JAVA GC
Garbage Collection
- 프로그램을 개발하다 보면 유효하지 않은 메모리인 가비지가 발생하게 됨
- C의 경우 직접 메모리를 해제해 줘야 하지만 java를 이용한다면 개발자가 직접 메모리를 해제하는 경우는 없음
- JVM의 가비지 컬렉터가 불필요한 메모리를 알아서 정리해 주기 때문
- GC의 관리 대상은 힙 영역
- GC를 수동으로 수행할 수 있지만 권장하지 않음
Object.finalize()
- 특정 객체에 대해 참조가 더 이상 없다고 판단할 때 가비지 컬렉션이 호출하는 함수
- 시스템 리소스를 삭제
- GC는 JVM 구현마다 다르기 때문에 finalize를 호출해도 언제 수행되는지 알 수 없음
- 따라서 중요한 리소스를 애플리케이션 실행 중에 해제해 버릴 위험이 있음
- 발생해도 재현하기 쉽지 않아 디비깅에 어려움
- finalize가 호출되지 않은 채로 애플리케이션이 종료될 수 있음
- finalize에서 발생하는 예외는 무시되며 스택 트레이스로도 표시되지 않음
Minor GC와 Major GC
- JVM의 Heap 영역은 처음 설게될 때 다음과 같은 전제를 기반으로 설계
- 대부분의 객체는 금방 접근 불가능한 상태가 됨
- 오래된 객체에서 새로운 객체로의 참조는 아주 적게 존재
- 객체는 대부분 일회성이며 메모리에 오랫동안 남아 있는 경우는 드묾
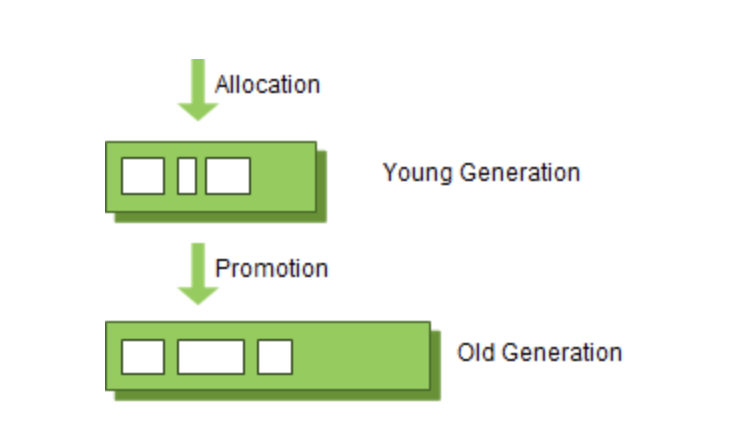
- Young 영역
- 새롭게 생성된 객체가 할당되는 영역
- 대부분의 객체가 금방 접근 불가능한 상태가 되기 때문에 많은 객체가 Young 영역에 생성되었다가 사라짐
- Young 영역에 대한 가비지 컬렉션을 Minot GC라고 부름
- Old 영역
- Young 영역에서 Reachable 상태를 유지하여 살아남은 객체가 복사되는 영역
- Young 영역보다 크게 할당되며 영역의 크기가 큰 만큼 가비지는 적게 발생
- Old 영역에 대한 가비지 컬렉션을 Majot GC라고 부름
equals() hashcode()
equals()
- 2개의 객체가 동일한지 검사하기 위해 사용
- 2개의 객체가 참조하는 것이 동일한지를 확인
- 동일성을 비교
- 2개의 객체가 가리키는 곳이 동일한 메모리 주소일 경우
hashcode()
- 실행 중에 객체의 유일한 integer 값 반환
- 기본적으로 heap에 저장된 객체의 메모리 주소를 반환하도록 되어 있지만 재정의 가능
equals와 hashcode
- 동일한 객체는 동일한 메모리 주소를 갖는다는 것을 의미
- 동일한 객체는 동일한 해시코드를 가져야 함
- 따라서 equals 메소드를 재정의한다면 hashcode도 재정의가 필요함
- 두 객체가 equals()에 의해 동일하다면 두 객체의 hashCode()도 동일해야 함
- 두 객체가 equals()에 의해 동일하지 않다면, 두 객체의 hashCode() 값은 일치하지 않아도 됨
- 하지만 hashTable 생성에 불이익을 가질 수도 있음
IoC와 DI
IoC
- Inversion of Control
- 제어의 역전
- 할리우드 원칙: 로미오는 줄리엣을 맡은 배우가 누구인지 몰라도 되고 영화 제작자만 알고 있으면 됨
- 일반적인 프레임워크는 객체의 생명 주기 (생성, 초기화, 소멸, 메서드 호출)등을 클라이언트 객체가 직접 관리
- 이러한 생명 주기를 직접 관리하지 않는 경우
- Controller, Service 같은 객체들의 동작을 우리가 직접 구현하기는 하지만 어느 시점에 호출될지 신경 쓰지 않는 것
- 프로그램의 제어권이 프레임워크로 역전되는 현상
- 템플릿 메소드 패턴: 알고리즘의 구조를 메서드에 정의하고 하위 클래스에서 알고리즘 구조의 변경 없이 알고리즘을 재정의하는 경우
- 프로그램의 흐름과 구체적인 구현 분리 가능
- 개발자가 비즈니스 로직에 집중 가능
- 구현체 사이의 변경 용이
- 의존성 하락
Dependenct Injection
- 의존성 주입으로 제어의 역전을 실행하는 여러 가지 방법 중 하나
- 프로그램의 제어권을 역전시키기 위해 사용하는 디자인 패턴 중 하나이지, 의존성 주입과 완벽하게 같은 개념이 아님
- 프로그램끼리는 인터페이스끼리만 의존해야 하며, 구체적인 구현체를 명시하는 순간 객체지향이 깨지게 됨
- 하지만 구체적인 구현체가 없다면 null point exception으로 프로그램이 진행되기 어려움
- 이러한 문제를 해결하기 위해 외부에서 실질적인 구현체를 만든 뒤 주입해 주는 형식
- 연극은 로미오와 줄리엣이라는 인터페이스만 참고하고 있고, 외부라는 제작자가 구체적인 구현체인 로미오 배우 역, 줄리엣 배우 역을 캐스팅하는 과정
- 의존성 주입에는 생성자 주입, Setter 주입, Interface 주입이 있음
public class A {
private B b;
public A(B b) {
this.b = b;
}
}
public class A {
private B b;
public void setB(B b) {
this.b = b;
}
}
public interface BInjection {
void inject(B b);
}
public A implements BInjection {
private B b;
@Override
public void inject(B b) {
this.b = b;
}
}
DI의 장점
- 클래스 모델이나 코드에는 런타임 시점의 의존 관계가 드러나지 않고 인터페이스만 의존하고 있기 때문에 변경에 용이
- 런타임 시점의 의존 관계는 컨테이너나 팩토리 같은 외부의 존재가 결정 → 의존의 역전 발생
- 단위 테스트에서 스텁 또는 모의 구현이 더욱 간편해짐 → 모의 객체를 주입할 수 있기 때문
- 테스트하고자 하는 기능이 있을 때마다 구현체를 하나하나 다 바꿀 필요가 없음
- 가독성과 재사용성의 향상
DispatcherServlet
DispatcherServlet
- HTTP 프로토콜로 들어오는 모든 요청을 가장 먼저 받아 적합한 컨트롤러에 위임해 주는 프론트 컨트롤러
- 클라이언트로부터 요청이 오게 되면 가장 먼저 받게 되는 프론트 컨트롤러
- 요청을 받으면 공통적인 작업을 먼저 처리한 후에 해당 요청을 처리해야 하는 컨트롤러를 찾아서 작업을 위임
- 과거에는 모든 서블릿을 URl 매핑을 위해 web.xml에 모두 등록해 줘야 했지만, dispatchServlet이 해당 앱으로 들어오는 모든 요청을 핸들링해 주고 공통 작업을 처리하면서 과정이 간소화됨
정적 자원 요청
- 정적 자원까지 모두 가로채서 static 요소를 불러오지 못하는 상황 발생
- Dispatch Servlet이 요청을 처리할 컨트롤러를 먼저 찾음
- 요청에 대한 컨트롤러를 찾을 수 없는 경우 2차원적으로 설정된 자원 경로를 탐색하여 자원 반환
DispatcherServlet 동작 과정

- 클라이언트의 요청을 디스패처 서블릿이 받음
- 웹 컨텍스트에서 필터들을 지나 스프링 컨텍스트에서 DispatcherServlet이 가장 먼저 요청을 받음

- 요청 정보를 통해 요청을 위임할 컨트롤러를 찾음
HandlerMapping을 통해 어떤 컨트롤러가 요청을 처리할 수 있는지 식별- 컨트롤러도 다양하게 구현할 수 있기 때문에
HandlerMapping 역시 인터페이스로 만들어 두고 컨트롤러에 맞게 구현
- 현재 @Controller는
RequestMappingHandlerMapping가 처리 → 해시맵으로 <요청 정보, 처리 대상>을 관리
- 요청을 컨트롤러로 위임할 핸들러 어댑터를 찾아서 전달함
- 컨트롤러로 요청을 직접 위임하는 것이 아닌
HandlerAdapter를 통해 위임
- 핸들러 어댑터가 컨트롤러로 요청을 위임함
- 비지니스 로직을 처리함
- 컨트롤러가 반환값을 반환함
- 핸들러 어댑터가 반환값을 처리함
HandlerAdapter는 컨트롤러로부터 받은 응답을 응답 처리기인 ReturnValueHandler가 후처리한 후에 디스패치 서블릿으로 돌려줌- 응답이
ResponseEntity인 경우 HttpEntityMethodProcessor가 MessageConverter를 사용해 응답 객체 직렬화
- 응답이
View일 경우 ViewResolver를 통해 반환
- 서버의 응답을 클라이언트로 반환함
DispathcerServlet은 처음 init되는 과정에서 여러가지 handlerMapping들을 등록하고 List를 통해 handlerMappings라는 이름으로 관리하고 있다. handelrMappings안에는 여러가지 handlerMapping들이 등록되어 있는 것이다.
DispathcerServlet은 각 요청을 독립적으로 처리하지만 서블릿 컨테이너에서 스레드 풀을 사용하여 여러 클라이언트 요청을 동시에 처리할 수 있다. 각 요청은 별도의 스레드에서 처리된다.
JPA와 같은 ORM을 사용하는 이유
JPA Start
- 가장 많이 사용하는 관계형 데이터베이스는 데이터를 테이블의 형태로 관리
- JAVA에서는 데이터를 객체를 통해 관리
- 우리가 객체 지향 언어를 쓰고 객체를 정의해서 쓰고 있는데, 객체 정보를 담고 있는 데이터베이스는 표현이 매우 어렵기 때문에 JPA가 시작
- ORM(Object Relational Mapping)
- 객체지향적 관점에서 객체를 사용하여 관계형 데이터베이스를 사용하는 기술이다. 객체를 테이블 및 레코드에 매핑해 주는 것
- 데이터베이스와 직접 소통하는 여지를 줄여 주는 것
JPA & Hibermate
JPA는 Java Persistence API로 ORM 기술이 아닌 객체를 꾸며 주는 용도의 Annotation으로 구성되는 라이브러리- 즉 데이터가 어떻게 테이블에 매핑되는지 명세하기 위한
Interface와 Annotation으로 구성
- 이를 실제로 테이블로 옮겨 주는 역할은
Hibernate
- JPA 명세를 바탕으로 작동하는 ORM 프레임워크
- JPA가 ORM을 위한 기초 단계라면 Hibernate가 실제로 그 일을 동작
영속성 컨텍스트
- 영속성 컨텐스트란
엔티티를 영구 저장하는 환경
- 애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할
- 엔티티 매니저를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리
- 엔티티 매니저를 생성할 때 하나 만들어짐
- 엔티티 매니저를 통해서 영속성 컨텍스트에 접근하고 관리
N + 1 Problem
- ORM 기술에서 특정 객체를 대상으로 수행한 쿼리가 해당 객체가 가지고 있는 연관관계 또한 조회하게 되면서 N번의 추가적인 쿼리가 발생하는 문제
- 관계형 데이터베이스와 객체지향 언어간의 패러다임 차이로 인해 발생
- 객체는 연관관계를 통해 레퍼런스를 가지고 있으면 언제든지 메모리 내에서 Random Access를 통해 연관 객체에 접근할 수 있지만 RDB의 경우 Select 쿼리를 통해서만 조회
- Eager Loading은 연관된 Entity 객체를 한번에 조회하도록 하는 기능으로 특정 경우에 N+1 문제를 부분적으로 해결해 줄 수 있지만 사용하지 않는 것이 좋음
- 어떤 Entity 연관관계 범위까지 Join 쿼리로 조회해올지 예상하기가 힘들어지기 때문에 오히려 필요없는 데이터까지 로딩하여 비효율적
@Transactional
@Transactional
- 데이터베이스 관리 시스템 또는 유사한 시스템에서 상호작용의 단위
- 여기서 유사한 시스템이란 트랜잭션이 성공과 실패가 분명하고 상호 독립적이며, 일관되고 믿을 수 있는 시스템을 의미
- 데이터의 정합성을 보장하기 위해 고안된 방법
- 오류로부터 복구를 허용하고 데이터베이스를 일관성있게 유지하는 안정적인 작업 단위를 제공
- 동시 접근하는 여러 프로그램 간 격리를 제공
Transaction 과정
- 트랜잭션 시작
- 비즈니스 로직 실행(여러 쿼리들이 실행) (DB내 갱신이 아직 적용되지 않는다)
- 트랜잭션 커밋 (트랜잭션이 성공적이며, 갱신이 실제 적용됨)
readOnly
- 이는 JPA의 영속성 컨텍스트(Persistence Context)가 수행하는 변경 감지(Dirty Checking)와 관련
- 영속성 컨텍스트는 Entity 조회 시 초기 상태에 대한 Snapshot을 저장
- 트랜잭션이 Commit 될 때, 초기 상태의 정보를 가지는 Snapshot과 Entity의 상태를 비교하여 변경된 내용에 대해 update query를 생성해 쓰기 지연 저장소에 저장
- 그 후, 일괄적으로 쓰기 지연 저장소에 저장되어 있는 SQL query를 flush 하고 데이터베이스의 트랜잭션을 Commit 함으로써 우리가 update와 같은 메서드를 사용하지 않고도 Entity 수정→ 변경 감지(Dirty Checking)
- 이 때, readOnly = true를 설정하게 되면 스프링 프레임워크는 JPA의 세션 플러시 모드를 MANUAL로 설정
- MANUAL 모드는 트랜잭션 내에서 사용자가 수동으로 flush를 호출하지 않으면 flush가 자동으로 수행되지 않는 모드
- 트랜잭션 내에서 강제로 flush()를 호출하지 않는 한, 수정 내역에 대해 DB에 적용되지 않음
- 이로 인해 트랜잭션 Commit 시 영속성 컨텍스트가 자동으로 flush 되지 않으므로 조회용으로 가져온 Entity의 예상치 못한 수정을 방지
- readOnly = true를 설정하게 되면 JPA는 해당 트랜잭션 내에서 조회하는 Entity는 조회용임을 인식하고 변경 감지를 위한 Snapshot을 따로 보관하지 않으므로 메모리가 절약되는 성능상 이점

