
뉴스 클러스터링 문제를 풀다가 어떻게 여기까지 왔는지 모르겠지만... 아무튼 개념을 명확하게 짚고 넘어가야겠다.
일반 파이썬 교재에는 이 개념이 제대로 설명되어있지 않았다. 그래서 전문가를 위한 파이썬 교재를 펼쳤다.
1. 변수는 상자가 아니다.
파이썬의 변수는 모두 객체로 이뤄져 있는데, 이때 이 객체의 개념은 자바에서의 참조 변수와 같다.
(보통 객체와 생성된 참조변수의 관계를 붕어빵 틀과 붕어빵으로 설명하는 경우가 있는데, 잘못된 설명인 것 같다.)
그래서 파이썬에서 변수는 다음과 같은 그림으로 표현할 수 있다.
어떤 객체라는 물체에 변수를 붙여서 같은 객체를 가리키게 하는 것이다. 변수는 객체에 붙은 레이블이라고 표현할 수 있다.
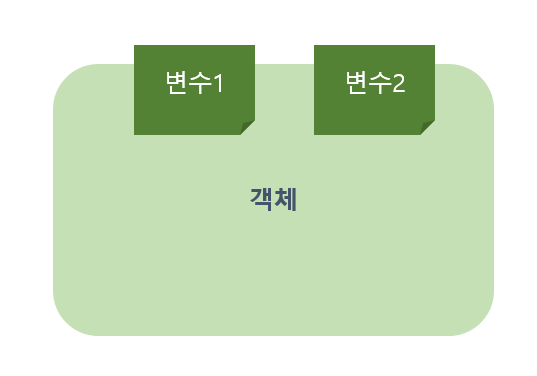
실제로, 이 개념을 프로그래밍을 할때 '변수1'이 객체에 할당되었다. 라고 하지 '객체'가 변수1에 할당됐다. 라고는 안한다.
2. 객체의 정체성, 동질성, 별명
1) 별명
하단의 예시를 보자
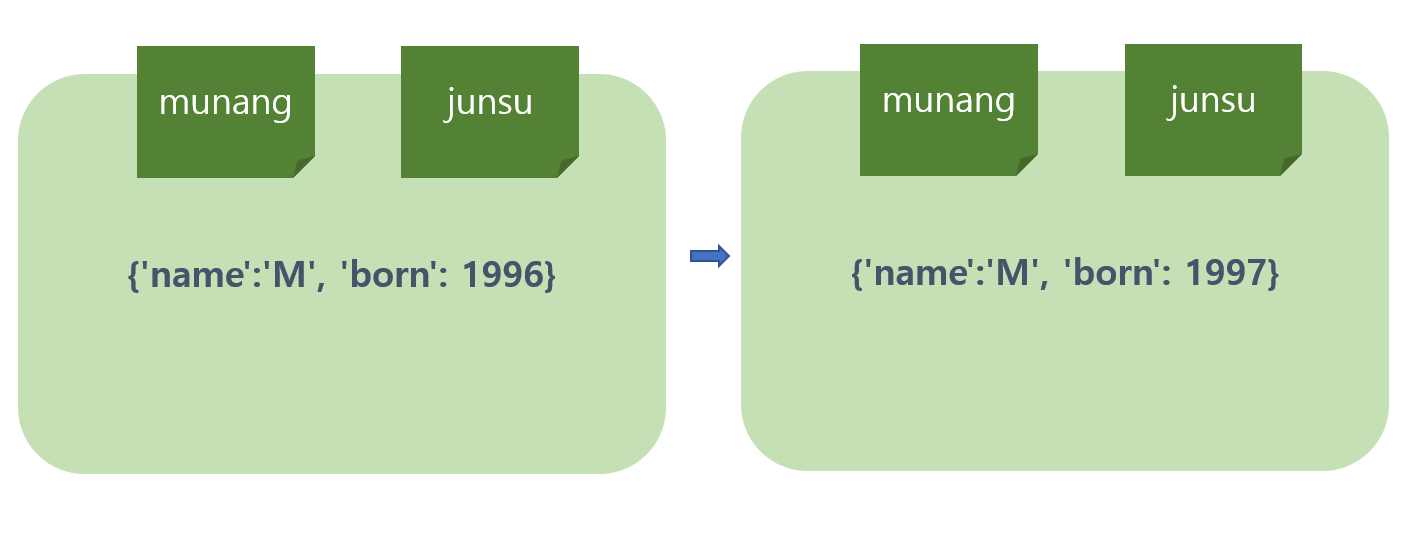
munang = {'name':'M', 'born': 1996}
junsu = munang
junsu is munang # 정체성 확인 연산자
-> True
junsu == munang # 내부의 값을 확인하는 동치연산자
-> True
id(junsu), id(munang)
->(43007498, 43007498)
junsu['born'] = 1997
munang
-> {'name':'M', 'born': 1997}munang 변수와 junsu 변수는 별명 관계이다. 두 변수 모두 동일한 객체를 참조하고 있으며, junsu에 변경을 하는 것은 munang에 변경하는 것과 같은 것이다.
그림으로 살펴보면 다음과 같다고 볼 수 있다.
2) 정체성
1)에서 보면, munang과 junsu는 같은 객체에 바인딩 되어있고 값이 같으므로 동치연산자와 정체성을 확인하는 연산자 모두 True를 반환한다.
또 다른 하단의 코드를 확인해보자.
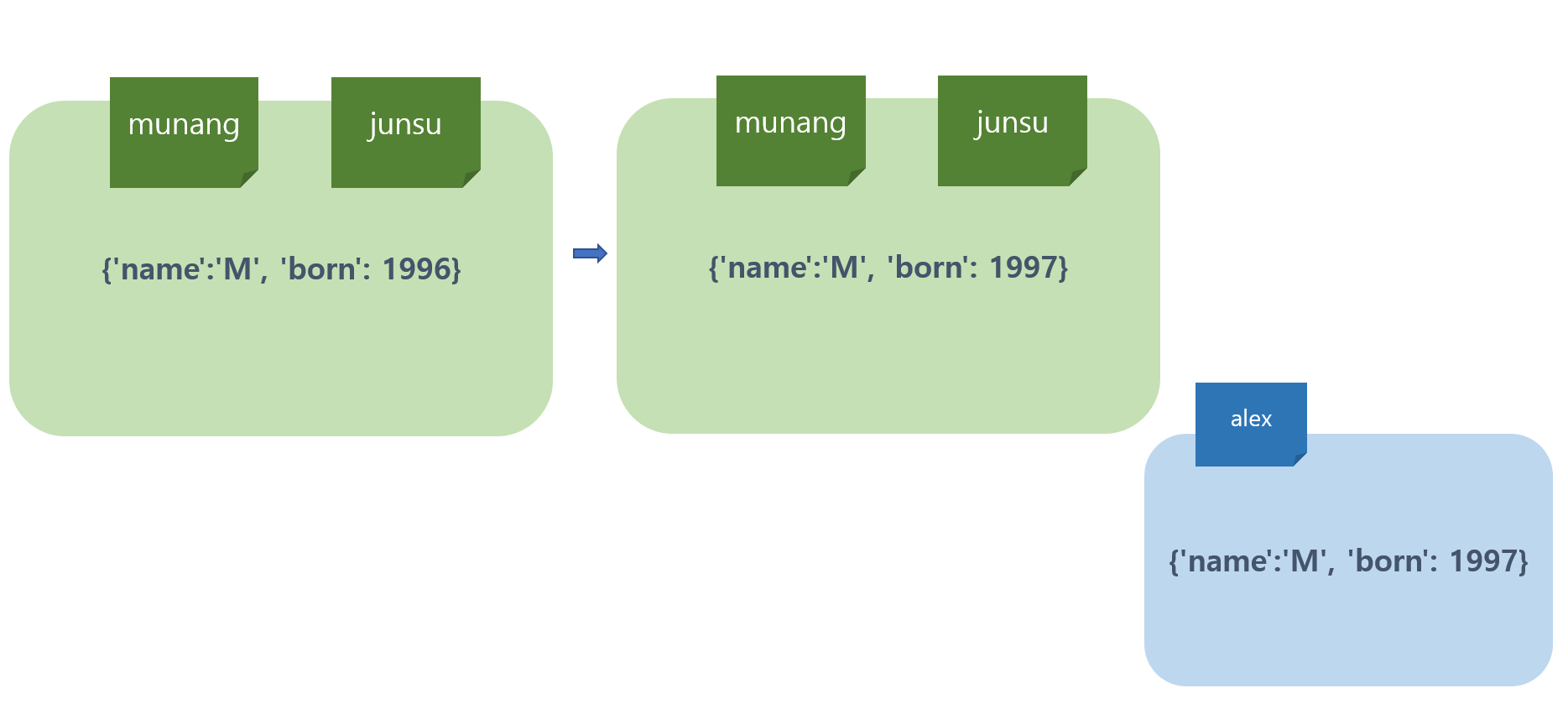
alex = {'name':'M', 'born': 1997}
alex == munang
-> True
alex is munang
-> False여기서 alex와 munang은 별명관계가 아니다. 두 변수가 서로 다른 객체에 바인딩 되어있다. 이때, 바인딩 객체가 가지고 있는 값이 같기 때문에 동치연산자의 결과가 True가 나온다. 하지만, 정체성은 다르다.
그림으로 보면 하단의 경우와 같다.
-
동치 연산자와 is연산자
동치 연산자는 객체의 값을 비교하는 반면,is연산자는 객체의 정체성을 비교한다. 보통은 값을 비교하기 때문에 파이썬에서는==가 자주쓰인다. 하지만,None값인지의 여부를 판별할때 주로is연산자가 쓰인다. -
속도 차이
is연산자는 오버로딩 할 수 없음으로 특별메서드를 호출할 필요가 없다. 따라서is연산자는 단순히 두 정수를 비교하는 정도의 연산이다.
하지만==연산자는 object객체에서 상속된__eq__()메서드를 오버라이딩해서 객체의 값을 비교한다. 따라서 훨씬 처리량이 많다고 볼 수 있다.
(object객체의__eq__()함수는 is연산자와 동일하게 구현되어있지만, 자료형(str, int, array ... 등등)에서 오버라이딩 되어있다.)
3. 얕은 복사, 깊은 복사
복사를 이해하기 위해서는 가변 변수, 불변 변수를 먼저 이해해야 한다. 왜냐면 가변이냐 불변이냐에 따라 동작방식이 매우 달라지기 때문이다.
(복사는 객체 참조에서 무슨관계일까.. 동치성, 정체성, 별명 과 어떤 관계가 있는 것인지? 그리고 이게 불변, 가변 변수간의 어떤 차이가 있는 것인지?... 다음 포스팅에서 얘기하겠다.)
1) 불변객체
불변 - int, str, tuple
불변객체는 말 그대로 변하지 않는다. 값을 변경하려고 하면 오류가 발생하고, 값을 추가하거나 새로할당하게 되면 메모리 공간을 다시 할당받고 다른 객체를 참조하게 된다.
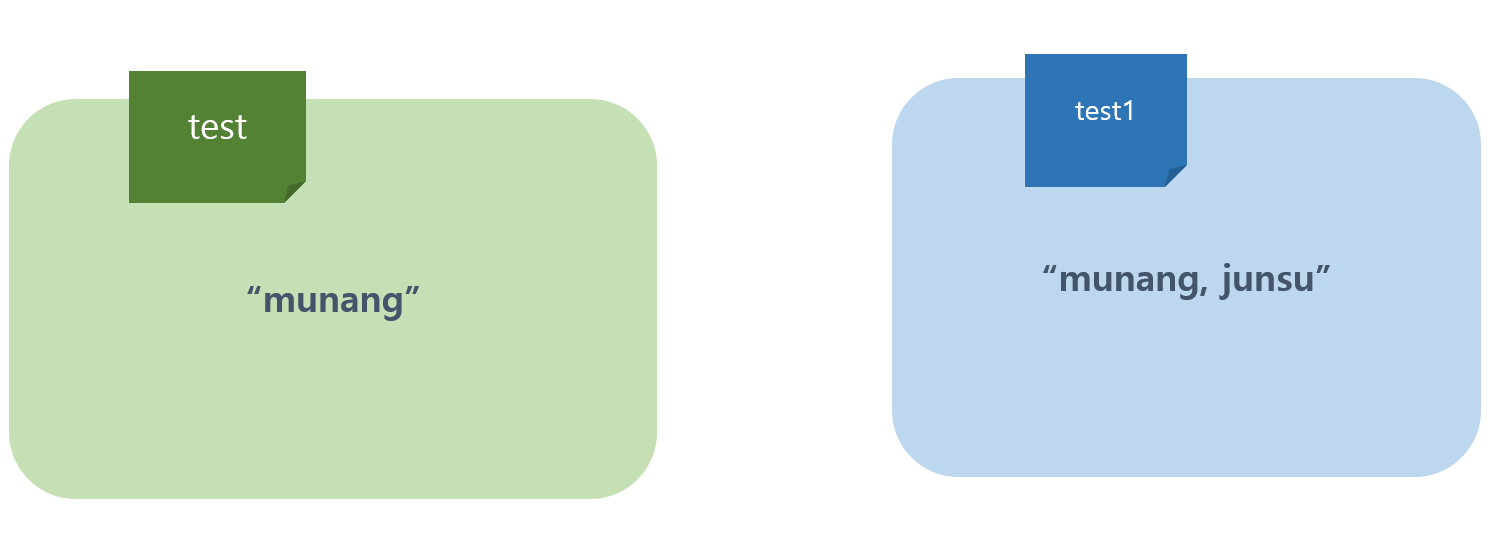
test = "munang"
test1 = test
test1 = test1+",junsu"위의 상황을 그림으로 보면 다음과 같다.
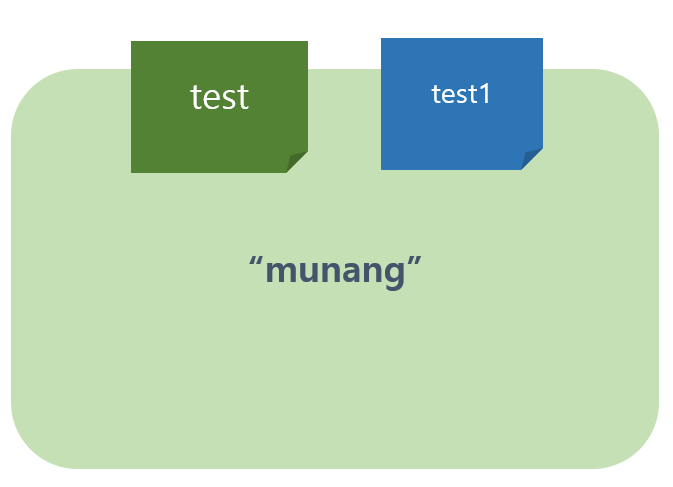
test와 test1변수는 같은 객체를 참조하게 된다. 이후, test1의 내용을 변경하게 되면 가변객체와 달리 새로운 메모리 공간의 새로운 객체를 참조하게 된다.
2) 가변객체
가변 - list, dict, set
가변객체는 말 그대로 변한다. 값을 변경하려 해도 오류가 발생하지 않고, 값을 추가하게 되면 재할당 없이 그대로 참조하고 있는 객체의 값이 변경된다. (여기서 =는 복사의 개념이 아닌, munang과 junsu를 같은 객체를 참조하도록 바인딩 해주는 것이다. == 대상과 객체의 바인딩을 형성해준다고 생각)
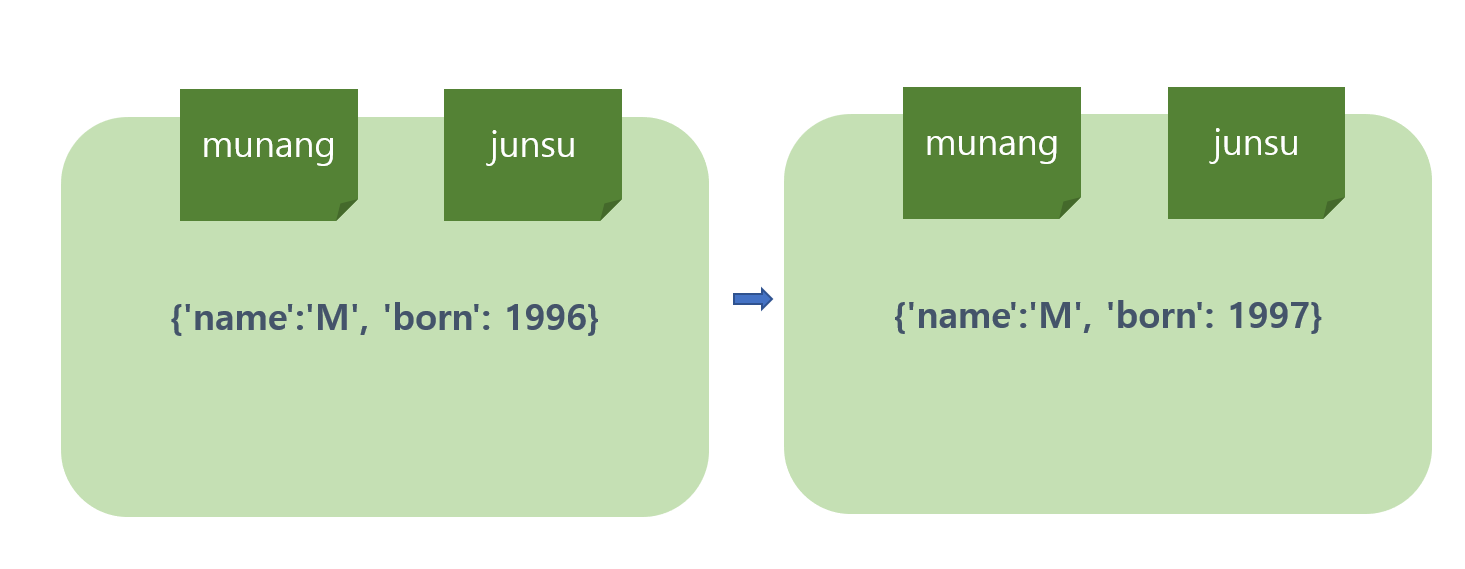
munang = {'name':'M', 'born': 1996}
junsu = munang
junsu['born'] = 1997그림으로 보면 다음과 같다.
3) 그래서 뭐 복사가 어떻게 다른건데?
위의 1)에서 확인하듯이 불변객체는 얕은복사, 깊은복사의 개념이 없다. 실제로 str클래스나 int클래스를 확인해보면 copy()함수가 존재하지 않는다. 왜냐면 그냥 = 연산자를 사용해서 할당해주면 되고, 값이 변하면 알아서 다른 객체를 참조하기 때문이다.
다른 점은 2)이다. 가변 객체는 얕은 복사와 깊은 복사의 개념이 있다.
얕은 복사와 깊은 복사는 가변객체가 하나의 컨테이너로만 이뤄졌다면, 차이가 없다. 그림으로 보면서 이해하겠다.
4) 가변객체의 복사는 디폴트: 얕은 복사
가변 객체를 복사하는 방법은 생성자,[:], .copy()함수를 사용하는 것이다. 모두다 얕은 복사이다.
복사를 하게 되면, 기존에 변수가 참조하던 객체를 모두 동일하게 복사하는 것이다. 즉 똑같이 만들어낸다. 말 그대로 복사하는 것이다. 주소는 다르게 된다. 여기까지는 얕은 복사 깊은 복사 모두 동일하다.

여기서 =와 헷갈리면 안된다. =는 같은 객체를 참조하도록 바인딩 해주는 것이다.
복사는 똑같이 다른 변수를 만들어내는 것이다.
5) 깊은 복사는 도대체 언제?
가변객체가 이루는 컨테이너가 여러가지일때 발생한다.
list_test = [1,2,3,['a','b','c']] 라고 하고, list_test_copy = list_test.copy()이렇게 한다면
얕은 복사의 경우 다음과 같다.
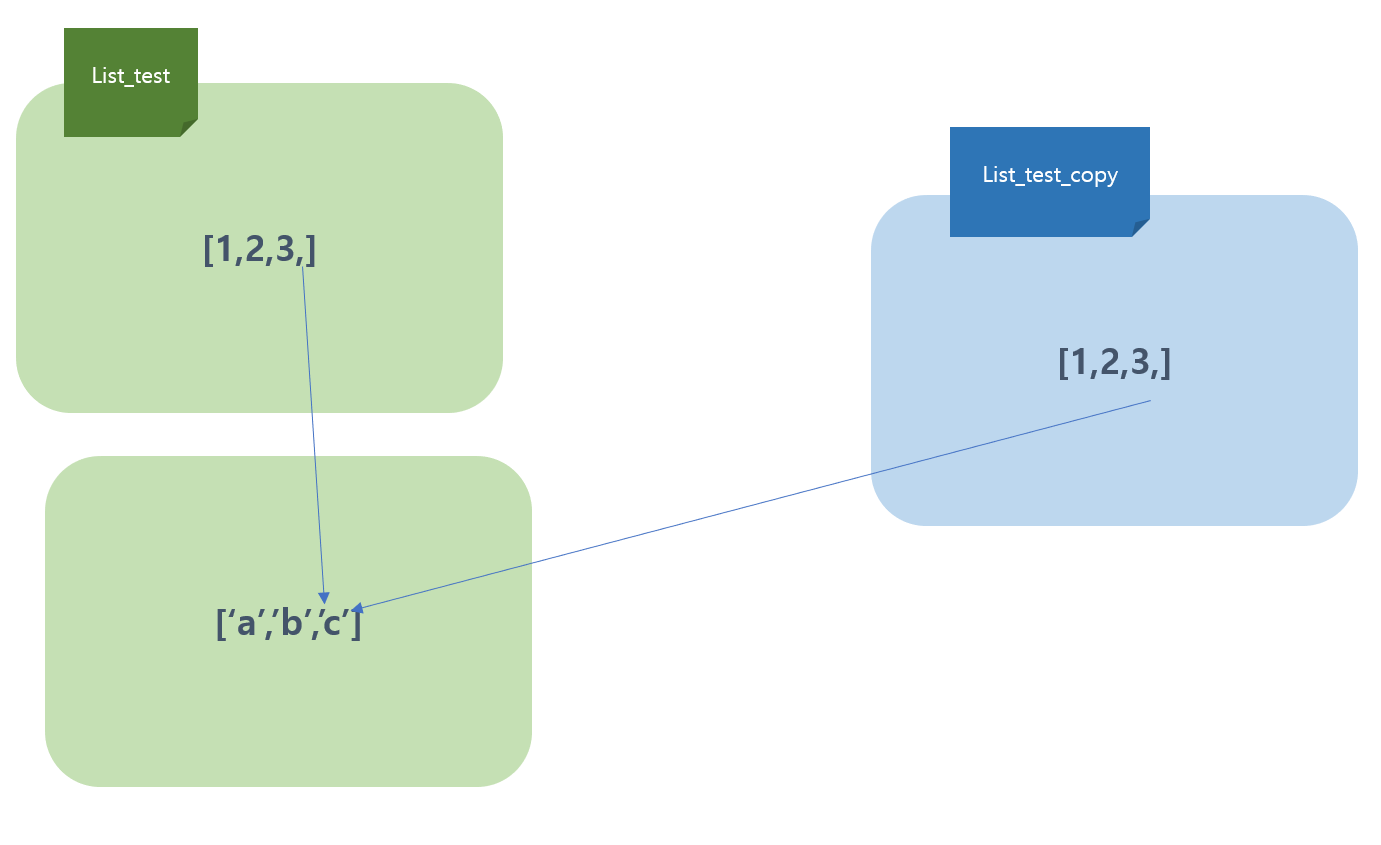
즉 가장 최상위 리스트는 그대로 복사했지만, 그 하위 리스트는 동일한 객체를 참조하게 된다. 그래서 얕은 복사이다.
이때 깊은 복사를 사용하면 이렇게 된다.
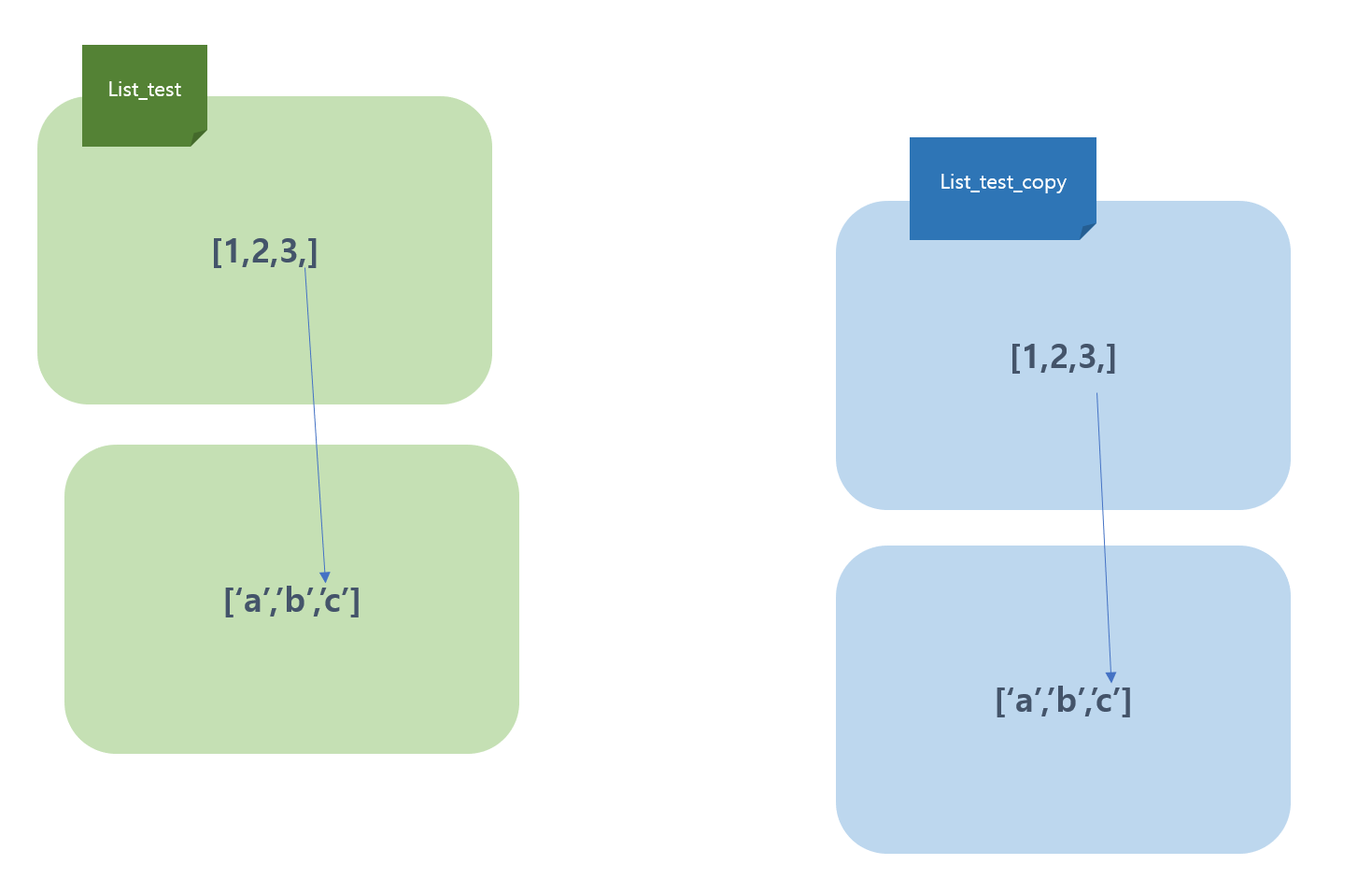
쓸 일이 많지는 않을 것 같다.
사용방법은 !!!
from copy import deepcopy
list_test_copy = deepcopy(list_test)다음 게시글에서는 참조로서의 매개변수가 어떻게 동작하는지 다뤄보겠다.
