카프카(kafka)는 메세지큐의 대표적인 솔루션 중 하나입니다.
링크드인에서 개발했으며 현재는 오픈소스로 공개되어있어 데이터 파이프라인 구축을 위해 많은 사람들이 사용하고 있습니다.
카프카 기본 구조
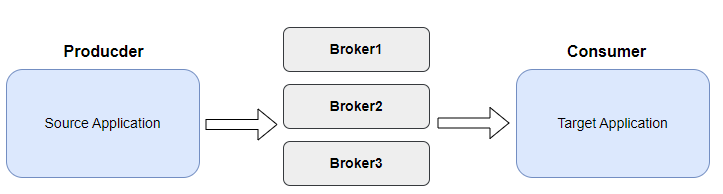
카프카는 크게 브로커, 컨슈머, 프로듀서 세가지 컴포넌트로 구성됩니다.
-
프로듀서: 카프카 브로커에 데이터(메세지)를 전송하는 어플리케이션
-
브로커: 브로커는 카프카가 설치되어 있는 서버이며 프로듀서로부터 받은 데이터를 관리한다. 보통 고가용성을 위해 클러스터로 구성된다.
-
컨슈머: 브로커에 저장된 메세지를 읽어와 사용하는 어플리케이션
카프카 토픽 & 파티션
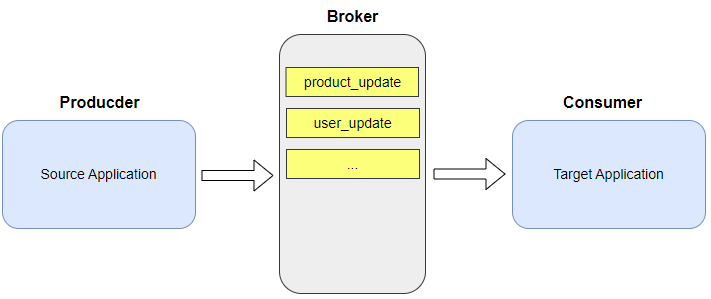
토픽은 카프카 클러스터에 데이터를 저장할 떄 데이터를 구분하기 위한 기준입니다.
프로듀서가 특정 토픽을 지정하여 메세지를 발행하면 브로커는 해당 토픽에 데이터를 저장합니다.
컨슈머는 자기가 컨슘할 토픽에 저장된 데이터를 읽어올 수 있습니다.
토픽이름은 어떤 데이터를 담고 있는지 알기 쉽도록 정하는게 좋고, 필요할 경우 버저닝을 하는 경우도 있습니다. (ex. user_update_v1)
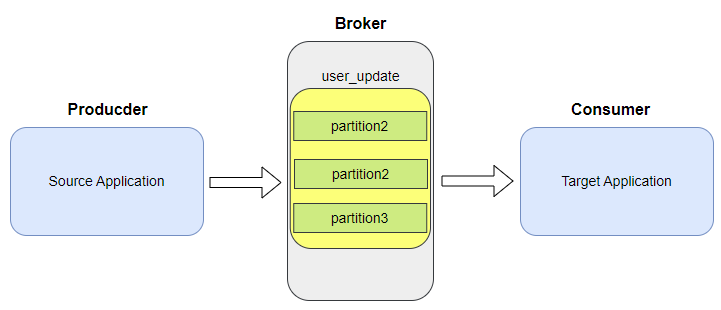
토픽은 1개 이상의 파티션으로 구성되어 있습니다.
브로커에 전송된 데이터는 토픽의 특정 파티션에 차례대로 저장됩니다.
컨슈머는 파티션에 가장먼저 저장된 데이터부터 차례대로 컨슘합니다.
파티션이 여러개일때 기본적으로 round-robin 방식으로 파티션을 선택하여 저장합니다.
만약 특정 파티션에 데이터를 넣고 싶을 경우 메세지를 발행할 때 key 값을 같이 전달하면 되는데 같은 key 를 가진 데이터는 같은 파티션에 저장됩니다.
컨슈머는 어떻게 파티션에서 데이터를 가져갈까?
파티션마다 컨슈머가 마지막으로 읽은 위치를 저장하고 있고 이를 오프셋(offset) 이라고 합니다.
컨슈머는 offset 을 작은 순서부터 차례대로 컨슘합니다.
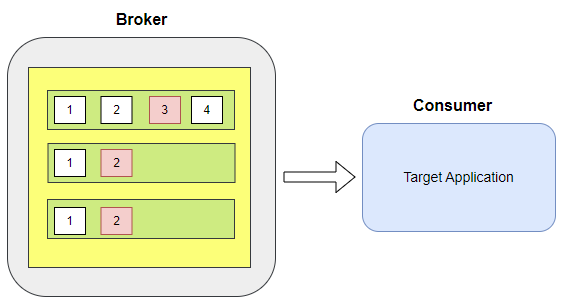
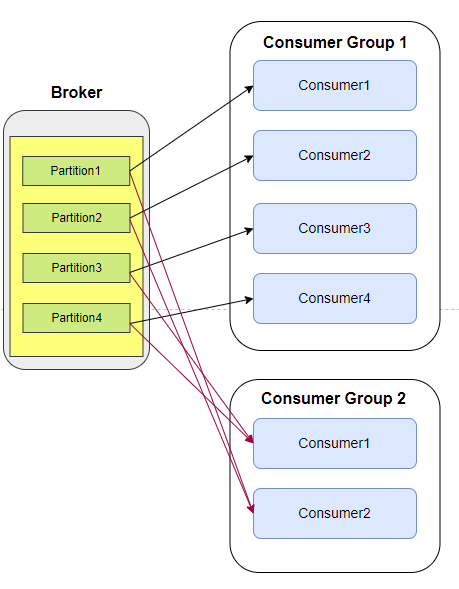
- 1개의 파티션은 1개의 컨슈머에만 할당될 수 있습니다.
- 파티션 개수보다 컨슈머 개수가 많다면 노는 컨슈머가 생길 수 있습니다.
- 1개의 컨슈머는 다수의 파티션에 할당될 수 있습니다.
- 파티션 개수보다 컨슈머 개수가 적다면 컨슈머는 1개 이상의 파티션에 할당될 수 있습니다.
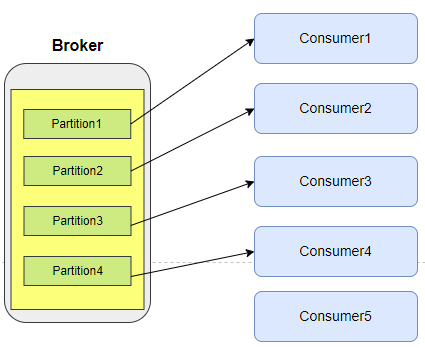
보통 데이터 처리량을 늘리고 싶을 때 파티션 개수와 컨슈머 개수를 늘립니다.
파티션 개수를 처음부터 넉넉하게 생성하고 데이터 처리량을 늘려야 할 때 컨슈머 개수만 조절하는 방법도 있습니다.
(참고로 파티션의 개수는 늘릴수는 있지만 줄이는 것은 불가능합니다.)
컨슈머는 컨슈머그룹 이라는 단위로 구분할 수 있습니다.
예를들어, 특정 토픽을 A서비스와 B서비스에서 컨슘하고 있다면 A와 B는 서로 다른 컨슈머 그룹입니다.
브로커는 컨슈머 그룹마다 offset 을 별도로 관리하기 때문에 컨슈머 그룹 간에는 서로 영향을 주지 않습니다.