scikit-learn의 user guide를 번역했습니다.
https://scikit-learn.org/stable/modules/outlier_detection.html
많은 응용프로그램은 새로운 관측값(observation)이 기존 관측값과 같은 분포에 있는지(인라이어, inlier) 혹은 다른 것인지(아웃라이어, outlier) 판단할 수 있어야 한다. 이 기능은 실데이터 세트(real data sets)를 정제하는데 자주 사용된다. 반드시 중요한 두 부류로 나눠야 한다.
- 아웃라이어 검출(Outlier detection): 훈련 데이터는 다른 관찰값과 구분되는 아웃라이어(outlier)를 포함한다. 아웃라이어 검출 추정기는 훈련 데이터가 가장 집중되면서 벗어난 데이터는 무시하는 영역을 찾는다.
- 노블티 검출(noverty detection): 훈련데이터가 아웃라이어에 오염되지 않았다면, 새로운 관찰값이 아웃라이어인지 여부를 알고 싶을 것이다. 이런 경우의 아웃라이어를 노블티라고 부른다.
아웃라이어 검출과 노블티 검출은 모두 이상값 검출(anomaly detection)에 쓰인다. 아웃라이어 검출은 비정상이거나 일반적이지 않은 관찰값을 찾아낸다. 그래서 아웃라이어 검출은 비지도(unsupervised) 이상값 검출로, 노블티 검출은 준지도(semi-supervised) 이상값 검출로 알려져 있기도 하다. 이런 맥락으로 보면 아웃라이어는 밀집한 클러스터를 구성할 수 없다. 따라서 상용 추정기들(estimator)은 아웃라이어들이 저밀도 영역에 있다고 가정한다. 반면에 노블티 검출에서 노블티들은 "정상적으로 간주되는 훈련 데이터의 저밀도 영역에 있는 한"(무슨소리일까?) 고밀도 클러스터를 구성할 수 있다.
사이킷런(scikit-learn) 프로젝트는 노블티나 아웃라이어 검출에 사용할 수 있는 일련의 기계학습 도구들을 제공 한다. 이 전략은 데이터에서 비지도 방식으로 학습하는 객체로 구현된다.
estimator.fit(X_train)새로운 관측값은 predict 메소드로 인라이어나 아웃라이어로 분류할 수 있다.
estimator.predict(X_test)인라이어들은 1로, 아웃라이어들은 -1로 분류된다. 예측 방법은 추정기에서 계산된 저수준 스코어링 함수(scoring function)의 임계값(threshhold)을 사용한다. 스코어링 함수는 score_samples 메소드를 통해 접근할 수 있다. 임계값은 contamination 파라미터로 제어할 수 있다.
decision_function 메소드는 스코어링 함수에서도 정의돼 있다. 음수 값들은 아웃라이어로 음수가 아닌 값들이 인라이어인 방식이다.
estimator.decision_function(X_test)알아둘 것은 neighbors.LocalOutlierFactor는 fit_predict를 제외한 predict, decision_function, score_samples를 디폴트로 지원하지 않는다. 따라서 이 추정기는 원래는 아웃라이어 검출에 적용될 예정이었다. 훈련 표본들의 이상치 점수는 negative_outlier_factor_ 속성값(attribute)를 통해 접근할 수 있다.
당신이 정말로 neighbors.LocalOutlierFactor를 노블티 검출에 사용하고 싶다면, 예를들면 새로 들어온 데이터의 레이블을 예측하거나 이상치 점수를 계산해 보는, noverty 파라미터를 True로 설정하고 추측기를 훈련시키면 된다. 이 경우 fit_predict는 사용할 수 없다.
주의: 아웃라이어 인자(Factor)로 노블티 검출하기
noverty가True로 설정된 경우, 훈련 표본에 없는 새로 들어온 데이터에는predict,decision_function,score_samples만을 써야만 한다. 따라서 이것은(여기서 이것은fit_predict사용인 것 같음) 잘못된 결과를 도출할 수 있다. 훈련 표본에 대한 이상치 점수는 언제나negative_outlier_factor_속성값을 통해 접근할 수 있다.
| Method | Outlier detection | Novelty detection |
|---|---|---|
fit_predict | OK | Not available |
predict | Not available | Use only on new data |
decision_function | Not available | Use only on new data |
score_samples | Use negative_outlier_factor_ | Use only on new data |
아웃라이어 검출 메소드 개요
싸이킷런의 아웃라이어 검출 알고리즘의 비교이다. 로컬 아웃라이어 팩터(LOF:Local Outlier Factor)는 검은색의 결정 경계(decision boundary)가 나타나지 않는다. 이 알고리즘은 새로운 데이터에 적용할 수 있는 아웃라이어 검출에 사용되는 예측 메소드를 갖고 있지 않기 때문이다.
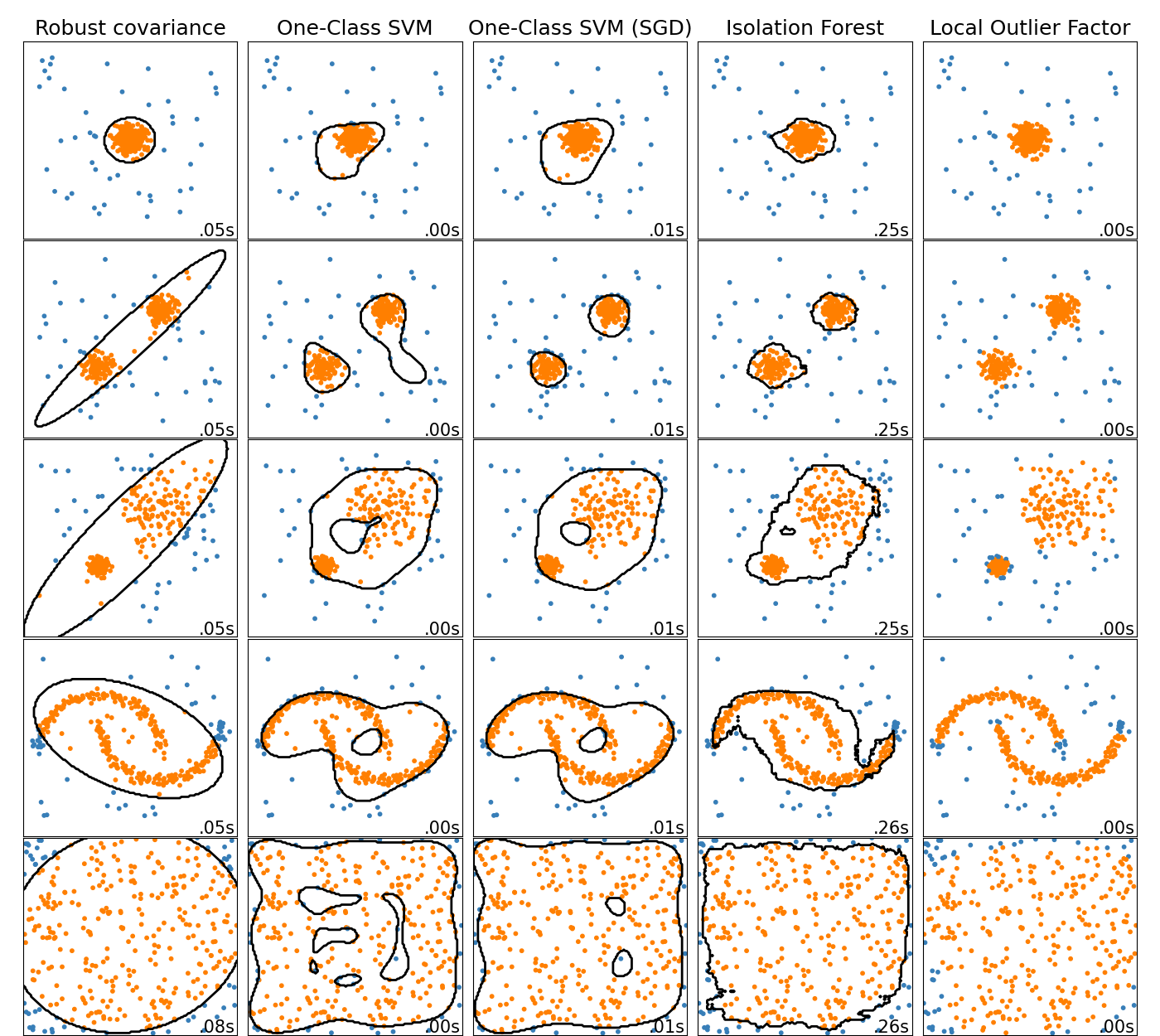
ensemble.IsolationForest와 neighbors.LocalOutlierFactor는 이 데이터 세트에는 꽤 잘 동작한다. svm.OneClassSVM는 아웃라이어에 민감하다고 알려져 있고 아웃라이어 검출에 잘 동작하지 않는 것을 볼 수 있다. 다차원 데이터나 인라이어 데이터 분포에 대한 가정 없이 아웃라이어 검출은 굉장히 어렵다는 것을 보여주는 것이다. svm.OneClassSVM 은 여전히 아웃라이어 검출에 사용될 수 있지만 아웃라이어들을 처리하고 과적합(overfitting)을 예방하기 위해 nu 파라미터를 세밀하게 조정할(fine-tuning) 필요가 있다. linear_model.SGDOneClassSVM은 수많은 표본들의 선형 복잡성을 갖는 단일-클래스 SVM(One-Class SVM)을 구현한 것이다. 가우시안 커널을 기본으로 사용하는 svm.OneClassSVM과 유사한 커널 근사화 기술과 함께 구현됐다. 마지막으로 covariance.EllipticEnvelope는 데이터가 가우시안이라고 가정하고 타원을 학습한다. 각각의 추정기에 대한 더 자세한 내용은 토이 데이터세트의 아웃라이어 검출을 위한 이상 감지 알고리즘 비교 예시와 아래 섹션을 참조하라.
Examples:
svm.OneClassSVM,ensemble.IsolationForest,neighbors.LocalOutlierFactor,covariance.EllipticEnvelope를 비교하려면 See Comparing anomaly detection algorithms for outlier detection on toy datasets를 보라.
노블티 검출
개의 관측값들로 구성된 데이터세트를 이용한다고 생각해보자. 이 관측값들은 특징값과 같은 분포에서 나왔다. 여기에 하나의 관측값을 추가할 것이다. 질문을 던져보자. 새로운 관찰값이 기존 것들과 많이 달라 그 규칙성이 의심되는가?(같은 분포에서 나온게 맞는지?) 반대로 그 관찰값이 기존 관찰값들과 구별할 수 없을 정도로 유사한가? 노블티 검출 도구와 방법에서 다루는 질문들이다.
일반적으로 p차원 공간에 표시된 최초 관찰값들이 분포한 윤곽을 구분하는 거칠고, 촘촘한 경계를 학습하는 것이다. 따라서 만약 추가된 관찰값들이 윤곽이 구분된 부분공간 내에 있는 경우 그 값들을 최초 관찰값과 같은 모집단에서 나온 것이라 간주한다. 반대로 추가된 관찰값들이 경계 바깥에 있다면 자신있게 비정상이라고 말할 수 있을 것이다.
단일 클래스 SVM(One-Class SVM)은 Schölkopf et al.이 소개했다.svm.OneClassSVM 객체의 서포트 벡터 머신 모듈에서 구현됐다. 경계를 정의하려면 커널과 스칼라 파라미터를 선택해야 한다. RBF 커널이 일반적으로 선택된다. 하지만 이 커널은 대역폭 파라미터를 설정하기 위한 명확한 공식이나 알고리즘이 없다. 사이킷런 구현체에서 이 커널이 기본값이다. 단일 클래스 SVM의 마진으로 알려진 nu 파라미터는 새롭지만 규칙적인 관찰값을 경계 밖에서 찾아낼 확률을 의미한다.
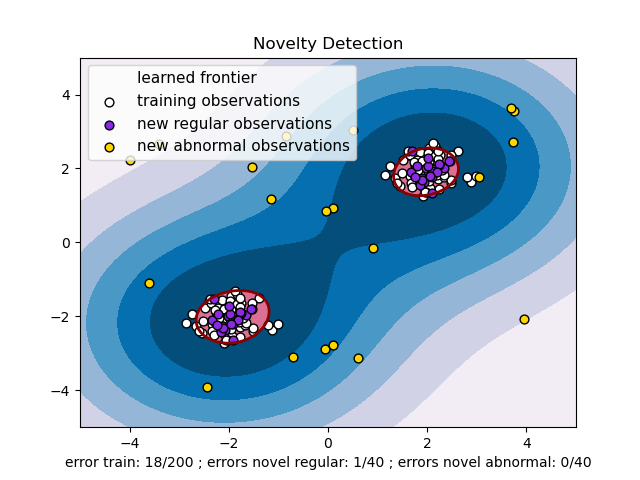
단일 클래스 SVM의 규모를 늘려보자.
온라인 선형 버전의 단일 클래스 SVM은 linear_model.SGDOneClassSVM에 구현되어 있다. 이 구현체는 샘플의 크기와 함께 선형으로 확장된다. 구현체는 샘플수의 복잡도가 기껏해야 2차인 커널화된 svm.OneClassSVM의 솔루션을 도출하기 위해서도 이용될 수 있다. 더 자세한 내용은 Online One-Class SVM에서 보라.
아웃라이어 검출
아웃라이어 검출은 노블티 검출과 비슷하다. 그 목표가 규칙성을 가진 관찰값들의 중심을 아웃라이어라고 부르는 것들로부터 분리해 낸다는 점에서 그렇다. 하지만 아웃라이어 검출의 경우 도구를 훈련하는데 사용할 규칙적인 관찰값의 모수를 나타내는 깨끗한 데이터 세트가 없는 차이가 있다.
타원형의 봉투 맞추기(Fitting an elliptic envelope)
아웃라이어 검출을 하는 일반적인 방법 중 하나는 규칙성을 갖는 데이터가 알려진 분포(정규 분포와 같은)에서 나왔다고 가정하는 것이다. 이런 가정에서 일반적으로 데이터의 "모양"을 정의하려 시도한다. 이 모양으로부터 멀리 떨어져 있는 값들을 이상 관찰값들을 정의할 수 있다.
사이킷런은 데이터에 대한 강력한 공분산 추측을 할 수 있는 covariance.EllipticEnvelope 객체를 제공한다. 이 구현체는 중심 데이터에 타원을 맞추고 그 바깥의 점을 무시한다.
예를들면 인라이어 데이터가 정규 분포라고 가정하면 인라이어 위치와 분산을 강력한 방법으로(아웃라이어들에 영향을 받지 않으면서) 추측할 수 있다. 이 추정으로 얻은 마할노비스(Mahalanobis) 거리는 외곽을 도출하는데 이용할 수 있다. 아래 그림을 보자.
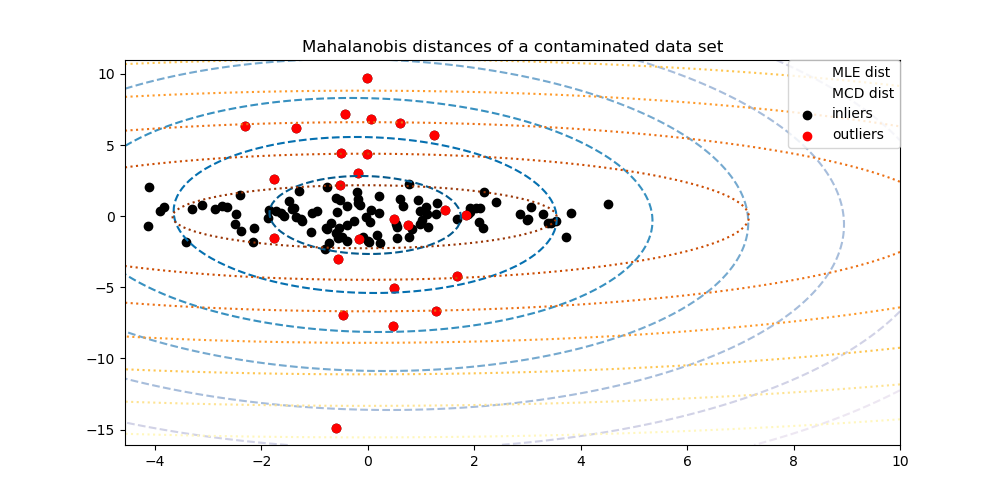
Examples:
- See Robust covariance estimation and Mahalanobis distances relevance for an illustration of the difference between using a standard (covariance.EmpiricalCovariance) or a robust estimate (covariance.MinCovDet) of location and covariance to assess the degree of outlyingness of an observation.
References:
- Rousseeuw, P.J., Van Driessen, K. “A fast algorithm for the minimum covariance determinant estimator” Technometrics 41(3), 212 (1999)
Isolation Forest
고차원 데이터세트에 대한 아웃라이어 검출에 가장 효과적인 방법 중 하나는 랜덤 포레스트를 이용하는 것이다. ensemble.IsolationForest는 관찰값들을 고립시킨다. 무작위로 특징을 고르고 그 특징의 최대값과 최소값 사이를 분리하는 무작위 값을 선택하는 방법이다.
재귀적 분할은 트리 구조로 나타낼 수 있기 때문에 샘플을 분리하는데 필요한 분할 수는 루트노드에서 종단노드까지의 경로길이와 동일하다.
이 경로길이가 이 같은 랜덤 트리들의 숲의 평균인 정상상태를 측정하는 결정 함수이다.
무작위 분할은 이상값로 가는 명확히 빠른 길을 만들어낸다. 따라서 랜덤 트리들의 숲은 이상값에 매우 가까운 특정 샘플들로 가는 더 빠른 경로 길이를 집합적으로 만들어낸다.
ensemble.IsolationForest의 구현체는 tree.ExtraTreeRegressor를 기반으로 한다. Isolation Forest의 논문에 따르면 각 트리의 최대 깊이는 으로 설정된다. 여기서 은 트리를 만드는데 사용한 샘플의 개수다.(더 자세한 내용은 Liu et al., 2008 참고)
아래 그림은 알고리즘을 보여준다.
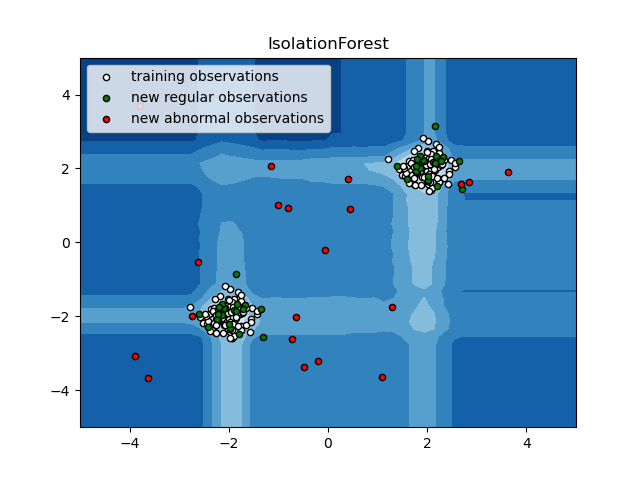
ensemble.IsolationForest는 이미 훈련한 모델에 더 많은 트리들을 추가할 수 있도록 하는 warm_start=True를 지원한다.
Examples:
See IsolationForest example for an illustration of the use of IsolationForest.
See Comparing anomaly detection algorithms for outlier detection on toy datasets for a comparison of ensemble.IsolationForest with neighbors.LocalOutlierFactor, svm.OneClassSVM (tuned to perform like an outlier detection method), linear_model.SGDOneClassSVM, and a covariance-based outlier detection with covariance.EllipticEnvelope.
References:
Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. “Isolation forest.” Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on.
Local Outlier Factor
적당한(?, moderately) 고차원 데이터세트에 아웃라이어 검출을 하는 또다른 효과적인 방법은 Local Outlier Factor(LOF) 알고리즘을 사용하는 것이다.
neighbors.LocalOutlierFactor (LOF) 알고리즘은 관찰값들의 이상치 정도를 반영한 (local outlier factor로 알려진) 점수를 계산한다. 이 구현체는 그 이웃에 대한 주어진 데이터 점들의 국부 밀도 편차를 측정한다. 이 아이디어는 그 이웃에 비해 명확히 낮은 분포를 갖는 샘플들을 찾아내는 것이다.
실제로 국부 밀도는 k-nearest neighbor로 얻어낸다. 관찰값에 대한 LOF 점수는 k-nearest neighbors의 평균 로컬 밀도와 자체 로컬 밀도의 비율과 같다. 정상 인스턴스는 그 이웃의 로컬 밀도와 같을 것이고, 비정상 데이터는 로컬 밀도에 비해 매우 작을 것이다.
k개의 이웃 개수는(n_neighbors 파라미터로 알려진) 일반적으로 아래 조건에 맞게 고른다.
- 1) 클러스터가 포함해야 하는 최소 개체 수보다 많아서, 다른 객체들이 이 클러스터와 관계 있는 로컬 아웃라이어가 될 수 있어야 함.
- 2) 잠재적 로컬 아웃라이어가 될 수 있는 인접 개체의 최대 수보다 작아야 함.
실제로는, 이런 정보는 일반적으로 알 수 없어서 n_neighbors를 20으로 설정하면 잘 동작하는 편이다. 아웃라이어들의 비율이 높으면(가령 아래 예제와 같이 10%를 넘는 경우), n_neighbors는 더 커져야 한다.(아래 예제에서는 n_neighbors를 35로 설정)
LOF 알고리즘의 장점은 데이터세트의 로컬과 글로벌 속성을 모두 고려한다는 것이다. 이상 표본들의 기저 밀도가 다른 데이터세트에도 잘 동작할 수 있다. 알고리즘이 풀어내는 질문은 '표본이 얼마나 고립되어 있냐?'가 아니고 '주변 이웃들에 대해 얼마나 고립되어 있냐?'이다.
LOF를 아웃라이어 검출에 적용할 때, predict, decision_function, score_samples는 사용할 수 없다.
fit_predict만 사용할 수 있다. 샘플의 이상치 점수는 negative_outlier_factor_ 특성값을 통해 알아낼 수 있다. 주의할 것은 predict, decision_function, score_samples은 LOF가 노블티 검출에 이용될 때 새로 들어온 데이터에 이용할 수 있다는 것이다. 노블티 인자가 True로 설정되어 있을 때를 말한다. Novelty detection with Local Outlier Factor를 보라.
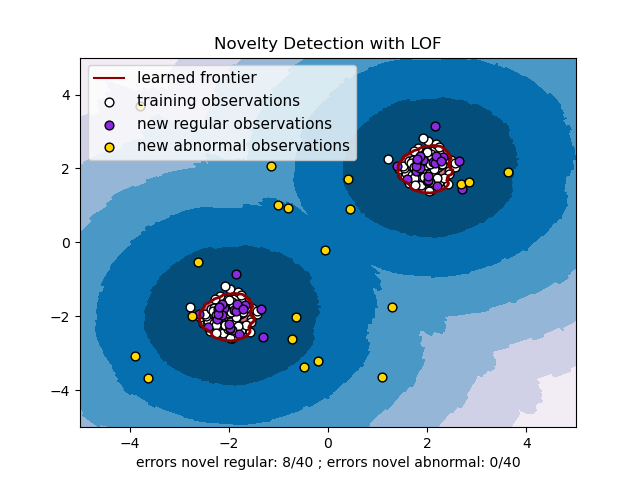
이 전략은 아래 그림에 설명돼어 있다.
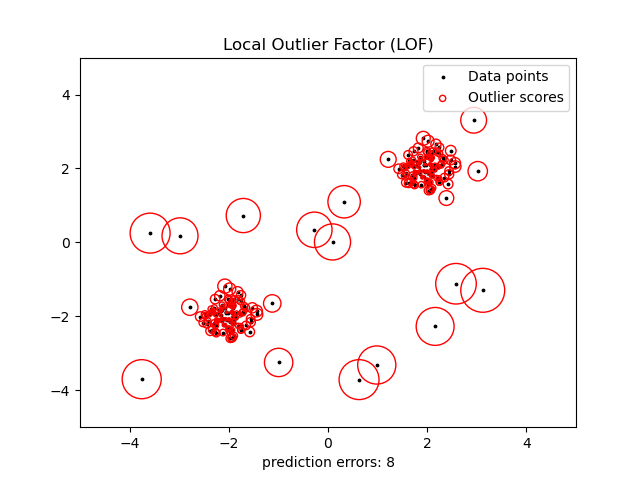
Examples:
See Outlier detection with Local Outlier Factor (LOF) for an illustration of the use of neighbors.LocalOutlierFactor.
See Comparing anomaly detection algorithms for outlier detection on toy datasets for a comparison with other anomaly detection methods.
References:
Breunig, Kriegel, Ng, and Sander (2000) LOF: identifying density-based local outliers. Proc. ACM SIGMOD
Novelty detection with Local Outlier Factor
neighbors.LocalOutlierFactor를 노블티 검출에 이용하려면, 가령 레이블을 예측하거나 새로 들어온 데이터의 비정상 점수를 계산하려면, 추정기를 훈련하기 전에 노블티 파라미터를 True로 설정해 초기화 해야 한다.
lof = LocalOutlierFactor(novelty=True)
lof.fit(X_train)이 경우 fit_predict는 사용할 수 없음을 주의하라.
주의 'Novelty detection with Local Outlier Factor'
novelty를 'True'로 설정하면 새로 들어온 데이터에 대해predict,decision_functionandscore_samples,score_samples만을 사용해야 함을 명심하라. 훈련 표본에 사용해선 안된다. 잘못된 결과를 도출할 수 있다. 훈련 표본의 비정상 점수는negative_outlier_factor_특성을 통해 항상 접근 가능하다.
아래 그림은 Local Outlier Factor로 수행한 노블티 검출 결과다.