github이 완성되지 못했습니다.
튜토리얼을 이행하실 때 문제가 생길 수 있습니다.
(예상 수정 완료일: 6/8)
TextRank 개요
TextRank는 그래프 기반 extractive 요약을 위해 많이 사용되는 알고리즘입니다. 제목에서 추측할 수 있으셨을텐데 자연어처리에 이용되는 알고리즘으로 단어, 문장, 문단 중 어느 한 타입에 대해서 주어진 문서 내에 중요도를 나열할 수 있는 알고리즘입니다. 이번에 다뤄볼 것은 문서 내에 키워드를 중요도에 따라 나열하는 것입니다.
튜토리얼을 진행하기 앞서, TextRank의 정의를 이루는 개념들에 대해 먼저 설명을 드리겠습니다.
이론적 배경
- 그래프 기반 알고리즘이란?
그래프 알고리즘을 이야기할 때의 그래프는 아래 그림같이 생긴 것을 의미합니다.
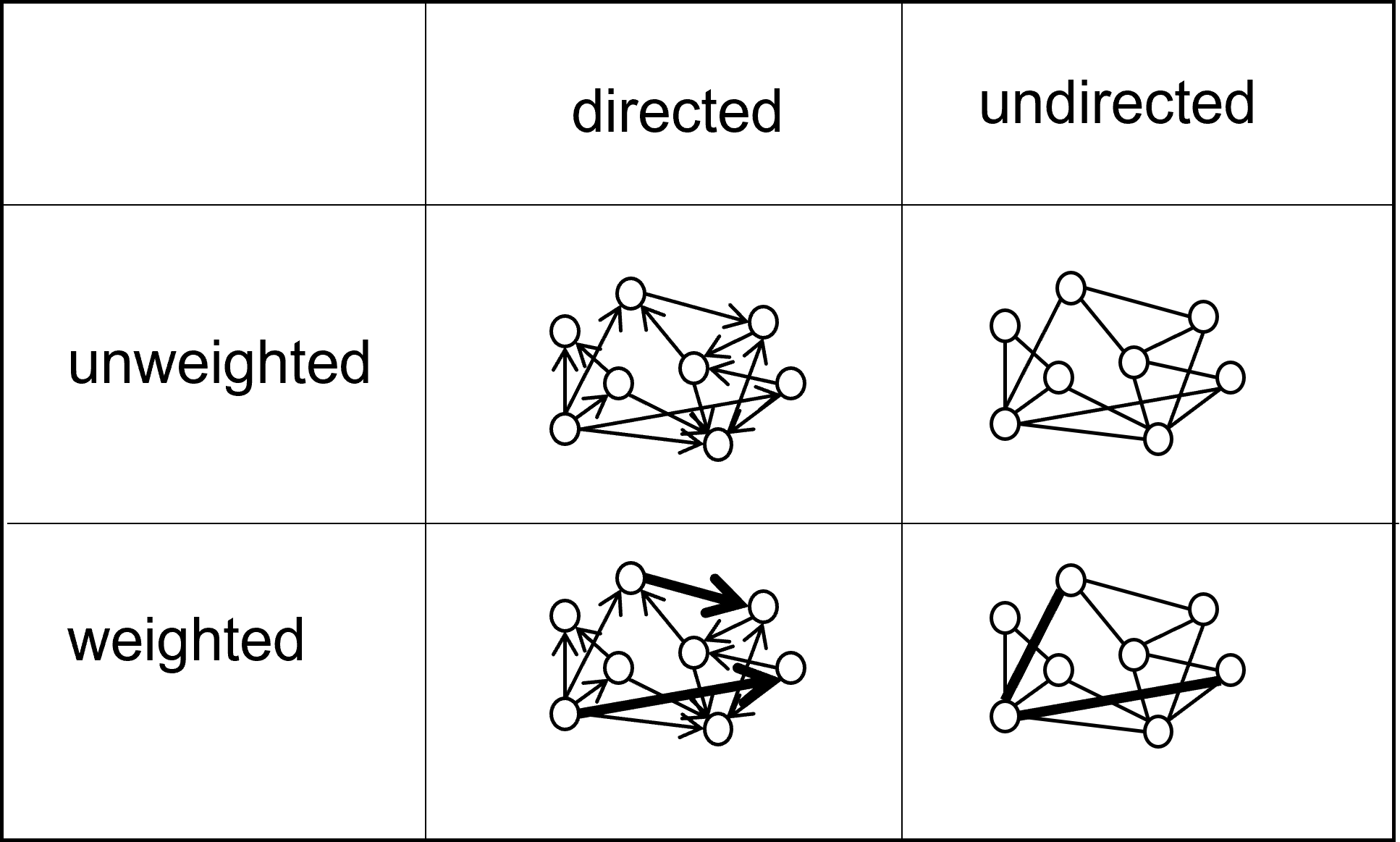
동그라미는 node, 선은 edge라고 불리는 것이 일반적입니다. 그래프는 edge의 방향성, 그리고 각 edge에 가중치가 있는지 없는지를 바탕으로 아래 표와 같이 구분될 수 있습니다.
- extractive vs abstractive 요약이란?
extractive 요약
문서에 존재하는 텍스트를 선택하는 추출 요약 방식입니다. 주로 머신러닝 알고리즘을 이용해서 실행하나, 요즘에는 BERT와 같은 transformer 기반 딥러닝 알고리즘으로도 수행합니다.
abstractive 요약
문서를 입력으로 했을 때 문서의 내용을 기반으로 새로운 문장, 단어를 생성합니다. 주로 GPT-3 혹은 BERT를 중심으로 연구가 이루어져 있습니다.
- TextRank 알고리즘에 대한 이해
고려대학교 산업경영공학부, [Paper Review] TextRank: Bringing Order into Texts
저는 위 링크로 연결되는 대략 50분짜리의 수업을 토대로 코드를 작성했습니다.
TextRank도 그래프의 유형에 따라 계산 방법이 다소 달라지는데, 기본적으로 빈도수 세기 기반으로 중요도를 계산합니다.
TextRank 수행 순서
이번 튜토리얼은 단어 추출이 목적이므로 단어 기준으로 설명하겠습니다.
- 노드의 생성: 모든 단어에 대한 node 생성
- 에지의 생성: 모든 1:1 단어 조합에 대한 edge 생성
- importance score의 계산: 한 노드의 다른 노드에 대한 중요도 계산
한글 키워드 추출: TextRank 튜토리얼
[github](https://github.com/FiBuddy/level1.git)
데이터 수집
데이터는 [AI hub](https://aihub.or.kr/aidata/30713) 에서 가지고 왔습니다.데이터 가공
주어진 데이터는 json 형식을 따르며, 저희가 사용할 요소는 id, passage, summary입니다.id는 각 도서에 대한 식별자이며 각각 passage는 도서 내용 string, summary는 대략 3줄로 요약되어있는 요약문에 대한 string입니다.
함수에 대한 상세한 설명은 github를 통해서 자세히 살펴보실 수 있습니다.
from 'TextRank_ExtractWords_as module.ipynb' import ParseText
stopword_file='stopwords.txt'
data_dir='./2020-02-019.도서자료요약_Sample'
parser=ParseText()
#type 1: 직접 경로 넣어주기,
data,summ=parser.doAll(type=1,dr=data_dir,stop=stopword_file)노드 생성
가공한 데이터를 담은 변수인 data를 노드로 변환합니다. 이 단계에서는 단지 중복 없이 리스트를 만듭니다.from 'TextRank_ExtractWords_as module.ipynb' import TextRank
tr=TextRank(data,window=5)
tr.makeNodes()
edge matrix 생성
가공한 데이터는 전부 문장 위에서 있던 선후관계가 보존되어있습니다. 따라서 n의 범위 내로 전, 후 관계에 있는 단어의 쌍을 생성합니다. 그런 후 쌍에 있어서 중복이 없는지 개수를 셉니다.tr.makeEdges(flip=False)만약 undirected graph based TextRank를 구현하신다면
아래 함수를 이용하셔서 포함된 단어의 순서만 다른 edge들을 하나로 묶어 세도록 합니다.
tr.makeEdges(flip=True)
#혹은
tr.flip()importance score의 iterative 계산
importance score는 원래 절대부등식의 풀이식으로 진행됩니다. 하지만 반복 수행을 통해 근사치로 구하는 방법이 있습니다.
n=10
result=tr.return_best(n) #모든 문서에 대한 리스트를 담은 리스트결과
하나의 문서에 대한 결과를 나타낸다.
얼마나 잘 한걸까?
F1 score
데이터셋은 passage인자와 summary인자가 있다.
답안지 만들기
- 각자를 토큰화한 것을 비교해 summary 속의 단어 토큰 중 passage의 것과 같았던 것을 간추린다.
- passage의 인자 중 일반명사는 중요도를 절반으로 선정한다.
F-feature 계산하기
- Precision을 구한다 : |교집합|/|TR 결과|
from 'TextRank_ExtractWords_as module.ipynb' import Importance
imp=Importance(tr,summ)

앞으로 발전 계획
- 복합어 처리
- 성과 관리
