이 포스트는 Sequelize 공식문서의 Model Page를 설명하는 글이다.
1. addScope
addScope의 사용법을 이해하기 위해서는 우선 Scope가 무엇인지 알아야한다.
Scope란?
Scope는 Object.find method의 reusable함을 높이기 위해서 도입된 개념이다.
Database에서 다양한 조건으로 instance들을 조회할텐데, 조회할때 조건들을 매번 일일이 작성하는 것이 아니라, 조회 조건의 별명을 붙여놓고 사용하고 싶을때 꺼내서 사용하는 느낌으로 이해하면 될 것 같다.
다음과 같이, scope는 finder object가 될수도 있고, finder object를 return 하는 함수가 될수도 있다. 그러나, default scope는 무조건 finder object여야 한다!
class Project extends Model {}
Project.init({
// Attributes
}, {
defaultScope: {
where: {
active: true
}
},
scopes: {
deleted: {
where: {
deleted: true
}
},
activeUsers: {
include: [
{ model: User, where: { active: true } }
]
},
random() {
return {
where: {
someNumber: Math.random()
}
}
},
accessLevel(value) {
return {
where: {
accessLevel: {
[Op.gte]: value
}
}
}
},
sequelize,
modelName: 'project'
}
});Model.addScope 를 사용하여 model이 정의된 이후에도 scope를 추가할 수 있다.
default scope는 항상 적용되기 때문에, Project.findAll() 을 작성할 경우 다음과 같은 SQL문으로 변환된다.
SELECT * FROM projects WHERE active = true
default scope를 적용하고 싶지 않다면, Project.unscope() , Project.scope(null)을 사용하면 된다.
default scope외의 다른 scope를 사용하고 싶다면, Project.scope('deleted').findAll();
과 같이 scope 함수의 인자로 scope 이름을 넣으면 된다.
여러개의 Scope들을 Merge 하고 싶다면, 다음과 같이 작성하면 된다.
Project.scope('deleted' , 'activeUsers').findAll();
Project.scope(['deleted' , 'activeUsers']).findAll();Generated SQL :
SELECT * FROM projects
INNER JOIN users ON projects.userId = users.id
WHERE projects.deleted = true
AND users.active = true여러 Scope들을 Merge해서 사용할 경우 limit , offset , order , paranoid , lock , raw field들은 뒤의 Scope에 의해 overwritten 된다. where은 기본적으로 충돌되는 부분만 overwritten 된다. whereMergeStrategy속성을 이용해서 where filed의 속성들이 and 또는 or로 merge되게 할 수 있다.
addScope 예시
public static addScope(name : string , scope : object | Function , options : string)
다음과 같은 model이 있다고 하자.
class User extends Sequelize.Model {
static init(sequelize) {
return super.init({
name: {
type: Sequelize.STRING(20),
allowNull: false,
unique: true,
},
age: {
type: Sequelize.INTEGER.UNSIGNED,
allowNull: false,
},
married: {
type: Sequelize.BOOLEAN,
allowNull: false,
},
comment: {
type: Sequelize.TEXT,
allowNull: true,
},
created_at: {
type: Sequelize.DATE,
allowNull: false,
defaultValue: Sequelize.NOW,
},
}, {
sequelize,
timestamps: false,
underscored: false,
modelName: 'User',
tableName: 'users',
paranoid: false,
charset: 'utf8',
collate: 'utf8_general_ci',
});
} User model에는 다음과 같은 사용자들의 정보가 저장되어있다.
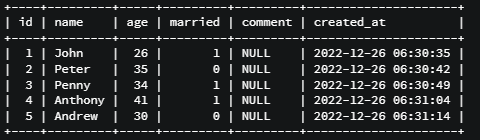
User.addScope('marriedUsers' , { where : { married : true, } }); 로 Scope를 추가하고,
const marriedusers = await User.scope('marriedUsers').findAll();
console.log(marriedusers);를 입력하면, married = true인 John , Penny , Anthony의 정보만 출력되는 것을 확인할 수 있다.
2. aggregate
aggregation
model에서 기준에 따라 자료들을 나누어서, 묶음별로 개수를 세거나, 최댓값등을 구하는 집계를 할때 사용된다.
공식문서에는 다음과 같이 설명되어있다.
Model.findAll({
attributes: [
'foo',
[sequelize.fn('COUNT', sequelize.col('hats')), 'n_hats'],
'bar'
]
});When using aggregation function, you must give it an alias to be able to access it from the model. In the example above you can get the number of hats with instance.n_hats.
하지만 실제로 작동시켜보면 여러가지 에러가 발생한다.
1. In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'learn-sequelize.Comment.comment'; this is incompatible with sql_mode=only_full_group_by
groub_by의 기준으로 추가하지 않은 column들을 attribute에 추가할 수 없다는 내용이다.
생각해보면 당연하다. 왜냐하면, 그룹별로 집계를 할 때, 집계의 기준이 되는 column이 존재할텐데, 집계의 기준이 되지 않은 column을 attribute의 요소로 포함하면, 어느 값을 대표로 표시해야할지 모르고, 애매모호한 상황이 발생한다.
예를 들어서, books라는 model에 author과 price , publisher라는 column이 있다고 하자.
author을 기준으로 가격들을 모두 더하고 싶은데, 더한 결과를 표시할때, author을 표시하는게 아니라, publisher을 표시하라고 하면 말이 안되는 것이다. author라는 group으로 분류를 했을때, 그 그룹에 속한 book들은 각기 다른 publisher을 가지고 있을 것이기 때문이다.
- 공식문서에서는
instance.aliasName로 접근할 수 있다고 했는데, 실제로 접근해보면undefined가 반환된다. 원인은 무엇인지 모르겠지만, alias를 사용한 객체들은instance.get('aliasName')로 값을 read할 수 있는 것 같다.
아무래도 두 문제 모두 Mysql과 sequelize의 버전이 업데이트 됨에 따라 생긴 문제인 것 같다.
Comment에 다음과 같은 정보가 저장되어있을때 실습을 진행해보자.
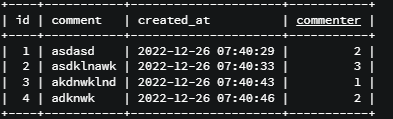
const Comments = await Comment.findAll({
attributes: [
'commenter',
[sequelize.fn('SUM', sequelize.col('id')), 'sum']
],
group:['commenter']
});
console.log(Comments);를 실행하게 되면, 다음과 같은 결과가 출력된다.
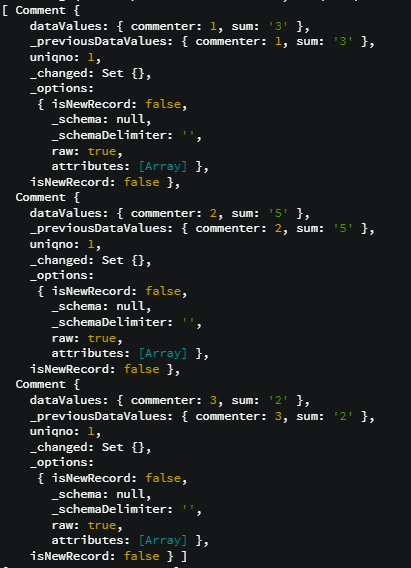
comment들을 commenter을 기준으로 그룹화 해서, 각각의 그룹에서 id의 합을 확인할 수 있다.
첫번째 그룹의 sum을 확인하고 싶으면, Comments[0].get('sum')으로 조회할 수 있다.
aggregation에는
'SUM' 뿐만 아니라, 'MIN' , 'MAX' , 'COUNT'들도 사용할 수 있다.
3. bulkCreate
이 method는 여러개의 instance를 한번에 insert 하고싶을때 사용한다.
다음과 같은 model이 있다고 하자.
const User = sequelize.define("User", {
firstName: {
type: Sequelize.STRING
},
lastName: {
type: Sequelize.STRING,
}
}, {
timestamps: false
});다음과 같이 세개의 instance를 한번에 생성후 저장할 수 있다.
User.bulkCreate([
{ firstName: "Nathan" },
{ firstName: "Jack" },
{ firstName: "John" },
])이때, 값을 지정하지 않은 column에는 NULL이 들어가게된다.
결과는 다음과 같다.
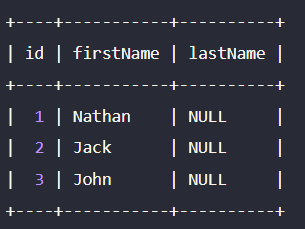
primary Key에도 AUTO_INCREMENT가 적용되어 있지 않다면, NULL 값이 들어가게 되므로 주의해야한다. 배열의 두번째 인자로 option들을 설정할 수 있다.
User.bulkCreate(
[
{ id: 1, firstName: "Nathan", lastName: "Sebhastian" },
{ id: 1, firstName: "Jack", lastName: "Stark" },
{ id: 1, firstName: "John", lastName: "Snow" },
],
{
ignoreDuplicates: true, //중복무시
}
)INCREMENT와 DECREMENT
Model.decrement(['number', 'count'], { by: 2, where: { foo: 'bar' } });
where 조건을 만족하는 instance들의 number과 count의 value를 2씩 감소시킨다.
Model.decrement({ answer: 42, tries: -1}, { by: 2, where: { foo: 'bar' } });
위와 같이 column 별로 감소시키고자 하는 값을 지정할수도 있고, 변경하고자 하는 모든 column의 개별 변경값이 지정되어있다면, by는 무시된다.
