
본 포스트는 학교 수업 강의내용을 단순 정리본 형태로 만든 내용입니다. 평소 포스트와 달리 다소 설명이 부실할 수 있음을 미리 알려드립니다 🙂
복습
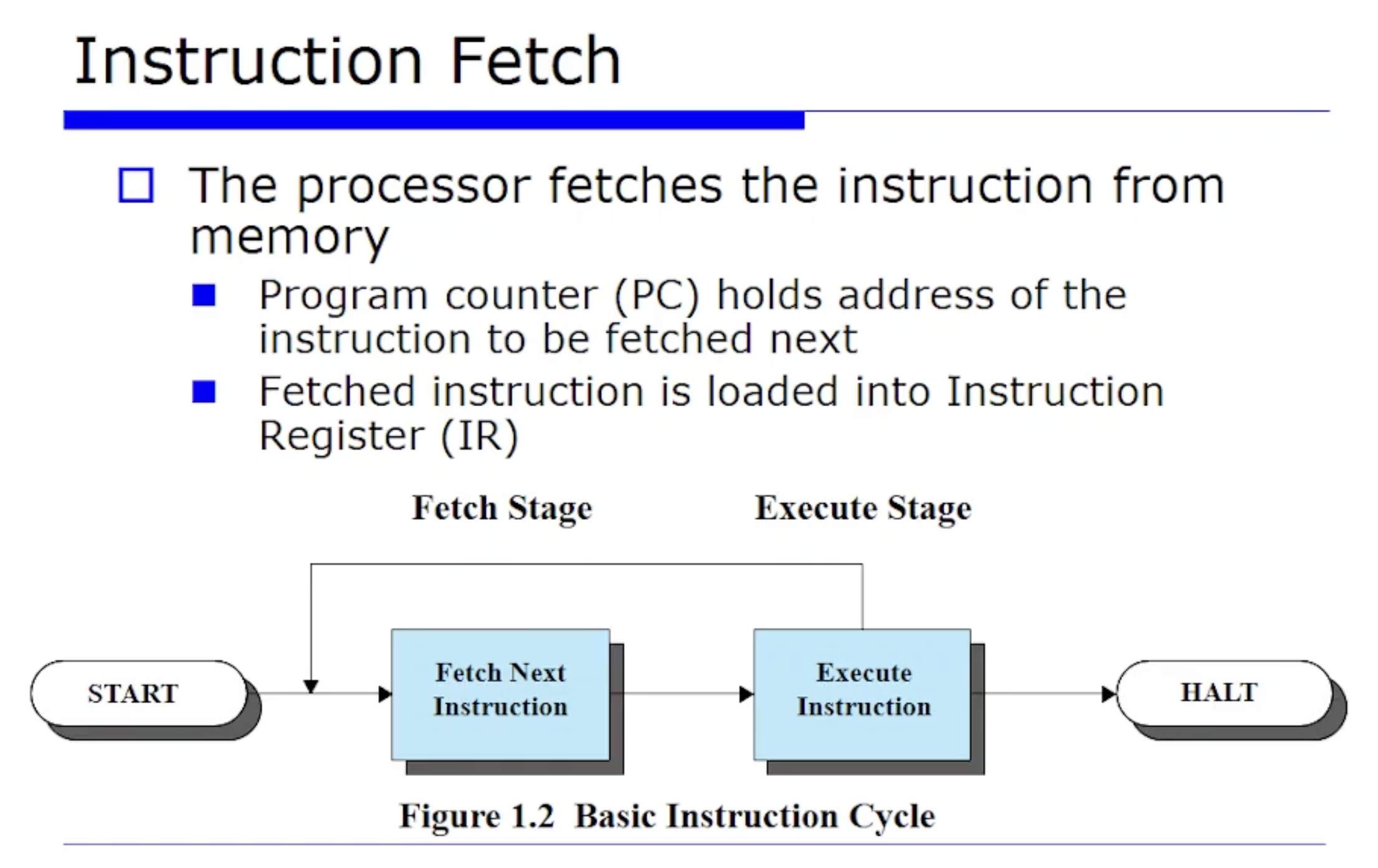
지난시간에 우리는 CPU와 그 내부에 있는 레지스터와, 또 메모리 모듈 이 둘 사이의 상호작용을 통해서 CPU 가 어떻게 프로그램의 명령어들을 수행하는지 살펴봤었다.
프로그램은 명령어의 집합이다. 어떤 프로그램이 메모리에 올라와있고, PC 가 가리키는 명령어를 가져오고(fetch), 수행하고(execute), 또 그 다음 명령어를 PC 에서 계속 가져오면서 반복적으로 수행하는 심플한 메커니즘을 살펴봤다.
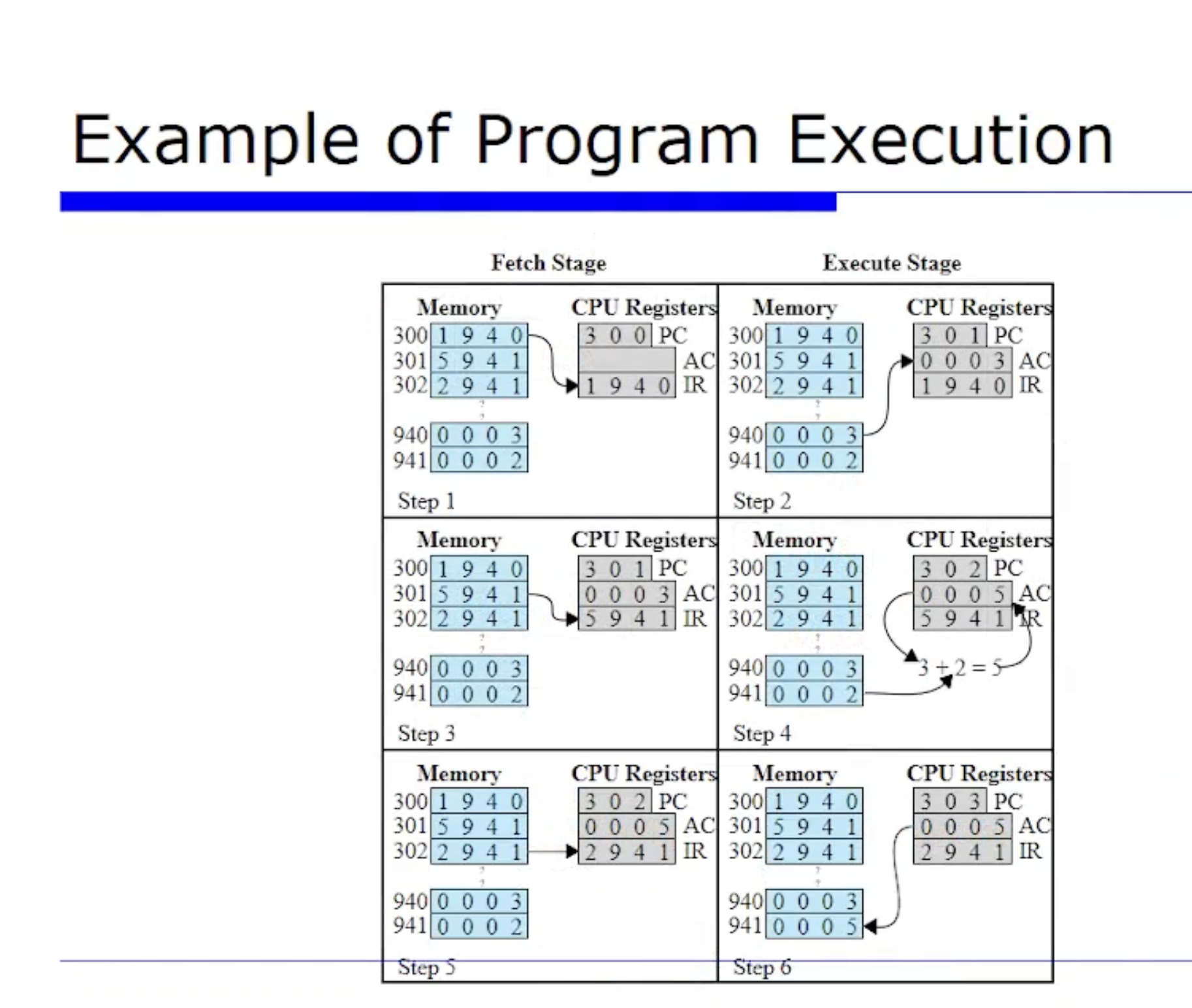
그리고 이 예제는 어떤 메모리에 있는 값에다 새로운 값을 더해서 업데이트 시키는 프로그램이였다. 그것이 명령어를 통해 어떻게 동작하는지, 그리고 그게 machine state, 즉 메모리와 레지스터의 값이 어떻게 변하는지를 살펴봤었다.
그런데 CPU 가 이렇게만 동작한다면 문제가 있을것이다. 끝날때까지 한 프로세스만 동작할 수 있기 때문이다. 프로세스라는건 실행중인 프로그램을 말한다.
Interrput
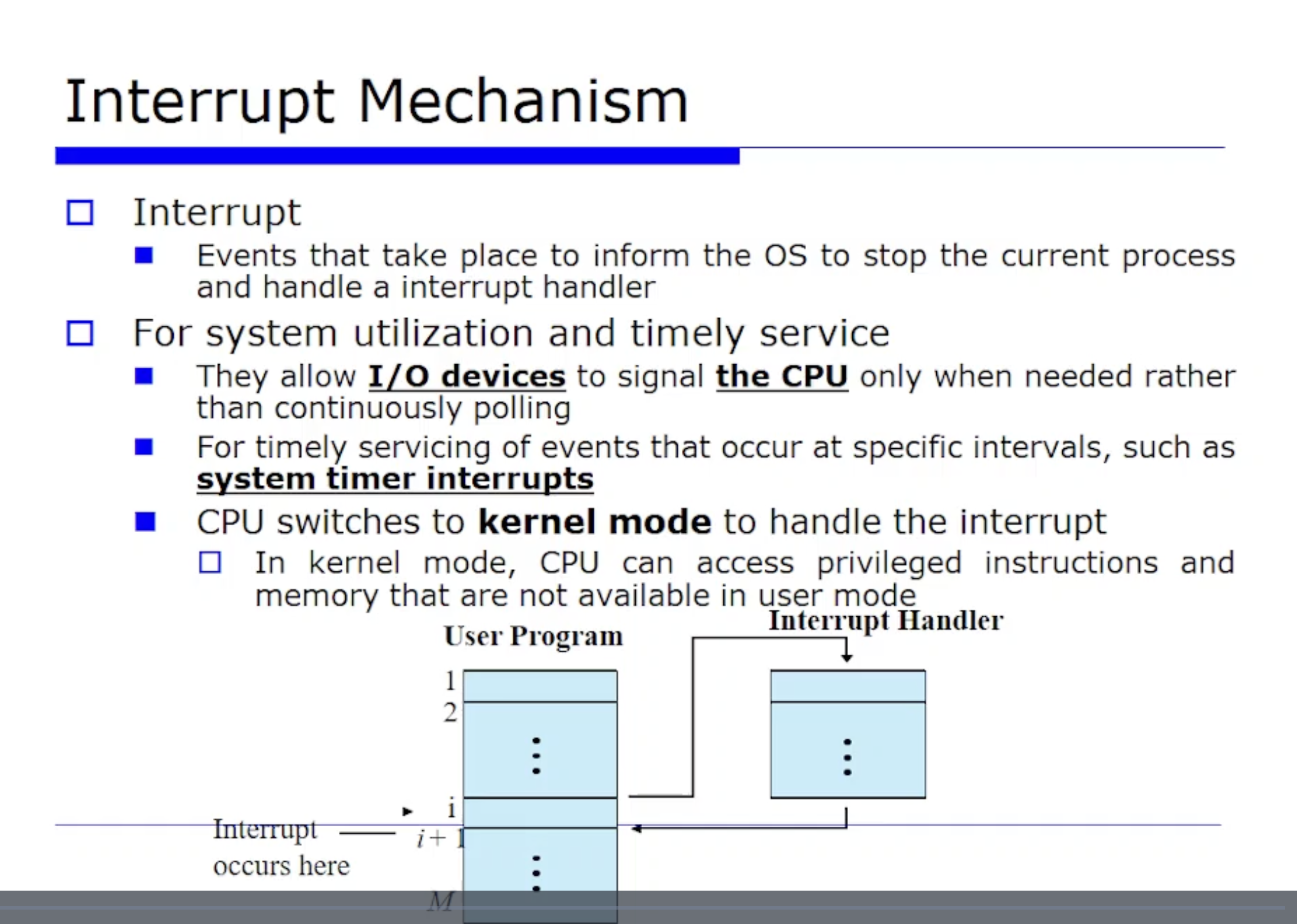
Interrput Mechanism 이란?
Interrput 는 이벤트이다. 또는 교재마다 Signal 이라고 표현하기도한다.
지금 우리가 살펴본것과 같이 Current Process, 즉 현재 실행중인 프로그램을 멈추고 그 이벤트를 처리하기 위한 핸들러를 수행하게끔 하는 과정을 Interrput Mechanism 이라고한다.
Interrupt 라는 것은 이벤트인데, OS 에게 지금 수행중인 프로그램을 멈추고 그 핸들러를 수행하게끔하는 이벤트이다. 그리고 이벤트가 발생해서 Interrput 핸들러까지 처리하는 과정이 기계적일것이다. 그것을 수행하게 하려면 하드웨어적인 서포트가 필요하고, 어떠한 소프트웨어적인 과정이 필요한데 그것을 바로 Interrput Mechanism 이라고 하는 것이다.
Interrput 의 목적
Parallelism 이 가능해진다!
Interrput 의 목적은 역사적으로 봤을때 일단 system utilization 을 높이기 위해서 진화했다. 엄밀히는 CPU utilization, 즉 CPU 활용율을 높이기 위해 진화한것이다.
왜냐하면 이전까지 내용을 다시 되짚어보면, I/O Device 는 꽤 느리다는 단점이 있다. 프린터를 예로 들어보자. 어떤 CPU 가 프런터를 device 에 write 해야한다. 그런데 그게 완료될 때 까지 기다려야한다면, 굉장히 속도가 느린 Device 에서 계속 주기적으로 Polling 해야한다는 번거로움이 있다. ( 폴링(polling)이란 하나의 장치(또는 프로그램)가 충돌 회피 또는 동기화 처리 등을 목적으로 다른 장치(또는 프로그램)의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식을 말한다 )
CPU 와 I/O 디바이스간에 퉁신을 할때 다 끝났는지 안끝났는지 확인하기위해 계속 Polling 하는 작업은 CPU 입장에서 다른 작업을 진행하지 못하기 때문에 성능이 저하된다. 따라서 너가 되면 나중에 나한테 비동기적으로 Signal(Interrput) 을 보내줘라는 뜻에서 등장했다. 그리고 Signal 을 받았을때 그에 알맞은 핸들링 처리를 해주는것이다.
이렇게 된다면 CPU 는 Polling 을 하지않고, 게시를 해놓고 다른 유의미있는 작업을 진행할 수 있게된다. 그러면서 I/O Device 의 프린터도 계속 작동을 할것이다. 즉 Parallelism 이다. I/O Device 와 CPU 가 동시간대에 병행성을 보인다. 이로써 system utilization (시스템 활용률) 이 높아지는 것이다.
시스템 타이머로부터 시간에 대한 서비스를 제공하기 위해 활용
또한 적절한 운영체제의 커널 서비스를 위해서 필요하다. 아까 말했듯이 Interrput 가 없다면 한 프로세스가 계속해서 순차적으로 수행할것이다. 독점할 수 있다는 것이다. 그래서 각 프로세스에게 부여되는 시간 할당량(time slices)을 정해놓았다. 특정 프로세스가 본인에게 부여된 시간 할당량을 다 쓴다면 제어권이 다른 프로세스에게 넘어가는 방식이다.
그렇다면 이 기능을 위해서 운영체제는 시간을 카운팅할 수 있어야할 것이다. 그래서 컴퓨터 시스템에는 시계를 가지고있는데, 보통 2가지 종류의 시계가 있다.
-
상대시간 : 지금, 현재 시간으로 부터 n초의 시간이 지났는지 안지났는지를 카운팅하는 상대시간 => ~초 마다 작업을 진행한다. 즉, 운영체제가 어떠한 작업을 주기적으로 진행할때 상대시간이라는 것이 필요한데, 그를위한 시스템 타이머가 존재한다.
-
절대시간 : 절대시간을 가지려면 전원이 나가도 정보를 유지해야한다. 즉, non-voliatile 속성을 가지고 있는것이다.
아무튼 시스템 타이머(컴퓨터 시계)가 딸깍거릴때마다 Interrput 가 가는것이다. 그래서 시간이 타이머로부터 Interrput 가 오면 Time Handler 로 가서 시간을 업데이트하는 루틴에 따라서 업데이트한다.
Mode Switching
Interrput 이벤트가 발생했을 떄 그를 처리하는 Interrput Handler 의 정체는 바로 OS 이다. 그래서 핸들러로 들어갈때 유저모드에서 커널모드로 바뀌게된다. 즉 유저 프로그램에서 Interrput 가 발생해서 핸들러로 들어가게 된다. 이를 Mode Switching (모드 전환) 이라고 표현한다.
유저모드는 제약되는 것들이 있고, 커널모드에서는 권한에 있어서 제약되는 것이 없다.
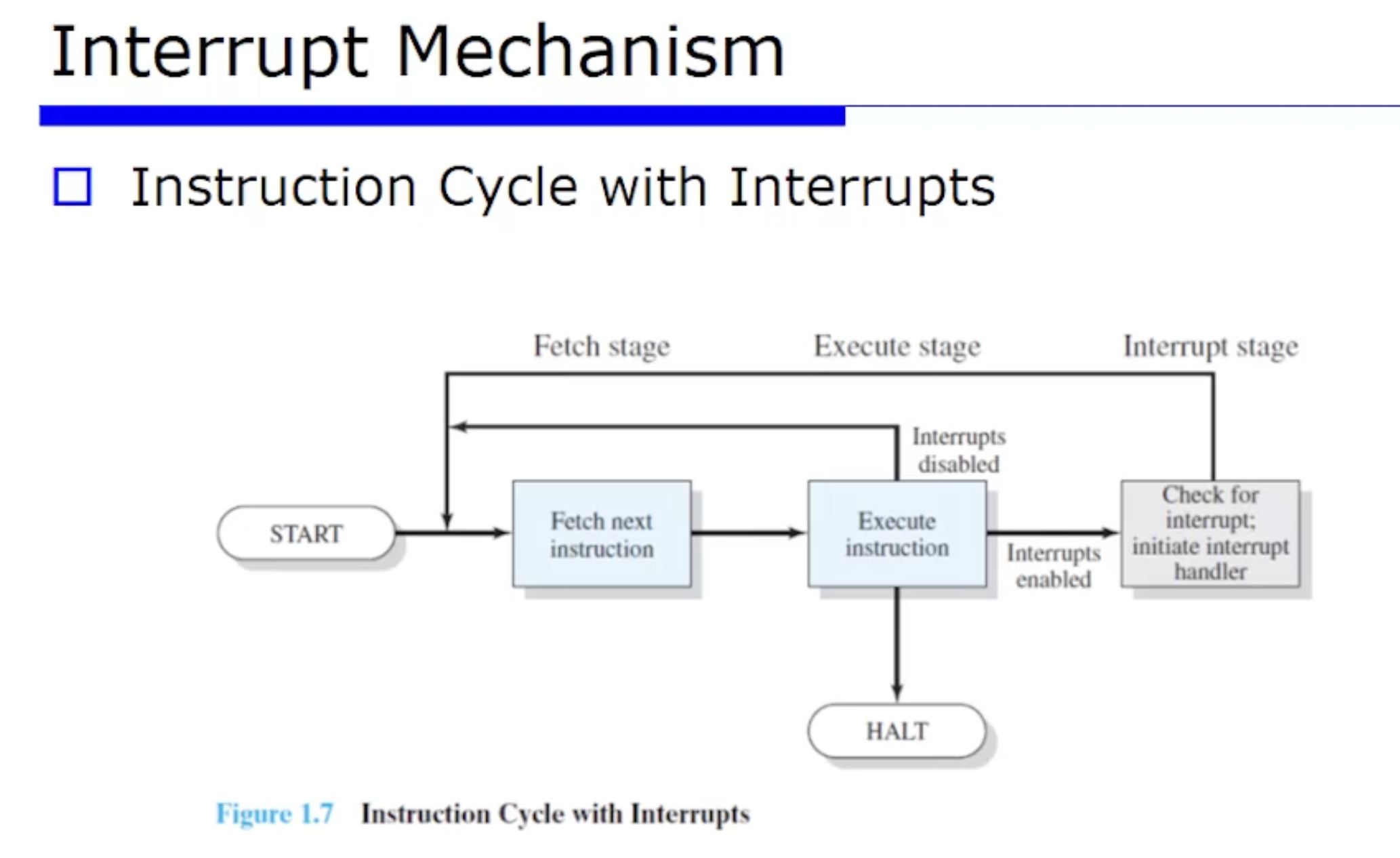
이에따라 지난번에 살펴봤던 Instruction Cycle 이 조금 수정되어야한다. Interrupt 가 발생했을 때 핸들러를 처리하고 와야한다. 그런데 중요한건 어디로 가야하냐면, 프로그램이 i번째 명령어를 수행하고 Interrput 가 처리하고나면 당연히 이제 다음 명령어를 가리킬 수 있도록 되돌아오는 것 까지가 Interrput Mechanism 이다.
하드웨어적으로, 소프트웨어적으로 어떻게 처리되는지를 보려면 먼저 이 Interrput Mechanism 을 위한 구성요소들을 살펴봐야한다.
Interrput 단계
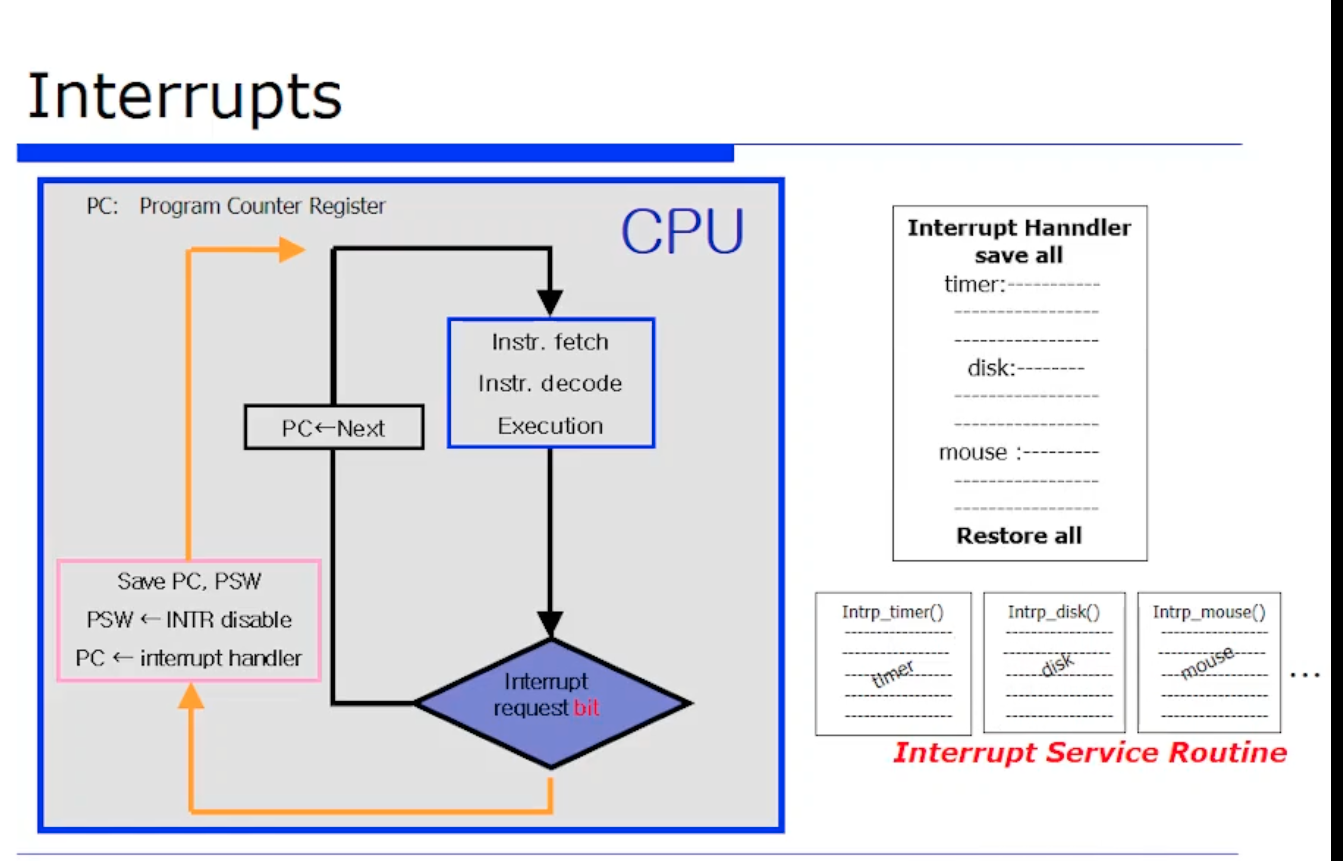
우선 첫번쨰로 CPU 가 바뀌었다. 지난 수업때 헀던것은 2단계로 fetch 와 execution 이였다. 그런데 위 그림처럼 Interrupt 를 지원하기위해, Interrupt 단계가 추가되었다.
fetch 와 execution 단게를 마치고나면 한 명령어에 대한 처리가 완료될것이다. 한 명령어에 대해 처리를 마치고나면, Interrupt 가 왔는지 안왔는지에 대한 정보 1bit 가 어딘가에 저장되있다고하자. 그 bit 를 확인하면 된다.
Interrput 로 인해 PC 에서 발생하는 문제점
그러면 둘 중 하나일것이다. 1bit 이므로 Interrput 가 왔거나 or 안왔거나이다.
만약에 Interrput 가 와있으면 CPU 는 Interrput 이벤트에 해당하는 핸들러를 게시하고 처리하러 가야한다. 그렇다면 Interrput 핸들러의 PC 값이 Interrput Handler 의 주소로 바뀌게 된다.
그러면 PC 가 바뀌니까 핸들러코드를 fetch 해온다. 그런데 문제가 하나있다. 만약에 Interrput 가 안왔으면 PC가 안바뀔것이다. Interrput Mechanism 은 일반적으로 Interrput 를 처리하고 그 프로그램의 다음 지점으로 넘어와야한다.
PC 값을 어디에 저장해두지? : 메모리 vs 레지스터
그런데 그 정보를 기억하고있어야하는데, 만약에 PC 의 값을 핸들러로 업데이트 해버리면 다음에 넘어가야할 레지스터 주소값이 날라가버리게 된다. 따라서 업데이트를 하기전에 PC 값을 저장해야한다.
그렇다면 PC 값을 어디에다 저장해두어야하는가? 컴퓨터에서 state 값을 저장해 놓을 곳은 레지스터 또는 메모리이다. 레지스터의 경우는 프로그램이 커널 OS 로 넘어가야하는데, 그러면 또 업데이트 될수도 있고, 그리고 레지스터 그리 많지도않아서 아껴쓰는것이 좋다.
그래서 중요한것이 뭐냐면, Interrput 가 발생해서 핸들러로 넘어가면 OS 라고 했었다. 그러면 아까봤던 시스템 타이머에 의해서 시간 할당량(time slice) 를 다 소진하게되면 현재 프로세스 A가 아닌 다른 프로세스B 로 바뀔수있다.
그러면 프로세스 B가 또 system time interrput 가 걸릴수있다. 그러면 프로세스 B 도 PC 값을 저장할 필요가있다. 즉, 한곳에 고정시켜놓으면 또 다른 프로세스가 업데이트 할수가 있다. 따라서 이는 레지스터에 저장할 것이 아니다.
PC 값은 각 프로세스마다 가지고 있을 수 있는 정보이다. 결국 PC 값은 레지스터가 아닌 메모리에 저장해야한다.
그리고 이렇게 함수 단위에서 발생하는 복귀 주소를 스택이라는 메모리 지역에다 저장해놓는다. (정확히는 스택외에도 구현방식에 따라서 스택외에 다른 메모리 지역의 방식에다 저장될 수 있지만, 지금 일단은 가장 보편적인 스택을 생각하면 편하다!)
메커니즘 요약
명령어를 수행하고, 항상 하나의 명령어가 끝날때마다 Interrput 가 왔는지 여부를 1bit 를 통해 체크하고, 만일 Interrput 가 왔다면 PC 값을 스택 메모리에 저장해두고, 그 다음 PC 값을 핸들러의 주소로 업데이트한다.
PIC
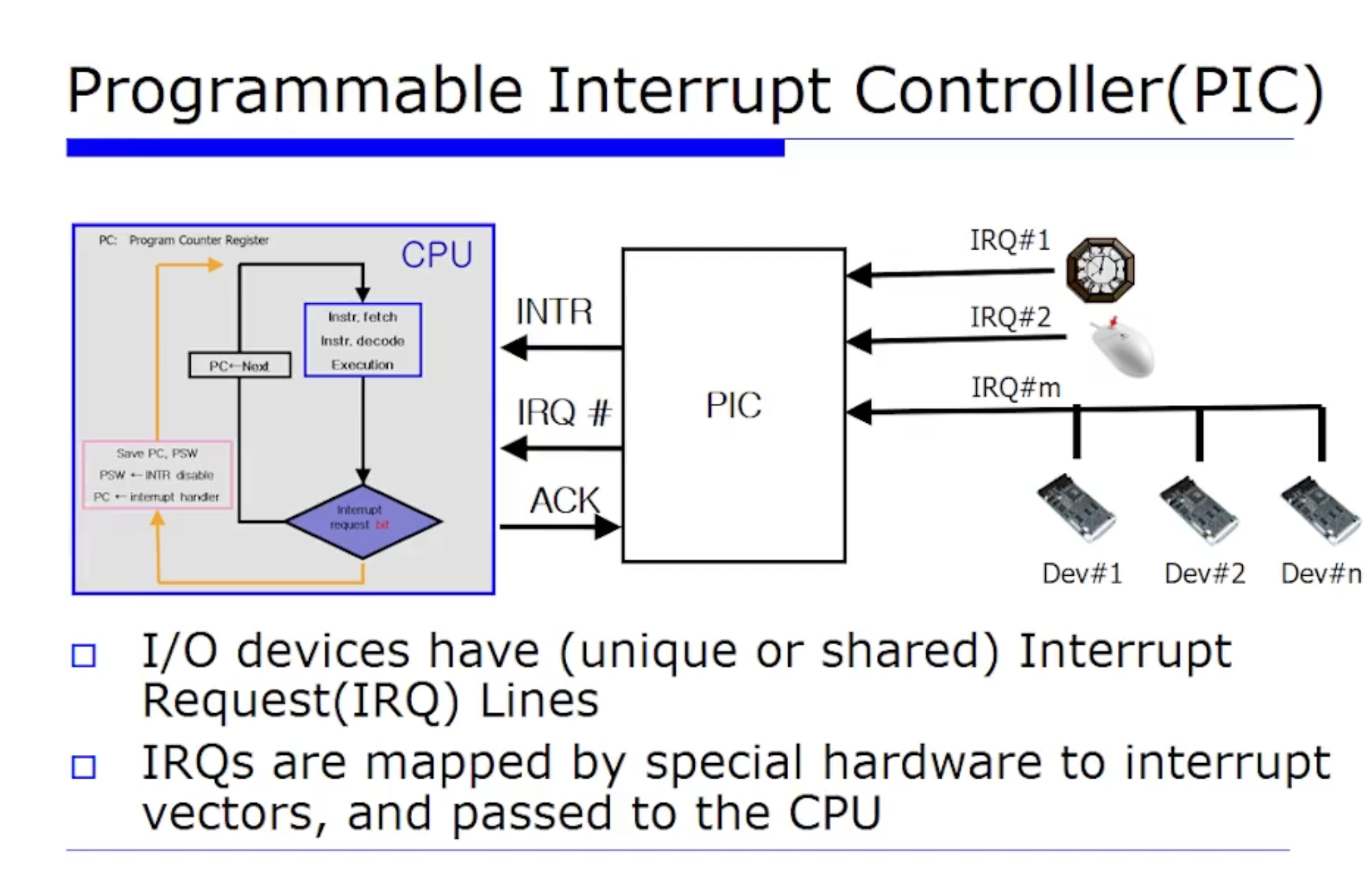
그러면 핸들러로 점프해서 핸들러에서 계속 수행했다고 해보자. 수행하는 핸들러가 끝나면 다시 복귀(restore)한다. 그 과정을 살펴보도록하자.
지금까지는 Interrput Mechanism 을 지원하기위해 하드웨어를 얘기하고 있는 것이다. 그리고 PIC 라는 별도의 하드웨어가 또 필요하다. PIC 는 우리말로 "제어기" 라고 번역되어있다. 말그대로 Interrput 를 제어하는 것이다.
위 그림처럼 한 컴퓨터 시스템에 외부 장치(디바이스)들이 굉장히 많을텐데, 그러니까 애네들이 직접적으로 CPU 에 많은 핀들이 있는데, CPU 의 핀도 칩의 일부를 결정하는 중요한 자원이다. 따라서 외부 장치를 CPU 에 직접적으로 연결시키면 확장성이 떨어지니 그를 통합,관리할 수 있는 제어기가 바로 PIC 이다.
그러면 제어기에 한 줄로 장치를 다 연결해서 각 장치에다 식별 가능하도록 번호를 부여한다. 이때의 번호를 IRQ(Interrput Request Number) 라고한다. 즉, 장치마다 IRQ 번호를 부여해서 현재 CPU 에게 온 이벤트가 어디로부터 온 것인지 식별 가능하도록 식별자 역할을 해주는 것이다. 이때 이벤트는 마우스, 키보드등 다양하게 PIC 에 연결되어있다.
PIC 의 기능
- Signal : 외부 장치의 Interrput Signal 을 벡터로 변환하는 기능
- masking : PIC 의 약자중 P 는 Programmable 이다. Programmable 한다는 것은 내가 얘를 enable/disable 할수 있다는 것이다. 이것을 masking 이라고한다. 즉 flag 를 on/off 시키는 masking 역할을 하는것이다.
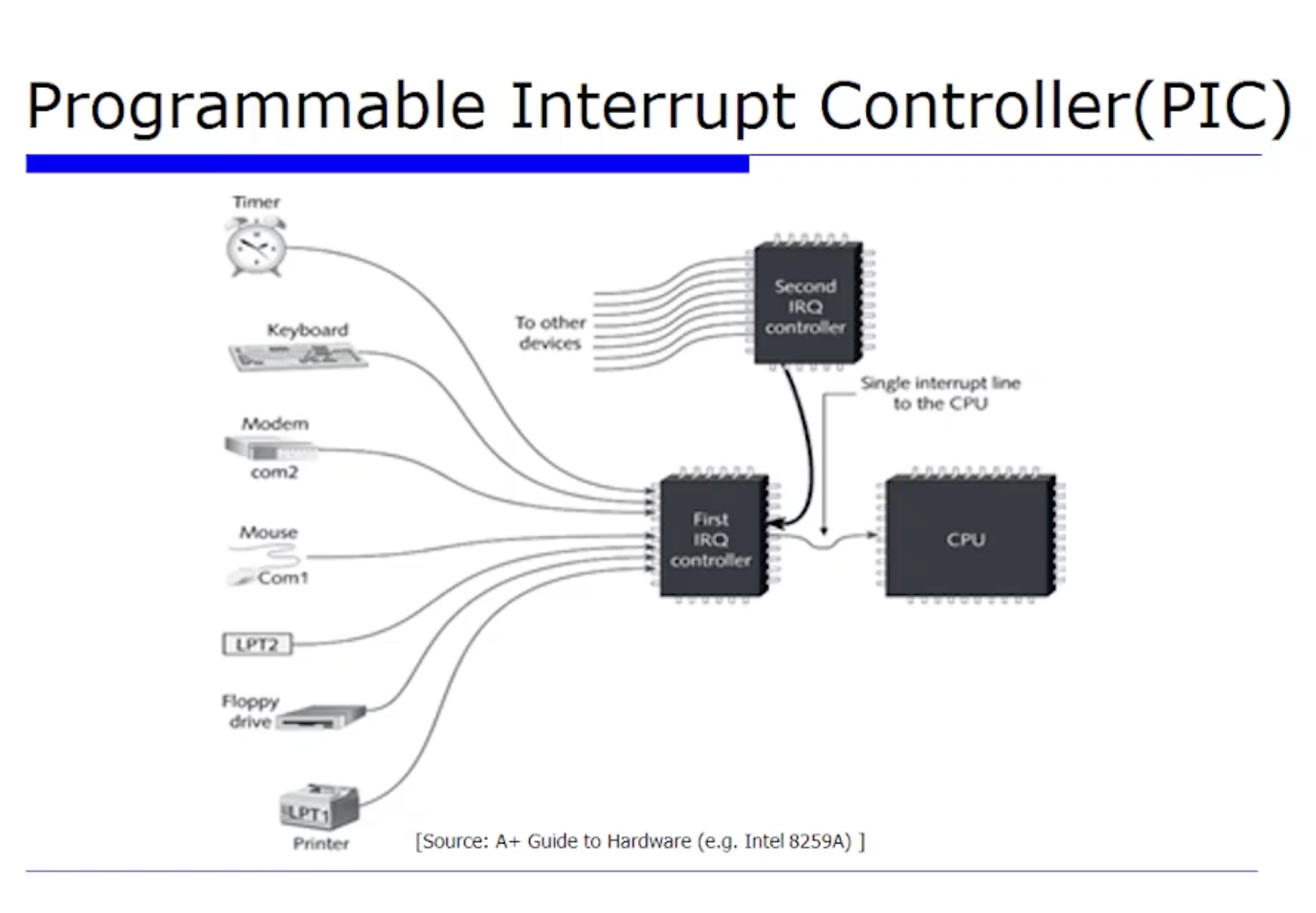
예를들어서 위 그림은 인텔의 초기 PIC 이다. (또는 IRQ Controller 라고도 불린다. )

이렇게 디바이스들이 총 8개의 핀이 제공되고 있는데, 디바이스들이 여기에 한 핀씩에 연결돼서 몇번 Interrput 가 왔는지 Interrput 번호를 식별하도록 구현되어있다.
이렇게 7개의 핀은 장치들과 연결시키고, 나머지 한 핀은 직렬화해서 또 다른 칩에 확장성있게 연결할 수 있다. 즉 확장성에 용이하다.

PIC 이 이렇게 장치의 요청을 IRQ 로 변경해주고, Interrput 가 왔다는것을 알려준다. 그 다음 CPU 로 부터 응답이 올때까지 기다린다. 그런 동기적인 방법으로 할 수 있다.
또한 언급했듯이 masking 도 할수있다. => 가령 내가 원한다면 어떤 장치를 비활성화 시킬 수 있는것이다. 그러면 동작을 안하는 것이다. 예를들어 마우스나 키보드에서 손을 때면 Interrput 신호가 가지 않는것이다.
Interrupt Mechanism
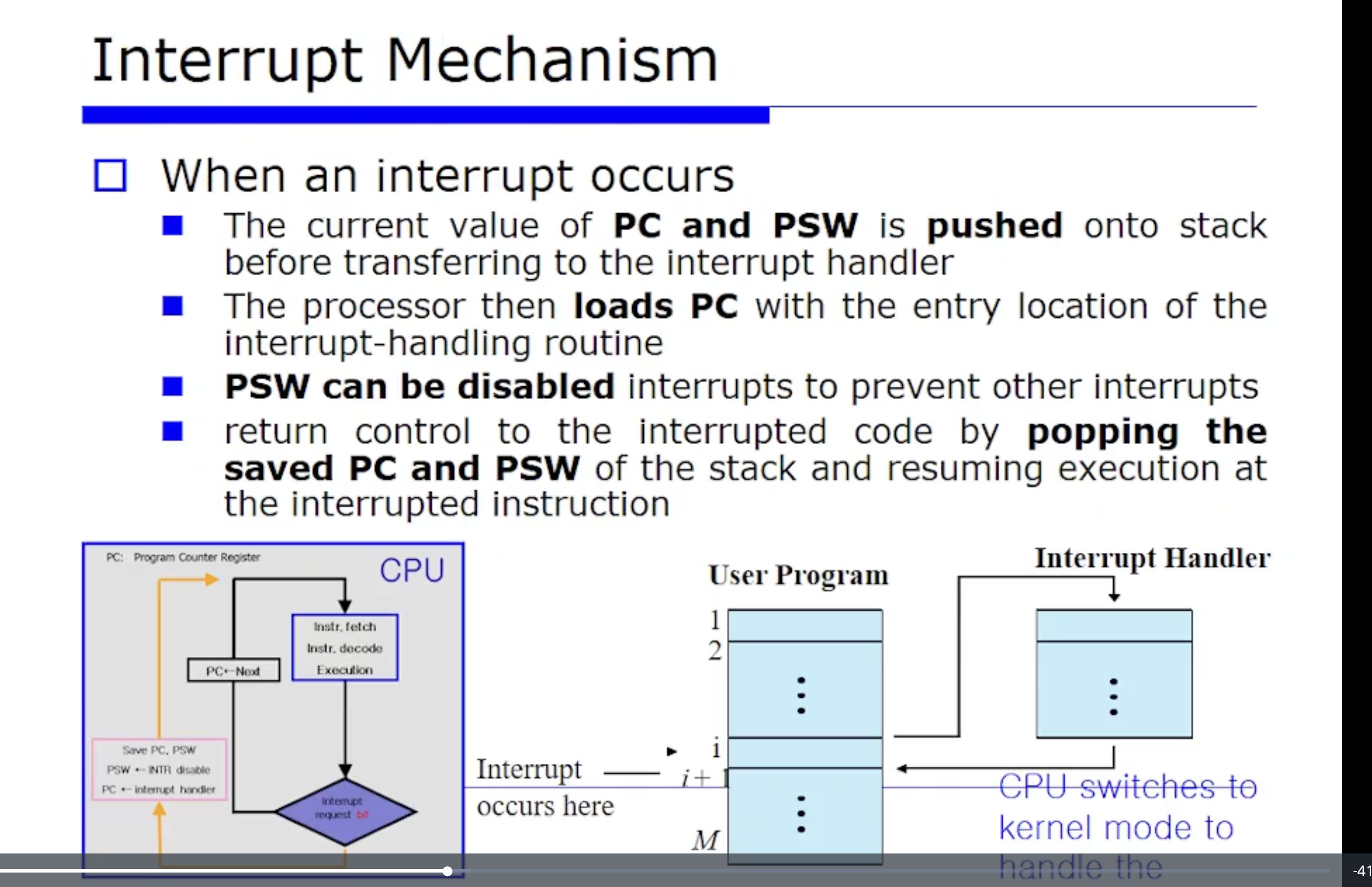
interrupt 는 이벤트이다. 또, 현재 실행중인 프로그램을 중단시키고 정의된 interrput 핸들러를 수행시키는 과정을 interrupt Mechanism 이라고 했었다.
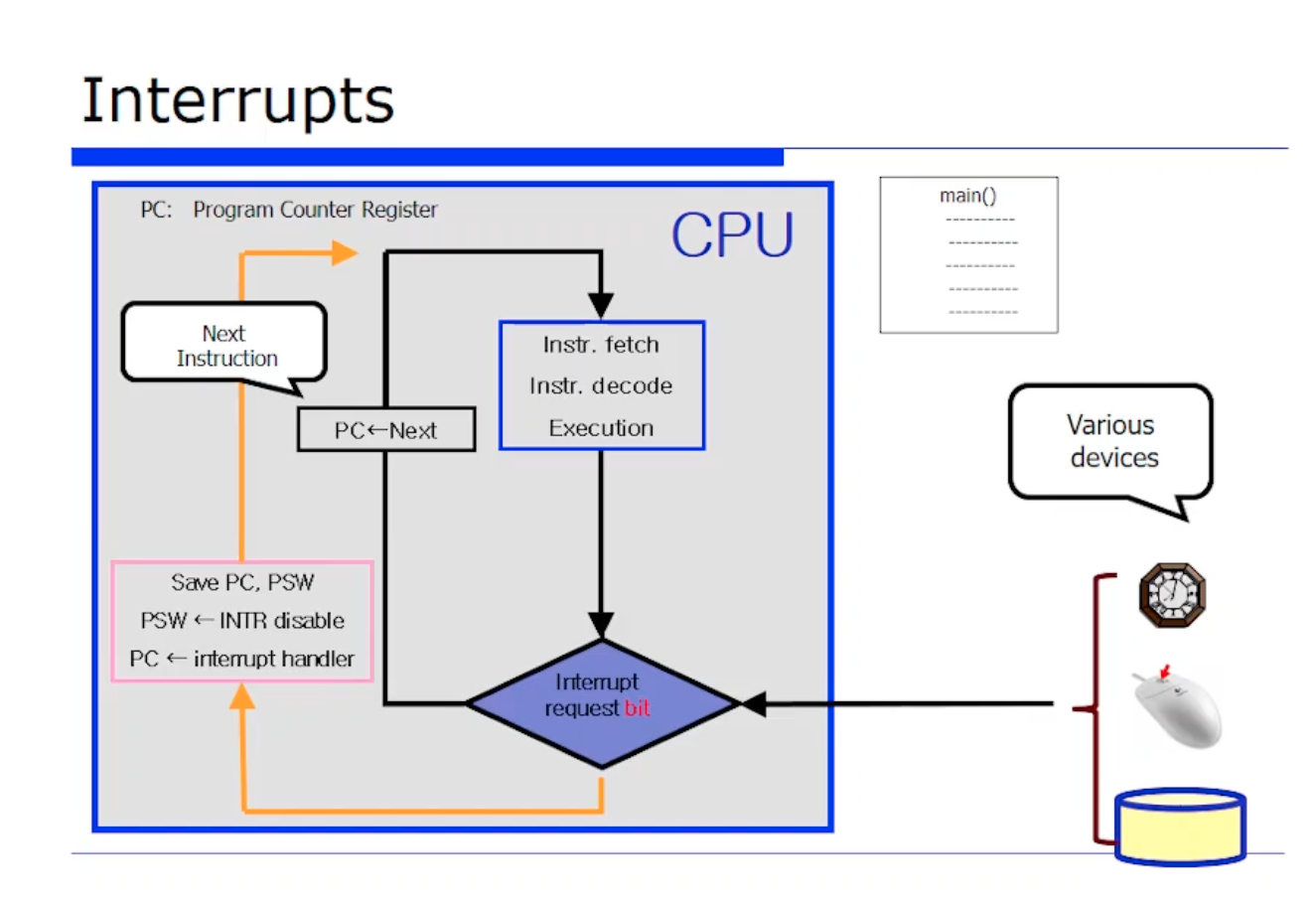
그러면 그 절차대로 다시 복습해보자면, interrput 가 i 번째 수행후에 확인했던 interrput 가 왔다. 그러면 하드웨어적으로 i번째 명령어에 대해 fetch, execute 을 마치고 1bit 을 보고 interrupt 왔는지 안왔는지를 본다.
안왔다면 계속 도는것이고, 왔으면 위 그림에서 주황색 라인을 타는 것이다. 즉 PC 값을 먼저 save 하고 PC 값의 interrput 핸들러 주소가 바뀌는 것이다. 이렇게되면 CPU 는 PC 가 가리키는 값을 또 fetch 해올것이다. 그 주소가 당연히 메모리 공간상으로 보면 운영체제 핸들러 코드가 되는 것이다. 그러면 interrupt 가 처리될 때 까지 뺑뺑 도는것이다.
PSW
결론은 update를 해서 변경이 일어나기전에, 상태를 잃지 않도록 먼저 save 를 하는것이다. 그런데 PC 말고도 하드웨어적으로 바뀔 수 있는게 또 있다. 그건 바로 PSW 이다. PSW 에는 어떤 정보가 들어갈 수 있다고 했었을까? 바로 Condition Code, Interrput Flag 값 (interrput 를 enable 할지 disable할지에 대한 것) 이 들어갈 수 있다고 배웠었다.
다중 interrput 처리방법
보통은 interrput 를 처리하는 2가지 모드가 존재한다. interrput 를 처리하고 있는데 또 interrput 가 오면 이를 어떻게 처리해야할까? 즉 다중 interrput (multiple interrupt) 가 발생한 상황이다.
- 순차 interrput 처리방식 : 가장 심플한 방법은 interrput 를 처리할때 꺼놓는 것이다. 꺼두면, 즉 pending 하고 있다가 enable 하면 또 알려주기 떄문이다. (state 를 알수있기 때문에)
그러면 이제 interrput 가 온것을 인지하고 바뀔때, 나는 순차 interrput 모드란다! 라고하면 disable 시킨다. 그 정보가 PSW 에 있다고하면 바뀔것이다. 따라서 PSW 도 함께 save 하고 update 한다. 이는 필연적으로 interrput 가 발생할 때 하드웨어적으로 바뀌기 때문에 save 못하고, 스택에 save 된다. (이때 정확히는 Control Stack (제어 스택)에 저장된다)
정리
우리 교재에서는 PC 와 PSW 가 스택에 저장해야할 최소한의 필연적인 정보이다. interrput handling 을 할때 가장먼저 이 2개가 바로 바뀌기때문에 바로 save 시키는것이다. 이들을 스택에 save 하고 그 다음에 PC, PSW 가 바뀌고, 그 다음에 disable 되는것이다. 그러고 다 끝날때쯤에 restore 한다.
또 커널 모드로 바뀐다. Interrput Handler 는 커널 코드이기 때문에 커널 모드로 바뀐다.
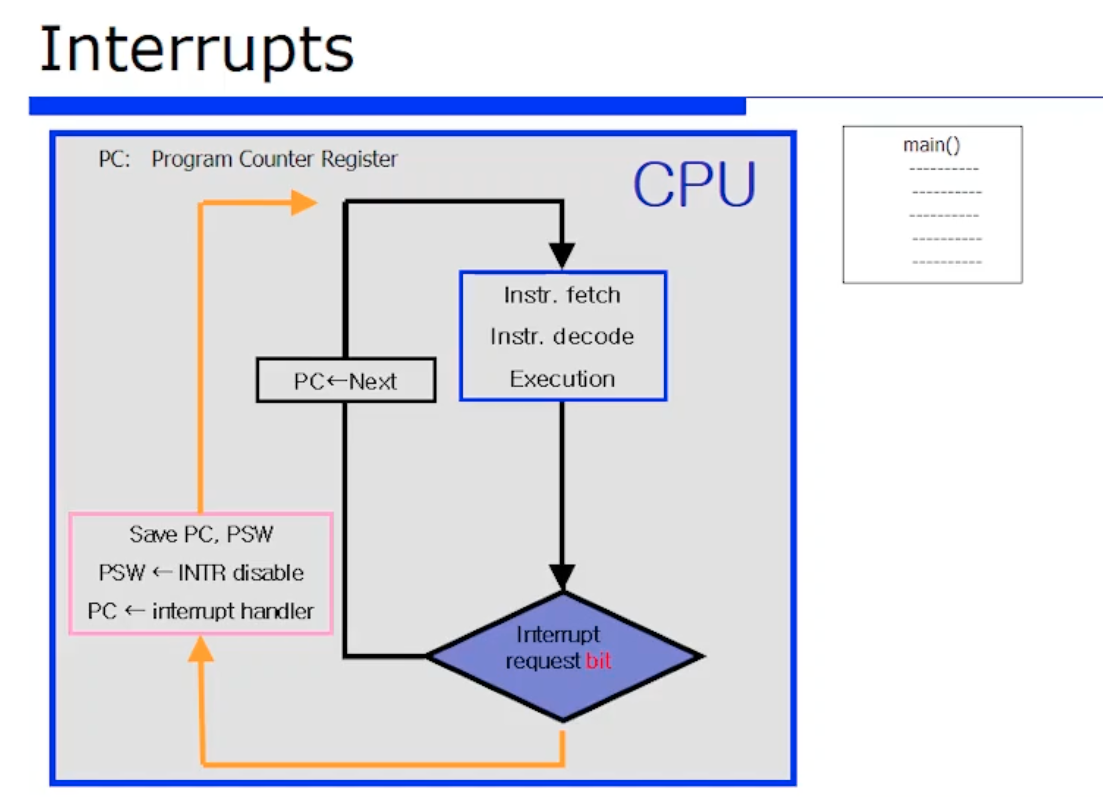
다시한번 정리해보자. c언어 코드가 main 함수에서부터 시작한다. 그러면 CPU 는 fetch, execution 을 수행할것이다. 한 명령어에 대한 수행을 마치면 interrput 가 왔는지 안왔는지 체크할것이고, 없다면 다음 명령어에 대해서 또 반복 수행할것이다. (순차 interrput 처리방식)
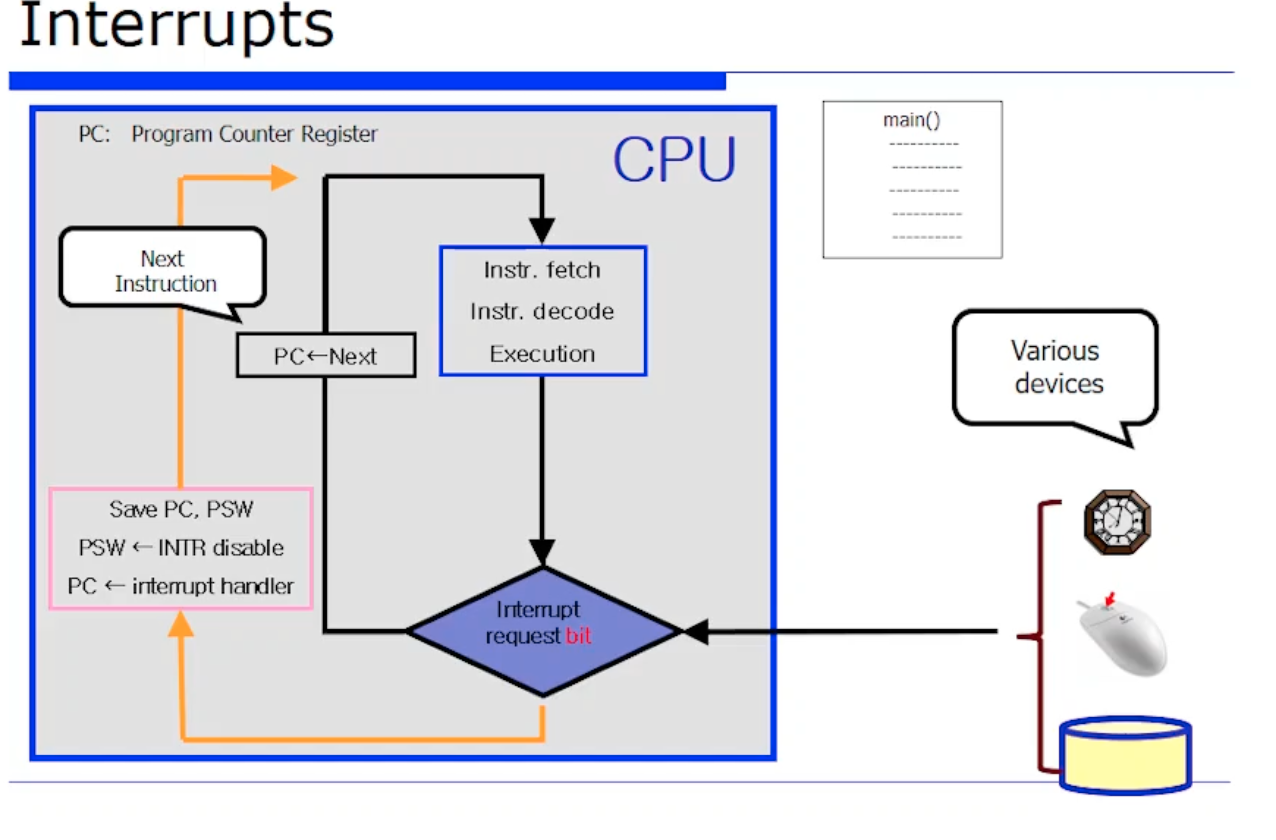
그러다가 interrput를, 즉 이벤트를 외부 디바이스 누군가보냈다. 그런데 외부에 있는 디바이스 이기 때문에 시간적으로 동기화가 될 수 없다. 만약에 fetch 하고 있는데 만약에 interrput 가 오는 경우, 해당 interrput 는 즉각적으로 바로 처리되는 것이 아니다. 한 명령어에 대한 처리가 다 끝나야 볼 수 있기 때문이다.
따라서 시간적인 gap 이 존재한다. interrput 이벤트의 발생시점과 현재 실행중인 명령어가 처리되는 시간과의 gap 이다. 그래서 보통 interrput 를 asynchronous 하다고 말하는 것이다. (비동기적으로 처리된다)
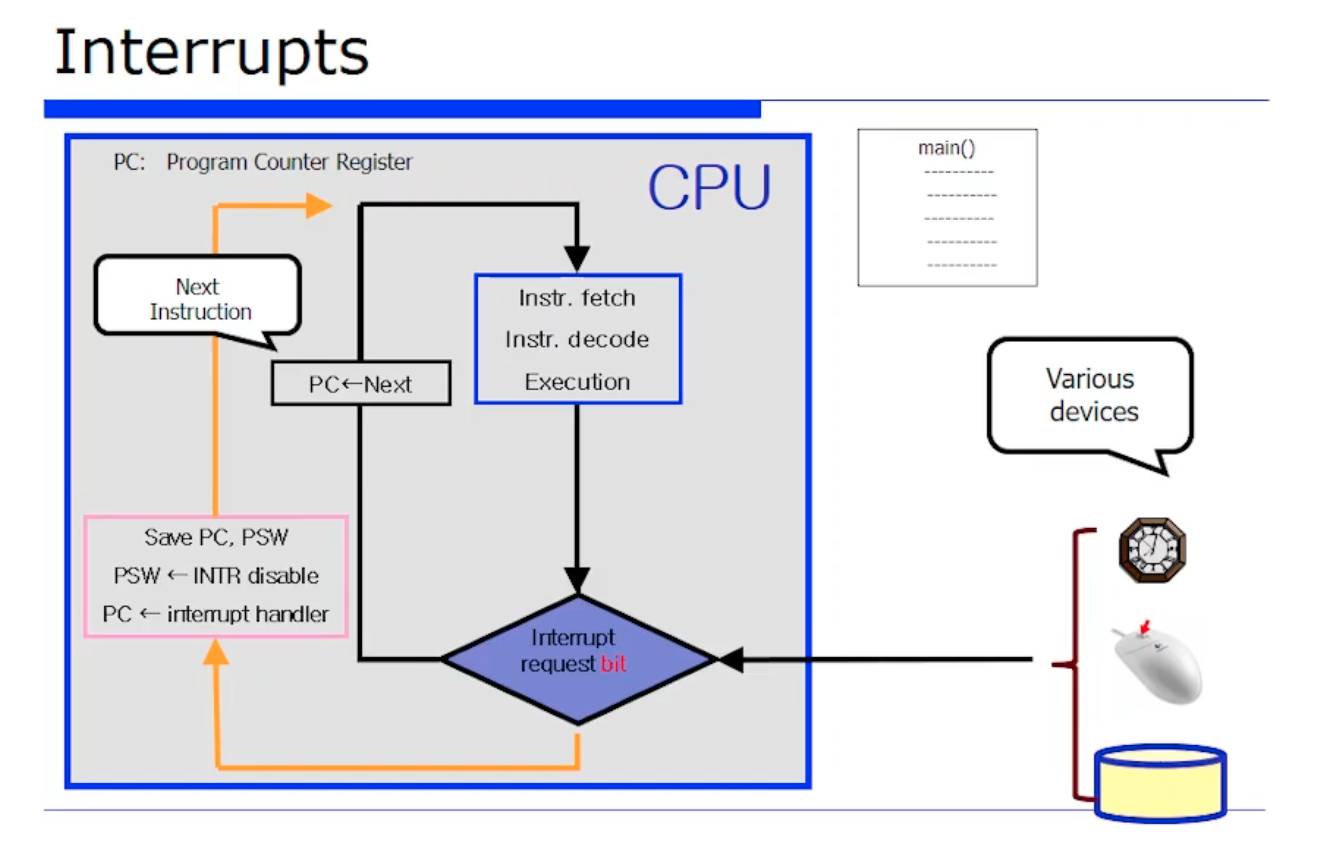
위와 같이 n번쨰 IRQ 외부장치로부터 이벤트가 왔다는것을 알면, 적절한 PSW 를 스택에 save 하고 interrput 를 disable 할것이다. 그리고 interrput 핸들러 주소를 바꿔서 점프하는 과정으로 가게된다.
ISR
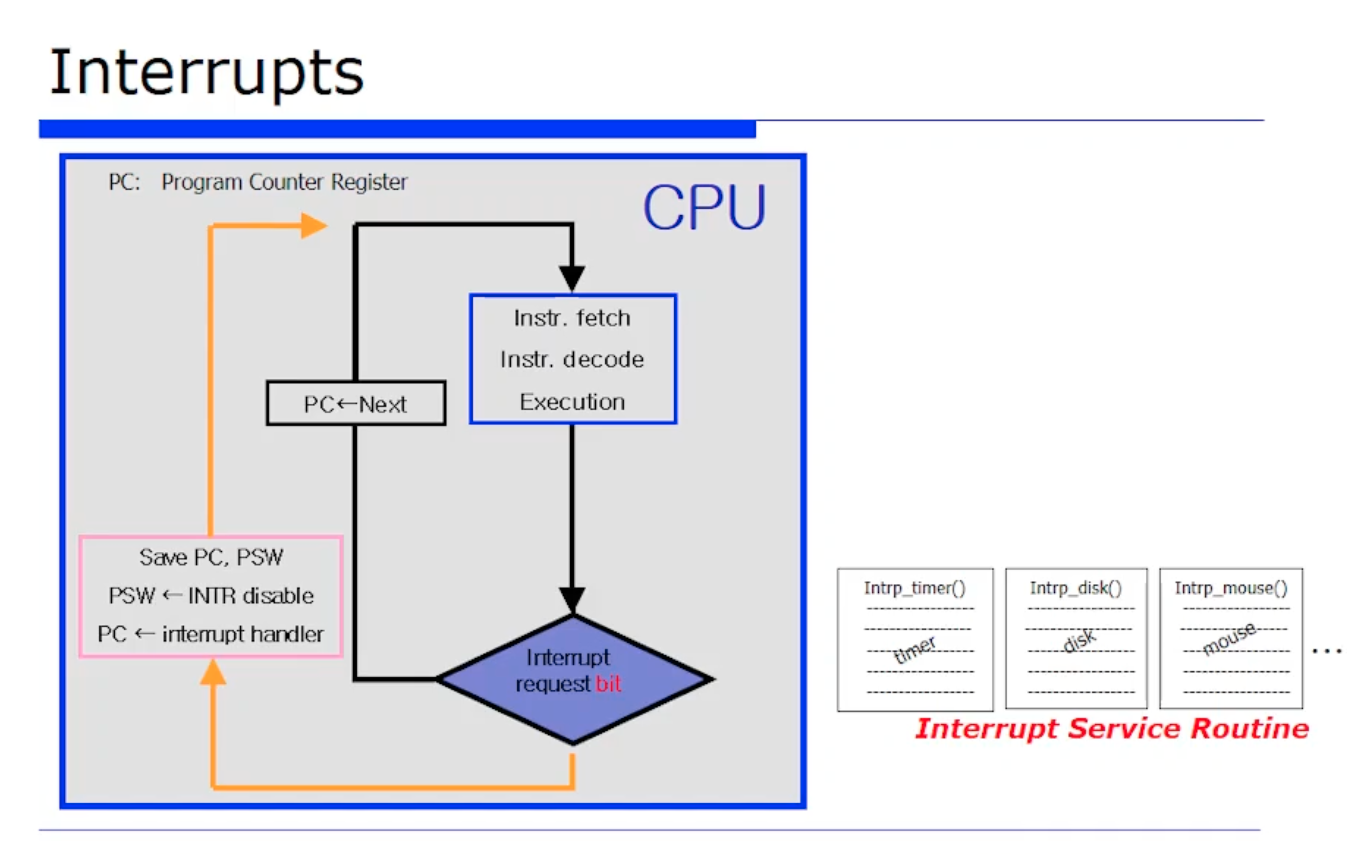
지금껏 interrput 핸들러라는 용어를 많이 사용했다. 그런데, 커널 코드에는 시스템 타이머, 마우스, 디스크마다 (디바이스마다) 처리하는 실제 작업은 다르다. 디바이스마다 각각의 핸들러를 가지고있는데, 이걸 더 구체적으로 그 디바이스의 특회된 함수를 interrput service routine 이라고한다. 줄여서 ISR 이다.
- 여러 교재마다 interrput 핸들러와 ISR 을 서로 동일한 표현으로 사용하는 경우도 있는데, 교수님은 조금 다르다고 말하심
interrput 핸들러가 ISR 보다 더 큰 개념인데, 이것은 디바이스 specific 한 용어이고, 그걸 처리하기위한 루틴(routine)이다. interrput 핸들러는 interrput 들이 오면 공통 루틴이온다. 무슨 공통 루틴을 갖게 되는지 알아보자.
우선 와서 save all 이라는 것을 한다. 이때 save all 이라는건 그 프로그램의 직전 상태의 state (context, 즉 문맥) 들을 모두 save 한다는 뜻이다.
=> 아까 프로그램이 수행하던 레지스터 정보(문맥)들이 있을것이다. PSW 말고도 범용 레지스터들도 본인이 작업중인 것들이 있고 각각 임시 결과값이 들어있을텐데 프로그램이 완전히 바껴서 update 되면 다 날라가버리므로, 따라서 모레지스터들이 들고있는 정보들을 모두 save (save all) 하는 것이다.
그리고 커널의 진입점 중 하나가 interrput 가 발생했을 떄이다. 커널 코드중에 방금 save all 하는 것이고, 끝날때쯤에 다 처리하고나면 다시 restore 하는것이다. 그러면 시스템 타이머일때, 마우스일때, 디스크일때 등 모든 외부 디바이스에 대한 각각의 함수를 실행하는데 그 context (문맥) 을 save 하고 restore 하는 이런 과정을 다 포함한것이 바로 interrput 핸들러이다. 그리고 디바이스 마다의 각각의 함수를 ISR 이라고 하는 것이다.
=> ISR 이 interrput 핸들러의 부분집합임을 구분하자!
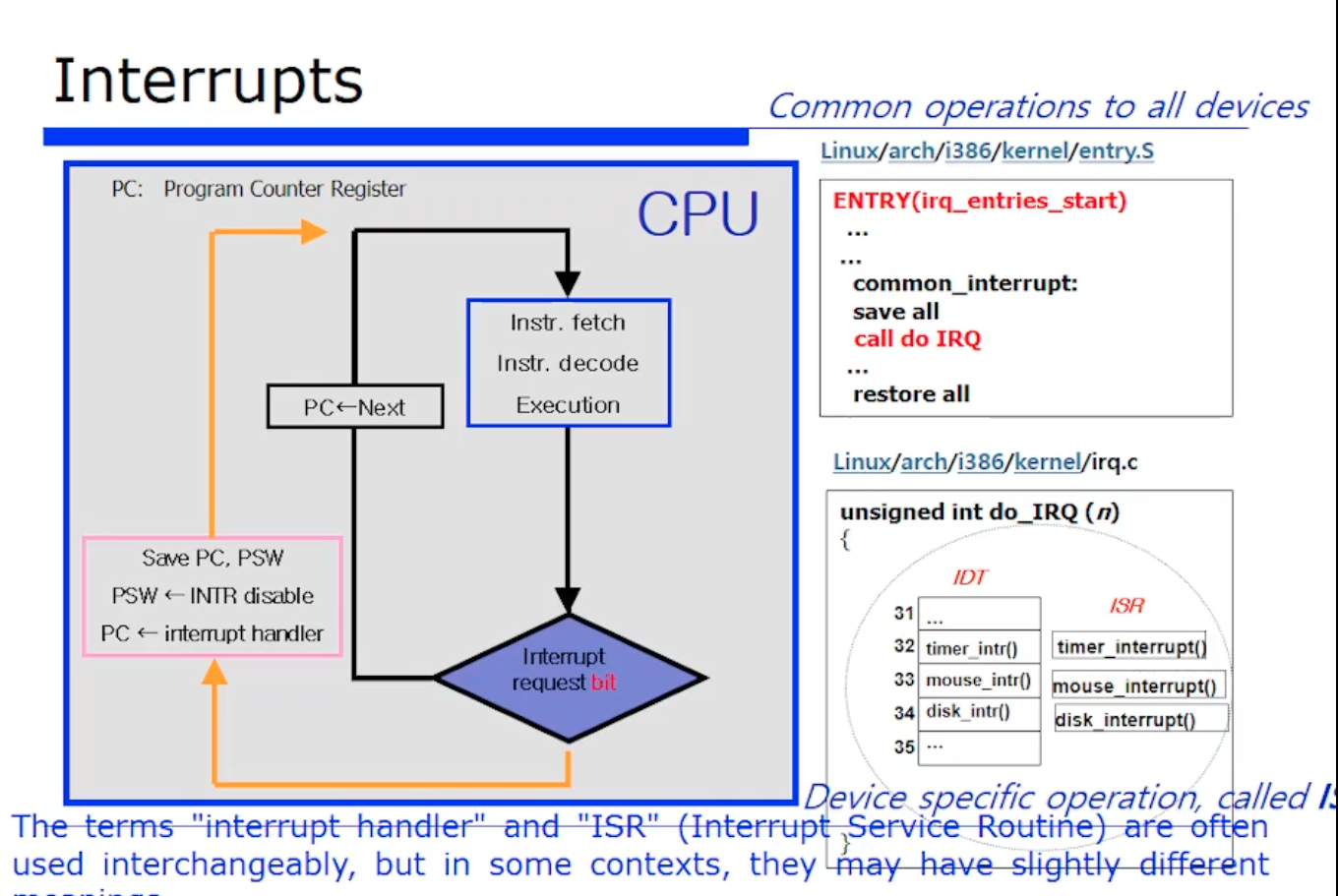
더 구체화된 코드로 위처럼 어셈블리어가 있다. 리눅스의 경우는 do IRQ 라는 함수가 있다. 이 함수부분이 c언어로 넘어오는 것이다. 그래서 interrput 벡터 번호를 가지고, 그 번호에 따라서 핸들링하는데, 보통 인텔과 같은 현대 아키텍처들은 그 interrput 들 각각 마다 번호들이 있다고 했었다. 각각의 interrput 번호에 따르는 ISR 의 주소, 즉 function pointer (함수형 포인터) 이다. 이 함수 포인터들에 대한 테이블을 가지고 있는데, 그 테이블 이름이 IDT(Interrput Descriptor Table) 이라고한다. (interrput 를 처리하기 위한 ISR 의 함수형 테이블 정도로 이해하면된다)
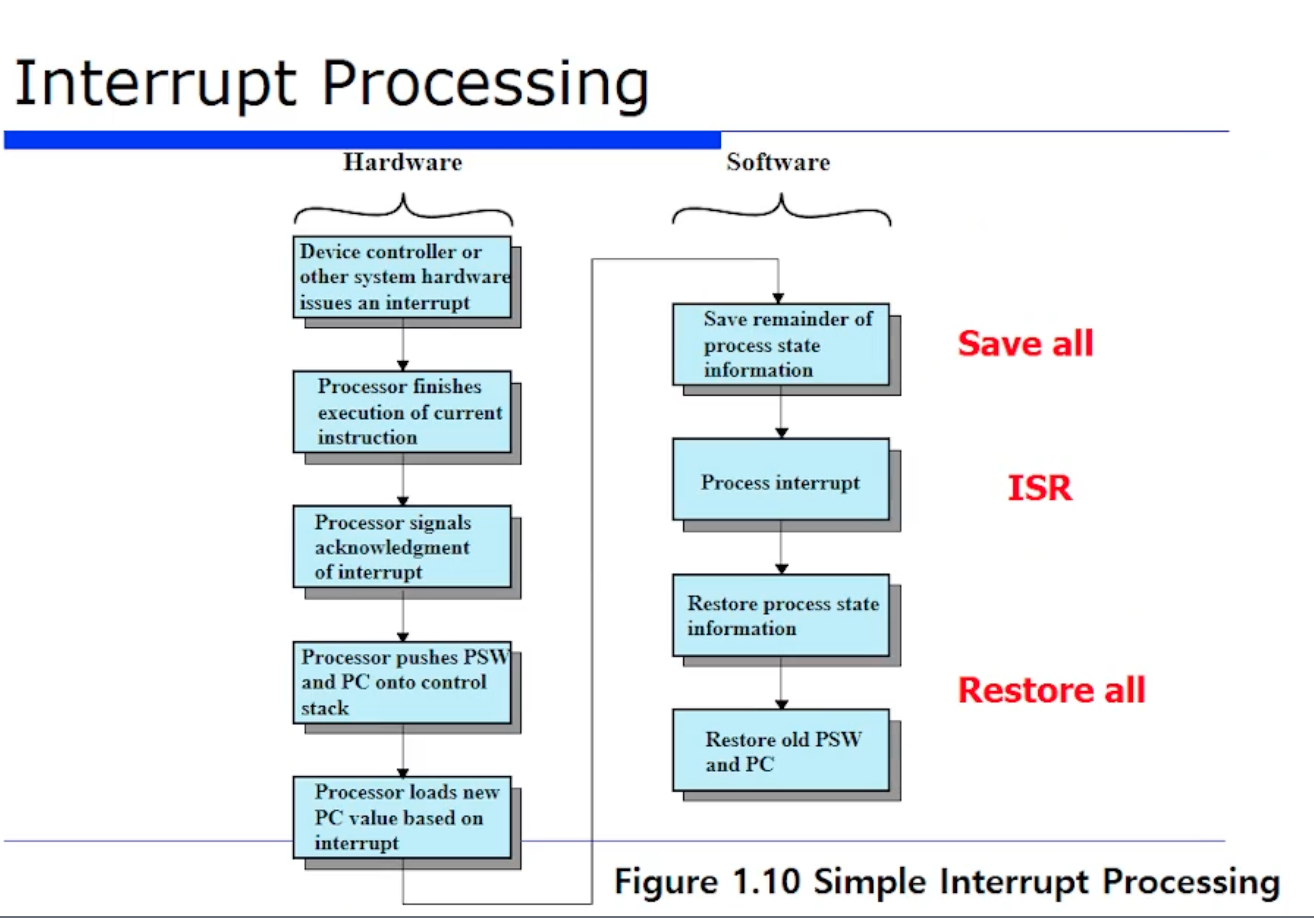
위 그림은 Interrput Mechanism 에 대한 하드웨어적인, 소프트웨어적인 흐름도를 정리해 놓은 것이다.
하드웨어 동작
1.가장 먼저 디바이스 컨트롤러(Device Controller) 가 interrput 를 issue 한다(발생시킨다). 즉 signal 을 보낸다. 여기서 Device Controller 는 Interrput Controller, 즉 PIC 이라고 보면된다. PIC 이 interrput 가 왔다라고 하는것이다.
2.Processor (처리기) 현재 명령어 수행을 다 끝낸다. 일단 자기가 실행해야할 것들을 다 마쳐놓는 것이다.
3.그러고 interrput 가 왔는지 안왔는지 확인됐으니까, 응답을 보낸다.
4.interrput가 왔다는 것을 알게되었다. 따라서 CPU 가 가장먼저 해야할일은 PSW 와 PC 를 메모리의 control 스택에 저장해놓는다.
5.PC값을 새로운 PC 값, 즉 interrput 를 핸들링하기 위한 주소로 업데이트한다.
=> 여기까지가 하드웨어의 동작이다.
소프트웨어 동작
6.그러면 아까 PC 값이 새롭게 업데이트 되었으므로, 즉 바뀌었으므로 점프해서 아까 소프트웨어에 관해서 봤던 interrput 핸들러 공통 routine(루틴)으로 온다. 그러면 거기서 save all 을 한다. 즉 PC, PSW 을 제외한 나머지 부분의 state 를 모두 각 프로세스마다 가지고 있는 메모리에 (스택에) save 하는 것이다.
그런데 여기는 사실 운영체제 코드인 어셈블리어이다. 즉 소프트웨어적으로 바꿀 수 있는것이다. vendor (운영체제) 마다 다를 수 있을것이다.
7.실제 interrput 를 처리하는데, 이게 엄밀한 용어로는 ISR 이다. 이 과정에서 IDT(interrput descriptor table) 테이블이 관여된다. (또는 다른말로 IVT(interrput vector table) 이라고도 불림)
8.그 다음은 process state information 을 restore 한다.
9.그 다음은 예전의 PSW 와 PC 값을 restore 한다.
=> 이러한 과정들이 바로 interrput 메커니즘이다.
요약
지금까지 한 것을 다시 요약해보자. interrput 지원을 위해 하드웨어적으로 어떤 지원이 있었는가? 일단 CPU 가 interrput 사이클 주기중에서 interrput 가 왔나 안왔나 확인하기위해 interrput 1 bit 를 확인하는 절차가 회로적으로 필요하다.
그리고 그것에 대응해서 칩 vendor 들은 interrput 핸들러가 있다고 가정한다. 어떤 하나의 핀이 signal 을 보낼것이라는 것을 기대하고 있는것이다.
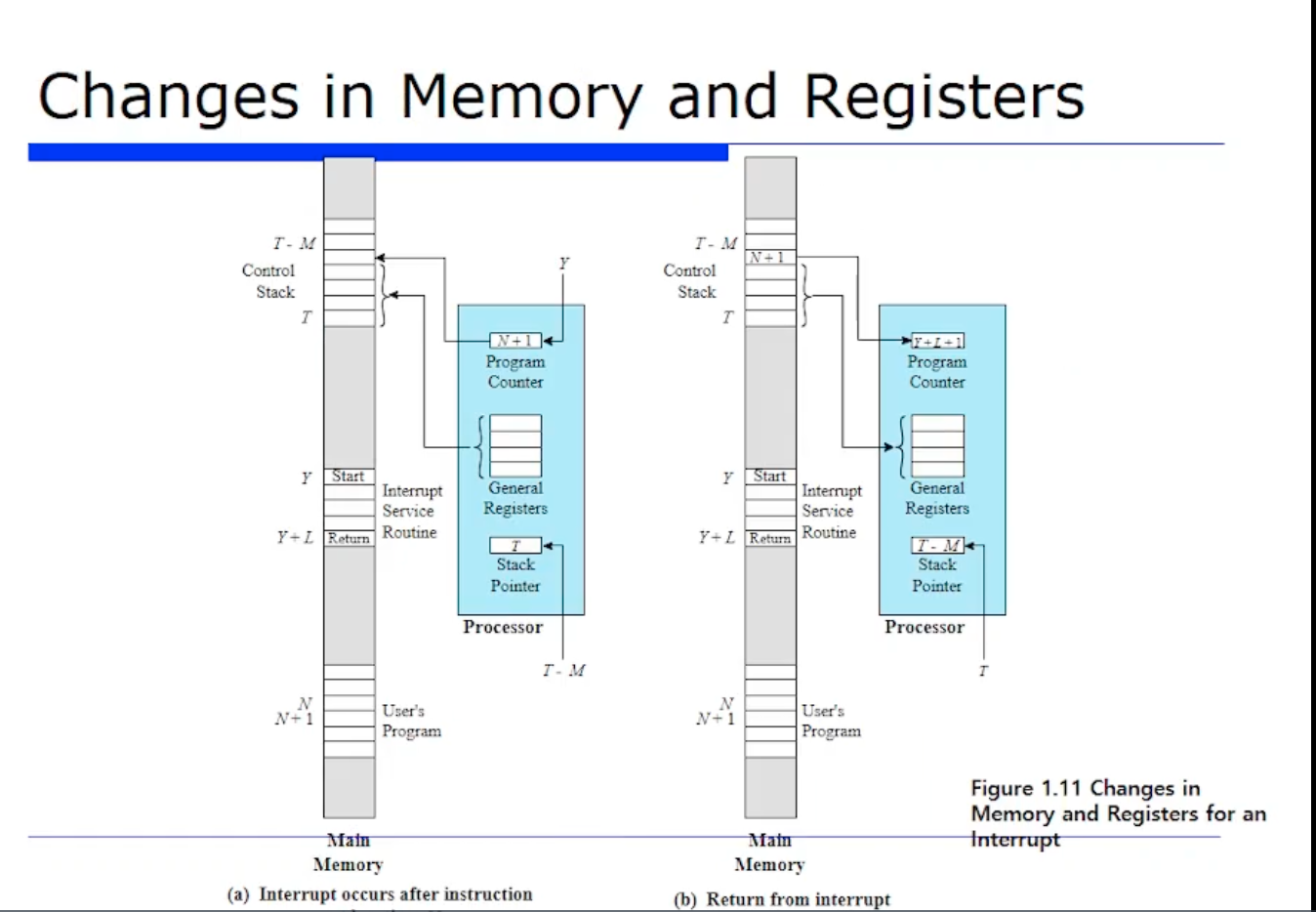
위 그림의 왼쪽 그림은 N번째 위치에서 명령어를 수행한후에 interrput 가 걸렸을때의 스냅샷(특정 시점)을 보여주고 있는것이다.
반대로 오른쪽 그림은 interrput 핸들러를 다 마치고나서 interrput 로 부터 리턴됐을때의 메모리의 스냅샷을 보여주고 있는것이다.
그래서 CPU 의 레지스터와 메모리, 즉 machine state 가 어떻게 변경되는지를 보여주는 그림이다.
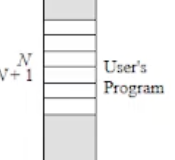
한번 왼쪽먼저 구성요소를 보자. 메모리이니까 사용자 프로그램(User's Program) 이 있다. 그리고 메모리 어딘가에 ISR(interrput service routine) 이 있다고하자. (Interrput Handler 라는 표현을 안쓰고 ISR 로 표현한것이다.) 그리고 또 메모리 어딘가에 스택이 있다고 해보자.
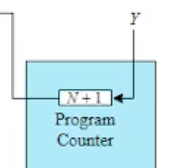
CPU 내부는 레지스터만 보이는것이다. PC 는 다음에 수행할 명령어의 주소를 저장하니까, 현재 N번째 명령어를 수행했으므로 현재 PC 안에는 N+1 이 들어있을것이다. 또 N+1 주소에 있는 명령어에 대한 수행을 실행할 경우 PC 의 값이 N+1 에서 Y 로 업데이트 될 것이다. Y 는 ISR 의 시작주소이기 때문이다.
또 PC 를 그냥 업데이트하면 안되니까, 이 N+1 은 스택에 저장될것이다. 이런 과정들을 위 그림처럼 스냅샷으로 보여주고 있다.
그리고 뿐만 아니라, PC 값 말고 범용 레지스터들도 save all 받는다. interrput 가 걸리면 스택에 싹 저장될것이다.
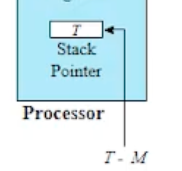
스택 포인터는 추후 배우겠지만, 스택의 TOP 을 가리키는 포인터다. 여기서 스택 포인터가 저장하는(가리키는) 주소는 T 에서 T-M 으로 업데이트 될 것이다 라는 것이다.
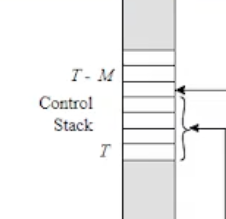
즉 데이터 크기는 M개 있는것이다.
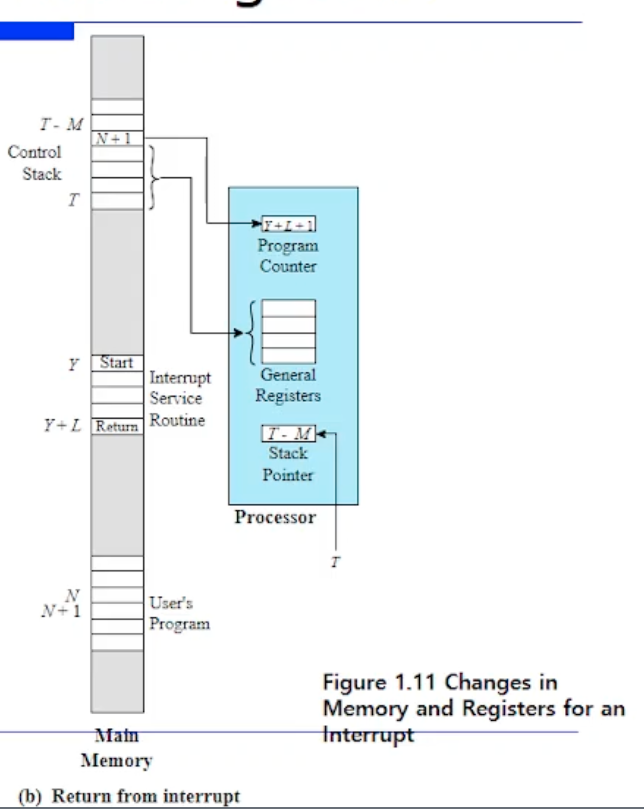
이렇게 바뀌고나서 PC 가 Y 로 바뀌었으니까 이 이후는 어떻게될까? CPU 는 여기서부터 또 계속 fetch, execution 을 할 것이다. 그러다가 execution 이 다 끝나면 핸들러의 기기가 L개의 명령어로 구현되어있다면, PC 가 이 핸들러의 끝을 만나면 Y + L + 1 로 업데이트 되어있을것이다.
그래서 리턴하고 끝나면 핸들러가 끝났으므로 스택에서 아까 잘 save 해놓았던 옛날 PC 값인 N+1 을 꺼내온다.
그러고 나머지들도 다 pop 해서 restore 한다. 그러면 스택 포인터는 다시 T 로 복귀될것이다. 그러면 이 이후에는 아무일도 없었던것처럼 N+1 부터 수행할것이다.

interrput 는 앞서 말했듯이 asynchronous interrput 라고했다. CPU 사이클과 interrput 의 발생이 시간적인 gap 이 존재하기 때문에 비동기적인 것이다. 그리고 보통은 외부의 주변 I/O 디바이스들과 연관된 외부 interrput 들을 그냥 interrput 라고 표현하는 것이다.
그런데 문제는 CPU 내부에서 프로그램이 동작하다가 CPU 에 의해서 발생되는 어떤 이벤트들이 있다. 예를들어서, 현재 유저모드인데 커널모드에서만 수행할 수 있는 명령어를 수행했을때 fetch 와 exection 을 할때 denied 된다. 위반하는 것이다. 또는 유저모드가 접근하면 안되는 커널영역의 메모리에 access 하면 CPU 가 허용하지 않을것이다.
이런 사건이 발생했을 때 어떻게 해결하는가의 문제인데, 잘보면 그것도 그 이벤트에 해당하는 핸들러가 있을것이고, 디바이스들 위에 발전되었던 이 이벤트와 같은 유사한 개념으로 처리할 수 있겠다라는 것이다.
전통적으로 외부 디바이스들과 CPU 내부에서 발생하는 이벤트들로 바뀌는것이고, 이를 interrput 라고 하는것이고 얘를 exception 이라고 하는것이다.
- : 우리가 실행단계에서 CPU 가 동작하는데 어떤 숫자를 0으로 나누거나, segmentaion fault, page fault 와 같이 더 이상 진도를 못나가며 하드웨어적으로 문제가 발생하는 애러가 발생했을때 어떻게 할 것인가에 대한 것이다.
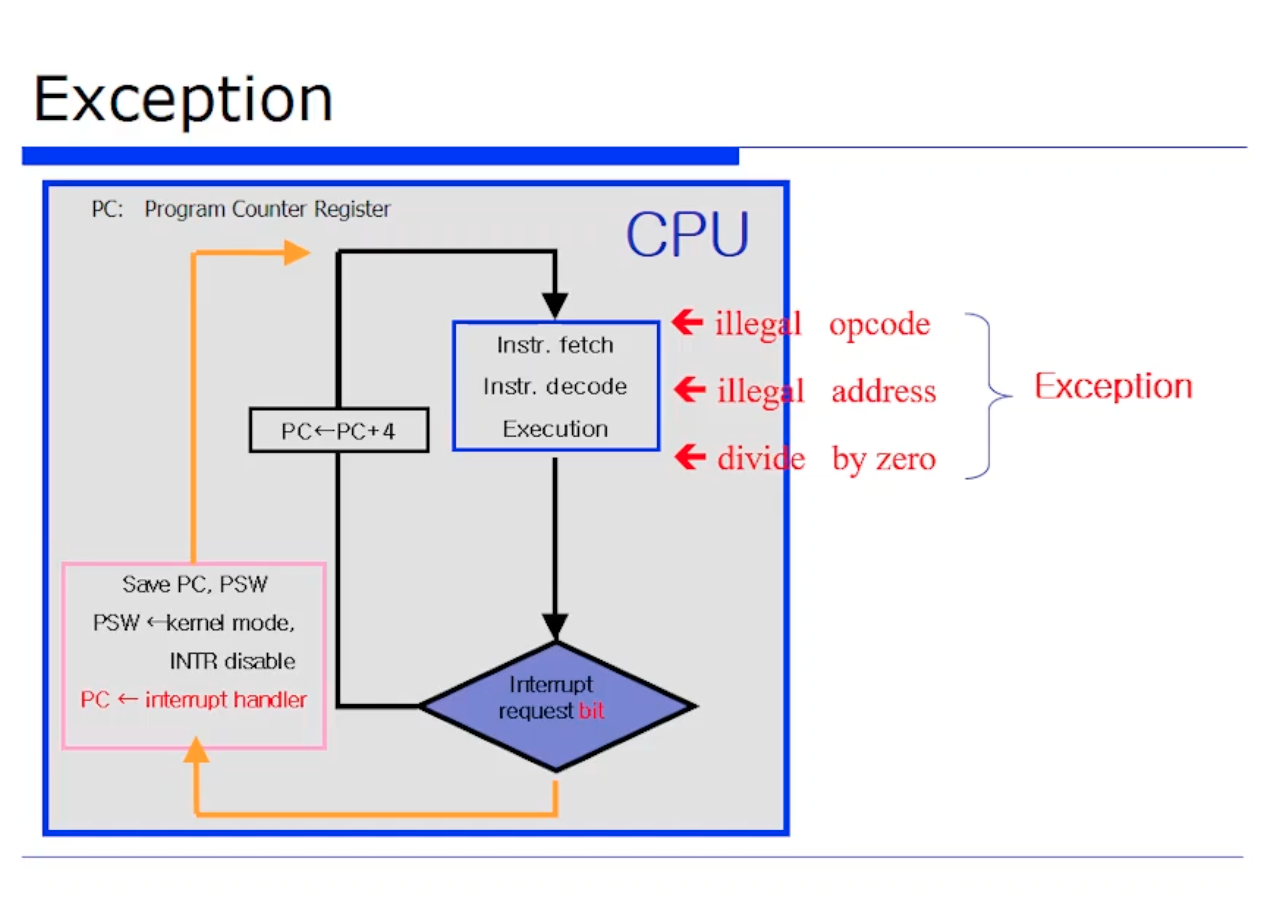
그래서 Exception 은 CPU 내부에서 발생한다. 아까 명령어가 수행되면 안되는 유저권한 내에서 Opcode 를 수행한다던지, 잘못된 메모리 참조, 또는 실행하는 단계에서 각 사이클에서 exception 이 발생할 수 있다.
exception 은 위와같은 이벤트가 발생했을 때 fetch 단계에서 뭔가 잘못됐다면 바로 핸들러로 넘어간다. 이는 이벤트가 발생했을 때와 핸들링 했을때의 시간 격차(gap) 이 없기 때문에 동기화되었다고 할 수 있다. 따라서 앞선 ppt 슬라이드에서 보았듯이 sychornous interrput 라고도 불리는 것이다.
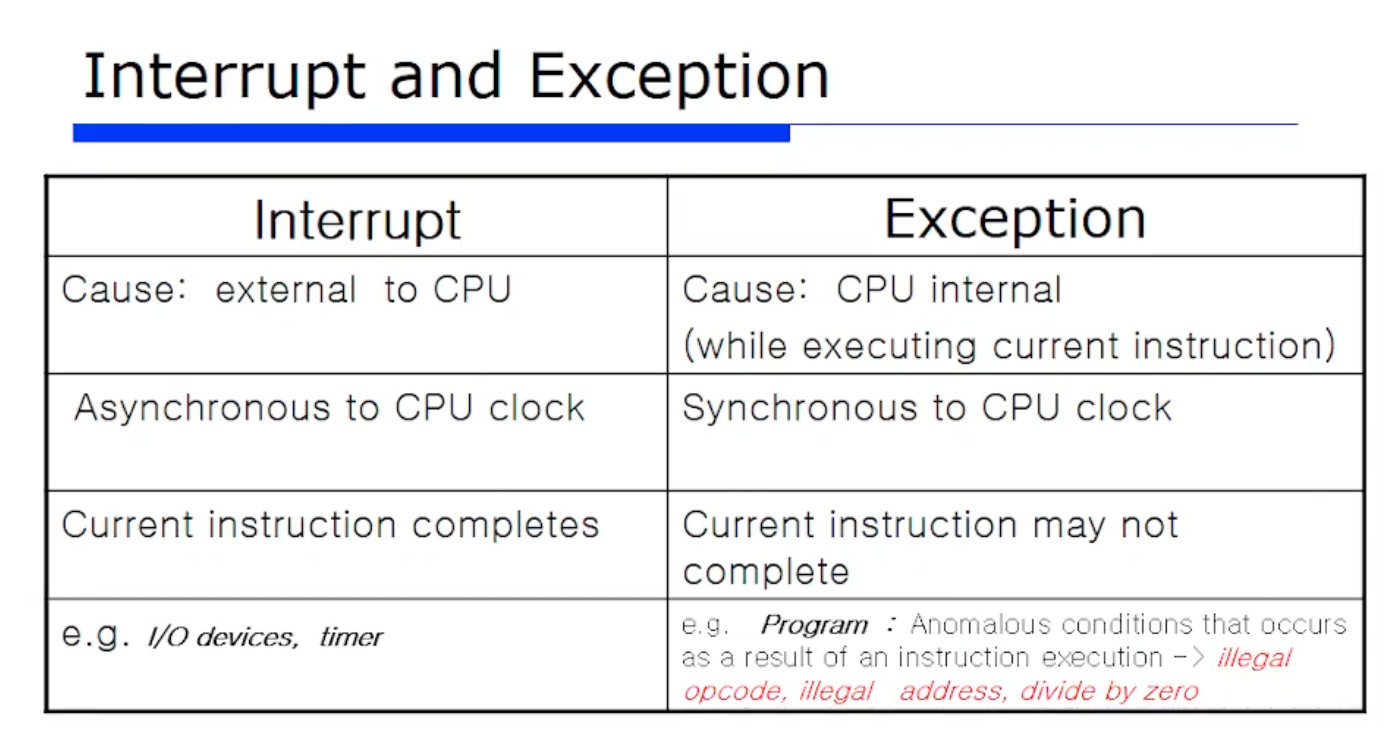
정리하면, 위와같이 interrput 와 exception 의 차이를 보여주고있다.
interrput 라는것은 협의의 interrput 용어로써 보면 CPU 외부에서 발생하는 이벤트이고, 반면 excpetion 은 CPU 내부에서 발생하는 이벤트이다.
근데 interrput 는 현재 명령어를 다 마치고나서 처리되는 것이고, exception 은 현재 명령어가 완전히 완료되지 않아도 즉각적으로, 즉시 처리가 되는것이다. 그래서 interrput 는 asynchoronous 하다고 하는것이고, exception 은 synchoronous 하다고 하는것이다.
예를들어 시스템 타이머는 CPU 외부에 있다. 따라서 시스템 타이머는 외부 interrput 로 보는것이다.
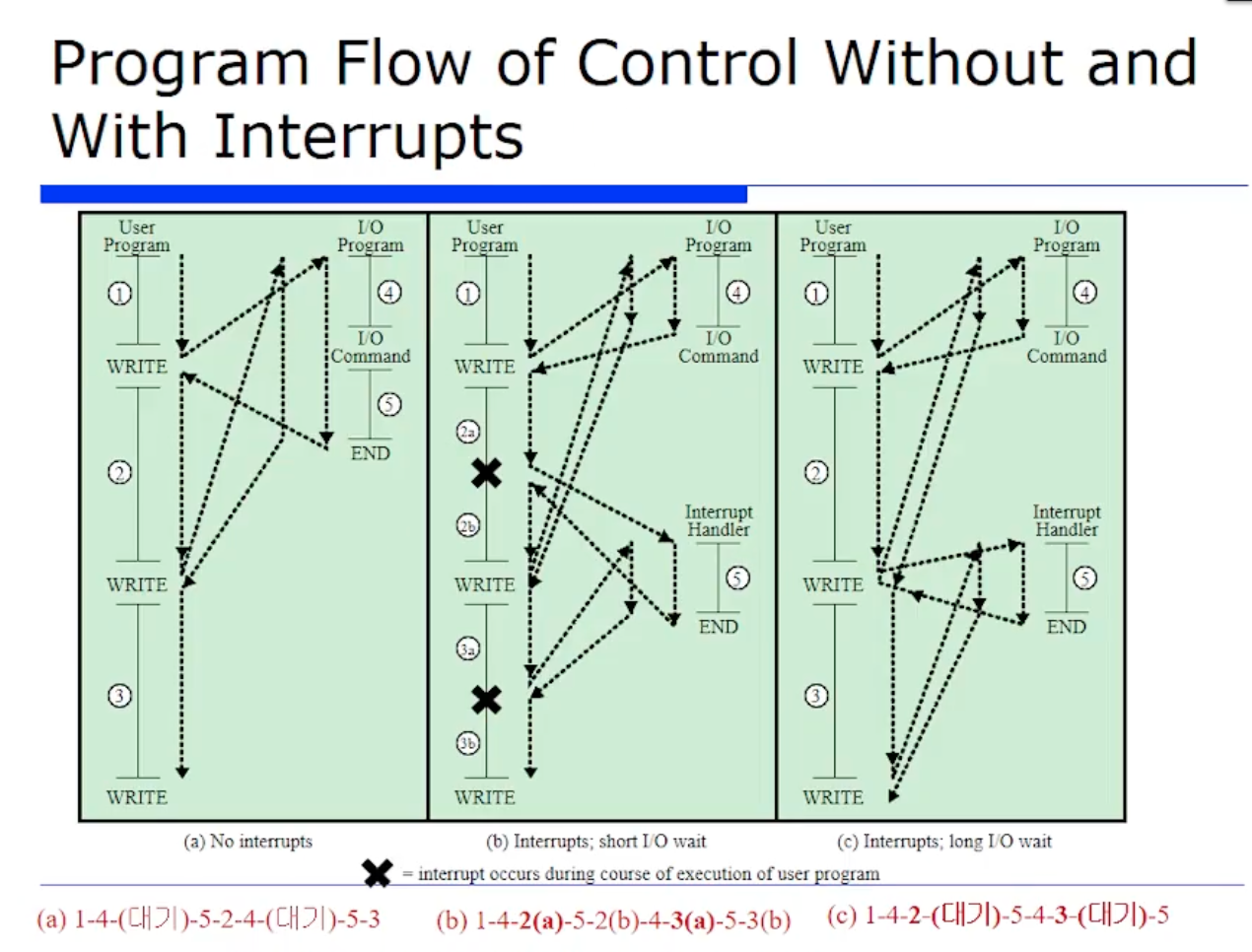
위 그림에서 (a) 는 interrput 가 없을때, (b) 와 (c) 는 interrput 가 발생했을 때의 동작 과정을 보여주는 것이다.
우선 (a) 과정인 interrput 가 없을때의 플로우를 살펴보자. User Program, 즉 main 함수부터 시작한다고 해보자. CPU 가 순차적으로 쭉 수행하다가 WRITE 라는 함수를 만났다고하자. (WRITE는 printer 라고 가정하자!) WRITE 를 통해서 들어오면, I/O 다바이스의 게시하기 위한 작업을한다.
그러면 이때부터 I/O 디바이스가 명령을 받았으니까 작업을 할것이다. 또 이때 interrput 가 없으니까 CPU 는 대기할 수 밖에 없다.
.
