
인덱스 기본
인덱스 구조 및 탐색
미리 보는 인덱스 튜닝
데이터를 찾는 두 가지 방법
- 테이블 전체 스캔
- 인덱스 이용
- 테이블 전체 스캔에 관련해서는 튜닝 요소가 많지 않지만 인덱스는 튜닝이 필요하고 기법도 다양함
인덱스 튜닝의 두 가지 핵심 요소
- 인덱스는 큰 테이블에서 소량의 데이터를 검색할 때 사용하기에 인덱스 튜닝 중요
인덱스 스캔 효율화 튜닝: 인덱스 스캔 과정에서 발생하는 비효율 제거랜덤 액세스 최소화 튜닝: 테이블 액세스 회수를 줄이는 것- 둘 다 중요하지만 특히 랜덤 액세스 최소화 튜닝이 미치는 영향이 큼
SQL 튜닝은 랜덤 I/O와의 전쟁
- 데이터베이스 성능은 디스크 I/O에서 결정
인덱스 구조
- 인덱스: 대용량 데이터 테이블에서 필요한 데이터만 빠르게 효율적으로 액세스하기 위해 사용되는 오브젝트
- 인덱스를 사용하면 데이터 전체가 아닌 일부만 읽고 멈추는
범위 스캔이 가능
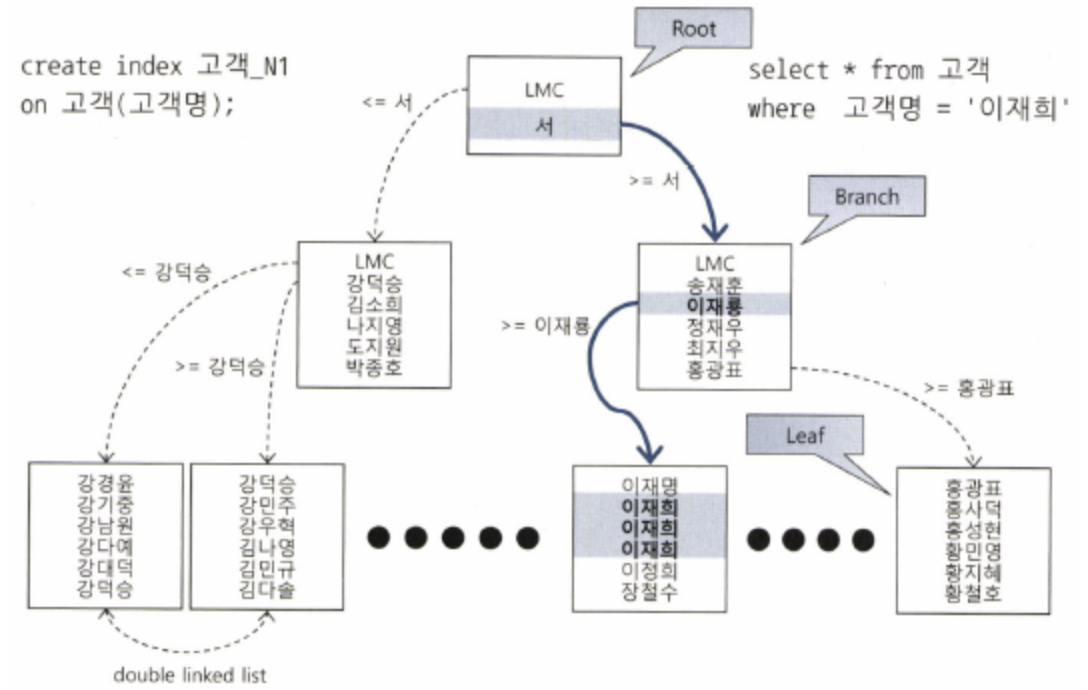
- DBMS는 기본적으로
B Tree Index사용- 나무를 거꾸로 뒤집은 모양으로 Root가 위에 있고 Leaf가 밑에 있음
- LMC: Leftmost Child
- LMC는 키값을 가지지 않는 특별한 레코드
- LMC가 가리키는 주소로 가면 다음 블록의 첫 번째 레코드 저장
- 리프 블록에 저장된 각 레코드는 키값 순으로 정렬돼 있으며 테이블 레코드를 가리키는 주소값 ROWID를 가짐
- 인덱스 키값이 같으면 ROWID 순으로 정렬
- 인덱스를 스캔하는 이유는 검색 조건을 만족시키는 소량의 데이터만 스캔하기 위함
- ROWID는 다음과 같이 구성
- ROWID = 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소 = 데이터 파일 번호 + 블록 번호
- 블록 번호: 데이터 파일 내에서 부여한 상대적 순번
- 로우 번호: 블록 순번
- 인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 구성
- 수직적 탐색: 인덱스 스캔 시작 지점을 찾는 과정
- 수평적 탐색: 데이터를 찾는 과정
인덱스 기본 사용법
인덱스를 사용한다는 것
- 인덱스 컬럼을 가공하지 않고 사용하는 것
- 리프 블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것
- 리프 블록 일부만 스캔하는 Index Range Scan
인덱스를 Range Scan할 수 없는 이유
인덱스 커럼을 가공하면 인덱스를 정상적으로 사용(Range Scan)할 수 없다- 인덱스 컬럼을 가공했을 때 인덱스를 정상적으로 사용할 수 없는 이유는
인덱스 스캔의 시작 지점을 찾을 수 없기 때문 - 수직적 탐색이 어려움
- 리프 블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈추는 것이 불가능
더 중요한 인덱스 사용 조건
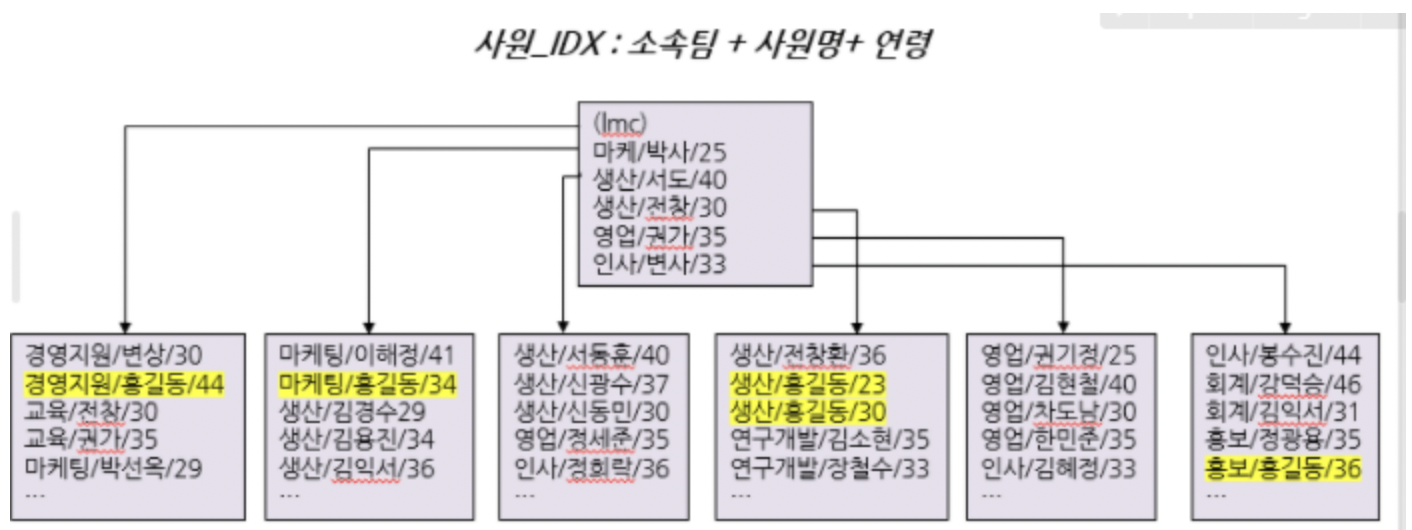
- 인덱스를 [소속팀 + 사원명 + 연령] 순으로 구성한다고 가정
- 사원명 = ‘홍길동’ 조건을 만족하는 데이터는 리프 블록 전 구간에 흩어짐
- 인덱스 스캔 시작 지점과 스캔 종료 지점 모두 찾을 수 없어 전부 스캔해야 함
- 인덱스를 Range Scan하기 위한 첫 번째 조건은
인덱스 선두 컬럼이 조건절에 있어야 함 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있으면 인덱스 Range Scan은 무조건 가능
인덱스를 이용한 소트 연산 생략
- 인덱스를 Range Scan할 수 있는 이유는 데이터가 정렬되어 있기 때문
- 이미 인덱스로 정렬되어 있는 데이터에 대해서는 ORDER BY를 사용해도 실행하지 않음
- 인덱스로 소트 연산 생략
ORDER BY 절에서 컬럼 가공
| 장비번호 | 변경일자 | 변경순번 |
|---|---|---|
| … | … | … |
| B | 20180505 | 031583 |
| … | … | … |
- 조건절이 아닌 ORDER BY 혹은 SELECT-LIST 에서 컬럼을 가공함으로 인해 인덱스가 정상적으로 작동되지 않는 경우가 있음
- PK 인덱스를 [장비번호 + 변경일자 + 변경순번] 순으로 구성했다고 가정
SELECT *
FROM 상태변경이력
WHERE 장비번호 = 'C'
ORDER BY 변경일자 || 변경순번- 위와 같은 코드는 정렬 연산을 생략할 수 없음
- 인덱스에는 가공되지 않은 상태로 값을 저장했는데 가공한 값 기준의 정렬을 요구하기 때문
SELECT-LIST 절에서 컬럼 가공
- MIN, MAX에서도 인덱스 값을 따라 제일 첫 번째 값, 마지막 값만 읽으면 되기에 정렬 연산이 생략되는 경우가 있음
SELECT NVL(MAX(TO_NUMBER(변경순번)), 0)
FROM 상태변경이력
WHERE 장비번호 = 'C' AND 변경일자 = '20180316'- 위와 같은 코드는 정렬 연산을 생략할 수 없음
- 인덱스는 문자열 기준으로 정렬되어 있는데 이를 숫자값으로 바꾼 순번을 요구했기 때문
자동 형변환
- 오라클에서는 문자형과 숫자형이 만나면 숫자형으로 자동적으로 형변환
- 날짜 포맷도 정확하게 지정해 주는 습관 필요
- 연산자가 LIKE일 때는 문자형으로 자동 변환
- 형변환 연산 횟수를 줄이는 것보다 블록 I/O를 줄이는 튜닝에 초점
인덱스 확장 기능 사용법
Index Range Scan
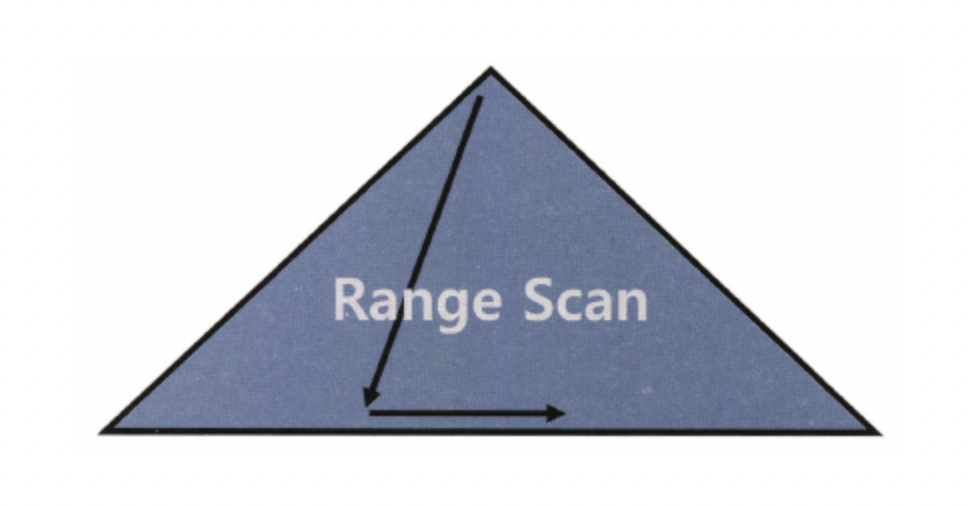
- B-Tree 인덱스의 가장 일반적인 방식
- 인덱스 루트에서 리프 블록까지 수직적으로 탐색한 뒤 필요한 범위까지 수평적으로 탐색
- 선두 컬럼을 가공하지 않은 상태로 조건절에 사용
Index Full Scan
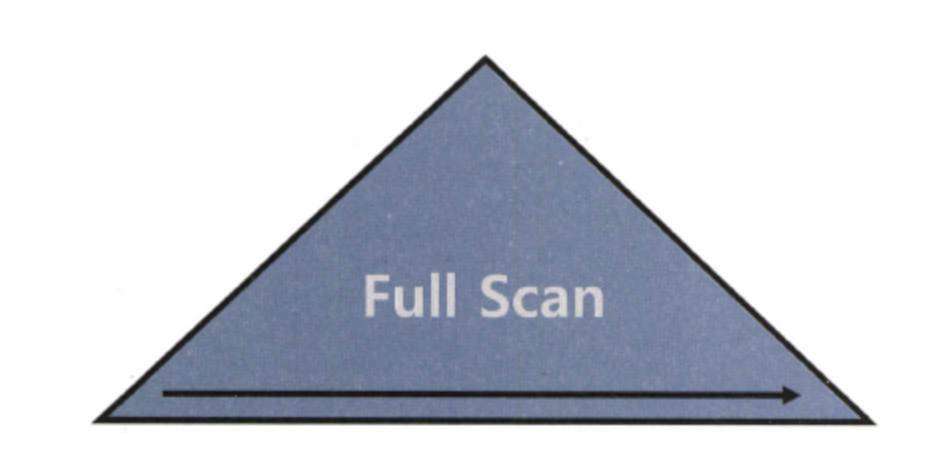
- 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방법
- 데이터 검색을 위한 최적의 인덱스가 없을 때
Index Full Scan의 효용성
- table full scan보다는 index full scan이 훨씬 효율적이기 때문에 인덱스를 사용
- 인덱스를 통한 소트 연산 생략 가능
Index Unique Scan
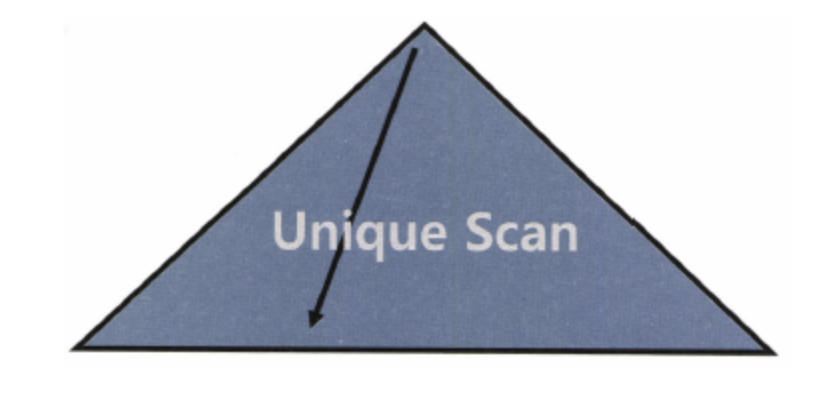
- 수직적 탐색으로만 데이터를 찾는 스캔 방식
- 결합 인덱스에 대해서 모든 인덱스에 대해 등호로 검색했을 때 발생
Index Skil Scan
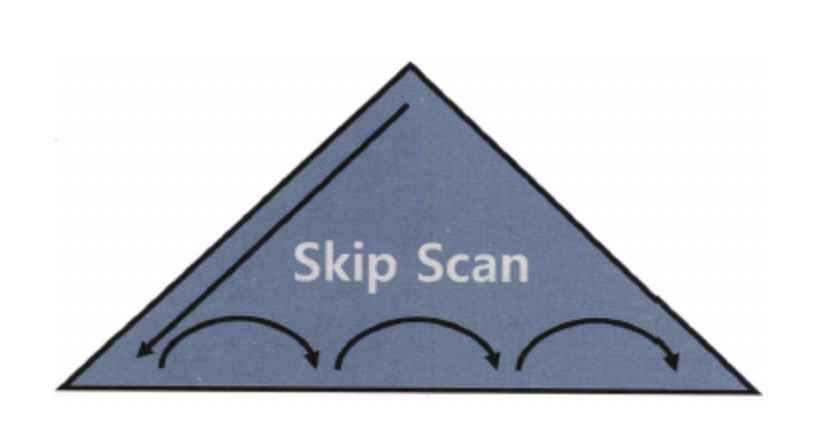
- 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유용
- Distinct Value: Column에 Unique 값이 얼마나 존재하는지
- Index Range Scan이 불가능하거나 효율적이지 못한 상황에서 발생
예시
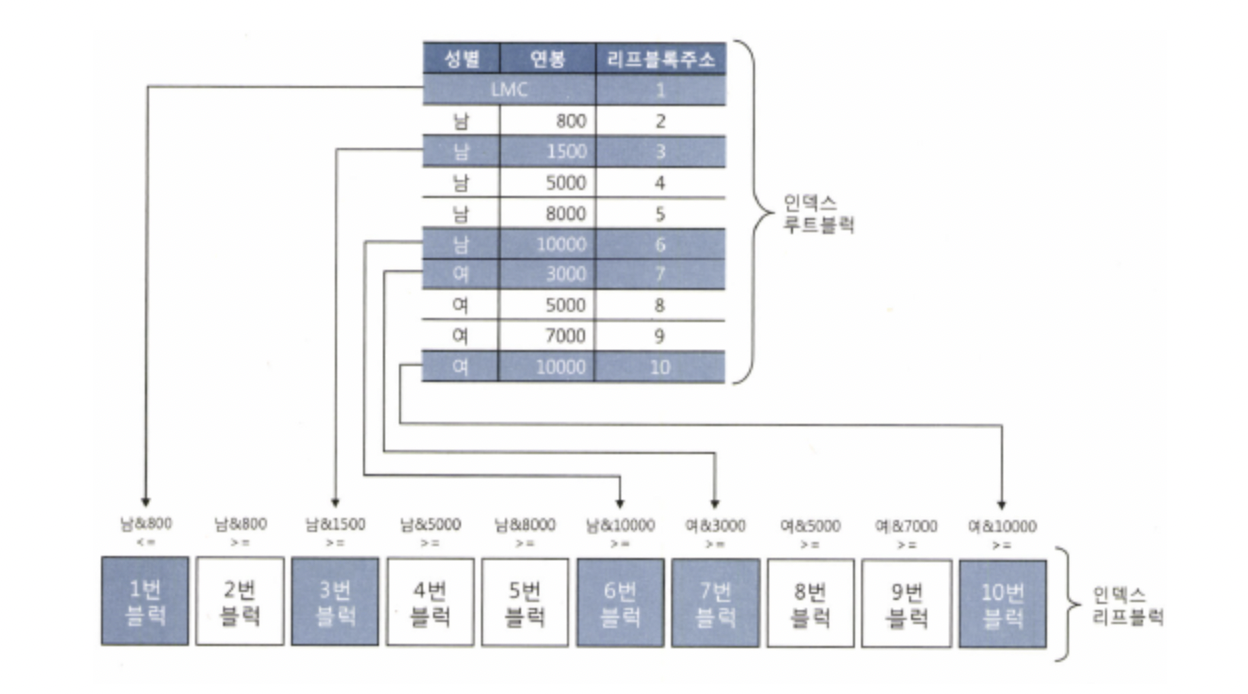
SELECT *
FROM 사원
WHERE 연봉 BETWEEN 2000 AND 4000- 성별 ≤ 남인 칼럼이 있을 까 봐 리프 블록 1 접근
- 성별이 남이면서 연봉 ≥ 800인 두 번째 리프 블록은 SKIP
- 성별이 남이면서 연봉 ≥ 1500인 세 번째 리프 블록 접근
- 성별이 남이면서 연봉 ≥ 5000, 연봉 ≥ 8000인 리프 블록 SKIP
- 성별이 남이면서 연봉 ≥ 10000인 리프 블록 6은 성별이 여자인 데이터가 있을지 모르니 접근
- 성별이 여이면서 연봉 ≥ 5000, 연봉 ≥ 7000인 리프 블록은 SKIP
- 성별이 여이면서 연봉 ≥ 10000인 리프 블록은 다음 성별이 있을지도 모르니 접근
Index Fast Full Scan
- Index Full Scan보다 빠른 스캔
- 논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock I/O로 스캔하기 때문
- 디스크로부터 대량의 인덱스 블록을 읽어야 할 때 유용
- 속도는 빠르지만 연결리스트 구조를 무시한 채 읽기 때문에 인덱스 . 키순서대로 정렬되지 않음
- 인덱스가 파티션돼 있지 않더라도 병렬 쿼리가 가능
| Index Full Scan | Index Fast Full Scan |
|---|---|
| 인덱스 구조를 따라 스캔 | 세그먼트 전체를 스캔 |
| 결과집합 순서 보장 | 결과집합 순서 보장 안 됨 |
| Single Block I/O | Multiblock I/O |
| 병행 스캔 불가능 | 병행 스캔 가능 |
| 인덱스에 포함되지 않은 컬럼 조회에 사용 가능 | 인덱스에 포함된 컬럼으로만 조회할 때 사용 |
Index Range Scan Descending
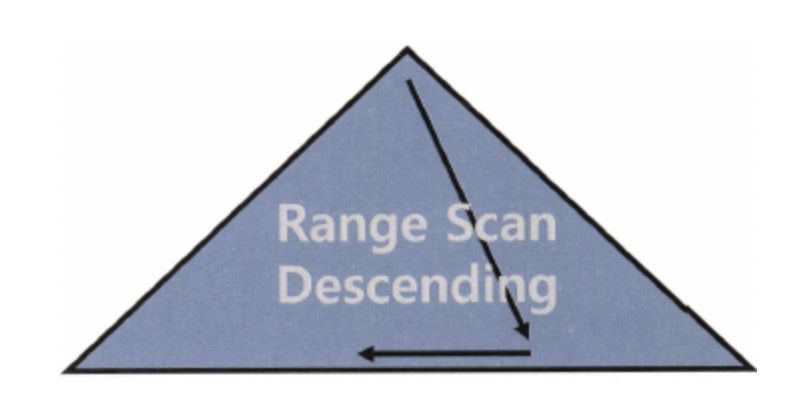
- 인덱스를 앞쪽부터 스캔하기 때문에 내림차순으로 정렬된 결과 집합을 읽음
