Spark는 가장 널리 사용 되는 분산 처리 framework로, In-memory, distributed data processing framework 로 설명할 수 있다. Spark는 RDD라는 abstract 한 데이터로 부터 연산(transformation)을 거쳐 새로운 RDD를 정의하고, 최종 연산(action)이 call 되면 실제로 계산을 통해 결과를 도출한다.
간단히 Spark의 실행 흐름에 대해 이해할 필요가 있다. 아래 그림은 간단한 Spark application 소스 코드와, 그에 대응 되는 DAG를 나타낸다. Spark의 실행흐름은 아래 그림과 같이 RDD가 vertex, transformation은 edge로 구성되는 DAG로 나타낼 수 있다.
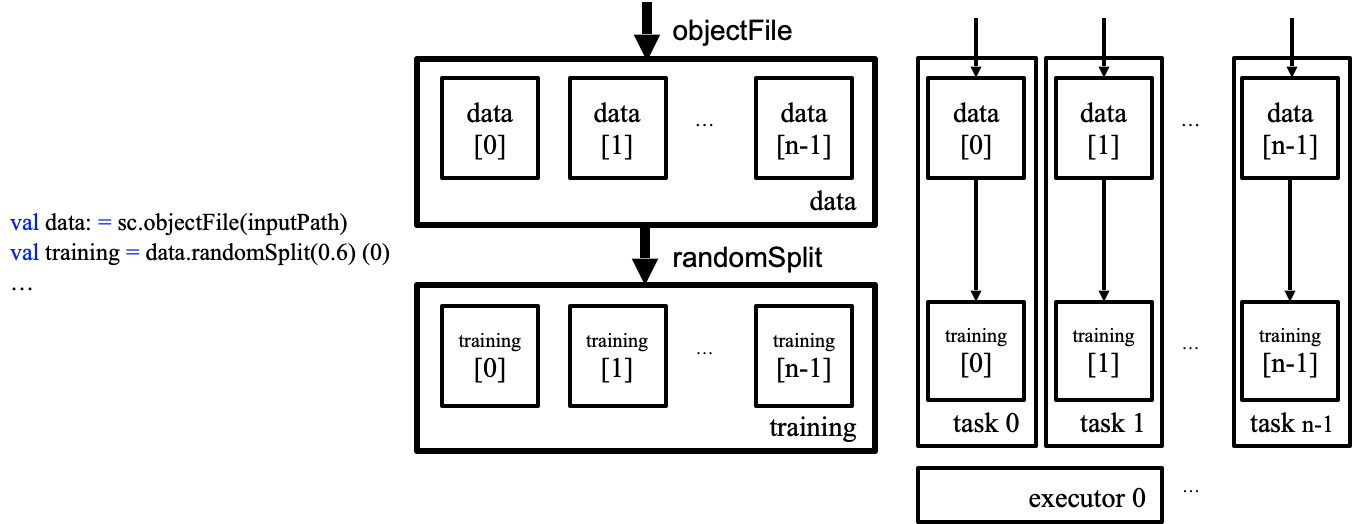
DAG는 Spark에서 하나의 Job을 나타낸다. 물론 application에서 여러개의 잡이 순차적으로 수행 될 수 있다. Spark의 Job은 Stage → Stage → … → Stage 와 같이 Stage들로 구성되고, 각 Stage 의 사이에는 shuffle이 발생한다.
RDD는 Resilent Distributed Dataset이라는 full name 처럼, 분산된 데이터 조각들의 집합이다. 이 조각을 RDD partition 또는 RDD block으로 불린다. 각 파티션들은 그림과 같이 개별적으로 처리가 되며, 파티션 하나와 연관된 연산들을 Task라고 칭한다. 각 Task들은 Spark executor들에 할당되어 수행이 된다.
여기까지의 과정 [실제 데이터들은 RDD라는 abstraction 아래에서 어떤 형태로 관리되고, 분산돼서 처리 되는지] 을 코드 수준으로 분석해보았다. Spark RDD, transformation, action의 관점에서 정리하였으며, 소스코드는 Spark 3.3.0 버전을 기준으로 작성하였다.
RDD
action
Spark는 lazy-evaluation을 한다. action이 불려야 RDD lineage를 따라 실제 연산을 수행한다. 가장 대표적인 action인 count() 를 예시로 보도록 하겠다.
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sumaction은 SparkContext 의 runJob을 호출한다. 호출하면서 RDD 객체와 수행할 함수를 인자로 넘긴다.
SparkContext
runJob
SparkContext에서 runJob은 dagScheduler의 runJob을 호출한다. DAG는 RDD들 간의 lineage(dependency)가 정의된 그래프이고, application 소스코드로 부터 DAG를 스케쥴링하여 생성하는 모듈이 DAGScheduler이다.
runJob 함수의 인자 partitions 는 Sequence of RDD partition 이다. RDD 객체 내에 존재하는 partition 정보로 부터 생성된다. func는 action의 결과물을 얻기 위해 사용된다.
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
...
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
}DAGScheuler
runJob
DAGScheuler에서는 submitJob 함수를 호출한다.
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
...
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
}submitJob
submitJob 함수에서는 partition이 empty 하지 않다면 eventProcessLoop에 Job을 submit 한다. JobSubmitted를 post 한다.
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))doOnReceive
eventProcesLoop에서는 event가 post 될 때마다 처리하는 eventThread가 존재한다. eventThread 에서는 event를 receive 할 때 마다 handling 하는 doOnReceive 함수가 run 하고 있다.
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)handleJobSummitted
handleJobSubmitted 함수에서는 finalStage를 생성하고, submitStage를 호출한다. DAG에서 가장 bottom 에 위치한 leaf node에서 action이 호출 되기 때문에, finalStage 부터 submit 되는 것이다.
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
...
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
...
submitStage(finalStage)
}submitStage
submitStage에서는 Task들을 수행 하는 명령을 내린다. Tasks 수행에 앞서 submit 되지 않은 Stage들 (finalStage의 parent Stage들)을 재귀적으로 submit 한다. 즉, Stage → Stage → … → Stage 에서 root Stage 부터 task가 수행이 되는 것이다.
private def submitStage(stage: Stage): Unit = {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}submitMissingTasks
submitMissingTasks 에서는 taskScheduler에 TaskSet를 submit 한다. 이 때 인자로 받는 stage가 ShuffleMapStage인지, ResultStage인지에 따라 다른 tasks를 생성한다.
private def submitMissingTasks(stage: Stage, jobId: Int): Unit = {
...
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties,
stage.resourceProfileId))
}TaskScheduler
실제 구현은 TaskSchedulerImpl.scala 에 있다.
submitTasks
submitTasks 가 호출 되면, taskManager를 생성하고 schedulableBuilder의 schedulerable pool에 추가한다. 추가하는 과정은 synchronization 된다. pool에 추가된 taskSet은 schedule rule에 따라 pop된다. 기본적으로 FIFO rule을 따른다. 그 후 schedulerBackend 에서 reviveOffers()를 호출한다.
override def submitTasks(taskSet: TaskSet): Unit = {
...
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
...
backend.reviveOffers()SchedulerBackend
reviveOffers
SchedulerBackend 에서는 driverEndPoint를 통해 ReviveOffers 메세지를 send 하며, 보낸 메세지는driverEndPoint 에서 receive 후 처리한다. 아래 코드는 CoarseGrainedSchedulerBackend의 구현 코드이다.
override def reviveOffers(): Unit = Utils.tryLogNonFatalError {
driverEndpoint.send(ReviveOffers)
}- https://github.com/apache/spark/blob/branch-3.3/core/src/main/scala/org/apache/spark/scheduler/SchedulerBackend.scala#L36
- https://github.com/apache/spark/blob/branch-3.3/core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala#L629
DriverEndpoint
DriverEndpoint 는 CoarseGrainedSchedulerBackend에 구현되어 있다. cluster mode를 사용해야 rpc endpoint를 통해 task 정보를 전송할 필요가 있기 때문이다.
receive
ReviveOffers 의 경우 makeOffers를 호출한다.
override def receive: PartialFunction[Any, Unit] = {
...
case ReviveOffers =>
makeOffers()makeOffers
TaskScheduler로부터 worker들의 resource를 제공받고, task들을 실행 한다. 위에서 언급된 schedulerable pool 에서 taskSet을 가져오고, task와 executor를 매칭한 taskDescs 를 생성한다. 그리고 launchTask를 call 한다.
private def makeOffers(): Unit = {
...
val taskDescs = { ...
scheduler.resourceOffers(workOffers, false)}
...
launchTasks(taskDescs)launchTasks
인자로 받은 tasks를 flatten 하여 task별로 할당된 Executor로 serializedTask를 launch 한다. executorEndPoint는 각 Executor의 ExecutorBackend에 존재한다.
private def launchTasks(tasks: Seq[Seq[TaskDescription]]): Unit = {
...
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))여기까지의 내용은 Spark cluster의 master node에 존재하는 driver 수준 에서의 내용이였다. worker node의 executor 수준 에서의 내용은 다음편에서 이어진다.
Reference
