 무엇인가?
배치 애플리케이션을 개발할 수 있도록 설계된 가볍고 포괄적인 배치 프레임워크입니다. 스프링 프레임워크 기반에서 작동합니다.
6. 그러면 Batch랑 Scheduler의 차이가 무엇인가?
간단히 Batch는 작업이나 데이터를 모아서 한꺼번에 처리하는 데이터 처리 방식이고, Scheduler는 주어진 작업을 미리 정의된 시간에 실행될 수 있게 해주는 도구나 소프트웨어를 의미합니다.
7. Spring Batch의 처리 흐름 (⭐⭐)
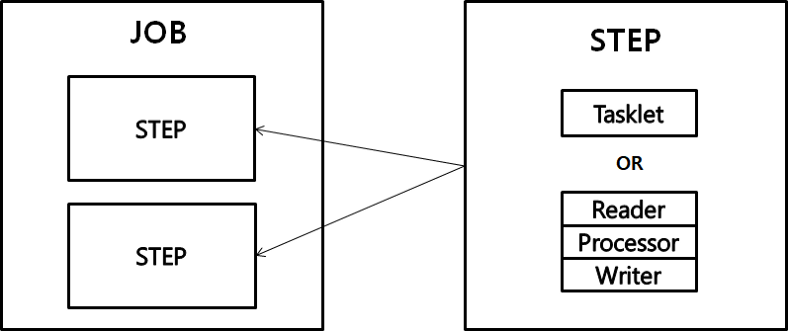 먼저 Job이란 전체 Batch 프로세스를 나타내는 객체로 Step으로 구성되어 있습니다.
먼저 Job이란 전체 Batch 프로세스를 나타내는 객체로 Step으로 구성되어 있습니다.
Step은 Job 내의 하나의 독립적인 작업 단위로, 실제 배치 처리 작업이 이루어집니다. 각 Step에서 데이터를 처리하는 방식은 Tasklet과 Chunksize가 있습니다.
이때 Chunksize(이하 Chunk)는 ItemReader / ItemRrocessor / ItemWriter 로 구분되어 처리됩니다.
대량의 데이터를 처리하는 데 적합하고, 프레임워크가 효율적으로 메모리 관리를 해줄 수 있는 Chunk 방식을 프로젝트에 도입하였습니다. 때문에 Chunk 방식으로 기록하겠습니다.
(Tasklet vs Chunk 두 방식의 차이점은 따로 블로그에 작성하도록 하겠습니다.)
전체적인 흐름은 다음과 같습니다.
-
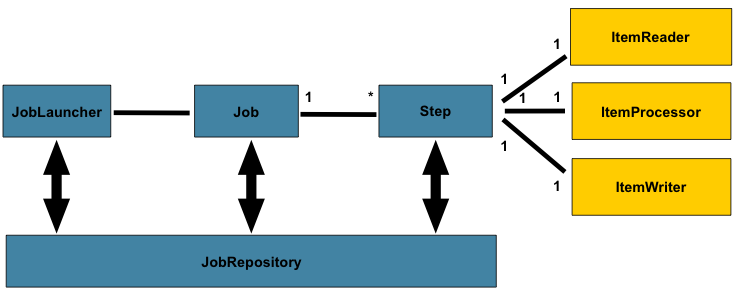
Job 실행 요청
JobLauncher(Job을 실행하는 인터페이스)를 통해 Job 실행이 요청됩니다. 이때JobParameters를 통해 실행에 필요한 파라미터를 전달할 수 있습니다. -
Job 실행
JobRepository(Job의 실행 정보JobExecution, Step의 실행 정보StepExecution, 메타데이터 등을 저장하고 관리하는 메커니즘)에서 이전 실행 정보를 확인합니다.
Job이 실행될 때,JobRepository는 새로운JobExecution과StepExecution을 생성하고, 이를 통해 실행 상태를 추적합니다.
이후 Job의 구성요소인 Step들을 순차적으로 실행합니다. -
Step 실행(Chunk방식 사용)
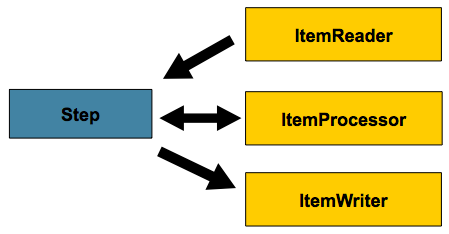
ItemReader를 통한 데이터 읽기: DB, 파일 등 데이터 저장소로부터 데이터를 읽어옵니다.
ItemProcessor를 통한 데이터 처리: 읽어온 데이터에 대해 비즈니스 로직을 적용합니다. 그 예로 데이터 필터링, 변환, 검증 등이 있습니다.
ItemWriter를 통한 데이터 쓰기: 처리된 데이터를 DB, 파일 등 데이터 저장소에 저장합니다. -
Chunk 처리 반복
3단계 과정을 반복하여 모든 데이터를 처리합니다.
각 Chunk 처리가 완료될 때마다 트랜잭션이 커밋됩니다. -
Step 완료
모든 Chunk 처리가 완료되면 Step이 종료됩니다.
Step의 실행 결과가JobRepository에 저장됩니다. -
다음 Step 실행
Job 내의 다음 Step으로 이동하여 위 3,4,5 과정을 반복합니다. -
Job 완료
모든 Step이 완료되면 Job이 종료됩니다. 이때 Job의 최종 실행 결과가 JobRepository에 저장됩니다. -
실행 결과 반환
JobLauncher는 Job 실행 결과를 반환합니다.
8. 마치며
Spring Batch를 적용시키면 유의미한 성능 개선이 있으리라 생각듭니다. 정확히 얼마나 성능이 개선되는지는 측정을 해봐야할 것 같습니다. 다음 편에서는 프로젝트에 직접 적용시킨 내용과 어떻게 성능이 개선되었는지를 다루겠습니다.
참고 문서:
AWS 공식 문서
Spring Batch란? 이해하고 사용하기(예제소스 포함)
Spring Batch란? 간단한 개념과 코드 살펴보기
