
✨같이 삽질해보기
-
혼자서도 문제를 해결하려면
- SQL을 사용하다보면 예상하지 못했던 에러를 자주 마주하게 됩니다.
모든 에러에 대한 해결책을 외워서 해결하는 건 비효율적이겠죠?
- SQL을 사용하다보면 예상하지 못했던 에러를 자주 마주하게 됩니다.
-
에러 메시지 해석해보기 (1)
-
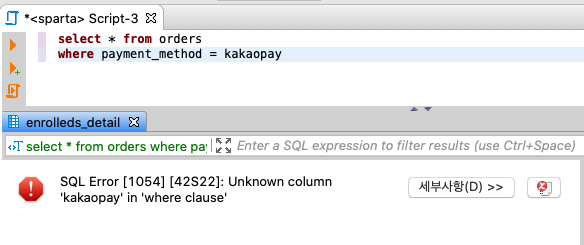
자, 뭔가 에러가 났습니다! 어떤 에러메시지일까요?
Unknown column 'kakaopay' in 'where clause'라고 나와있죠?Where 절에 있는 kakaopay라는 컬럼(필드)가 알려지지 않았다 (컴퓨터는 알지 못한다) 라는 것입니다.
즉, kakaopay라는 글자가 '컬럼(필드)' 이름으로 인식되어서 발생한 에러에요.💡 kakaopay를 'kakaopay'로 바꿔주면 되겠죠?
글자를 ''로 감싸면 변수가 아닌, 문자열(값)로 인식하겠다는 의미입니다.결제수단이 kakaopay라는 값을 가진 데이터만 불러오기 위해서는, kakaopay를 문자열(값)으로 지정해 줘야겠죠!
-
✨퀴즈 풀어보기
- [퀴즈] Select 쿼리문, Where 절 연습하기
- 성이 남씨인 유저의 이메일만 추출하기
select email from users where name = "남**"; - Gmail을 사용하는 2020/07/12~13에 가입한 유저를 추출하기
select * from users where created_at between "2020-07-12" and "2020-07-14" and email like "%gmail.com"; - 이외 유용한 문법 연습하기
select count(*) from users where created_at between "2020-07-12" and "2020-07-14" and email like "%gmail.com";
- 성이 남씨인 유저의 이메일만 추출하기
✨끝 & 숙제 설명
- 📌 숙제
naver 이메일을 사용하면서,
웹개발 종합반을 신청했고
결제는 kakaopay로 이뤄진 주문데이터 추출하기select * from orders where email like '%naver.com' and course_title = '웹개발 종합반' and payment_method = 'kakaopay' ```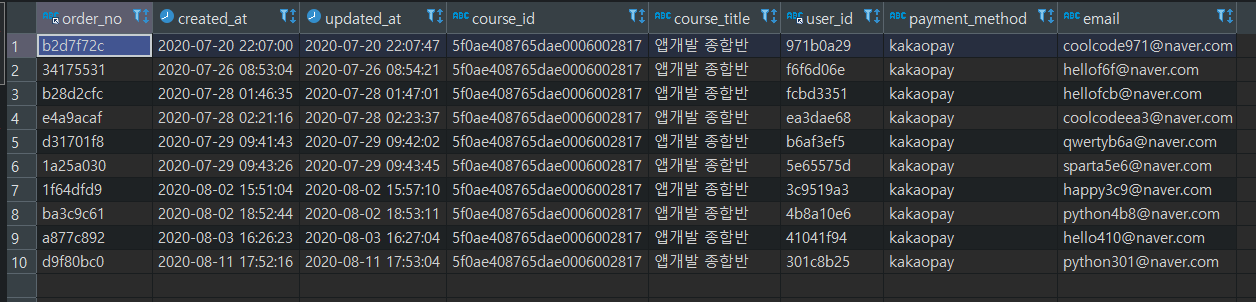
✨범주의 통계를 내주는 Group by
-
스파르타 회원: 성씨별로 몇 명의 회원이 있는지 알아보자
- 성씨별로 몇 명이 회원이 있는지 구하려고 where 절을 사용해서 수십개의 쿼리를 작성하는 것은 너무 비효율적입니다. 이 문제를 Group by를 사용해서 어떻게 해결할 수 있을까요?
select name, count(*) from users group by name;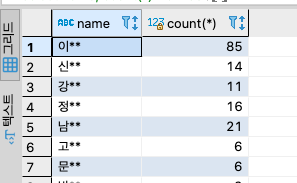
- from users: users 테이블에서 데이터를 불러옵니다
- group by name: name이라는 필드에서 동일한 값을 갖는 데이터를 하나로 합쳐줍니다
- select name, count(): 이름과 count()를 출력해 주는데, 여기서 count(*)는 group by로 합쳐진 데이터의 개수를 세어주는 것입니다!
- 성씨별로 몇 명이 회원이 있는지 구하려고 where 절을 사용해서 수십개의 쿼리를 작성하는 것은 너무 비효율적입니다. 이 문제를 Group by를 사용해서 어떻게 해결할 수 있을까요?
-
Group by 제대로 알아보기: SQL 쿼리가 실행되는 순서
select name, count(*) from users group by name;👉 위 쿼리가 실행되는 순서: from → group by → select
- from users: users 테이블 데이터 전체를 가져옵니다.
- group by name: users 테이블 데이터에서 같은 name을 갖는 데이터를 합쳐줍니다.
- select name, count(*): name에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 세어줍니다.
-
users 테이블 전체 불러오기
select * from users; -
users 테이블에서 '신' 씨를 가진 데이터만 불러와서 개수 살펴보기
select * from users where name = "신**"; -
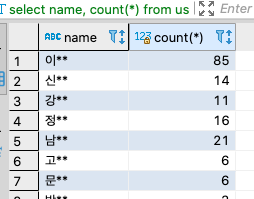
group by를 사용해서 '신'씨를 가진 데이터가 몇 개인지 살펴보기
select name, count(*) from users group by name;
✨Group by, Order by 사용해보기
-
Group by 기능 알아보기
💡 Group by는 동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내주는 것이라고 지난 시간에 배웠습니다. 이번 시간에는 Group by로 통계를 내는 기능을 알아볼까요? -
동일한 범주의 개수 구하기
- 주차별 '오늘의 다짐' 개수 구하기
select week, count(*) from checkins group by week;select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명 group by 범주별로 세어주고 싶은 필드명; - 동일한 범주에서의 최솟값 구하기
select week, min(likes) from checkins group by week; - 동일한 범주에서의 최댓값 구하기
select week, max(likes) from checkins group by week;select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명 group by 범주가 담긴 필드명; - 동일한 범주의 평균 구하기
select week, avg(likes) from checkins group by week;select 범주가 담긴 필드명, avg(평균값을 알고 싶은 필드명) from 테이블명 group by 범주가 담긴 필드명; - 동일한 범주의 합계 구하기
select week, sum(likes) from checkins group by week;select 범주가 담긴 필드명, sum(합계를 알고 싶은 필드명) from 테이블명 group by 범주가 담긴 필드명;
- 주차별 '오늘의 다짐' 개수 구하기
-
Order by로 앞의 결과를 정렬해보자
select name, count(*) from users group by name;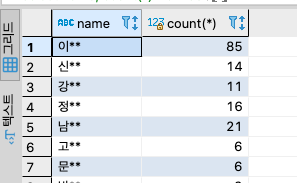
-
결과의 개수 오름차순으로 정렬해보기
select name, count(*) from users group by name order by count(*);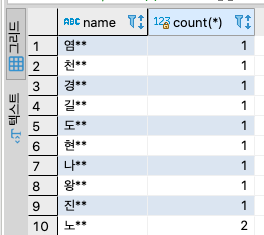
-
결과의 개수 내림차순으로 정렬해보기
select name, count(*) from users group by name order by count(*) desc;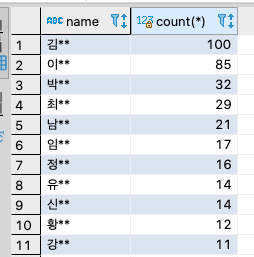
-
-
Order by 사용해보기
select * from checkins
order by likes desc;select * from 테이블명
order by 정렬의 기준이 될 필드명;-
Order by 제대로 알아보기: SQL 쿼리가 실행되는 순서
select name, count(*) from users group by name order by count(*);👉 위 쿼리가 실행되는 순서: from → group by → select → order by
-
Where와 Group by, Order by 함께 사용해보기
select payment_method, count(*) from orders where course_title = "웹개발 종합반" group by payment_method;💡 [순서]
- orders 테이블에서 주문 데이터를 읽어오고
- 웹개발 종합반 데이터만 남기고
- 결제수단(범주) 별로 그룹화하고
- 결제수단별 주문건수를 세어준다!
-
SQL 쿼리가 실행되는 순서
select payment_method, count(*) from orders where course_title = "웹개발 종합반" group by payment_method;👉 위 쿼리가 실행되는 순서: from → where → group by → select
-
from orders: users 테이블 데이터 전체를 가져옵니다.
-
where course_title = "웹개발 종합반": 웹개발 종합반 데이터만 남겨줍니다.
-
group by payment_method: 같은 payment_method을 갖는 데이터를 합쳐줍니다.
-
select payment_method, count(*): payment_method에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 세어줍니다.
예) CARD, CARD, kakaopay 이렇게 데이터가 있었다면, CARD는 2개, kakaopay는 1개겠죠!
-
✨같이 삽질해보기
-
왜 이런 결과가 나왔을까요?

💡
범주에 따른 통계치를 구하고 싶어 group by를 사용해 보았습니다.
하지만, 통계치는 나오지 않고 4개의 데이터만 출력된 것을 알 수 있죠.💡
범주별로 묶어달라는 명령어 (group by)는 작성해줬지만,
묶은 데이터를 '어떤 통계치'로 출력해달라는 명령어가 없어서 그렇습니다!💡
'어떤 통계치로' 출력해달라는 명령어를 추가하면 됩니다. 범주별 갯수를 세어볼까요? 아래와 같이요!
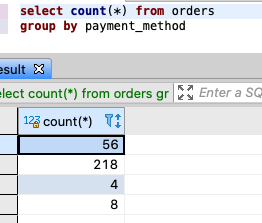
-
원하는 통계치가 나온 것 같지만 각각 어떤 범주에 대한 통계치인지는 나와있지 않아요.
당연한 것이, select 문 안에 count(*)만 적혀있어서 그렇겠죠?
-
그렇다면 group by에 들어간 필드를 똑같이 적어주면 됩니다. 깔끔하게 원하는 데이터가 잘 나오는걸 확인할 수 있습니다!
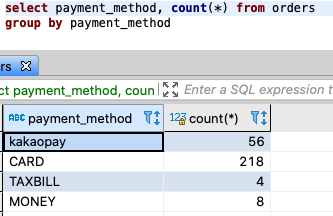
-
