Infinite Scroll & CSR & SSR

모든 코드에 의미를 담겠습니다.
지금 내가 구현하는 기능중에 꽤나 유용했고 알아두면 좋은 기능들을 정리하면서 개발일지에 한번 정리해보려고 한다.
그런것들은 위와 같이 유레카 이미지가 들어가 있고, TIL과는 다른 개발일지로 구분이 될 것 같다.
오늘의 유레카!!!
무한 스크롤(Infinite) & CSR & SSR 부분.
무한스크롤...
이 부분은 내가 쓰게 된 이유에 대해서 고민하게 되었다. 왜 굳이?? 써야하는가? 그냥 데이터를 한번에 받아와서 특정 height를 주고 overflow: hidden을 app_tsx파일 전체에 적용을 하면, 나머지 데이터들은 스크롤을 내릴 때 받아오지 않는가?
당연히 이런 방법도 작은 서비스의 회사이거나 아니면 뿌려줄 데이터 양이 적을 경우에는 좋다. 하지만, 한번에 백엔드를 통해 받아와야하는 데이터의 양이 페이스북 같은 거대기업이라면? 그런 회사가 아니더라도 데이터를 한번에 뿌려줄때 서버사이드에서 부담이 되는 곳이라면 무한스크롤을 사용해야 한다.
무한 스크롤 동작원리
백엔드 쪽에서 보통 무한 스크롤 및 다양한 Pagination 활용을 위해서 보통 page별로 데이터를 나누고 한 페이지에는 10개 혹은 6개 정도의 데이터가 들어간다.
데이터를 받고나서 처음에는 page 1번의 데이터를 먼저 뿌려주고 Apollo-graphql기준으로는 fetchMore 그리고 updateQuery 함수를 써서 데이터를 다보여주고 해당 데이터를 추가로 보여준다.
코드를 통해 살펴보자.
const [page, setPage] = useState(1) //백엔드에 request할때 페이지 숫자
const onLoadMore = () => {
if(!commentData) return
if(commentData?.fetchBoardComments?.length % 10 !== 0) return
fetchMore({
variables: {
boardId: String(router.query._id),
page: Math.floor(commentData?.fetchBoardComments.length /10) + 1
},
updateQuery: (prev, { fetchMoreResult }) => {
const aaa = Object.assign({}, prev, {
fetchBoardComments: [
...prev.fetchBoardComments,
...fetchMoreResult.fetchBoardComments
]
})
return aaa
}
})여기서 중요한점은 onLoadMore 안에 함수에서 최대한 setState를 사용하지 않고 풀어나가야 한다. 이유는 정확하게 아직 파악하지 못했는데 라이브러리의 함수와 꼬여서 원하는 값을 정확히 반환하지 못한다 (아시는 분은 이유좀...)
Infinite Scroll의 return 부분은 library를 사용해서 특별히 다를 건 없다.
무한 스크롤을 사용하는 이유와 그 원리를 조금 이해한것 같아서 기쁘다. 시간이 된다면, infinite scroll 구현을 직접 모달창과 함께 해보고 싶은 마음이다.
클라이언트 사이드 렌더링 vs 서버 사이드 렌더링
이 두 렌더링은 항상 나오는 이야기인것 같다. 서버 사이드 렌더링은 데이터에 변화가 있을 때마다 응답을 받아와줘서 컴포넌트를 다시 그리는 형태이다.
서버사이드는 렌더링은 보통 데이터 변경이 필요해서 통신을 할 때를 제외하고는 나머지 부분들은 클라이언트 사이드 렌더링에서 해결을 하는게 좋다.
서버에 요청을 최대한 많이 하지않는 프론트엔드 개발자가 좋은 개발자다!!!!
서버사이드 렌더링: 보통 SEO 나 OG태그를 활용해서 slack이나 카카오톡이 해당 정보를 채팅에서 간략하게 보여줄 때 사용을 해야한다.
SEO같은 경우, 검색봇이 웹페이지들을 돌아다니면서 curl을 한다. 클라이언트 사이드 렌더링은 curl을 할경우 (React 기준) javascript 문법만 들어와서 검색봇이 해석을 하지 못한다. (실제로 내용들이 id='root' 형태로 들어옴). 그래서 개발한 게 next.js 프레임워크다 (React 기능 + server side rendering 기능 추가)
클라이언트사이드 렌더링: 대표적인 프레임워크가 React이다.
서버사이드 렌더링과 다르게 데이터를 받아올 때마다 html & css 페이지를 렌더링하는게 아니라 서버사이드에서 한번에 html & css를 다 받아오고 요청에 대한 응답이 올 때 리소스를 추가 또는 제거를 해주는 형식이다.
이 내용을 다루는 이유는 무엇인가?
라이브러리에서 가끔씩 이미지데이터나 내용을 받아올때 서버사이드에서 그려주지 못하는 경우가 있다.
맨처음 클라이언트 사이드렌더링이 작동을 하려면 서버사이드에서 먼저 html 을 그려주고 클라이언트 사이드 렌더링의 html 그려준것과 비교한 이후에 같다면 그려주는 형태인데, 라이브러리는 서버사이드 렌더링을 할 때 문제가 있는 경우가 있다.
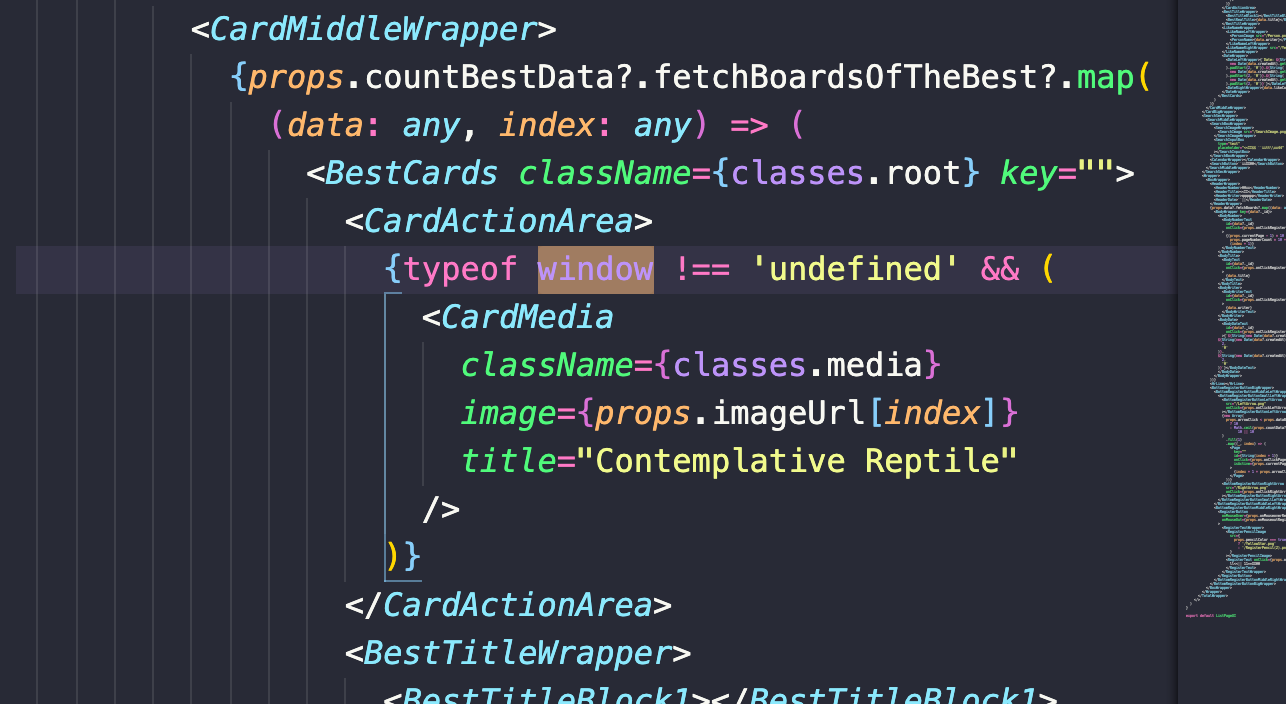
위와같이 typeof window 자체가 undefined가 아니면 클라이언트사이드 렌더링을 의미하는 것이고, 서버사이드렌더링은 undefined을 의미한다. 그래서 클라이언트 사이드 렌더링을 한다면
typeof window !== 'undefined' && (...)위 코드를 작성해주고 라이브러리를 사용해야한다. 서버사이드 렌더링이 안되는 몇몇개는 새로고침을 했을 떄 이미지같은 게 제대로 작동하지 않는다.
