티스토리에 저장했던 글을 옮겼습니다.
https://mrcocoball.tistory.com/51?category=1080971
3. DML (Data Manipulation Language)
(1) 정의
- 데이터
CRUD (생성, 읽기, 갱신, 삭제)및 검색을 하는데에 사용 SELECT,INSERT,DELETE,UPDATE문 등이 있음SELECT문은 특별히Query문(질의어)라고도 함
(2) 검색 : SELECT
- 특정 조건을 가진 속성을 테이블에서 검색하기
SELECT 속성명
FROM 테이블명
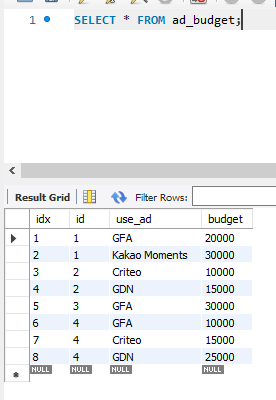
WHERE 검색조건; - 테이블 내 모든 속성 확인 SELECT * FROM 테이블명
- 예시
※ ad_budget 테이블에서 예산이 20000원 이상인 고객 아이디와 매체 검색
SELECT ID, use_ad
FROM ad_budget
WHERE budget >= 20000;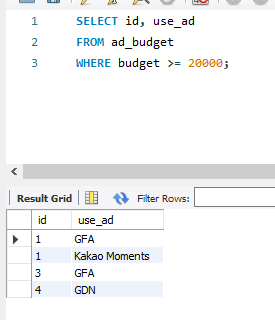
WHERE절에 조건으로 사용될 술어- 비교 : =,<>, <, <=, >, >=
- 범위 :
BETWEEN - 집합 :
IN,NOT IN - 패턴 :
LIKE - NULL :
IS NULL,IS NOT NULL - 복합조건 :
AND,OR,NOT
(3) 삽입 : INSERT, 테이블에 새로운 튜플을 삽입
- 테이블에 속성 삽입하기
INSERT INTO 테이블명(속성)
VALUES 속성; - 예시
※ ID = 5를 부여하여 '김쥐똥' 이라는 이름의 광고주를 추가
INSERT INTO client(ID, client_name)
VALUES ('5', '김쥐똥');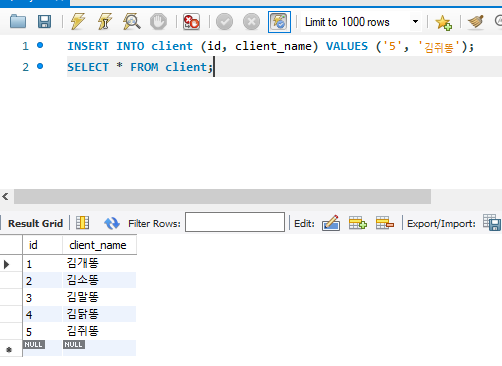
- 다른 테이블에서 속성 가져와 삽입하기
INSERT INTO 테이블명(속성)
SELECT 삽입할 속성
FROM 가져올 테이블명; (4) 갱신 : UPDATE, 특정 속성 값을 수정
- 특정 테이블의 특정 속성을 수정하기
UPDATE 테이블명
SET 수정하고 싶은 속성 = 수정할 속성 내용
WHERE 적용할 대상에 대한 조건; - 예시
※ 위에서 추가된 ID = '5'인 광고주의 이름을 김쥐똥에서 김뱀똥으로 바꾸려면
UPDATE client
SET client_name = '김뱀똥'
WHERE ID = '5';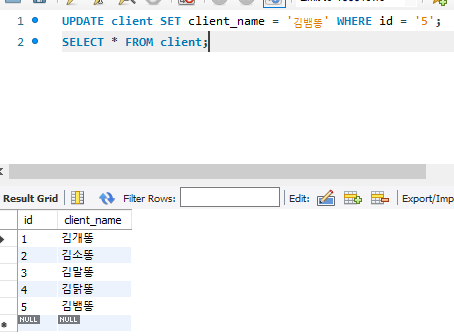
(5) 삭제 : DELETE, 테이블에 있는 기존 튜플을 삭제
- 테이블에서 특정 튜플 삭제
DELETE FROM 테이블명
WHERE 삭제 대상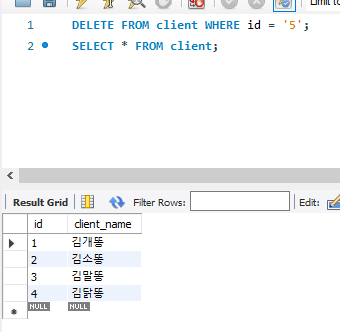
- ※ DROP은 아예 DB, 테이블, 컬럼 등을 완전히 없애버리는 것이고 DELETE는 데이터만 삭제함
(6) JOIN : WHERE를 이용
- 두 테이블의 속성과
WHERE를 사용하여 연산 - 예시
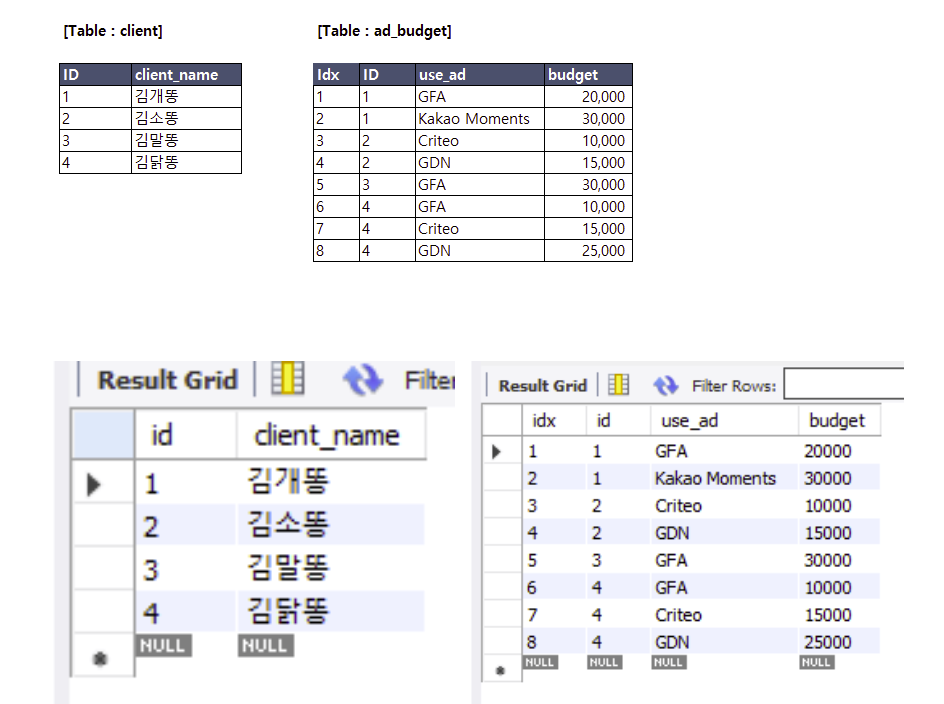
※ client 테이블의 광고주명과 ad_budget 테이블의 매체를 JOIN
(Foreign Key : ID)
SELECT client.client_name, ad_budget.use_ad
FROM client, ad_budget
WHERE client.ID = ad_budget.ID;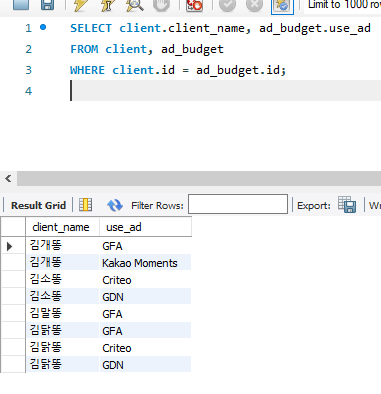
(7) JOIN : INNER JOIN 구문을 이용
- 두 테이블의 해당 필드 값, 속성이 매칭되는 (두 테이블의 모든 필드로 구성된) 레코드만 가져옴
- 조인하는 테이블의 ON 절의 조건이 일치하는 결과만 출력
FROM 테이블1
INNER JOIN 테이블2 ON 테이블1과 테이블2의 매칭 조건 - 예시
※ client 테이블과 ad_budget 테이블을 이용,
예산이 20000원이 이상인 매체를 가진 광고주명과 매체명, 예산을 표시
SELECT client.client_name, ad_budget.use_ad, ad_budget.budget
FROM client
INNER JOIN ad_budget ON client.ID = ad_budget.ID
WHERE ad_budget.budget >= 20000;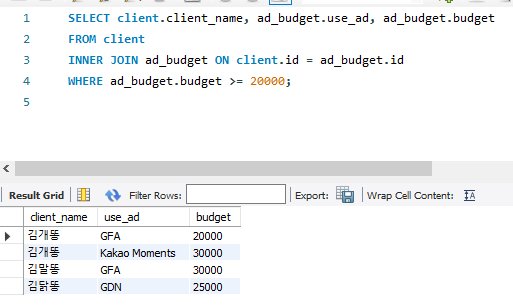
(8) 부속질의 (Subquery)
- SQL 문 안에 포함되어 있는 SQL 문, 테이블과 테이블 간 검색 시 검색 범위를 좁힐 때 주로 사용
- 상관 부속질의 (Correlated subquery) 는 상의 부속질의의 튜플을 이용하여 하위 부속질의를 계산
- 상위 부속질의와 하위 부속질의가 독립적이지 않고 서로 관련을 맺고 있음
- 예시
※ client 테이블과 ad_budget 테이블을 이용,
예산이 20000원이 이상인 매체를 가진 광고주 이름 출력
SELECT client_name
FROM client
WHERE ID IN (SELECT ID
FROM ad_budget
WHERE ad_budget.budget >= 20000);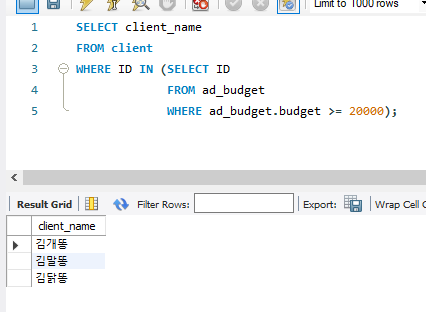
(9) EXISTS
- 조건에 맞는 튜플이 존재하면 결과에 포함시킴
- 부속질의문의 어떤 행이 조건에 만족하면 참
(10) 집계 함수
SUM(): 컬럼 값의 합계,SUM(budget)AVG(): 컬럼 값의 평균,AVG(budget)MAX(): 최대 컬럼 값,MAX(budget)MIN(): 최소 컬럼 값,MIN(budget)COUNT(): 검색 결과의 row 수를 가져올 수 있음
※ 예산(budget) 이 2만원을 넘는 건수를 모두 세려면
SELECT COUNT(budget)
FROM ad_budget
WHERE budget > 20000;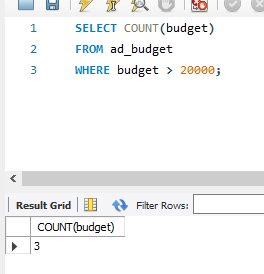
(11) GROUP BY
- 그룹을 지어서 데이터를 분석하고자 할 때 사용
- 집계 함수와 같이 사용할 경우 각 그룹별로 집계할 수 있음
※ 매체별 (use_ad) 예산 평균을 구하려면
SELECT use_ad, AVG(budget)
FROM ad_budget
GROUP BY use_ad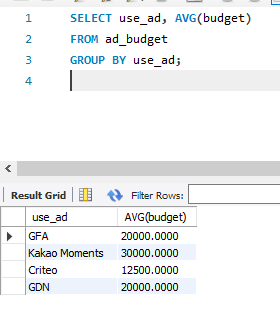
(12) GROUP BY와 HAVING 조건
HAVING은 집계 함수를 가지고 조건 비교를 할 때 사용되며GROUP BY와 같이 사용
※ 매체별 예산 평균이 20000원을 넘는 매체와 평균 예산을 구하려면
SELECT use_ad, AVG(budget)
FROM ad_budget
GROUP BY use_ad
HAVING AVG(budget) > 20000;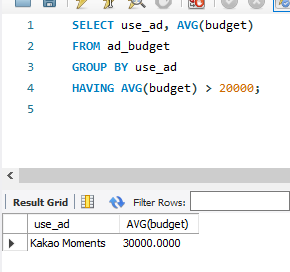
(13) GROUP BY와 DISTINCT
DISTINCT는 특정 컬럼 값 출력 시 중복된 값을 출력하지 않음
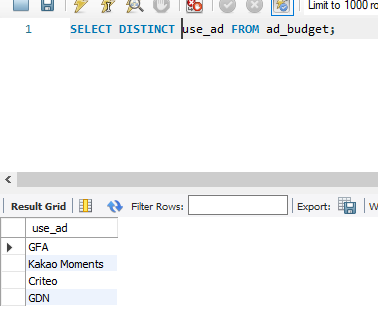
※ 이용 매체 종류를 중복없이 구하려면
SELECT DISTINCT use_ad FROM ad_budget GROUP BY는 집계 함수를 사용하여 특정 그룹으로 구분 할 때 사용DISTINCT는 특정 그룹 구분 없이 중복된 데이터를 제거
(14) AS
- 특정 결과값의 이름을 변경하는 방법
※ 매체별 예산 평균을 'ad_budget_average' 라는 이름으로 지정하여 가져오려면
SELECT use_ad, AVG(budget) AS ad_budget_average
FROM ad_budget
GROUP BY use_ad;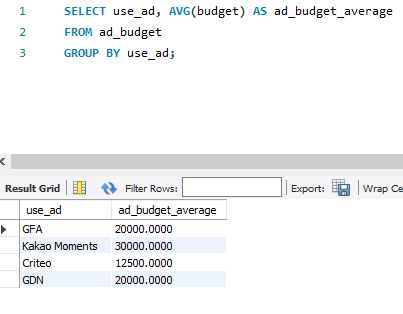

공부했던 내용들을 모아둔 창고입니다.