Song2Vec
Background
-
음악 애호가들의 행동은 지난 수십 년 동안 음악 산업의 발전과 함께 변화해 옴
-
이전에 콤팩트 디스크로 음악을 샀지만 지금은 음악 스트리밍 서비스가 더 선호되고 있으며 플랫폼들이 제공하는 편리함 때문에 사용자는 음반 매장에 가지 않고도 자신이 좋아하는 노래를 바로 검색할 수 있음
-
사용자가 사용 가능한 모든 노래를 확인하고 재생 목록을 수동으로 만드는 시간이 비효율적일 수 있으므로 관련 노래를 빨리 찾을 수 있도록 추천하는 시스템이 구축 됨
-
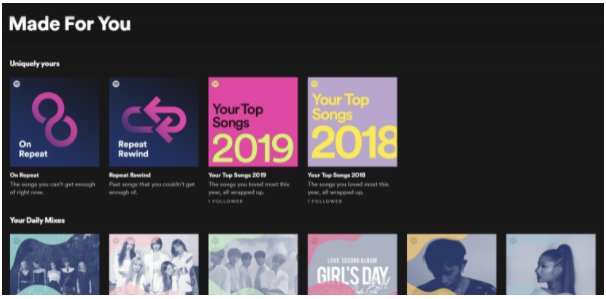
다음과 같은 Spotify의 "Made For You" 기능을 예로 들 수 있음
-
이런 개인화된 플레이리스트들은 서로 잘 어울리는 비슷한 노래들을 그룹화해서 추천 함
-
이는 사용자의 활동(좋음, 재생목록 이력, 듣기 이력)에 기초하여 여러 추천 알고리즘을 결합하여 이루어짐
-
본 포스팅에서는 Word2Vec 모델을 이용한 신경망 접근법을 이용해 곡 임베딩 추출법, 곡 추천 생성법, 퍼포먼스 평가법 등을 시연
Word2Vec이란?
-
토마스 미콜로프가 2013년 구글에서 개발한 이 기술은 얕은 신경망을 이용해 여러 NLP(Natural Language Processing) 사례에서 단어 임베딩을 하는 가장 흔한 기법 중 하나
-
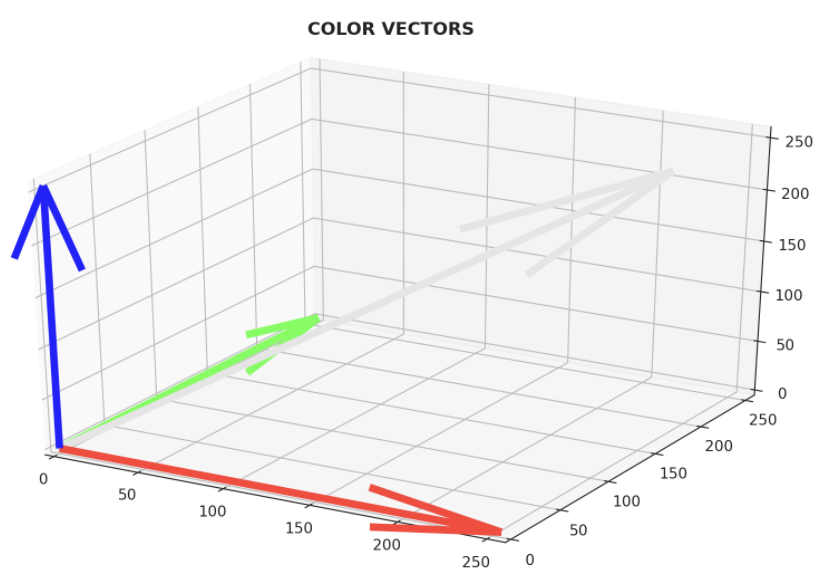
단어 임베딩은 단지 단어를 숫자로 표현하는 방법으로 색상이 RGB 값으로 표현되는 것으로 비유할 수 있으며
이 값들의 집합은 벡터라고 불림
예를 들어 "검은색"은 (0,0,0), "흰색"은 (25,255,255)로 픽셀 강도 값으로 연관시킬 수 있다.
-
실제로 워드 임베딩 방식은 전자상거래 웹사이트의 어떤 제품이나 유튜브의 어떤 동영상, 넷플릭스의 영화를 벡터로 연결하는 다른 아이템 임베딩으로 일반화할 수 있으며 물론 이 경우 노래도 벡터가 될 수 있음
-
Word2Vec이 단어의 벡터 표현을 학습하기 위해 활용하는 문장의 속성은 텍스트의 순차적 성격임
gives Spotify millions you access music service to digital a that is of songs.
-
위의 문장은 문장에 순서가 없기 때문에 텍스트를 이해하기가 어려움
-
어떤 자연어에서도 말의 순서가 결정적이므로 이 속성은 순차적 성격을 가진 다른 데이터에도 구현될 수 있음
-
음악 스트리밍 서비스의 노래 재생 목록이 순차적 속성이 있는 데이터 중 하나이며 다음 이미지는 Spotify의 재생목록의 예로서, 각 재생목록에는 일련의 노래가 포함되어 있음
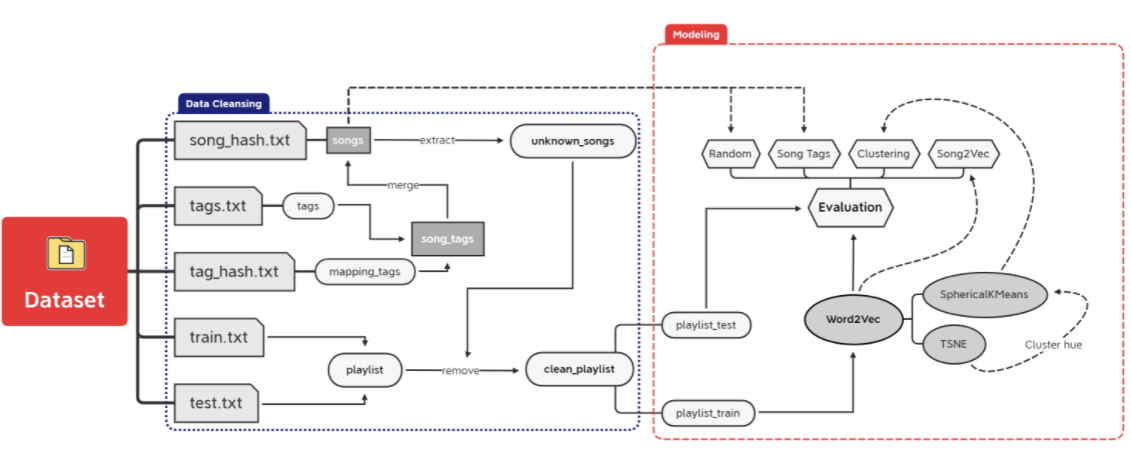
- 데이터 정리 및 모델링 프로세스가 상당히 복잡하므로 전반적인 워크플로우를 이해할 수 있도록 시각화 제시
라이브러리 가져오기
-
pandas: 데이터 분석
-
numpy: 데이터 계산
-
matplotlib, seaborn: 데이터 시각화
-
gensim: 데이터 모델링 (Word2vec)
-
sklearn, spherecluster: 다른 학습 알고리즘
# Data Analysis
import pandas as pd
import numpy as np
# Visualization
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d
import Axes3D
import seaborn as sns
plt.style.use('seaborn')
sns.set_style("whitegrid")
# Modelling
from gensim.models import Word2Vec
from gensim.models.callbacks import CallbackAny2Vec
from spherecluster import SphericalKMeans
from sklearn.model_selection import train_test_split
from sklearn.manifold import TSNE
from scipy import stats
# Additional
import math
import random
import itertools
import multiprocessing
from tqdm import tqdm
from time import time
import logging
import pickle데이터 클렌징
-
코넬 대학의 슈오 첸이 수집한 사람이 만든 음악 재생목록은 이 곡을 임베딩하는데 사용 됨
-
이 데이터 집합에는 2010년 12월부터 2011년 5월까지 Yes.com의 미국 라디오 재생 목록과 Last.fm의 노래 태그가 포함되어 있음
-
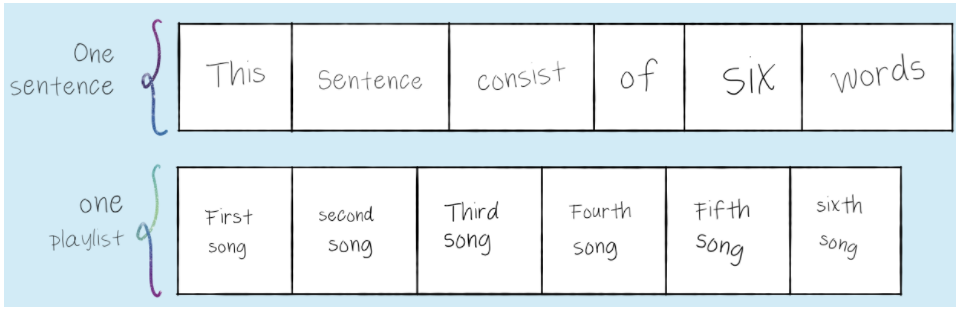
각 재생목록은 문장으로 처리되고 재생목록의 각 곡은 한 단어로 처리 됨
-
원시 데이터는 다음과 같이 5개의 개별 txt 파일로 구성 됨
-
song_hash.txt: 노래를 대표하는 song_id(int)에 title, artist 이름 매핑
-
tags.txt: 소셜 태그, 노래를 대표하는 song_id(int)
-
tag_hash.txt: 정수 ID에 태그 이름 매핑
-
train.txt, test.txt: 노래를 대표하는 song_id(int)를 사용한 재생 목록
-
노래
- 각 노래에는 정확히 하나의 제목과 아티스트 이름에 매핑되는 자체 song_id가 있으며 song_hash.txt에 75252개의 고유한 노래가 있음
songs = pd.read_csv(FOLDER_PATH+"song_hash.txt", sep = '\t', header = None,
names = ['song_id', 'title', 'artist'], index_col = 0)
songs['artist - title'] = songs['artist'] + " - " + songs['title']
songs
#> title ... artist - title
#> song_id ...
#> 0 Gucci Time (w\/ Swizz Beatz) ... Gucci Mane - Gucci Time (w\/ Swizz Beatz)
#> 1 Aston Martin Music (w\/ Drake & Chrisette Mich... ... Rick Ross - Aston Martin Music (w\/ Drake & Ch...
#> 2 Get Back Up (w\/ Chris Brown) ... T.I. - Get Back Up (w\/ Chris Brown)
#> 3 Hot Toddy (w\/ Jay-Z & Ester Dean) ... Usher - Hot Toddy (w\/ Jay-Z & Ester Dean)
#> 4 Whip My Hair ... Willow - Whip My Hair
#> ... ... ... ...
#> 75257 Dearest (I'm So Sorry) ... Picture Me Broken - Dearest (I'm So Sorry)
#> 75258 USA Today ... Alan Jackson - USA Today
#> 75259 Superstar ... Raul Malo - Superstar
#> 75260 Romancin' The Blues ... Giacomo Gates - Romancin' The Blues
#> 75261 Inner Change ... The Jazzmasters - Inner Change
#>
#> [75262 rows x 3 columns]태그
- 각 노래에는 tags.txt에 존재하는 여러 태그가 있으며 매핑은 tag_hash.txt에서 제공 됨
def readTXT(filename, start_line=0, sep=None):
with open(FOLDER_PATH+filename) as file:
return [line.rstrip().split(sep) for line in file.readlines()[start_line:]]
tags = readTXT("tags.txt")
tags[7:12]
#> [['49', '65', '72', '141', '197'], ['11', '35', '154'], ['#'], ['#'], ['#']]- 노래에 태그가 없으면 위와 같이 '#'으로 표시되므로 "unknown" 문자열로 바꿈
mapping_tags = dict(readTXT("tag_hash.txt", sep = ', '))
mapping_tags['#'] = "unknown"- song_tags 데이터 프레임은 이전 노래와 결합 및 병합 됨
song_tags = pd.DataFrame({'tag_names': [list(map(lambda x: mapping_tags.get(x), t)) for t in tags]})
song_tags.index.name = 'song_id'
songs = pd.merge(left = songs, right = song_tags, how = 'left',
left_index = True, right_index = True)
songs.index = songs.index.astype('str')
songs.head()
#> title ... tag_names
#> song_id ...
#> 0 Gucci Time (w\/ Swizz Beatz) ... [wjlb-fm]
#> 1 Aston Martin Music (w\/ Drake & Chrisette Mich... ... [chill, rnb, loved, hip hop, rap, soft, wjlb-f...
#> 2 Get Back Up (w\/ Chris Brown) ... [wjlb-fm]
#> 3 Hot Toddy (w\/ Jay-Z & Ester Dean) ... [pop, hip-hop]
#> 4 Whip My Hair ... [pop, american, dance, rnb, hip-hop, hip hop, ...
#>
#> [5 rows x 4 columns]알 수 없는 노래
- 알 수 없는 노래는 대시(-) 문자로 표시된 아티스트나 제목이 없는 노래로 정의되며 제거 함.
unknown_songs = songs[(songs['artist'] == '-') | (songs['title'] == '-')]
songs.drop(unknown_songs.index, inplace = True)재생 목록
- 재생 목록은 train.txt 및 test.txt의 노래 목록(song_id로 표시) 목록이며 데이터에 존재하는 재생 목록이 15910개가 존재
playlist = readTXT("train.txt", start_line = 2) + readTXT("test.txt", start_line = 2)
print(f"Playlist Count: {len(playlist)}")
#> Playlist Count: 15910- 목록에서 재생 목록은 다음과 같이 표시되며 이러한 재생 목록은 문장으로 처리되고 song_id는 단어 토큰으로 처리 됨
for i in range(0, 2):
print("-------------------------")
print(f"Playlist Idx. {i}: {len(playlist[i])} Songs")
print("-------------------------")
print(playlist[i])
#> -------------------------
#> Playlist Idx. 0: 97 Songs
#> -------------------------
#> ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35', '36', '37', '38', '39', '40', '41', '2', '42', '43', '44', '45', '46', '47', '48', '20', '49', '8', '50', '51', '52', '53', '54', '55', '56', '57', '25', '58', '59', '60', '61', '62', '3', '63', '64', '65', '66', '46', '47', '67', '2', '48', '68', '69', '70', '57', '50', '71', '72', '53', '73', '25', '74', '59', '20', '46', '75', '76', '77', '59', '20', '43']
#> -------------------------
#> Playlist Idx. 1: 205 Songs
#> -------------------------
#> ['78', '79', '80', '3', '62', '81', '14', '82', '48', '83', '84', '17', '85', '86', '87', '88', '74', '89', '90', '91', '4', '73', '62', '92', '17', '53', '59', '93', '94', '51', '50', '27', '95', '48', '96', '97', '98', '99', '100', '57', '101', '102', '25', '103', '3', '104', '105', '106', '107', '47', '108', '109', '110', '111', '112', '113', '25', '63', '62', '114', '115', '84', '116', '117', '118', '119', '120', '121', '122', '123', '50', '70', '71', '124', '17', '85', '14', '82', '48', '125', '47', '46', '72', '53', '25', '73', '4', '126', '59', '74', '20', '43', '127', '128', '129', '13', '82', '48', '130', '131', '132', '133', '134', '135', '136', '137', '59', '46', '138', '43', '20', '139', '140', '73', '57', '70', '141', '3', '1', '74', '142', '143', '144', '145', '48', '13', '25', '146', '50', '147', '126', '59', '20', '148', '149', '150', '151', '152', '56', '153', '154', '155', '156', '157', '158', '159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172', '173', '174', '175', '60', '176', '51', '177', '178', '179', '180', '181', '182', '183', '184', '185', '57', '186', '187', '188', '189', '190', '191', '46', '192', '193', '194', '195', '196', '197', '198', '25', '199', '200', '49', '201', '100', '202', '203', '204', '205', '206', '207', '32', '208', '209', '210']- 재생 목록에서 알 수 없는 노래 제거
playlist_wo_unknown = [[song_id for song_id in p if song_id not in unknown_songs.index]
for p in playlist]- 0개 또는 1개의 노래가 있는 재생 목록에서 모델이 해당 목록의 시퀀스를 캡처하지 못하므로 제거
clean_playlist = [p for p in playlist_wo_unknown if len(p) > 1]
print(f"Playlist Count After Cleansing: {len(clean_playlist)}")
#> Playlist Count After Cleansing: 15842- 재생 목록에 없는 노래 제거
unique_songs = set(itertools.chain.from_iterable(clean_playlist))
song_id_not_exist = set(songs.index) - unique_songs
songs.drop(song_id_not_exist, inplace = True)
print(f"Unique Songs After Cleansing: {songs.shape[0]}")
#> Unique Songs After Cleansing: 73448- 75262개의 고유한 노래, 15910개의 재생 목록이 데이터 클렌징을 통해 73448개의 고유한 노래, 15842개의 재생 목록이 됨
모델링
- 재생 목록은 추가 평가를 위해 재생 목록을 크기가 1000인 테스트 재생 목록과 트레인 재생 목록으로 분할
playlist_train, playlist_test = train_test_split(clean_playlist, test_size = 1000, shuffle = True, random_state = 123)Song2Vec
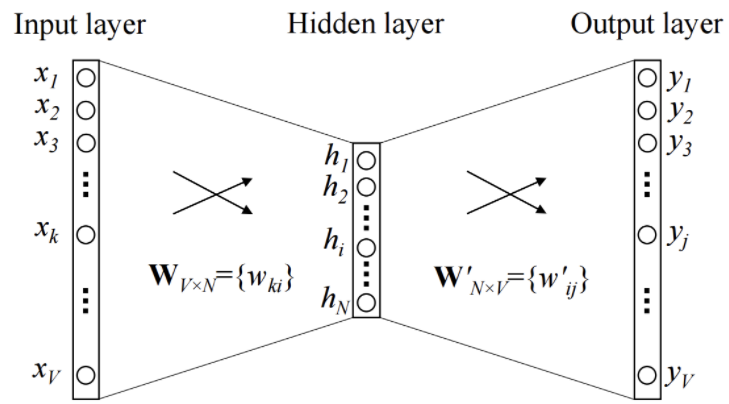
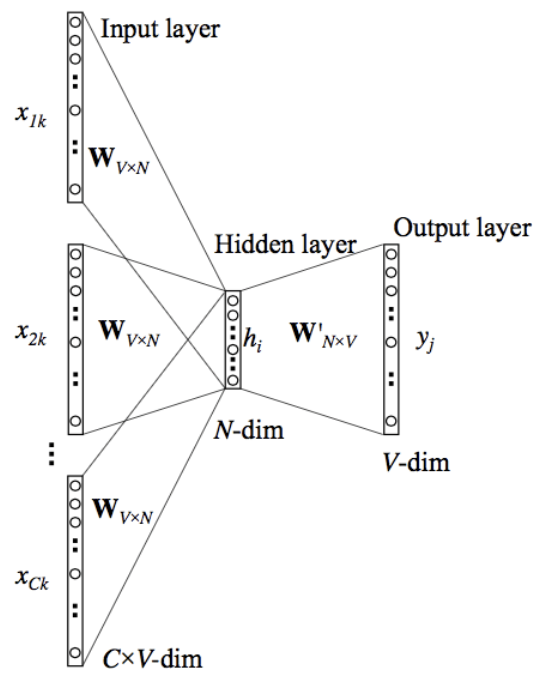
- 일반적인 Word2Vec 아키텍처
-
세부사항
-
입력 계층은 V크기의 단일 핫 인코딩 벡터
-
Wv𝗑n은 입력 x를 히든 레이어에 projection하는 weight matrix이며 이 값들은 내장된 벡터
-
히든 레이어는 활성화 기능 없이 입력의 가중 합을 다음 레이어에 복사
-
W′v𝗑n은 히든 레이어 출력을 최종 출력 레이어에 매핑하는 weight matrix
-
출력 계층은 다시 소프트맥스 활성화 기능을 가진 V길이 벡터가 됨
-
-
Word2Vec의 두 가지 접근방식은 모두 동일한 아키텍처를 사용
-
스킵그램 - 목표 단어를 지정하면 모델이 상황에 맞는 단어를 예측
-
CBOW - 문맥 단어로 목표 단어를 예측하는 것
-
-
CBOW는 더 빨리 훈련하고 빈번한 노래를 더 많이 캡처할 수 있기 때문에 대신 사용 됨
-
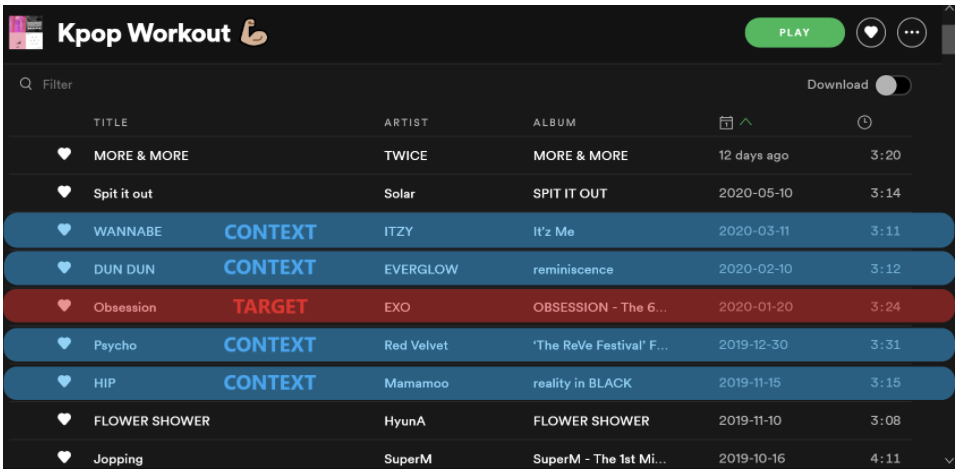
컨텍스트 곡 사이에 연주되는 타겟곡은 서로 비슷한 곡으로 추정
-
재생목록이 사용자나 특정 장르를 위한 서비스에 의해 디자인된다면 곡 임베딩은 장르에 대한 더 많은 정보를 논리적으로 통합할 것
-
CBOW의 한 에포크는 다음과 같은 단계로 세분 됨
-
생성된 교육 샘플을 입력 계층에 대한 단일 벡터 x1,x2,...,xC(컨텍스트)로 변환, 사이즈는 C×V
-
모든 벡터 x에 Wv𝗑n을 곱한 다음 내장된 벡터의 합계 또는 평균을 구함
-
히든 레이어에 W′v𝗑n을 곱하여 크기 V의 가중 합계를 구함
-
소프트맥스 함수를 적용하여 가중 합을 확률로 변환, 일반적으로 ŷ로 표시
-
출력과 각 컨텍스트 단어 사이의 오차는 다음과 같이 계산, (ŷ-y)
-
Gradient Download Optimizer를 사용하여 가중치를 다시 조정
-
출력 매트릭스의 모든 가중치가 업데이트
-
업데이트될 입력 행렬의 해당 단어 벡터만
-
-
-
소프트맥스 기능은 모든 V 단어의 확률 분포를 계산하기 위해 전체 출력 임베딩 매트릭스를 통해 스캔해야 하기 때문에 계산적으로 매우 비쌈
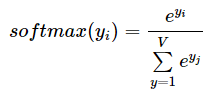
-
분모의 정규화 계수에도 V반복이 필요하며 코드로 구현하면 정규화 계수가 한 번만 계산되고 파이썬 변수로 캐시되어 알고리즘 복잡성이 O(V)가 됨
-
계산상의 비효율성 때문에 시그모이드를 이용한 네거티브 샘플링 사용
계산량은 O(K+1)이며 K는 네거티브 샘플 1은 파지티브 샘플이다. -
아래 코드는 교육 과정을 감시하기 위한 로깅 설정
logging.basicConfig(format="%(asctime)s : %(levelname)s : %(message)s", level=logging.INFO)
class Callback(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
self.training_loss = []
def on_epoch_end(self, model):
loss = model.get_latest_training_loss()
if self.epoch == 1:
current_loss = loss
else:
current_loss = loss - self.loss_previous_step
print(f"Loss after epoch {self.epoch}: {current_loss}")
self.training_loss.append(current_loss)
self.epoch += 1
self.loss_previous_step = loss트레이닝
- gensim 사용한 훈련 과정을 세 가지 단계로 구분
1단계
-
Word2Vec() 모델 파라미터 설정, 모델을 초기화하지 않은 상태로 생성
-
size: 곡 벡터의 치수
-
window: 컨텍스트와 대상 사이의 최대 거리
-
min_count: 모델에서 고려할 곡의 주파수 컷오프
-
sg = 0: CBOW 아키텍처 사용
-
negative: 음의 샘플링 데이터
-
workers: 모델을 교육하는 데 사용되는 CPU 수
-
model = Word2Vec(
size = 256,
window = 10,
min_count = 1,
sg = 0,
negative = 20,
workers = multiprocessing.cpu_count()-1)
print(model)
#> Word2Vec(vocab=0, size=256, alpha=0.025)2단계
- .build_vocab() 메서드는 재생 목록 시퀀스에서 어휘를 빌드하고 모델을 초기화하기 위해 호출 됨
logging.disable(logging.NOTSET) # enable logging
t = time()
model.build_vocab(playlist_train)
#> 2020-06-29 14:35:46,001 : INFO : collecting all words and their counts
#> 2020-06-29 14:35:46,001 : INFO : PROGRESS: at sentence #0, processed 0 words, keeping 0 word types
#> 2020-06-29 14:35:46,211 : INFO : PROGRESS: at sentence #10000, processed 1805894 words, keeping 63337 word types
#> 2020-06-29 14:35:46,338 : INFO : collected 72047 word types from a corpus of 2670082 raw words and 14842 sentences
#> 2020-06-29 14:35:46,338 : INFO : Loading a fresh vocabulary
#> 2020-06-29 14:35:46,562 : INFO : effective_min_count=1 retains 72047 unique words (100% of original 72047, drops 0)
#> 2020-06-29 14:35:46,562 : INFO : effective_min_count=1 leaves 2670082 word corpus (100% of original 2670082, drops 0)
#> 2020-06-29 14:35:46,726 : INFO : deleting the raw counts dictionary of 72047 items
#> 2020-06-29 14:35:46,728 : INFO : sample=0.001 downsamples 3 most-common words
#> 2020-06-29 14:35:46,728 : INFO : downsampling leaves estimated 2667923 word corpus (99.9% of prior 2670082)
#> 2020-06-29 14:35:46,872 : INFO : estimated required memory for 72047 words and 256 dimensions: 183575756 bytes
#> 2020-06-29 14:35:46,873 : INFO : resetting layer weights3단계
-
.train()은 모델을 훈련시킴, 여기서 로깅은 주로 각 에포크 후 손실을 모니터링하는 데 유용
-
total_examples: 고유 어휘 수(수)
-
epochs: 데이터셋을 통한 반복 횟수(재생 목록)
-
compute_loss: track model 손실
-
logging.disable(logging.INFO) # disable logging
callback = Callback() # instead, print out loss for each epoch
t = time()
model.train(playlist_train,
total_examples = model.corpus_count,
epochs = 100,
compute_loss = True,
callbacks = [callback])
model.save(MODEL_PATH+"song2vec.model")
print(model)
#> Word2Vec(vocab=72047, size=256, alpha=0.025)손실 평가
-
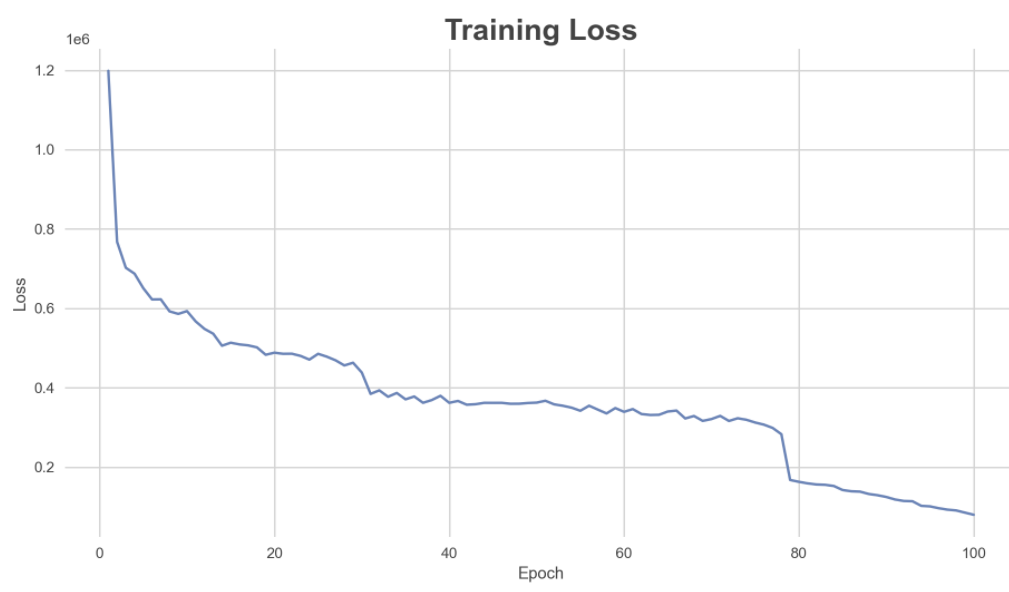
훈련 손실을 플로팅하여 각 에포크 후에 감소하는지 확인
-
손실 값이 0에 가까울수록 모델은 주변 컨텍스트 노래를 감안할 때 대상 노래를 더 잘 예측, 따라서 제작된 송 벡터는 의미가 있음
벡터 시각화
-
곡 벡터는 색의 그라데이션으로 시각화할 수 있음
-
모델은 256차원을 사용하여 훈련되므로 곡마다 256개의 색상 막대가 있어 벡터의 요소 값을 나타냄
-
곡 사이의 유사성은 코사인 유사성을 사용하여 계산
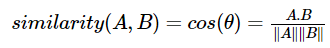
-
수학적으로 코사인 유사도는 다차원 공간에 투영된 두 벡터 A와 B사이의 각도의 코사인(cosine)을 측정
-
유사한 맥락의 노래 벡터는 가까운 공간 위치를 점유하며 벡터 사이의 코사인은 1에 가까워야 하고, 각도는 0에 가까워야 함, 각도가 작을수록 코사인 유사도가 높아짐

-
위의 플롯은 song_id = '4162'(Maroon 5 - She Will Be Loved)와 가장 유사한 5개의 노래를 보여줌
-
이 모델은 코사인 유사도를 사용하여 신곡을 추천하는 데 사용할 수 있지만 하나의 메인 곡만 기반으로 함
클러스터링
-
노래 벡터로 K-Means 클러스터링을 사용하여 여러 클러스터로 그룹화할 수 있음
벡터 간의 유사성은 일반(유클리드) 거리 대신 코사인 거리를 사용하여 계산된다. -
구형 K-Means 클러스터링: 코사인 거리를 이용한 K-Means
구면 K-MEANS
-
아래 그림을 참조하여 그림을 보고 다음 단계를 수행
- (0,0) ~ (1,1) 범위의 임의 2D 벡터 생성
- 벡터가 정규화되도록 각 벡터를 단위 원 위에 투영(길이 1과 동일)
- 투영 벡터로부터 k 클러스터로 기본 k-Means 군집화를 수행하여 동일한 클러스터 내의 벡터가 가능한 유사하고 서로 다른 군집에서의 벡터는 가능한 한 차이가 나도록 함
- 각 벡터에 대해 클러스터 번호를 할당
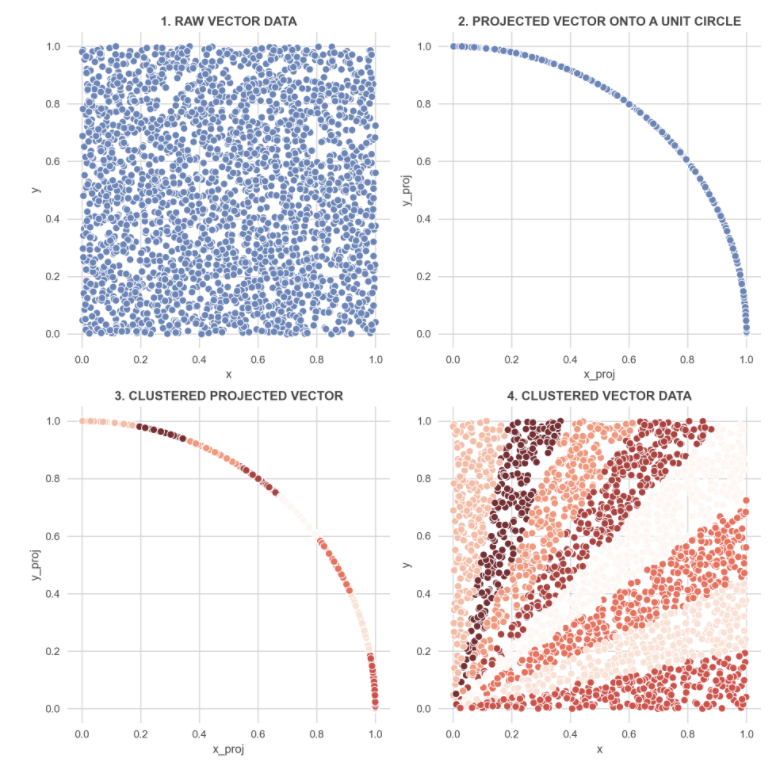
-
군집 수를 10개에서 500개로 반복해서 최적의 군집 수를 설정하여 곡 벡터에 구형 K-Means를 수행, k_opt 팔꿈치 방법으로 선택
embedding_matrix = model.wv[model.wv.vocab.keys()]
embedding_matrix.shape
#> (72047, 256)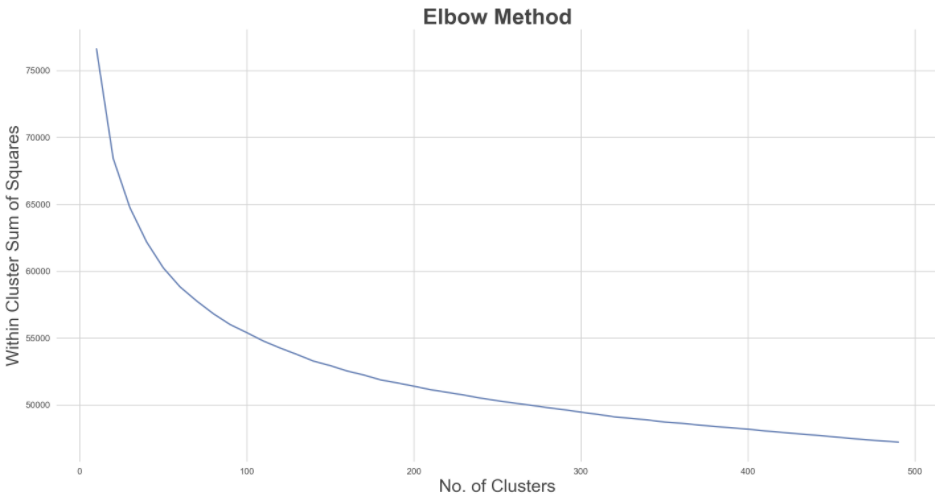
-
최적의 클러스터 수를 객관적으로 찾는 방법 (k_opt elbow method)
-
곡선의 첫 번째 점과 마지막 점을 직선으로 연결
-
각 점에서 해당 선까지의 수직 거리 계산
-
가장 긴 거리를 팔꿈치로 간주
-
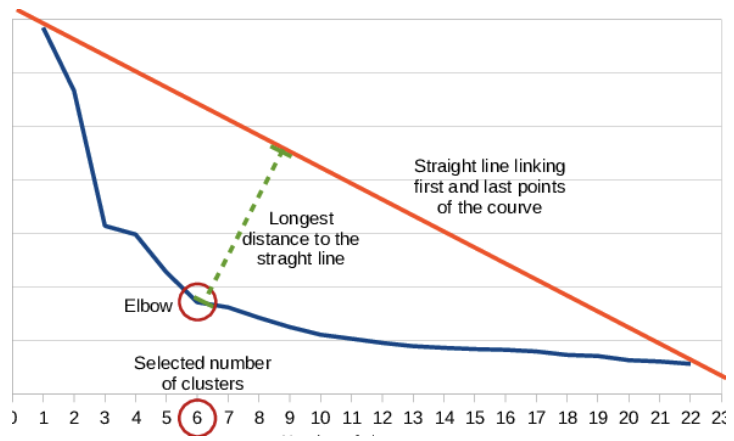
k_opt = locateOptimalElbow(skm_df.index, skm_df['WCSS'].values)
skm_opt = skm_df.loc[k_opt, "skm_object"]
skm_opt
#> SphericalKMeans(copy_x=True, init='k-means++', max_iter=300, n_clusters=110,
#> n_init=5, n_jobs=-1, normalize=True, random_state=123, tol=0.0001,
#> verbose=0)
songs_cluster = songs.copy()
songs_cluster.loc[model.wv.vocab.keys(), 'cluster'] = skm_opt.labels_
songs_cluster['cluster'] = songs_cluster['cluster'].fillna(-1).astype('int').astype('category')
songs_cluster.head()
#> title ... cluster
#> song_id ...
#> 0 Gucci Time (w\/ Swizz Beatz) ... 94
#> 1 Aston Martin Music (w\/ Drake & Chrisette Mich... ... 94
#> 2 Get Back Up (w\/ Chris Brown) ... 33
#> 3 Hot Toddy (w\/ Jay-Z & Ester Dean) ... 94
#> 4 Whip My Hair ... 94
#>
#> [5 rows x 5 columns]-
최적 군집 수는 110개로 설정 됨
-
재생 목록이 학습 및 테스트를 위해 분할되어 있기 때문에 일부 노래에는 내장 벡터가 없을 가능성이 있으며, 이 경우 클러스터를 대신 -1로 할당
클러스터 시각화
-
생성된 임베딩을 시각화하는 것은 항상 매우 유용함
-
여기에 256차원의 노래 벡터가 있으며 이러한 고차원 벡터는 3D 세계에서 시각화할 수 없으므로 t-SNE(t-Distributed Stochastic Neighbor Embedding)와 같은 차원 축소 알고리즘을 사용하면 벡터를 더 낮은 차원으로 매핑할 수 있음
-
t-SNE는 실제로는 뚜렷하게 격리된 클러스터로 시각화를 생성하는 경향이 있음
embedding_tsne = TSNE(n_components = 2, metric = 'cosine',
random_state = 123).fit_transform(embedding_matrix)
save2Pickle(embedding_tsne, "tsne_viz")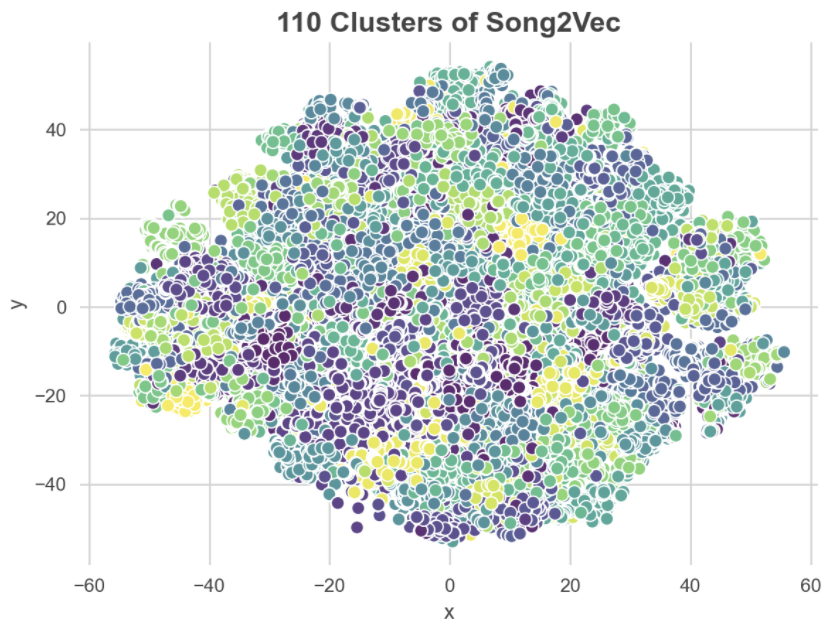
- 110개 클러스터가 모두 한 번에 구성되기 때문에 클러스터가 어수선해 보일 수 있으므로 무작위로 선택한 10개의 군집에 대해 t-SNE를 수행하고 결과를 시각화
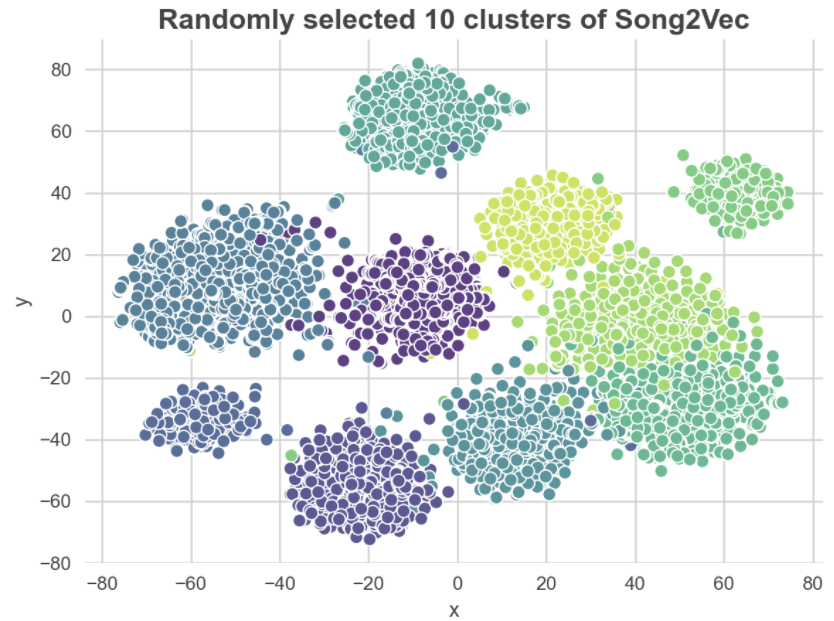
-
유사한 맥락(코사인 유사성 기준)을 가진 노래는 나란히 표시되는 경향이 있으므로 별개의 노래 클러스터를 생성함
-
클러스터는 차원 축소로 인해 서로 겹치는 것처럼 보일 수 있지만 실제 차원에서는 그렇지 않음
추천 시작
-
노래 벡터를 사용하여 특정 재생 목록을 기반으로 유사한 노래를 제안하는 방법
-
해당 재생 목록의 모든 노래 벡터를 평균화하여 각 재생 목록에 대한 재생 목록 벡터를 계산
-
이러한 벡터는 코사인 유사도를 기반으로 유사한 노래를 찾는 쿼리가 됨
-
-
playlist_test의 각 재생 목록에 대해 meanVectors() 함수를 사용하여 평균 벡터를 계산, 노래가 이전에 삽입되지 않은 경우 무시
def meanVectors(playlist):
vec = []
for song_id in playlist:
try:
vec.append(model.wv[song_id])
except KeyError:
continue
return np.mean(vec, axis=0)
playlist_vec = list(map(meanVectors, playlist_test))-
각 재생 목록 벡터에 대해 코사인 유사도를 기반으로 상위 n개의 유사한 노래를 추천할 수 있음
-
노래 임베딩을 테스트하여 인덱스 305의 playlist_test에 대한 상위 10개 노래를 추천
def similarSongsByVector(vec, n = 10, by_name = True):
# extract most similar songs for the input vector
similar_songs = model.wv.similar_by_vector(vec, topn = n)
# extract name and similarity score of the similar products
if by_name:
similar_songs = [(songs.loc[song_id, "artist - title"], sim)
for song_id, sim in similar_songs]
return similar_songs
print_recommended_songs(idx = 305, n = 10)
#> ============================
#> SONGS PLAYLIST
#> ============================
#> Selena - Como La Flor
#> The Texas Tornados - Who Were You Thinkin' Of
#> Selena - Sentimientos
#>
#> ============================
#> TOP 10 RECOMMENDED SONGS
#> ============================
#> [Similarity: 0.835] Selena - Como La Flor
#> [Similarity: 0.779] Selena - Sentimientos
#> [Similarity: 0.763] Little Joe Y La Familia - Borrachera
#> [Similarity: 0.751] Lorenzo Antonio - Con La Misma Espina
#> [Similarity: 0.745] Tierra Tejana - Eres Casado
#> [Similarity: 0.742] Jennifer Y Los Jetz - Me Piden
#> [Similarity: 0.730] The Texas Tornados - (Hey Baby) Que Paso
#> [Similarity: 0.712] The Texas Tornados - Who Were You Thinkin' Of
#> [Similarity: 0.709] Ruben Vela - La Papaya
#> [Similarity: 0.704] Sparx - Lo Dice Mi Corazon
#> ============================- 흥미롭게도 이 모델은 명시적으로 언급되지 않은 305 재생 목록_테스트의 "스페인" 장르를 기반으로 한 신곡을 캡처하고 추천할 수 있음
평가하기
-
추천자 시스템의 성능을 평가하는 방법은 다음과 같은 적중률을 계산하는 것
-
재생 목록의 각 곡에 대해 한 곡을 의도적으로 LOO(Leave-One-Out)를 사용
-
아래 몇 가지 시스템을 사용하여 LOO 노래를 추측
-
상위 n개 추천곡을 추천인에게 요청
-
LOO 곡이 상위 n추천 목록에 나타나면 HIT로 간주
-
재생 목록이 끝날 때까지 LOO 프로세스를 반복한 후 HIT 수를 재생 목록의 길이로 나누어 재생 목록의 적중률을 계산
-
playlist_test의 모든 재생 목록에 대해 1-5단계를 반복하고 n(AHR@n)에서 평균 적중률을 계산
-
top_n_songs = 25랜덤 추천자
- 베이스라인으로 시스템 없이 랜덤하게 LOO 노래를 추천
def hitRateRandom(playlist, n_songs):
hit = 0
for i, target in enumerate(playlist):
random.seed(i)
recommended_songs = random.sample(list(songs.index), n_songs)
hit += int(target in recommended_songs)
return hit/len(playlist)
eval_random = pd.Series([hitRateRandom(p, n_songs = top_n_songs)
for p in tqdm(playlist_test, position=0, leave=True)])
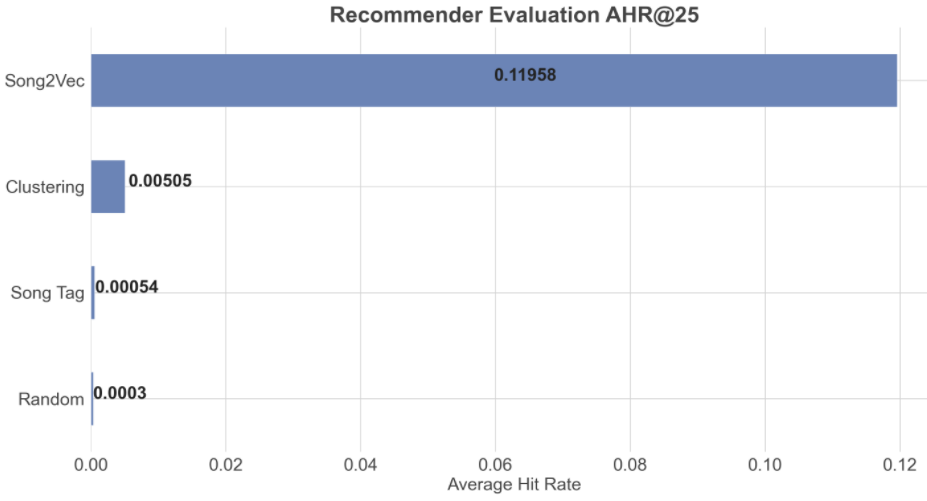
eval_random.mean()Output: 0.00030413731380910425
노래 태그 추천자
-
데이터에서 제공되는 노래 태그를 기반으로 다음과 같이 추천이 가능
-
LOO 노래를 둘러싸는 노래 tag_names 목록을 만들고 LOO와 컨텍스트 노래 사이의 최대 거리는 window에 의해 정의
-
목록에서 가능한 모든 노래를 나열
-
가능한 노래 목록에서 n곡을 무작위로 추출.
-
mapping_tag2song = songs.explode('tag_names').reset_index().groupby('tag_names')['song_id'].apply(list)
def hitRateContextSongTag(playlist, window, n_songs):
hit = 0
context_target_list = [([playlist[w] for w in range(idx-window, idx+window+1)
if not(w < 0 or w == idx or w >= len(playlist))], target)
for idx, target in enumerate(playlist)]
for i, (context, target) in enumerate(context_target_list):
context_song_tags = set(songs.loc[context, 'tag_names'].explode().values)
possible_songs_id = set(mapping_tag2song[context_song_tags].explode().values)
random.seed(i)
recommended_songs = random.sample(possible_songs_id, n_songs)
hit += int(target in recommended_songs)
return hit/len(playlist)
eval_song_tag = pd.Series([hitRateContextSongTag(p, model.window, n_songs = top_n_songs)
for p in tqdm(playlist_test, position=0, leave=True)])
eval_song_tag.mean()Output: 0.0005425495180688559
클러스터 기반 추천자
-
더 개선하여 모델링 섹션의 클러스터링 결과를 활용
-
주변 노래에서 가장 빈번한(다수 투표에 의해) 클러스터 번호를 식별, LOO와 컨텍스트 노래 사이의 최대 거리는 window에 의해 정의
-
다수결 클러스터에서 가능한 노래를 나열
-
가능한 노래 목록에서 n곡을 무작위로 추출
-
def hitRateClustering(playlist, window, n_songs):
hit = 0
context_target_list = [([playlist[w] for w in range(idx-window, idx+window+1)
if not(w < 0 or w == idx or w >= len(playlist))], target)
for idx, target in enumerate(playlist)]
for context, target in context_target_list:
cluster_numbers = skm_opt.predict([model.wv[c] for c in context if c in model.wv.vocab.keys()])
majority_voting = stats.mode(cluster_numbers).mode[0]
possible_songs_id = list(songs_cluster[songs_cluster['cluster'] == majority_voting].index)
recommended_songs = random.sample(possible_songs_id, n_songs)
songs_id = list(zip(*recommended_songs))[0]
hit += int(target in songs_id)
return hit/len(playlist)
eval_clust = pd.Series([hitRateClustering(p, model.window, n_songs = top_n_songs)
for p in tqdm(playlist_test, position=0, leave=True)])
eval_clust.mean()Output: 0.005054657281168753
SONG2VEC 추천자
- 마지막으로, 다음과 같이 CBOW Song2Vec 모델을 평가
- 이전에 정의한 meanVectors() 함수를 사용하여 주변 컨텍스트 노래의 평균 벡터를 가져옴, 최대 거리는 wiodow로 정의
- SimilarSongsByVector() 함수를 사용하여 코사인 유사도를 기반으로 상위 n개의 유사한 노래를 추천
def hitRateSong2Vec(playlist, window, n_songs):
hit = 0
context_target_list = [([playlist[w] for w in range(idx-window, idx+window+1)
if not(w < 0 or w == idx or w >= len(playlist))], target)
for idx, target in enumerate(playlist)]
for context, target in context_target_list:
context_vector = meanVectors(context)
recommended_songs = similarSongsByVector(context_vector, n = n_songs, by_name = False)
songs_id = list(zip(*recommended_songs))[0]
hit += int(target in songs_id)
return hit/len(playlist)
eval_song2vec = pd.Series([hitRateSong2Vec(p, model.window, n_songs = top_n_songs)
for p in tqdm(playlist_test, position=0, leave=True)])
eval_song2vec.mean()Output: 0.11958469298590102
비교
-
4개의 추천 시스템 중 (AHR@25)로 계산된 평균 적중률을 비교
-
AHR이 높을수록 시스템이 좋음
-
아래 막대 그래프에서 Song2Vec은 히트율 측면에서 다른 방법보다 성능이 우수하므로 주변 컨텍스트 노래를 기반으로 노래를 잘 추천할 수 있음
-
실제 시나리오에서 이 시스템은 AHR이 약 12%에 불과하기 때문에 품질이 낮을 수 있지만 여전히 추천 시스템이 없는 것보다 훨씬 나음
결론
-
Song2Vec은 재생 목록의 주변 노래를 기반으로 노래의 컨텍스트를 캡처할 수 있는 Word2Vec의 구현
-
재생 목록의 순차 속성을 성공적으로 활용하고 각 노래를 256차원 벡터로 나타냄
-
벡터 표현은 코사인 유사도 점수를 기반으로 하는 추천 시스템으로 사용됨
-
음악 추천자의 목표는 과거 재생 목록이나 청취 대기열에서 정확한 개인화된 추천을 생성하는 것이므로 AHR@n과 같은 메트릭을 사용하여 주변 컨텍스트 곡을 기반으로 추천곡 상위 n개에 곡이 평균 몇 번(평균) 나열되는지 평가
-
Song2Vec을 적용할 때 주의해야 할 점은 새로운 사용자에게 어떤 노래를 추천, 어떤 사용자에게 새 노래를 추천이 불가능한 콜드 스타트 문제
-
이는 "Song Tags Recommender" 섹션에서 설명한 대로 노래의 명시적 특징 또는 특성을 활용하는 콘텐츠 기반 기술을 사용하여 추천자를 결합하여 효율적으로 처리할 수 있음
Reference

데이터 클렌징 노래 코드에서 FOLDER PATH가 정의가 안되어있는데 이 글에 있는 코드말고도 더 필요한 코드가 있나요?