Word2Vec
개념
희소 표현 (Sparse Representation)
- 원-핫 인코딩과 같이 벡터 또는 행렬의 값이 대부분이 0으로 표현되는 방법
Ex) word = [0, 0, 0, 1, 0, ... , 0] - 단점: 각 단어 벡터간 유의미한 유사성을 표현할 수 없음
분산 표현 (Distributed Representation)
-
단어의 의미를 다차원 공간에 벡터화하는 방법
-
기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법
이 가정은 '비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다' 라는 가정 -
워드 임베딩: 분산 표현을 이용하여 단어 간 의미적 유사성을 벡터화하는 작업
Example
-
강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 해당 내용을 가진 텍스트의 단어들을 벡터화한다면 해당 단어 벡터들은 유사한 벡터값을 가짐
-
분산 표현은 분포 가설을 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현
-
표현된 벡터들은 원-핫 벡터처럼 벡터의 차원이 단어 집합(vocabulary)의 크기일 필요가 없으므로, 벡터의 차원이 상대적으로 저차원으로 줄어듬
-
갖고 있는 텍스트 데이터에 단어가 10,000개 있고 인덱스는 0부터 시작하며 강아지란 단어의 인덱스는 4였다면 강아지란 단어를 표현하는 원-핫 벡터는 다음과 같이 1이란 값 뒤에 9,995개의 0의 값을 가지는 벡터가 됨
Ex) 강아지 = [0, 0, 0, 0, 1, 0, 0, 0, ... 중략 ... , 0] -
분산 표현으로 임베딩 된 벡터는 굳이 벡터 차원이 단어 집합의 크기가 될 필요가 없으므로 강아지란 단어를 표현하기 위해 사용자가 설정한 차원의 수를 가지는 벡터가 되며 각 차원의 값은 실수값을 가짐
Ex) 강아지 = [0.2, 0.3, 0.5, 0.7, 0.2, ... 중략 ... , 0.2] -
희소 표현이 고차원에 각 차원이 분리된 표현 방법이었다면, 분산 표현은 저차원에 단어의 의미를 여러 차원에다가 분산 하여 표현하며 단어 벡터 간 유의미한 유사도를 계산할 수 있음 (대표적인 학습방법: Word2Vec)
CBOW (Continuous Bag of Words)
-
주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
-
이해를 위해 간소화 된 예시로 설명
예문 : "The fat cat sat on the mat"
-
['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측하는 것은 CBOW가 하는 일
-
중심 단어(center word): 예측해야하는 단어 (sat)
-
주변 단어(context word): 예측에 사용되는 단어 (['The', 'fat', 'cat', 'on', 'the', 'mat'])
-
윈도우(window): 중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정하는 범위
예를 들어 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 입력으로 사용합니다. -
윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n
데이터 셋 (Dataset)
- 슬라이딩 윈도우(sliding window): 윈도우 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는 방법
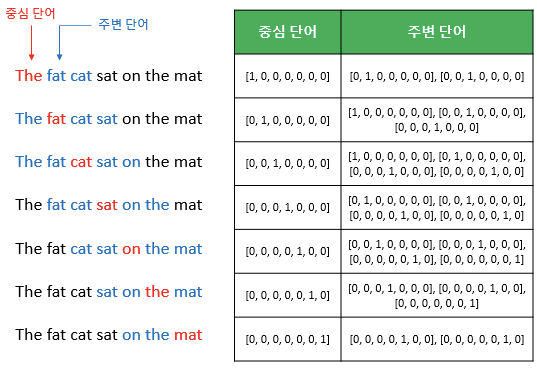
-
위 그림에서 좌측의 중심 단어와 주변 단어의 변화는 윈도우 크기가 2일때, 슬라이딩 윈도우가 어떤 식으로 이루어지면서 데이터 셋을 만드는지 보여줌
-
Word2Vec에서 입력은 모두 원-핫 벡터가 되어야 하며 우측 그림은 중심 단어와 주변 단어를 어떻게 선택했을 때에 따라서 각각 어떤 원-핫 벡터가 되는지를 보여주고, 위 그림은 CBOW를 위한 전체 데이터 셋을 보여줌
인공신경망
- CBOW의 인공 신경망을 간단히 도식화하면 다음과 같음
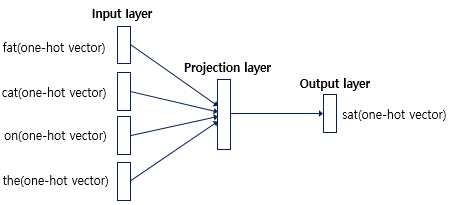
-
입력층(Input layer): 입력으로서 앞, 뒤로 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들의 원-핫 벡터가 들어감
-
출력층(Output layer): 예측하고자 하는 중간 단어의 원-핫 벡터가 레이블로서 필요
-
Word2Vec은 은닉층이 다수인 딥 러닝(deep learning) 모델이 아니라 은닉층이 1개인 얕은 신경망(shallow neural network)
-
Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담당하는 층으로 투사층(projection layer)이라고 부르기도 함 (단순히 행렬연산을 통한 선형변환에 가까움)
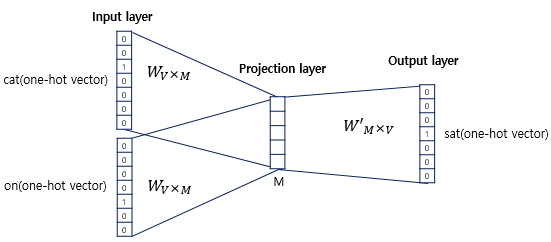
-
위 그림에서 투사층의 크기가 M이며 CBOW에서 임베딩하고 난 벡터의 차원이 됨
위의 그림에서 투사층의 크기는 M=5이므로 CBOW를 수행하고나서 얻는 각 단어의 임베딩 벡터의 차원은 5가 될 것이다. -
입력층과 투사층 사이의 가중치 W는 V × M 행렬이며, 투사층에서 출력층사이의 가중치 W'는 M × V 행렬이고, V는 단어 집합의 크기를 의미
주의할 점은 이 두 행렬은 동일한 행렬을 전치(transpose)한 것이 아니라, 서로 다른 행렬이라는 점이며 인공 신경망의 훈련 전에 이 가중치 행렬 W와 W'는 랜덤 값을 가지게 된다. -
CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W'를 학습해가는 구조
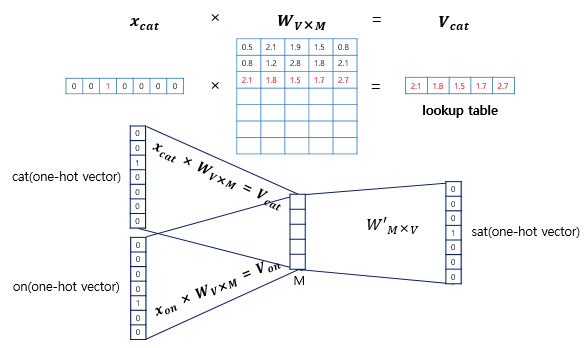
-
입력으로 들어오는 주변 단어인 원-핫 벡터 x와 가중치 W행렬의 곱은 위의 그림과 같음
-
i번째 인덱스에 1이라는 값을 가지고 그 외의 0의 값을 가지는 입력 벡터와 가중치 W 행렬의 곱은 W행렬의 i번째 행을 그대로 읽어오는 것과(lookup) 동일하며 이 작업을 룩업 테이블(lookup table)이라고 함
-
CBOW의 목적은 W와 W'를 잘 훈련시키는 것인데 그 이유가 lookup해온 W의 각 행벡터가 Word2Vec 학습 후에는 각 단어의 M차원의 임베딩 벡터로 간주되기 때문
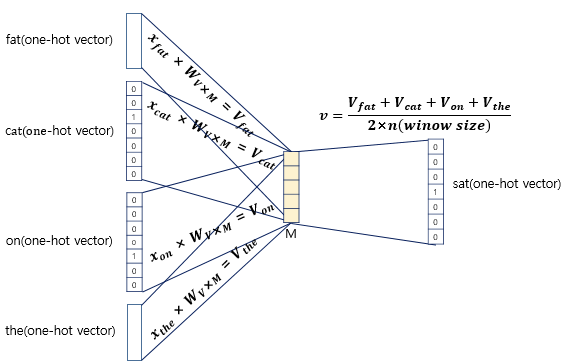
-
주변 단어인 원-핫 벡터에 대해서 가중치 W가 곱해서 생겨진 결과 벡터들은 투사층에서 만나 이 벡터들의 평균인 벡터를 구하게 됨
-
윈도우 크기 n=2라면, 입력 벡터의 총 개수는 2n이므로 중간 단어를 예측하기 위해서는 총 4개가 입력 벡터로 사용되고 평균을 구할 때는 4개의 결과 벡터에 대해서 평균을 구하게 됨
-
투사층에서 벡터의 평균을 구하는 부분은 CBOW가 Skip-Gram과 다른 차이점임
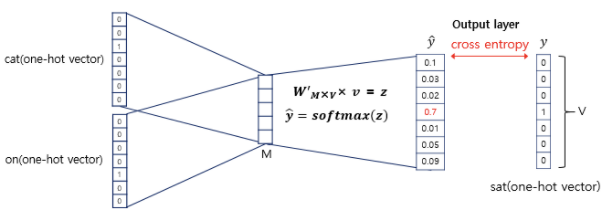
-
구해진 평균 벡터는 두번째 가중치 행렬 W'와 곱해지며 곱셈의 결과로는 원-핫 벡터들과 차원이 V로 동일한 벡터가 나옴
만약 입력 벡터의 차원이 7이었다면 여기서 나오는 벡터도 마찬가지이다. -
이 벡터에 소프트맥스(softmax) 함수를 지나면 벡터의 각 원소들의 값은 0과 1사이의 실수로, 총 합은 1이 되며 다중 클래스 분류 문제를 위한 스코어 벡터(score vector) 됨
j번째 인덱스가 가진 0과 1사이의 값은 j번째 단어가 중심 단어일 확률을 나타낸다. -
스코어 벡터의 값은 레이블에 해당하는 벡터인 중심 단어 원-핫 벡터의 값에 가까워져야 함
-
스코어 벡터를 ŷ라고 하고 중심 단어의 원-핫 벡터를 y로 했을 때, 이 두 벡터값의 오차를 줄이기위해 손실 함수(loss function)로 크로스 엔트로피(cross-entropy) 함수를 사용
-
크로스 엔트로피 함수에 중심 단어인 원-핫 벡터와 스코어 벡터를 입력값으로 넣고, 이를 식으로 표현하면 다음과 같으며 아래의 식에서 V는 단어 집합의 크기
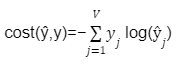
- 역전파(Back Propagation)를 수행하면 W와 W'가 학습이 되는데, 학습이 다 되었다면 M차원의 크기를 갖는 W의 행렬의 행을 각 단어의 임베딩 벡터로 사용하거나 W와 W' 행렬 두 가지 모두를 가지고 임베딩 벡터를 사용하기도 함
Skip-gram
- 중간에 있는 단어들을 입력으로 주변 단어들을 예측하는 방법
데이터 셋 (Dataset)
- 윈도우 크기가 2일 때, 데이터셋은 다음과 같이 구성 됨
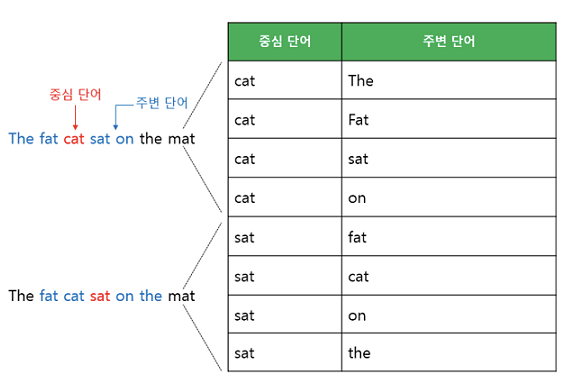
인공신경망
- 인공 신경망을 도식화해보면 아래와 같음
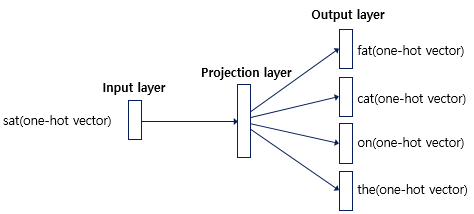
- 중심 단어에 대해서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없으며 여러 논문에서 성능 비교를 진행했을 때 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있음
Negative Sampling
Concept
-
Word2Vec의 출력층에서는 소프트맥스 함수를 지난 단어 집합 크기의 벡터와 실제값인 원-핫 벡터와의 오차를 구하고 이로부터 임베딩 테이블에 있는 모든 단어에 대한 임베딩 벡터 값을 업데이트함
-
단어 집합의 크기가 수만 이상에 달한다면 이 작업은 굉장히 무거운 작업이므로, Word2Vec은 학습하기에 무거운 모델이 됨
-
Word2Vec은 역전파 과정에서 모든 단어의 임베딩 벡터값의 업데이트를 수행하는데 현재 집중하고 있는 중심 단어와 주변 단어가 '강아지'와 '고양이', '귀여운'과 같은 단어라면 이 단어들과 별 연관 관계가 없는 '돈가스'나 '컴퓨터'와 같은 수많은 단어의 임베딩 벡터값까지 업데이트하는 것은 비효율적
-
네거티브 샘플링은 Word2Vec이 학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법
Example
-
현재 집중하고 있는 주변 단어가 '고양이', '귀여운'이라고 가정
-
'돈가스', '컴퓨터', '회의실'과 같은 단어 집합에서 무작위로 선택된 주변 단어가 아닌 단어들을 일부 가져옴
-
하나의 중심 단어에 대해서 전체 단어 집합보다 훨씬 작은 단어 집합을 만들어놓고 마지막 단계를 이진 분류 문제로 변환
-
주변 단어들을 긍정(positive), 랜덤으로 샘플링 된 단어들을 부정(negative)으로 레이블링하면 이진 분류 문제를 위한 데이터셋이 됨
-
기존의 단어 집합의 크기만큼의 선택지를 두고 다중 클래스 분류 문제를 풀던 Word2Vec보다 훨씬 연산량에서 효율적
SGNS (Skip-Gram with Negative Sampling)
- 앞서의 Skip-gram은 중심 단어로부터 주변 단어를 예측하는 모델
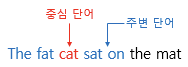
-
위와 같은 문장이 있다고 한다면, Skip-gram은 중심 단어 cat으로부터 주변 단어 The, fat, sat, on을 예측
-
기존의 Skip-gram 모델을 일종의 주황 박스로 생각해본다면, 아래의 그림과 같이 입력은 중심 단어, 모델의 예측은 주변 단어인 구조

-
네거티브 샘플링을 사용하는 SGNS(Skip-Gram with Negative Sampling, SGNS)는 다른 접근 방식
-
SGNS는 다음과 같이 중심 단어와 주변 단어가 모두 입력이 되고, 이 두 단어가 실제로 윈도우 크기 내에 존재하는 이웃 관계인지 그 확률을 예측

- 기존의 Skip-gram 데이터셋을 SGNS의 데이터셋으로 바꾸는 과정은 다음과 같음
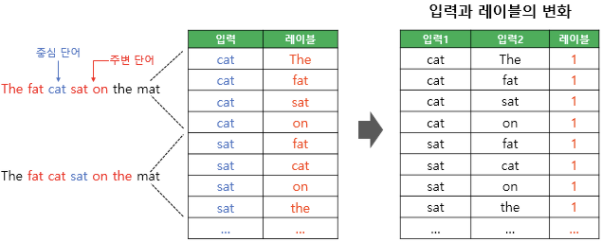
-
위의 그림에서 좌측의 테이블은 기존의 Skip-gram을 학습하기 위한 데이터셋이며 SGNS를 학습하고 싶다면, 이 데이터셋을 우측의 테이블과 같이 수정해야 함
-
기존의 Skip-gram 데이터셋에서 중심 단어와 주변 단어를 각각 입력1, 입력2로 두고 이 둘은 실제로 윈도우 크기 내에서 이웃 관계였므로 레이블은 1로 함
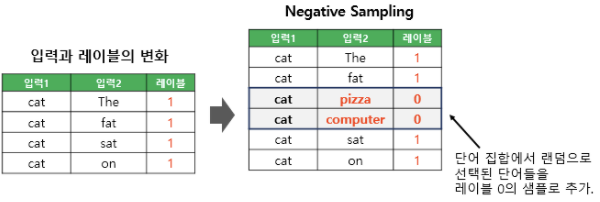
-
실제로는 입력1(중심 단어)와 주변 단어 관계가 아닌 단어들을 입력2로 삼기 위해서 단어 집합에서 랜덤으로 선택한 단어들을 입력2로 하고, 레이블을 0으로 함
-
다음으로 두 개의 임베딩 테이블을 준비하며 두 임베딩 테이블은 훈련 데이터의 단어 집합의 크기를 가지므로 크기가 같음
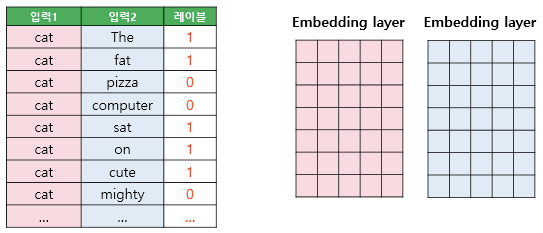
- 두 테이블 중 하나는 입력 1인 중심 단어의 테이블 룩업을 위한 임베딩 테이블이고, 하나는 입력 2인 주변 단어의 테이블 룩업을 위한 임베딩 테이블
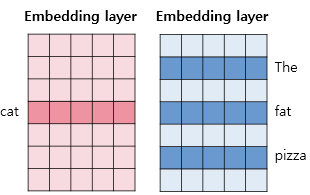
- 각 단어는 각 임베딩 테이블을 테이블 룩업하여 임베딩 벡터로 변환 됨
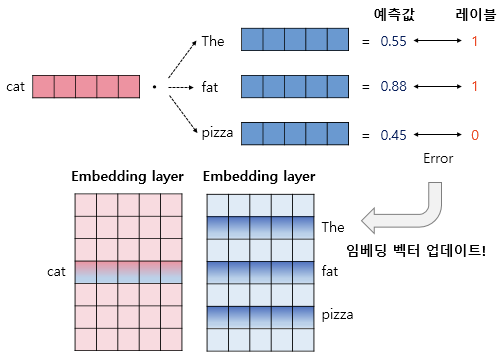
-
중심 단어와 주변 단어의 내적값을 이 모델의 예측값으로 하고, 레이블과의 오차로부터 역전파하여 중심 단어와 주변 단어의 임베딩 벡터값을 업데이트
-
학습 후에는 좌측의 임베딩 행렬을 임베딩 벡터로 사용할 수도 있고, 두 행렬을 더한 후 사용하거나 두 행렬을 연결(concatenate)해서 사용할 수 있음
Feedforward Neural Net Language Model (NNLM)
- input, projection, hidden, output layer로 구성
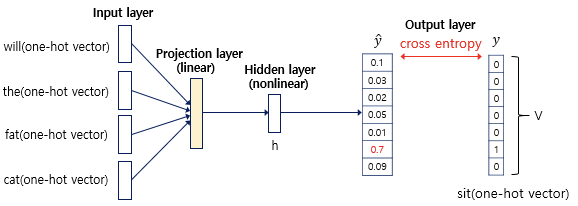
input layer
-
N 개의 이전 단어들이 1-of-V coding(one-hot-vector)으로 인코딩 됨 (V 는 전체 단어의 수)
-
보통 N = 10 으로 지정
-
projection matrix를 통해 input이 projection layer로 전달
projection layer
-
N × D dimensionality
-
상대적으로 저렴한 비용의 연산이다.
-
D = 500 ~ 2000
hidden layer
-
projection layer와 hidden layer 사이의 연산에서 상대적으로 큰 비용이 발생
-
hidden layer size H = 500 ~ 1000
output layer
-
V 차원의 결과를 제공
-
계산 비용 computational complexity Q = N × D + N × D × H + H × V
-
가장 큰 비용을 차지하는 부분 : H × V
-
hierarchical softmax 를 사용하면 비용이 log(V) 까지 줄어들 수 있음
NNLM vs Word2Vec
- NNLM은 단어 벡터 간 유사도를 구할 수 있도록 워드 임베딩의 개념을 도입하였고, 워드 임베딩 자체에 집중하여 NNLM의 느린 학습 속도와 정확도를 개선하여 탄생한 것이 Word2Vec
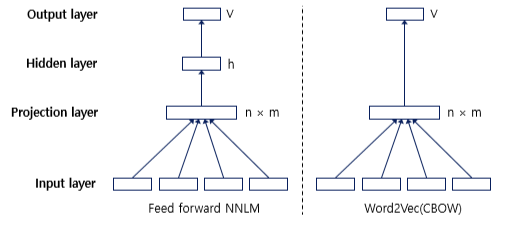
차이점
-
예측하는 대상이 달라짐
-
NNLM은 다음 단어를 예측하는 언어 모델이 목적이므로 다음 단어를 예측하지만, Word2Vec(CBOW)은 워드 임베딩 자체가 목적이므로 다음 단어가 아닌 중심 단어를 예측하게 하여 학습
-
중심 단어를 예측하므로 NNLM이 예측 단어의 이전 단어들만을 참고하였던 것과는 달리, Word2Vec은 예측 단어의 전, 후 단어들을 모두 참고
-
-
구조 달라짐
-
Word2Vec은 우선 NNLM에 존재하던 활성화 함수가 있는 은닉층을 제거
-
투사층 다음에 바로 출력층으로 연결되는 구조
-
-
학습 속도
-
Word2Vec이 NNLM보다 학습 속도에서 강점을 가지는 이유는 은닉층을 제거뿐만 아니라 추가적으로 사용되는 기법들 덕분이기도 함
-
대표적인 기법으로 계층적 소프트맥스(hierarchical softmax)와 네거티브 샘플링(negative sampling)이 있음
-
입력층에서 투사층, 투사층에서 은닉층, 은닉층에서 출력층으로 향하며 발생하는 NNLM의 연산량
NNLM : (n×m)+(n×m×h)+(h×V)
-
추가적인 기법들을 사용하였을 때 Word2Vec은 출력층에서의 연산에서 V를 log(V)로 바꿀 수 있고, 이에 따른 Word2Vec의 연산량은 아래와 같으며 NNLM보다 훨씬 빠른 학습 속도를 가짐
Word2Vec : (n×m)+(m×log(V))
-
Reference
https://wikidocs.net/69141 (개념)
https://lazyer.tistory.com/10 (개념)
https://arxiv.org/abs/1411.2738 (개념논문)
https://cpm0722.github.io/paper-review/efficient-estimation-of-word-representations-in-vector-space (논문리뷰)
https://yjjo.tistory.com/14?category=876638 (개념/ hierarchical softmax, negative)
