JS Engine
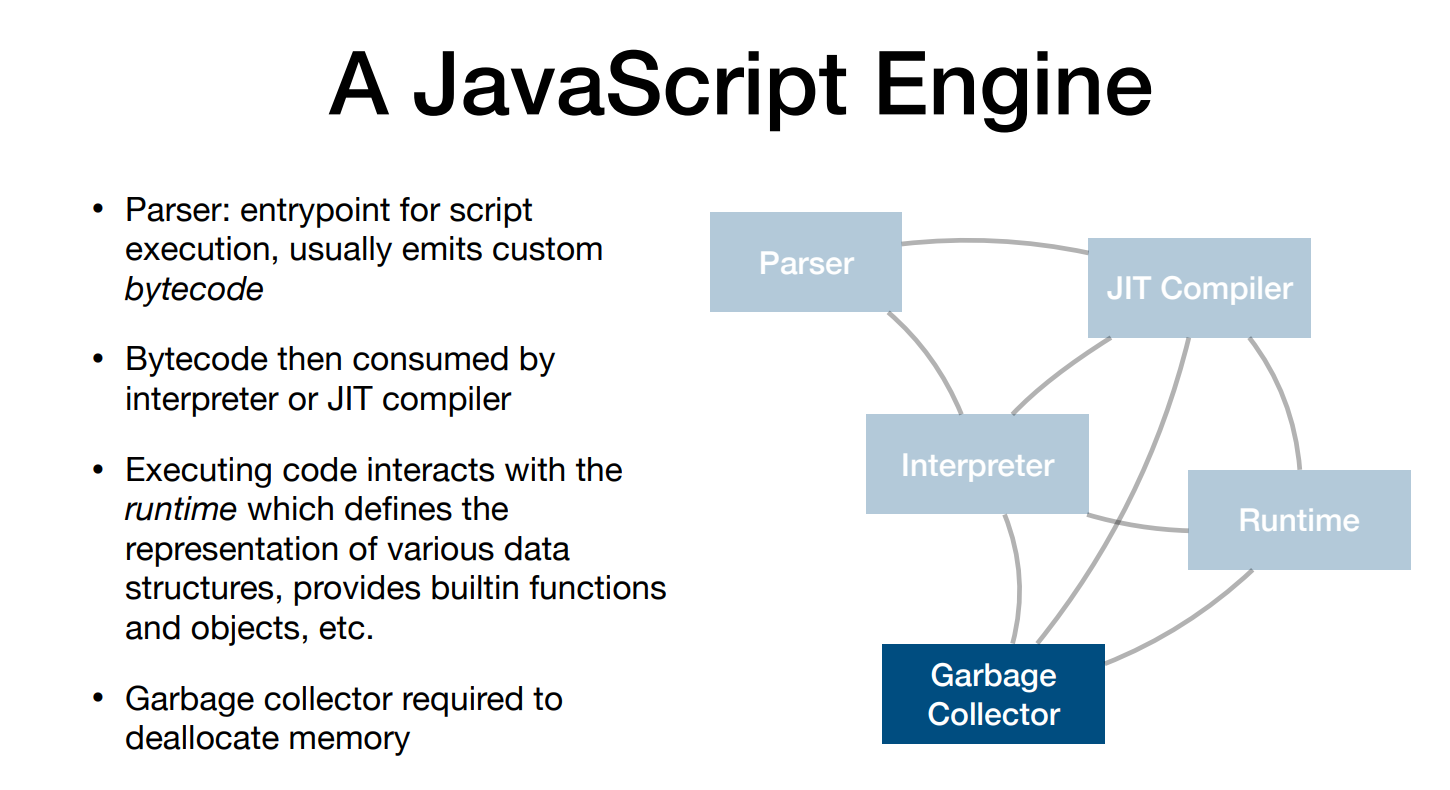
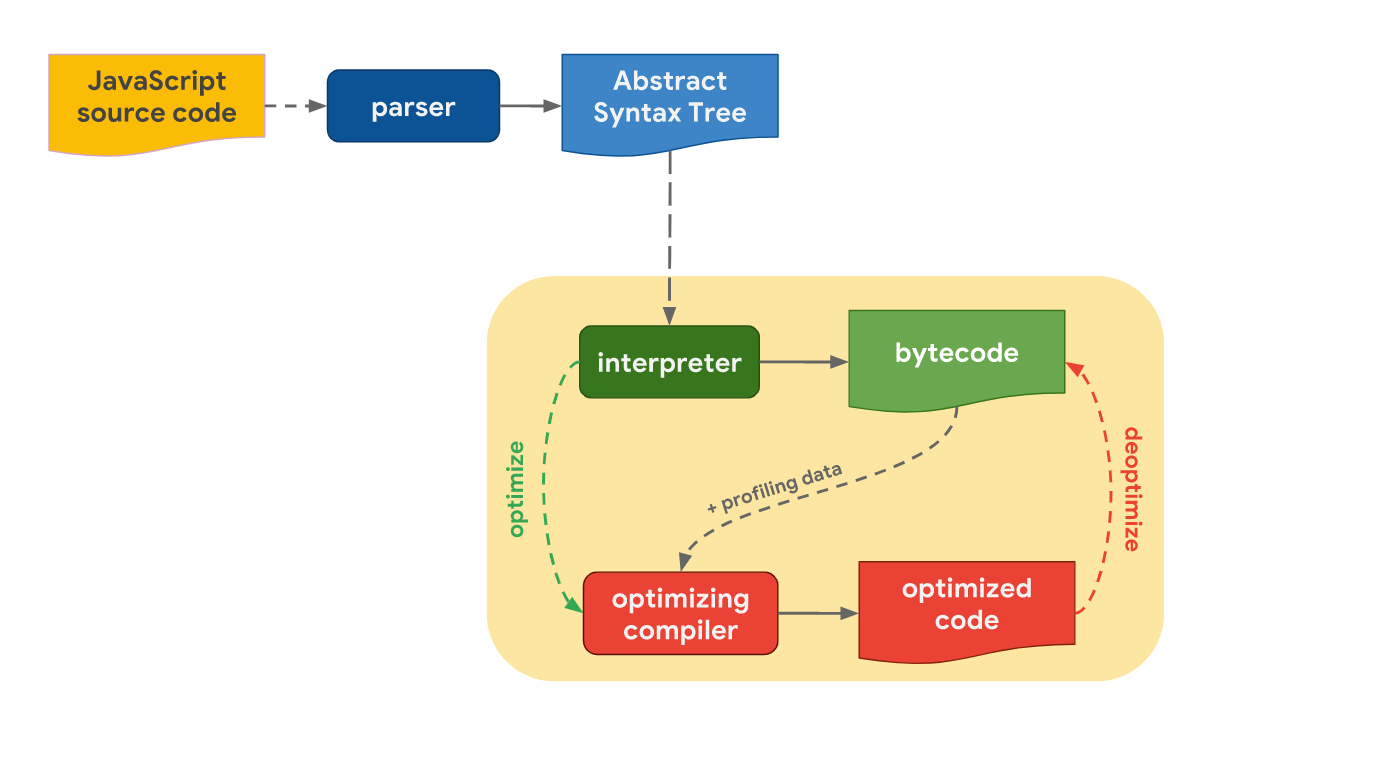
기본적인 순서는 다음과 같다.
1) JS 코드 파싱
2) AST 생성
3) 인터프리터가 AST를 통해 최적화되지 않은 바이트 코드 생성
4) 최적화 컴파일러에서 최적화된 코드 생성
5) 결과가 이상하면 원래대로 되돌림
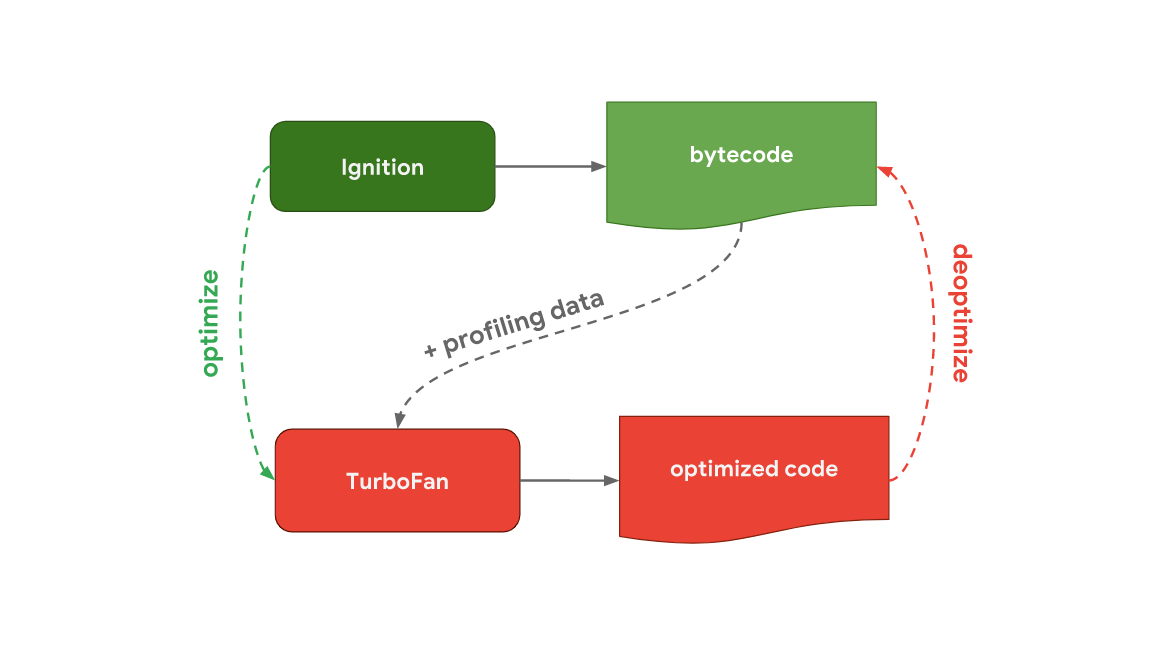
V8에선 interpreter를 Ignition, Optimizing compiler를 TurboFan이라고 부른다.
전체적으로 흐름은 동일하다.
파싱하고, ignition이 바이트 코드를 생성하고, turboFan이 자주 사용되는 코드들을 optimize 해준다.
Runtime
Builtins

slice 같은 애들이 Builtin이라고 할 수 있다.
엔진에서 자체적으로 구현되어있다.

Builtins가 low-level 언어로 구현되는 경우가 많아서, 취약점이 터질 가능성이 높다.
JSValues

JSValue는 동적으로 타입이 결정된다.
컴파일 타임 변수 제외하고는 타입 정보가 런타임 변수에 저장된다.
효과적으로 저장하기 위한 방법이 있다.

V8에 Pointer tagging scheme 이란게 있다.
하위 1비트가 0이냐 1이냐에 따라서 SMI인지, pointer인지 구분한다.
JSObjects
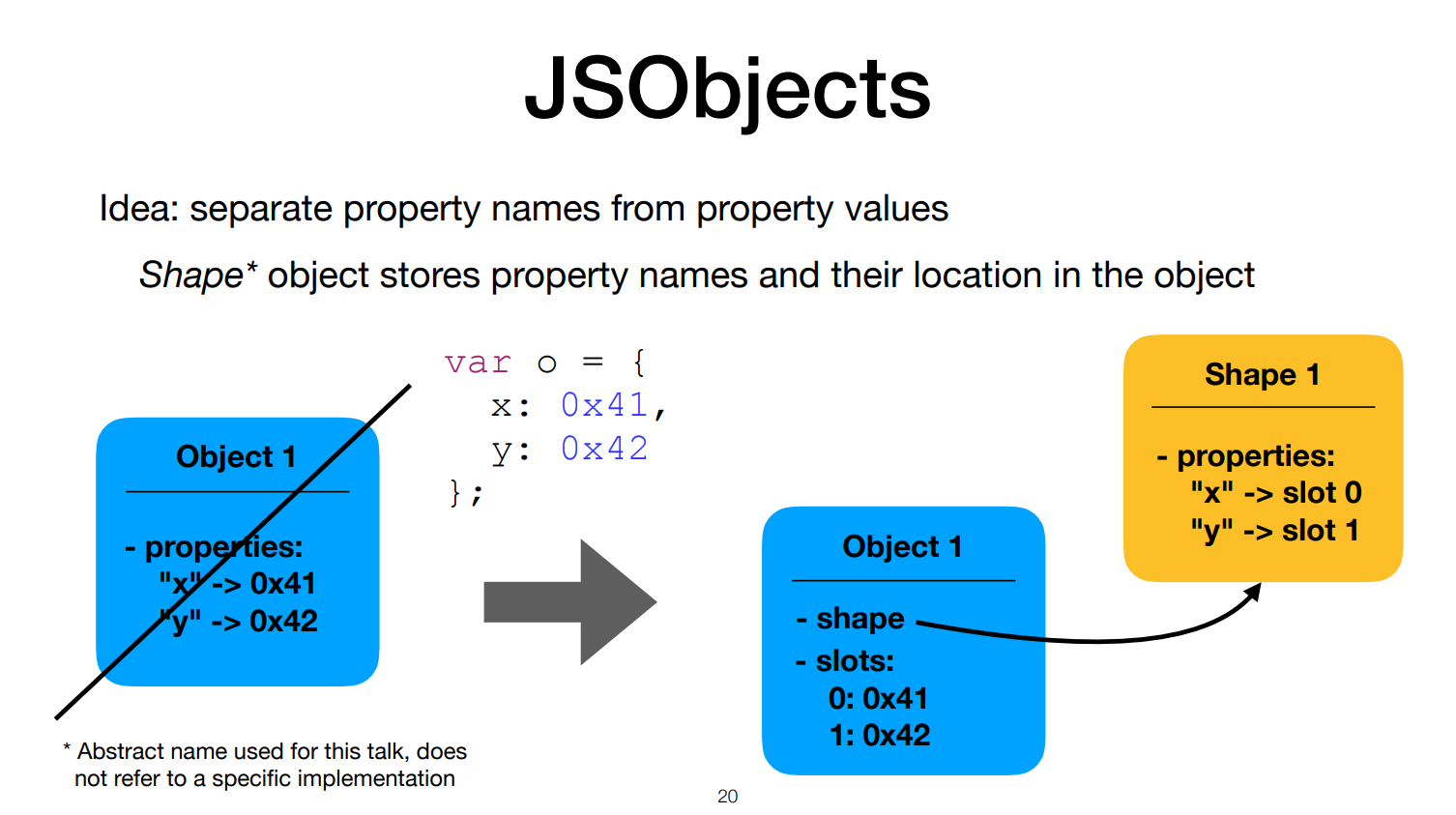
property name과 property value를 분리한다.
이때 shape는 immutable과 shared라는 특성을 가진다.
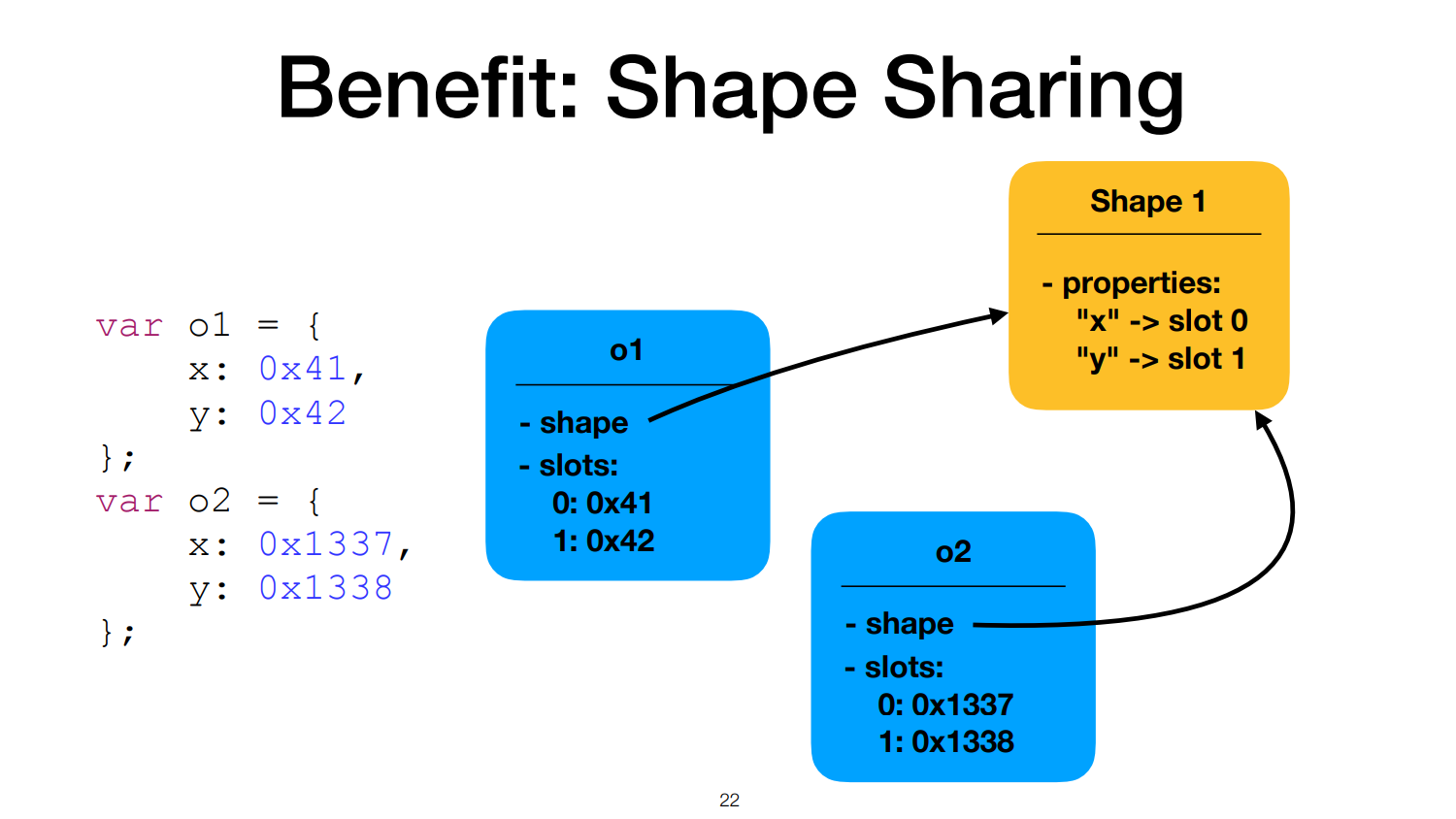
두 객체 둘다 유사하게 생겼다.
shape를 공유하면, 메모리 낭비를 줄일 수 있다.

새로운 property가 추가되면 새로운 shape가 생성된다.
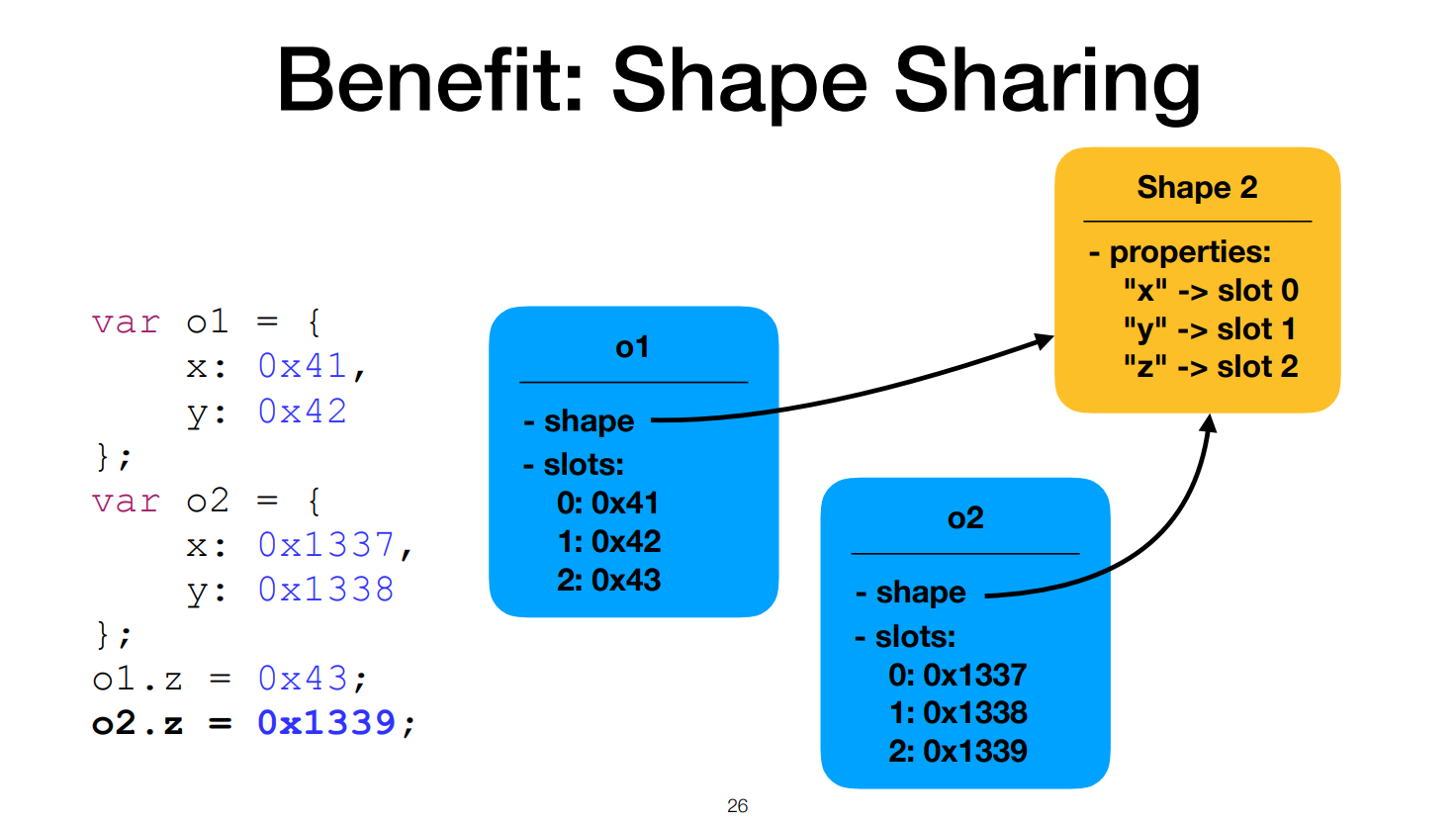
shape가 필요없어지면 사라진다.
Object Example

shape 포인터를 따로 가진다.
SMI들은 하위 1비트가 0인것을 확인할 수 있다.
Speculative JIT Compilers
Interpreter Vs JIT Compiler

JIT compiler는 기본적으로 인터프리터처럼 동작하다가, 반복되는 함수 호출같은 최적화 가능한 부분들을 machine code로 컴파일하고, machine code로 돌리는 방식이다.
major challenge

위 코드는 컴파일하기 쉽다.
컴파일 타임에 타입이나 ABI를 알 수 있기 때문이다.

위 코드는 컴파일하기 어렵다.
컴파일 타임에 파라미터 타입도 모르고, + operation이 타입에 따라 동작이 다 다르기 때문이다.
객체도 약간 비슷한 맥락이다.

파라미터 타입도 알고 구조체 레이아웃도 알고 있으니 쉽게 컴파일 가능하다.

파라미터 타입, shape, 어디 저장되어있는지 알기 힘들기 때문에 컴파일하기 어렵다.
Assumption : Known types
위 케이스들처럼 dynamic languages를 컴파일할때 걸림돌이 많다.
걸림돌중 하나는 missing type information이다.

그냥 Known type으로 때려 맞추고 시작한다.

일단 찍어 맞춘다.
Obtaining Type information
JIT compile 하면서 앞에서 호출된 함수들의 인자 타입 정보들을 통해서 예측 가능하다.


Code Generation

타입을 찍어 맞췄으면, 그걸 체크해야된다.
그래서 있는게 Speculation guards이다.

SMI 인지 체크하는 예시이다.

객체 shape 찍어맞추는 예시이다.
