1. 브라우저 동작 방법
파이어폭스, 크롬 등과 같은 오픈소스 브라우저를 예로 들어 설명함.
1-1. 브라우저의 주요 기능
- 사용자가 선택한 자원을 서버에 요청하고 브라우저에 표시하는 것.
- 자원 = HTML, PDF, 이미지 파일 등...
- 자원의 주소 =
URI(Uniform Resource Identifier)에 의해 정해진다. - 브라우저는 웹 표준화 기구인 W3C(World Wide Web Consortium)에서 정한 명세에 따라 HTML파일을 해석한다.
과거 각각의 브라우저들은 이 명제의 일부만 따르고 독자적인 방법을 추구해서 호환성에 문제가 있었음.
(현재는 대부분의 브라우저는 표준을 따른다.)
1-1-1. 브라우저 사용자 인터페이스 요소
- URI를 입력할 수 있는 주소 표시줄
- 이전 버튼과 다음 버튼
- 북마크
- 새로 고침 버튼과 현재 문서의 로드를 중단할 수 있는 정지 버튼
- 홈 버튼
HTML5 명세는 주소 표시줄, 상태 표시줄, 도구 모음과 같은 일반적인 요소를 제외하고 브라우저의 필수 UI를 정의하지 않았지만, 시간이 흐르면서 현재와 같은 장정만 남아있는 상태로 유지됨.
1-2. 브라우저의 기본 구조
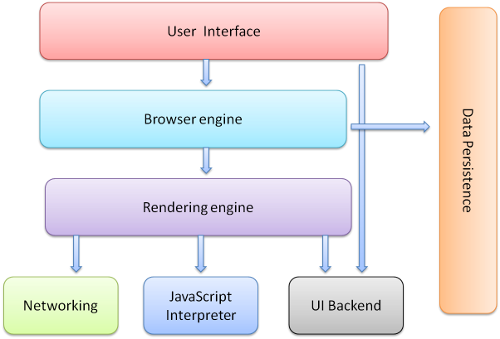
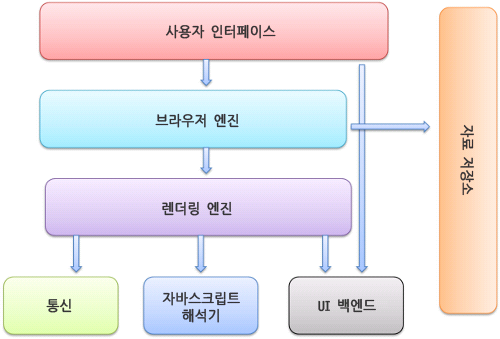
- 사용자 인터페이스 : 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등과 같이 요청한 페이지를 보여주는 부분을 제외한 나머지
- 브라우저 엔진 : 사용자 인터페이스와 렌더링 엔지 사이의 동작을 제어
- 렌더링 엔진 : 요청한 컨텐츠를 표시(HTML 및 CSS을 해석하여 보여줌.)
- 통신 : HTTP 요청과 같은 네트워크 호출에 사용됨.(플랫폼마다 독립적인 인터페이스이며, 각 플랫폼 하부에서 실행됨.)
- UI 백엔드 : 콤보상자 및 창 등의 기본 위젯과 같은 인터페이스를 표시합니다.(브라우저의 인터페이스를 의미한다.)
- 자바스크립트 인터프리터 : 자바스크립트 코드를 해석 및 실행함.
- 자료 저장소 : 브라우저는 쿠키와 같은 모든 종류의 데이터를 사용자의 컴퓨터에 저장 할 수 있다.
크롬은 대부분의 브라우저와 달리 각 탭마다 별도의 렌더링 엔진 인스턴스를 유지한다.
각 탭은 독립된 프로세스에서 실행된다.
1-3. 렌더링 엔진이란?
- 요청 받은 내용을 브라우저 화면에 표시함.
- 기본적으로 HTML 및 XML, 이미지를 표시함.
- 플러그인을 이용하여 다른 유형의 데이터(PDF 등)를 표시함.
1-3-1. 렌더링 엔진의 종류
- 크롬, 오페라(15버전부터) : 웹킷(Webkit)에서 파생된 블링크(Blink)
- 사파리 : 웹킷(Webkit)
- 파이어폭스 : 게코(Gecko)
1-3-2. 렌더링 엔진의 주요 흐름(동작 과정)
통신을 통해 요청된 내용을 가져오는 것으로 시작하는데 단위는 보통 8KB 단위로 진행된다.
다음은 렌더링 엔진의 기본 흐름이다.


"렌더링 엔진은 HTML 문서를 파싱하고 "콘텐츠 트리" 내부에서 태그를 DOM 노드로 변환한다. 그 다음 외부 CSS 파일과 함께 포함된 스타일 요소도 파싱한다. 스타일 정보와 HTML 표시 규칙은 "렌더 트리"라고 부르는 또 다른 트리를 생성한다.
렌더 트리는 색상 또는 면적과 같은 시각적 속성이 있는 사각형을 포함하고 있는데 정해진 순서대로 화면에 표시된다.
렌더 트리 생성이 끝나면 배치가 시작되는데 이것은 각 노드가 화면의 정확한 위치에 표시되는 것을 의미한다. 다음은 UI 백엔드에서 렌더 트리의 각 노드를 가로지르며 형상을 만들어 내는 그리기 과정이다.
일련의 과정들이 점진적으로 진행된다는 것을 아는 것이 중요하다. 렌더링 엔진은 좀 더 나은 사용자 경험을 위해 가능하면 빠르게 내용을 표시하는데 모든 HTML을 파싱할 때까지 기다리지 않고 배치와 그리기 과정을 시작한다. 네트워크로부터 나머지 내용이 전송되기를 기다리는 동시에 받은 내용의 일부를 먼저 화면에 표시하는 것이다."
위의 말은 많이 어렵다......
HTML, CSS 등의 파일을 해석하여서 웹 페이지를 표시하는 하나의 과정이다.
1-3-3. 동작 과정 예시(웹킷)
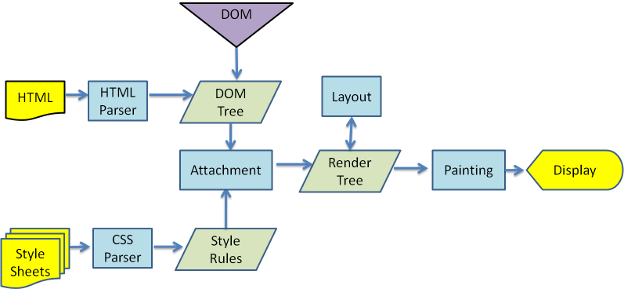
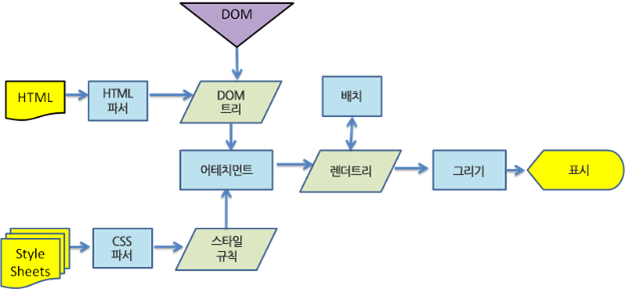
웹킷을 예로 들어 기본흐름을 설명하자면 아래와 같다.
- 통신을 통해 요청 받음.
- 요청받은 페이지의 HTML를 해석(파싱)하여 DOM트리 구축함.
- 요청받은 페이지의 Style Sheets(CSS) 등 스타일 요소를 해석(파싱)하여 스타일 규칙 구축함.
- 2번과 3번을 합하여 Render Tree 구축하고, 스타일 규칙에 맞추어 배치함.
- UI 백엔드에서 구축하고 배치한 Render Tree를 그려낸다.
- 그려진 내용을 출력한다.
1-4. 파싱(Parsing)이란?
파싱은 예를 들어 HTML, CSS, JAVASCRIPT 등과 같은 언어로 쓰여진 문서 파일을 해석하여 웹 페이지를 구현하는 것과 C, C++ 등과 같은 언어로 쓰여진 문서 파일을 컴파일하는 등의 예시가 있다.
이러한 예시를 들어 한마디로 "프로그래밍 언어로 된 문서 파일을 해석한다."는 의미이다.
1-5. DOM (Document Object Model)이란?
문서 객체 모델(The Document Object Model, 이하 DOM) 은 HTML, XML 문서의 프로그래밍 interface 이다. DOM은 문서의 구조화된 표현(structured representation)을 제공하며 프로그래밍 언어가 DOM 구조에 접근할 수 있는 방법을 제공하여 그들이 문서 구조, 스타일, 내용 등을 변경할 수 있게 돕는다. DOM 은 구조화된 nodes와 property 와 method 를 갖고 있는 objects로 문서를 표현한다. 이들은 웹 페이지를 스크립트 또는 프로그래밍 언어들에서 사용될 수 있게 연결시켜주는 역할을 담당한다.
여기까지 브라우저의 동작방법 정리를 마침. 더 깊게 들어가면 프런트엔드의 전문성을 가지는 방향이다.
2. Cookie & Session
2-1. 쿠키(Cookie) & 세션(Session) 정리
| 구분 | 쿠키(Cookie) | 세션(Session) |
|---|---|---|
| 저장위치 | Client | Server |
| 저장형식 | Text | Object |
| 만료시점 | 쿠키 저장시 설정 (설정을 안하면 브라우저 종료 시 삭제) | 정확한 시점 모름 |
| 리소스 | 클라이언트의 리소스 | 서버의 리소스 |
| 용량제한 | 1개의 도메인 당 20개, 1개의 쿠키당 4KB | 제한없음 |
3. HTTP Status Code
이거 말고도 상태코드는 더 많음.
3-1. 10X : 정보 확인
| 상태코드 | 이름 | 의미 |
|---|---|---|
| 100 | Continue | 현 상태 괜찮음. 통신 해도됨. |
| 101 | Switching Protocol | 서버에서 프로토콜 변경함을 알림 |
3-2. 20X : 통신 성공
| 상태코드 | 이름 | 의미 |
|---|---|---|
| 200 | OK | 요청 성공(GET) |
| 201 | Create | 생성 성공(POST) |
| 202 | Accepted | 요청 접수O, 리소스 처리X |
| 204 | No Contents | 요청 성공O, 내용 없음 |
3-3. 30X : 리다이렉트
| 상태코드 | 이름 | 의미 |
|---|---|---|
| 300 | Multiple Choice | 요청 URI에 여러 리소스가 존재 |
| 301 | Move Permanently | 요청 URI가 새 위치로 옮겨감 |
| 304 | Not Modified | 요청 URI의 내용이 변경X |
3-4. 40X : 클라이언트 오류
| 상태코드 | 이름 | 의미 |
|---|---|---|
| 400 | Bad Request | API에서 정의되지 않은 요청 들어옴 |
| 401 | Unauthorized | 인증 오류 |
| 403 | Forbidden | 권한 밖의 접근 시도 |
| 404 | Not Found | 요청 URI에 대한 리소스 존재X |
| 405 | Method Not Allowed | API에서 정의되지 않은 메소드 호출 |
| 406 | Not Acceptable | 처리 불가 |
| 408 | Request Timeout | 요청 대기 시간 초과 |
| 409 | Conflict | 모순 |
| 429 | Too Many Request | 요청 횟수 상한 초과 |
3-5. 50X : 서버 오류
| 상태코드 | 이름 | 의미 |
|---|---|---|
| 500 | Internal Server Error | 서버 내부 오류 |
| 502 | Bad Gateway | 게이트웨이 오류 |
| 503 | Service Unavailable | 서비스 이용 불가 |
| 504 | Gateway Timeout | 게이트웨이 시간 초과 |
4. REST(REpresentational State Transfer) API
REST(REpresentational State Transfer) - 웹 서비스에서 많이 사용되는데 Application 사이에 결합도를 낮추게끔 설계하는 아키텍처 스타일, 서버 / 클라이언트가 별도로 구축
4-1. REST API란?
- API 또는 애플리케이션 프로그래밍 인터페이스는 애플리케이션이나 디바이스가 서로 간에 연결하여 통신할 수 있는 방법을 정의하는 규칙 세트
- REST API는 REST(REpresentational State Transfer) 아키텍쳐 스타일의 디자인 원칙을 준수하는 API
- 이러한 이유로
"REST API"를"RESTful API"라고도 함.
4-2. REST API의 구성요소
- REST API는 자원(Resource), 행위(Verb), 표현(Representations)의 3가지 요소로 구성된다.
- REST는 자체 표현 구조로 구성되어 REST API(Self-descriptiveness)만으로 요청을 이해할 수 있다.
| 구성요소 | 내용 | 표현 방법 |
|---|---|---|
| Resource | 자원 | HTTP URI |
| Verb | 자원에 대한 행위 | HTTP Method |
| Representations | 자원에 대한 행위의 내용 | HTTP Message Payload |
HTTP Message Payload
데이터를 전송 할 때 헤더와 메타데이터, 메소드, 에러 체크 비트 등과 같은 다양한 요소들을 함께 보내어, 데이터 전송의 효율과 안정성을 높히게 됩니다.
보내고자 하는 데이터 자체를"Payload"라고 한다.
4-3. HTTP Method의 종류
| Method | 의미 | Payload | Idempotent(멱등성) |
|---|---|---|---|
| GET | Select(조회) | X | O |
| POST | Create(생성) | O | X |
| PUT | Update(전체를 변경할 때) | O | O |
| DELETE | Delete(삭제) | X | O |
| PATCH | Update(일부를 변경할 때) | O | O |
"PATCH"는"PUT"을 이용하여 데이터의 일부만 변경하는 것이 REST API의 규칙을 위반하는 방식이기 때문에 생겼다고 한다.
PATCH에 관련된 내용 참조
Idempotent(멱등성) :"몇 번이고 같은 내용을 수행하였을 때 같은 결과를 만들어 내는가?"에 대한 내용
4-4. REST API의 중심 규칙
REST에서 가장 중요한 기본적인 규칙은 2개이다.
URI는 자원을 표현하는 데에 집중하고 행위에 대한 정의는 HTTP Method를 통해 하는 것이 REST한 API를 설계하는 중심 규칙이다.
1. URI는 정보의 자원을 표현해야 한다.
- 리소스명은 동사보다는 명사를 사용한다.
- URI는 자원을 표현하는데 중점을 두어야 한다.
- get 등과 같은 행위에 대한 표현을 불가능하다.
# 옳은 방식
GET /item/1
# 잘못된 방식
GET /getItem/1
GET /item/show/12. 자원에 대한 행위는 HTTP Method로 표현한다.
# 옳은 방식
DELETE /item/1
# 잘못된 방식
GET /item/delete/14-5. REST의 아키텍쳐 제약 조건
1. Uniform interface
- identification of resources(자원 식별) - 리소스가 URI로 식별되어야 한다.
- manipulation of resources through representations(표현을 통한 자원 조작) - Payload에 같이 포함된 데이터 중에서 GET, POST 등과 같은 Method를 통한 리소스의 조작을 의미한다.
- self-descriptive messages(자기 설명 메세지) - 메시지만 보고도 무엇을 하려고 하는지 직관적으로 확인이 되어야한다.
- hypermedia as the engine of application state(HATEOAS)(응용프로그램 상태의 엔진으로서의 하이퍼미디어) - 어플리케이션의 상태는 하이퍼링크를 통해 전이되어야함.(페이지 변경 등)
Uniform interface가 필요한 이유는
"독립적 진화"
1. 서버와 클라이언트가 각자 독립적으로 진화함.
2. 서버의 기능이 변경되어도 클라이언트를 업데이트 할 필요가 없다.
3. REST를 만들게 된 계기 : "How do I improve HTTP without breaking the Web"
2. Client–server
- 클라이언트와 서버는 서로 독립적이다.
- 서로의 의존성(결합성)을 낮춘다.
3. Stateless
- 서버의 세션에 상태를 저장하지 않음.
- 즉, 요청에 상태를 포함한 모든 내용이 있어야 한다.
- 구현이 단순해지고, 서비스의 자유도가 높아진다.
4. Cacheable
- 요청에 대한 응답 내의 데이터에 캐싱의 가능여부를 명시해야한다.
- 그것은 서버의 확장성 및 클라이언트의 성능 향상을 위해서이다.
5. Layered system
- 요청과 응답은 서로 다른 계층에서 수행되어야한다.
- REST API의 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 계층을 추가하여 구조상의 유연성을 둘 수 있다.
- PROXY, 게이트웨이와 같은 네트워크 기반의 중간 매체를 사용할 수 있다.
6. Code on demand (선택사항)
- 정적인 데이터를 보내는 것이 보통의 선택이다.
- 하지만 데이터를 보낼 때 클라이언트에서 바로 실행 가능한 코드를 보내기도 한다.
참조한 내용의 사이트 목록(생각보다 이해가 안되서 참조한 사이트가 많다...)
- www.html5rocks.com
- d2.naver.com
- gyoogle.dev
- developer.mozilla.org
- developer.mozilla.org
- developer.mozilla.org
- www.ibm.com
- poiemaweb.com
- meetup.toast.com
- restfulapi.net
- mizzo-dev.tistory.com
- sabarada.tistory.com
- sabarada.tistory.com
- www.ics.uci.edu
- doitnow-man.tistory.com
- naver d2 유튜브 영상 - Day1, 2-2. 그런 REST API로 괜찮은가
