
📌 1장. 데이터의 이해
1. 데이터와 정보
1) 데이터의 정의
- 데이터(Data)는 보통 연구나 조사 등의 바탕이 되는 재료 혹은 자료를 의미한다.
2) 데이터의 특성
- 데이터: 있는 그대로의 사실, 가공되지 않은 자료를 의미한다. => 객관적인 사실
- 정보: 데이터로부터 얻은 것, 가공된 자료를 의미한다.

3) 데이터의 유형
-
정성적 데이터와 정량적 데이터
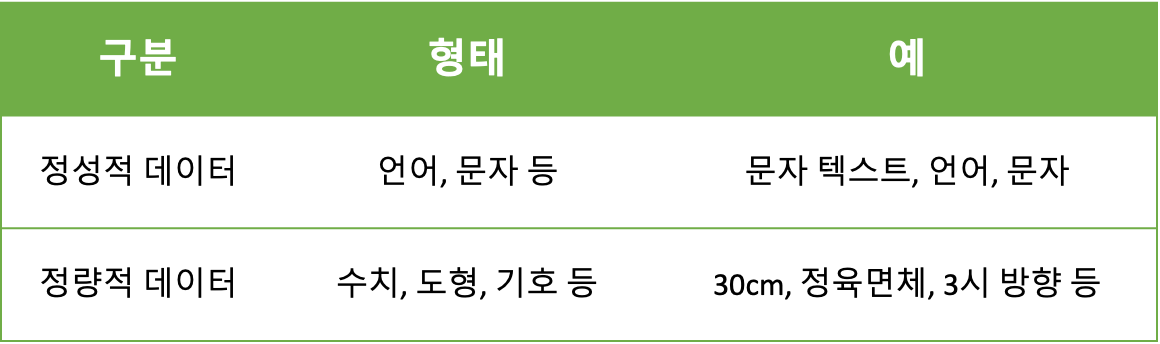
-
정형, 비정형, 반정형 데이터

-
암묵지와 형식지
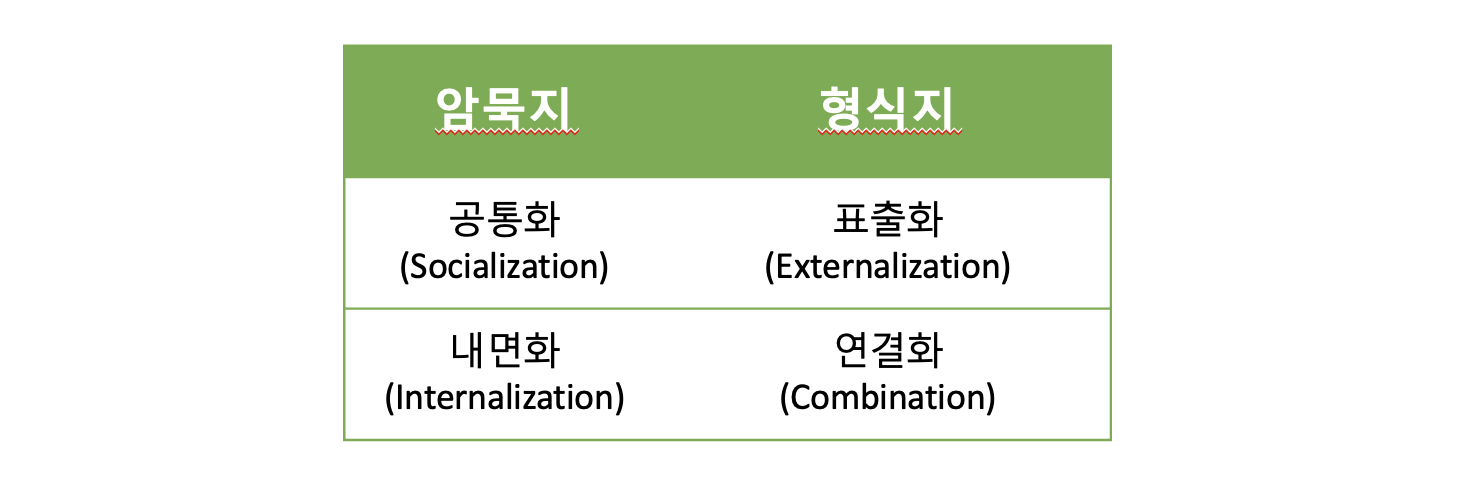
- 암묵지(Tacit Knowledge): 학습과 체험을 통해 개인에게 습득되어 있지만, 겉으로 드러나지 않은 상태의 지식
- 형식지(Explicit Knowledge): 암묵지가 문서나 메뉴얼처럼 외부로 표출돼 여러 사람이 공유할 수 있는 지식
- 암묵지와 형식지의 상호작용: 공유화되기 어려운 암묵지가 형식지로 표출되고 연결되면 그 상호작용으로 지식이 형성된다.
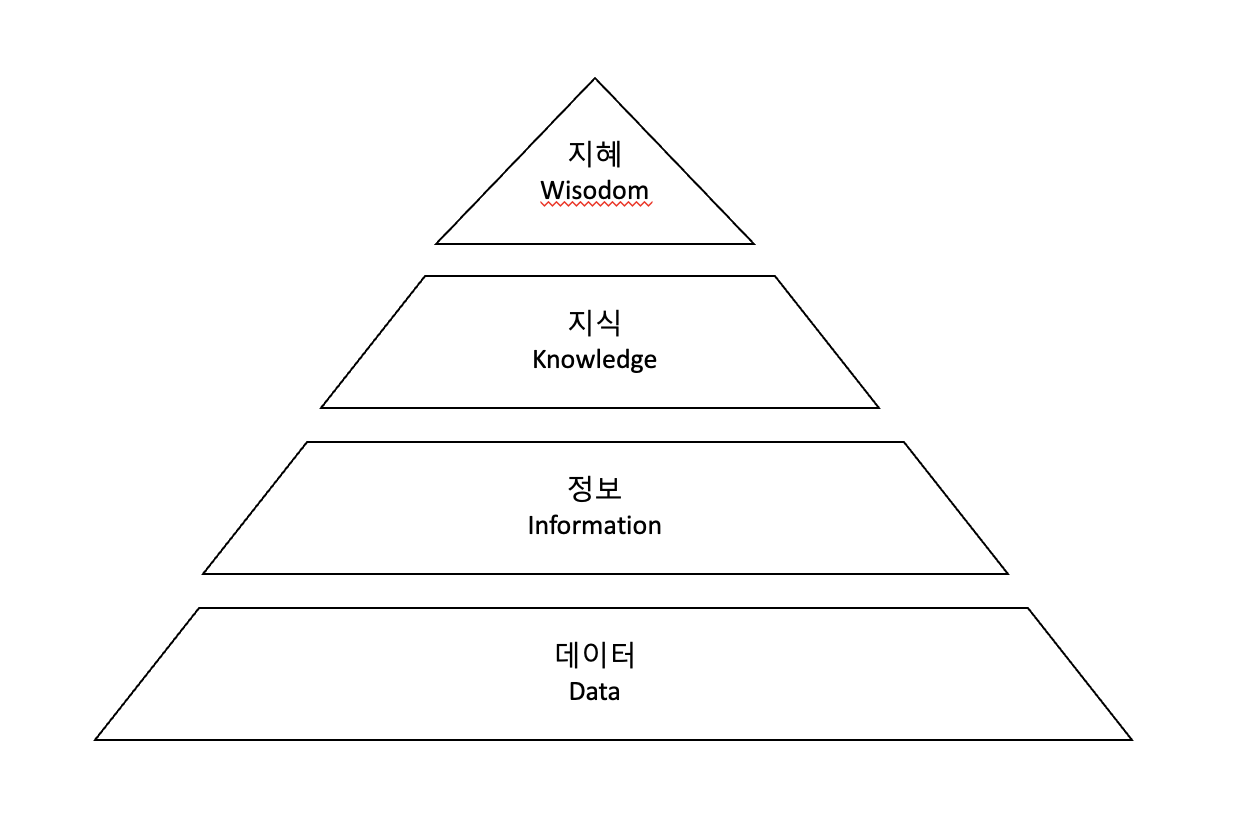
4) DIKW 피라미드
- 데이터(Data): 개별 데이터 자체는 의미가 중요하지 않은 객관적인 사실
- 정보(Information): 데이터의 가공•처리와 데이터간 연관관계 속에서 의미가 도출된 것
- 지식(Knowledge): 데이터를 통해 도출된 다양한 정보를 구조화하여 유의미한 정보를 분류하고 개인적인 경험을 결합해 고유의 지식으로 내재화된 것
- 지혜(Wisdom): 지식의 축적과 아이디어가 결합된 창의적 산물
5) 데이터에 관한 상식
- 비트와 바이트
- 비트(bit): 0과 1의 두 가지 값으로 신호를 나타내는 최소단위
- 바이트(byte): 8개의 비트로 구성된 데이터의 양을 나타내는 단위
- 데이터 단위
- 1byte = 8bit(비트)
- 1KB = 1024byte(바이트)
- 1MB = 1024KB(킬로바이트)
- 1GB = 1024MB(메가바이트)
- 1TB = 1024GB(기가바이트)
- 1PB = 1024TB(테라바이트)
- 1EB = 1024PB(페타바이트)
- 1ZB = 1024EB(엑사바이트)
- 1YB(요타비트) = 1ZB(제타바이트)
2. 데이터베이스
1) 데이터베이스 개요
-
데이터베이스 정의

-
데이터베이스의 일반적인 특징

-
데이터베이스의 다양한 측면에서의 특성

-
데이터베이스 구성요소
- 인스턴스(Instance): 하나의 객체를 의미하며, 존재하는 모두 인스턴스가 될 수 있다.
- 속성(Attribute): 객체를 표현하기 위해 사용되는 값을 의미한다.
- 엔터티(entity): 데이터의 집합을 의미한다. 2개 이상의 인스턴스와 1개 이상의 속성을 보유하고 있어야 한다.
- 인덱스(Index): 데이터베이스에서 데이터를 저장할 때 내부에서 자동적으로 데이터의 이름을 지정하게 되는데, 이때 부여되는 이름들을 인덱스라고 한다.
-
데이터의 트랜잭션 특성
- 트랙잭션(Transaction)
- 원자성(Atomicity): 트랜잭션이 데이터베이스에 모두 적용되거나 또는 모두 적용되지 않아야 한다.
- 일관성(Consistency): 트랜잭션의 결과는 항상 일관성을 띠어야 한다.
- 고립성(Isolation): 하나의 트랜잭션이 다른 트랜잭션에 영향을 주지 않아야 한다.
- 지속성(Durability): 트랜잭션이 성공적을 수행된 경우 그 결과는 영구적이어야 한다.
- 트랙잭션(Transaction)
2) 데이터베이스 활용
-
기업 내부의 데이터베이스
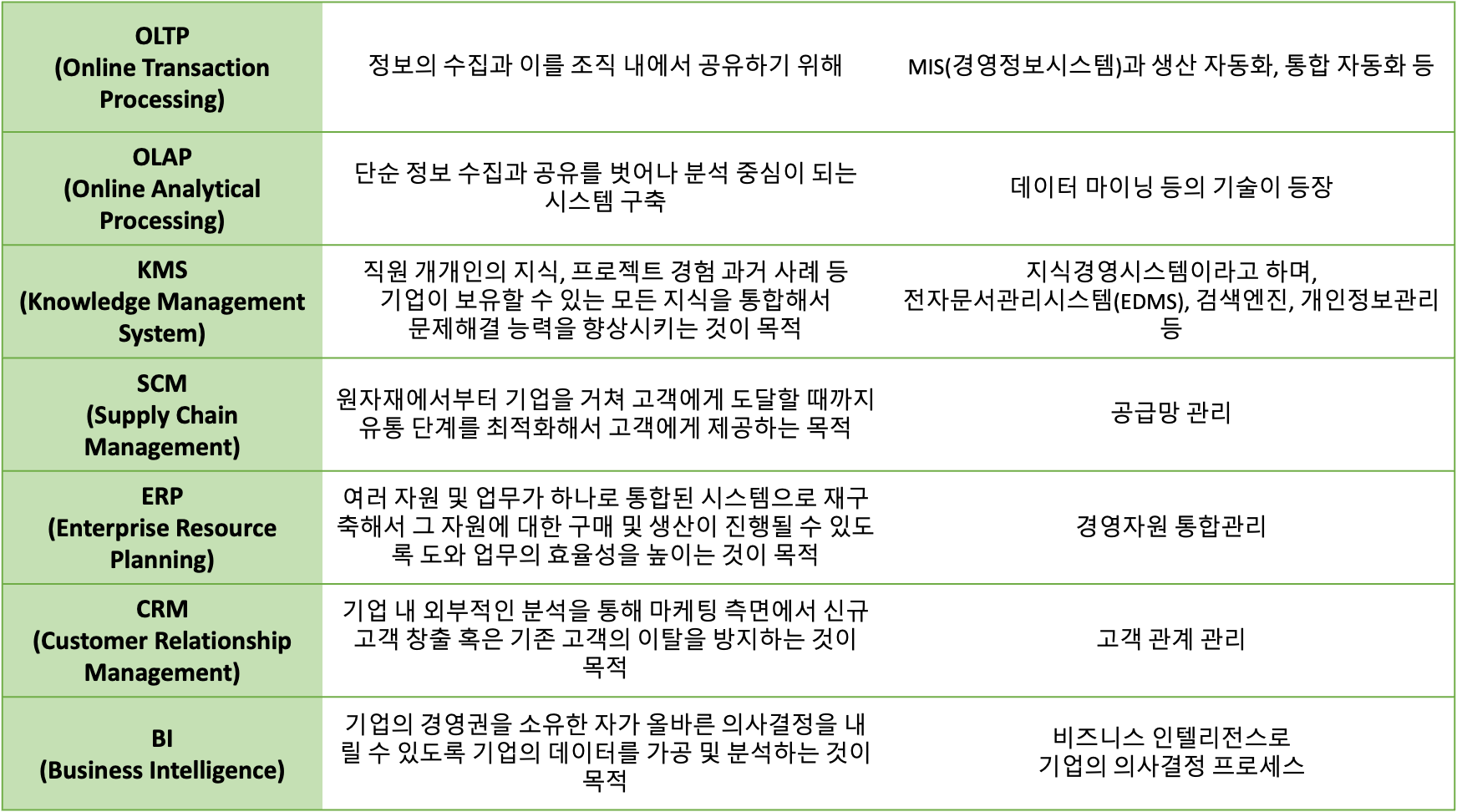
-
산업 부문별 데이터 베이스 발전 과정
- 제조 부문
- 금융 부문
- 유통 부문
-
사회기반구조로서의 데이터베이스
- 물류 부문
- 지리 부문
- 교통 부문
- 의료 부문
- 교육 부문
3) 데이터베이스 종류
- 데이터베이스의 종류
- 관계형 데이터베이스(RDB): 데이터를 행과 열로 이뤄진 테이블에 저장하며, 하나의 열은 하나의 속성을 나타내고 같은 속성의 값만 가질 수 있다. 정형 데이터를 다루는데 특화되어 있다.
- NoSQL: 'No-relational'의 의미로 비관계형 데이터베이스라고 하며, 기존 RDB의 SQL을 보완 및 개선한 비관계형 DB라는 의미를 담고 있다. 비정형 데이터와 대용량의 데이터 분석 및 분산처리에 용이하다.
- 계층형 DBMS: 데이터가 부모자식 형태를 갖도록 관계를 맺어 관리하는 데이터베이스 시스템으로서 데이터 중복 문제가 발생하기 쉬운 단점이 있다.
- 네트워크형 DBMS: 각 데이터 간의 연결을 통해 네트워크처럼 복잡한 그물 형태로 데이터를 관리하는 데이터베이스 관리 시스템이다.
- 분산형 DBMS: 분산된 여러 개의 데이터베이스를 하나의 데이터베이스로 인식하고 사용할 수 있는 데이터베이스 관리 시스템이다.
- 객체지향 DBMS: 사용자가 정의하는 타입을 하나의 데이터 유형으로 저장하는 데이터베이스 관리 시스템으로서 구조가 없는 비정형 데이터라도 사용자가 원하는 방식에 따라 표현 가능하다는 장점이 있다.
- SQL의 이해
- 개념
- SQL(Structured Query Language)은 DBMS에서 데이터베이스에 명령을 내리는 데이터베이스의 하부 언어다.
- 데이터 언어의 종류
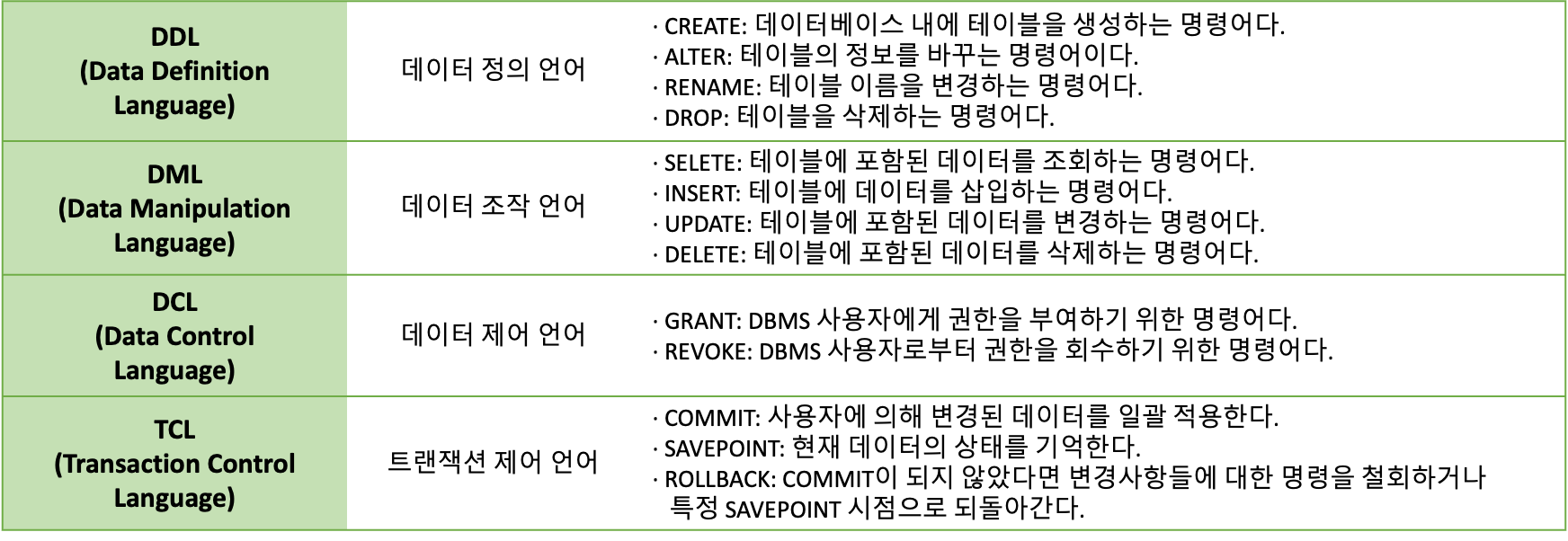
- 개념
📌 2장. 데이터의 가치와 미래
1. 빅데이터의 이해
1) 빅데이터의 이해
- 빅데이터의 정의
- 일반적으로 빅데이터란 큰 용량과 복잡성으로 기존 애플리케이션이나 툴로는 다루기 어려운 데이터셋의 집합을 의미한다.
-
빅데이터의 특징
- 더그 래니의 3V
- 데이터의 양(Volume)
- 데이터의 유형(Variety)
- 데이터의 생성 및 처리 속도의 증가(Velocity): 실시간
- 새로운 특징 4V
- 가치(Value): 데이터 전체를 파악하고 패턴을 발견하기가 어렵게 되면서 가치의 중요성이 강조된다.
- 정확성(Veracity): 빅데이터 기반의 예측 분석 결과에 대한 신뢰성이 중요하게 되었다.
- 더그 래니의 3V
-
빅데이터의 출현 배경
- 데이터의 양적 증가
- 산업계의 변화
- 학계의 변화
- 거대한 데이터를 다루는 학문 분야가 늘어나면서 필요한 기술 아키텍처 및 통계 도구도 지속해서 발전하고 있다.
- 관련 기술의 발전
- 디지털화의 급진전, 저장 기술의 발전, 가격 하락, 인터넷의 발전과 모바일 시대 돌입, 크라우드 컴퓨팅 보편화 등
-
빅데이터의 기능과 변화
- 빅데이터의 기능
- 빅데이터는 "산업혁명의 석탄•철"
- 빅데이터는 "21세기 원유"
- 빅데이터는 "렌즈"
- 빅데이터는 "플랫폼"
- 빅데이터의 기능
-
빅데이터가 만들어내는 변화
- 사전처리 -> 사후처리: 데이터를 사전처리하지 않고, 가능한 많은 데이터를 모으고 데이터를 다양한 방식으로 조합하여 숨은 인사이트를 발굴한다.
- 표본조사 -> 전수조사: 데이터 처리 비용이 감소하게 되면서 데이터 활용 방법이 표본조사에서 전수조사로 변화했다.
- 질 -> 양: 수집 데이터의 양이 증가할수록 분석의 정확도가 높아져 양질의 분석 결과 산출에 긍정적인 영향을 주었다.
- 인과관계 -> 상관관계: 상관관계를 통해 특정 현상의 발생 가능성이 포착되고 그에 상응하는 행동을 추천하는 등 상관관계를 통한 인사이트 도출이 점점 확산되고 있다.
2. 빅데이터의 가치와 영향
1) 빅데이터의 가치
- 빅데이터의 가치
- 어떤 인사이트를 발굴하여 어떻게 활용할 것인지에 달렸다.
- 빅데이터 가치 산정의 어려움

2) 빅데이터의 영향
- 빅데이터가 가치를 만들어내는 5가지 방식
- 투명성 제고로 연구개발 및 관리 효율성 제고
- 시뮬레이션을 통한 수요 포착 및 주요 변수 탐색으로 경쟁력 강화
- 고객 세분화 및 맞춤 서비스 제공
- 알고리즘을 활용한 의사결정 보조 혹은 대체
- 비즈니스 모델과 제품, 서비스의 혁신 등
3. 빅데이터와 비즈니스 모델
1) 7가지 빅데이터 활용 기본 테크닉
- 연관규칙 학습
- Association rule learning
- 어떤 변인 간에 주목할 만한 상관관계가 있는지를 찾아내는 방법
- 유형분석
- Classification tree analysis
- 새로운 사건이 속할 범주를 찾아내는 방법
- 예) "문서를 어떻게 분류할 것인가?", "온라인 수강생들의 특성을 반영하여 어떻게 분류할 것인가?"
- 유전 알고리즘
- Genetic algorithms
- 최적화가 필요한 문제의 해결책을 자연선택, 돌연변이 등과 같은 메커니즘을 통해 점진적으로 진화시켜 나가는 방법
- 머신러닝(=기계학습)
- Machine learning
- 컴퓨터가 데이터로부터 규칙을 찾고 이러한 규칙을 활용해 '예측'하는데 초점을 둔 방법
- 회귀분석
- Regression analysis
- 독립변수를 조작하면서 종속변수가 어떻게 변하는지를 보며 수치형으로 이루어진 두 변인의 관계를 파악하는 방법
- 감정분석
- Sentiment analysis
- 비정형 데이터 마이닝의 대표적인 기법 중 하나이다.
- 특정 주제에 대해 말하거나 글을 쓴 사람의 감정을 분석하는 방법
- 소셜 네트워크 분석
- SNA: Social Network Analysis
- 사회 관계망 분석이라고도 불린다.
- SNS와 같은 온라인 공간에서 유자 사이의 팔로워, 팔로잉 관계를 분석하여 기업의 효율적인 마케팅이나 범죄 수사에서 공범을 찾는 등 다양한 분야에서 활용될 수 있다.
2) 빅데이터의 위기 요인과 통제 방안
- 위기 요인
- 사생활 침해
- 책임 원칙 훼손 : 분석 대상이 되는 사람들이 예측 알고리즘의 희생양이 될 가능성도 높아졌다.
- 데이터 오용: 데이터 과신 혹은 잘못된 지표의 사용으로 인한 잘못된 인사이트를 얻어 비즈니스에 적용할 경우 직접 손실이 발생할 수 있다.
- 통제 방안
- 사생활 침해의 통제방안
- '동의'에서 '책임'으로
- 개인정보 제공자의 '동의'를 통해 해결하기보다 개인정보 사용자의 '책임'으로 해결한다는 방식
- 책임 원칙 훼손의 통제방안
- 결과 기반 책임원칙 고수
- 특정인의 '성향'에 따라 처벌하는 것이 아닌 '행동 결과'를 보고 처벌한다.
- 데이터 오용의 통제방안
- 알고리즘 접근 허용
- 데이터가 어떻게 사용되어 어떠한 이유로 피해자가 발생하게 되었는지 데이터 활용 로직인 알고리즘(알고리즈미스트)을 살펴봄으로써 피해자를 구제할 수 있다.
- 개인정보 비식별 기술
- 데이터 마스킹

- 가명 처리

- 총계 처리

- 데이터 값 삭제

- 데이터 범주화

- 데이터 마스킹
- 사생활 침해의 통제방안
