[Paper Review]XLNet: Generalized Autoregressive Pretraining for Language Understanding
Paper Review
이번에 리뷰할 논문은 XLNet이다.
이 논문은 2020년에 나온 논문으로 기존 BERT와 같은 Denoising AutoEncoder 기반의 pretrain model과 GPT와 같은 AutoRegressive 기반 pretrain model의 단점을 보완하고자 만들어진 논문이다.
들어가기 앞서 XLNet의 주요 특징들을 꼽자면 다음과 같다.
- AR과 DAE 방식의 문제를 해결하기 위해 제안됨
- Permutation LM
- Transformer-XL
- Two-Stream Self-Attention
기존 pretraining objective의 문제점
XLNet 이전에 주로 쓰이던 pretrain model은 주로 GPT와 같은 autoregressive model, BERT와 같은 denoising autoencoding model이 있었다. XLNet의 저자는 둘 모두 장점도 있으나 단점도 있다고 이야기한다.
DAE (Denoising auto encoding)
가장 유명한 모델로 BERT가 있다. 이 방식의 장단점을 꼽자면 다음과 같다.
Pros
- Bidirectional context information
Cons
- pretrain-finetune discrepency
- Independence assumption
우선 장점, DAE방식은 입력을 sequential하게 받아 하나씩 생성해내는 방식이 아니라 입력을 한꺼번에 받아 마스킹된 토큰을 예측하는 방식으로 학습하게 된다. 이로 인해서 한 방향만의 정보만을 사용하는 것이 아니라 양방향의 정보를 모두 활용할 수 있게 된다.
단점으로는 pretrain-finetune discrepency, independence assumption이 있는데, 이 둘 모두 [MASK] 토큰 때문에 발생한다.
우선 pretrain-finetune discrepency 문제의 경우, pretraining 단계에서는 [MASK] 토큰을 사용하지만 실제 데이터를 이용해서 finetuning을 진행하는 경우에 [MASK] 토큰은 절대 등장하지 않는다. 이로 인해서 pretrain과 finetune간의 괴리가 발생하게 되어 성능 저하의 원인이 된다.
Independence assumption 또한 [MASK] 토큰 때문에 발생하게 된다.
예를 들어 "New York is a city."라는 문장이 주어졌다고 하고 [New, York]이 마스킹되었다고 한다면 각각의 마스킹된 토큰을 예측할 때 DAE 기반 방식은
과 같이 예측하게 된다. 문제는 실제로 New와 York은 서로 관련이 있는 상태인데 DAE 방식에서는 둘을 서로 관계 없는 단어라고 가정하고 예측을 진행하게 된다.
AR (Autoregressive)
가장 유명한 AR 방식 모델은 GPT가 있다.
AR 계열의 가장 큰 문제점은 unidirectional context information만을 이용한다는 것인데, 이는 NLU 계열의 downstream task에서 성능 저하를 일으킨다. NLU task들은 보통 bidirectional context information을 필요로 하는 경우가 많은데 AR 기반의 모델들은 unidirectional context information만을 활용하여 모델을 학습시키기 때문에 DAE 기반 모델들에 비해 낮은 성능을 갖게 된다.
그래도 DAE방식의 문제점이였던 independence assumption, pretrain-finetune discrepency는 존재하지 않는다.
Permutation LM
XLNet은 AR과 DAE 방식의 pretrain model의 문제들을 해결하기 위해 Permutation LM 방식을 이용해서 pretrain을 진행했다.
그러면 Permutation LM이란 무엇일까?
Permutation은 번역하면 순열이다. Sequence에서 각 토큰들을 중복없이 순서에 상관있게 나열하는 것을 말하는데, 이렇게 가능한 모든 순열에 대해서 sequence의 log likelihood를 최대화 하도록 학습을 진행한다. Permutation LM의 objective를 수식으로 나타내면 다음과 같다.
여기서 는 길이가 T인 sequence에서 가능한 모든 permutation들의 집합을 말하고, 는 permutation 집합 에 속하는 의 t번째 원소를, 는 permutation 의 첫 t-1개의 원소들을 말한다. 이를 토대로 해석하면 길이가 T인 sequence가 주어졌을 때 해당 sequence의 가능한 모든 permutation에서 각각의 정답 토큰이 등장할 확률을 최대화하는 것이 objective가 된다.
그러면 이 permutation language model이 왜 좋을까?
Bidirectional context information
우선 GPT에서 문제로 삼았던 bidirectional context information의 부재가 해결된다. 기존의 전통적인 AR 방식의 모델과는 다르게 XLNet은 bidirectional context information을 얻을 수 있다. Permutation 덕분에 가능하게 되는데, 예를 들어 길이가 4이고 각 토큰을 [1,2,3,4]라고 하는 sequence가 입력되었다고 할 때, GPT는 토큰 2가 생성되는 확률을 토큰 1을 이용해서만 모델링해야된다. 하지만 permutation을 이용하게 된다면, 단순히 [1,2,3,4]의 순서뿐만 아니라 [3,4,1,2], [4,1,2,3], [3,1,4,2]등 여러 permutation에서 실제로 문장에서 뒤에 등장하는 토큰들을 이용해서 확률값을 모델링할 수 있게 된다.
Independence Assumption
그리고 BERT에서 [MASK] 토큰으로 인해서 생겼던 문제인 independence assumption 또한 필요없어지게 된다. 앞에서 예로 들었던 "New York is a city."라는 문장에서 New와 York은 실제로 연관이 있으나 masking되면 BERT에서는 둘을 독립한다고 가정하게 된다.
하지만 permutation LM에서는 필요가 없어진다. 모델에 입력된 permutation을 [is, a, city, New, York]라고 할 때 두 토큰들의 등장 확률을 모델링하면 다음과 같다.
이렇게 permutation 방식은 기존 DAE 방식인 BERT와 달리 토큰 "New"를 이용해서 "York"의 확률을 모델링할 수 있게 된다. 그래서 문장에서 XLNet은 항상 BERT보다 더 많은 연관성을 학습할 수 있게 되며 같은 문장에 대해 더 꼼꼼하게 학습이 가능해진다.
Pretrain-finetune discrepency
마찬가지로 기존 BERT에서 [MASK] 토큰 때문에 문제되었던 pretrain-finetune discrepency 또한 XLNet에서는 [MASK] 토큰 등으로 입력 문장에 noise를 가할 필요가 없어져 finetune과의 괴리가 없어진다.
Permutation LM in Detail
Permutation LM을 좀 더 자세히 들여다 보자.
Objective
앞서 말한 permutation LM의 objective는 아래와 같았다.
하지만 이를 그대로 활용하지는 않고 몇가지 기법을 추가해서 활용하게 된다. 우선 실제 XLNet에서는 sequence의 permutation을 입력으로 주지않고, Transformer에서 positional encoding으로 나타내는 기존의 순서를 유지한채 attention mask만을 활용해서 sequence의 permutation을 수행한다. 입력 순서에 대해서 permutation을 진행하지 않는 이유는 finetuning시 사용되는 실제 데이터가 원래 정상적인 순서로 입력되기 때문이다.
내 생각에는 이러한 방식을 이용하는 주 이유가 DAE기반에서 문제로 삼았던 pretrain-finetune discrepency를 줄이기 위함이라고 생각한다.
Two-Stream Self-Attention
Permutation LM의 objective는 standard Transformer에서는 제대로 작동하지 못한다고 한다. 그 이유를 살펴보자.
위는 기존 Transformer에서 Softmax를 이용해서 다음 토큰의 확률 분포를 모델링하는 수식이다. 여기서 는 Transformer에서 t 시점 이전까지의 등장 토큰들에 대한 hidden representation을 말한다. Hidden state의 표기를 보면 알 수 있듯이 해당 hidden state는 예측해야할 time-step t 위치에 대해 구애받지 않은채 예측하게 된다.
이게 왜 문제라는거야?
Permutation을 이용하기 때문에 문제가 생긴다.
예를들어 입력된 sequence가 [1,2,3,4,5]라고 하자. 여기서 두 개의 permutation을 각각 [4,2,3,1,5], [4,2,3,5,1]이라고 하고, 현재 예측하려는 time-step을 t라고 하면 기존 Transformer의 Softmax는 이전까지 등장한 토큰들인 [4,2,3]만을 이용해서 time-step t의 토큰을 예측하게 된다. 여기서 문제가 발생하게 되는데, 서로 다른 permutation임에도 불구하고 에측에 사용되는 확률 분포는 같게 되어 1과 5를 둘 다 예측할 수 없고, 단 하나의 값만을 뱉어내게 된다.
그래서 별도의 조정을 통해 토큰을 예측해야 한다.
Target position aware Softmax
라는 기존 Softmax의 hidden state에서 target position 를 입력으로 더 추가한 새로운 representation을 만들었다.
이 Target aware representation을 만들기 위해서는 두 모순적인 조건을 충족해야 한다.
- 는 position 에 대한 정보만 사용해야하며 토큰 의 정보에 대해서는 사용하면 안된다.
- time-step t 이후 j 시점의 토큰을 예측하기 위해서 는 토큰 의 정보를 함께 encoding해야 한다.
사실 하나로는 해결 못하는 문제다. 그래서 저자는 그냥 target aware representation과 함께 기존의 hidden representation 도 같이 쓰기로 했다. 그래서 각각의 용도를 다음과 같이 설정했다.
- : Content representation, time-step t 이전 토큰들과 토큰 의 정보도 함께 encoding
- : Query representation, time-step t 이전 토큰들의 정보와 위치 정보 만을 encoding, 토큰 의 정보는 포함하지 않음
Partial Prediction
알다시피 원래 permutation을 만들어보면 매우 많은 경우의 수가 생기게 된다. 만들어진 모든 permutation에 대해서 modeling을 진행하면 이점이 존재하나 optimization이 매우 어려워지며 너무 많은 경우의 수로 인해 수렴 속도가 느려지게 된다.
그래서 XLNet은 permutation 전체를 예측하지않고 BERT와 같이 일부만을 예측하는 partial prediction을 활용했다.
Sequence 가 입력되면 sequence를 cutting point 를 기준으로 나누고, cutting point 뒤만을 예측하도록 한다. 여기서 cutting point 뒤의 subsequence 를 target subsequence라고 하며, non-target subsequence 에 대한 의 log-likelihood를 최대화하는 방향으로 학습을 진행한다.
Transformer-XL
XLNet은 Transformer-XL에서 사용된 기술이 Relative Positional Encoidng Scheme과 Segment Recurrence Mechanism 두 가지를 사용한다.
Relative Positional Encoding
기존 Transformer에서는 absolute positional encoding 방식을 사용해 각 segment내의 위치를 나타내왔다. 하지만 이는 segment를 여러개 사용할 경우에 성능의 저하를 야기했고, 이를 해결하고자 사용된 것이 relative positional encoding이다.
이는 각 토큰의 위치를 상대적으로 나타낸다. 기준 토큰의 위치로부터 얼마나 떨어져있는가에 대한 정보를 encoding해서 사용한다.
Segment Recurrence Mechanism
솔직히 말해서 이름은 거창한데 아이디어는 생각보다 되게 간단하다고 생각한다. 2개의 permutation 각각을 segment라고 할 때 각 layer에서 첫번째 segment의 hidden state를 메모리에 chaching하고 그 값을 다음 layer의 전체 hidden state를 계산할 때 사용하는 방식이다.
이 방식은 recurrence하게 동작하는데, 이 때 양방향 segment 정보를 활용하고자 XLNet에서는 bidirectional data input pipeline이라고 batch의 반씩 각각 forward/backward direction으로 recurrence를 진행했다.
Span-based Prediction
XLNet에서는 span-based prediction이라는 방식을 사용했는데, 이는 길이 중 하나를 샘플링하고 L개의 연속된 토큰을 KL개의 token내에서 예측하는 방식을 말한다.
(사실 논문에 크게 설명도 없고, 검색했을 때 제대로 된 결과도 잘 찾지 못해 깊은 이해는 하지 못했다.)
Relative Segment Encoding
여러 downstream task에서 여러개의 segment를 입력으로 사용하는 만큼 XLNet 또한 여러개의 segment를 입력으로 받고자 한다.
XLNet에 들어오는 입력은 기존 BERT의 것과 같다. [CLS, A, SEP, B, SEP] 처럼 샘플링한 두 문장을 입력으로 받고, 두 문장을 concat한 것에 대해 permutation을 수행하여 학습을 진행한다.
BERT와 다른 점은 segment embedding 부분인데, BERT에서는 두 segment를 입력으로 받아 각각의 segment에 대해 embedding값을 따로 주었다. 하지만 XLNet에서는 relative positional encoding과 비슷한 원리로 relative segment encoding을 사용한다.
Relative segment encoding은 각각의 토큰들이 어떤 segment에 속하는지에 대한 정보를 encoding하는 것이 아니라 토큰 위치 쌍이 같은 segment에 속하는지, 다른 segment에 속하는지에 대한 정보를 encoding한다. 위치 쌍 i, j가 있을 때 둘이 같은 segment에서 나온 것이라면 , 다른 segment에서 나온 것이라면 라는 segment encoding을 사용한다.
이렇게 relative segment encoding을 사용하면 relative segment encoding 방식의 inductive bias에 의해 일반화 성능이 더 좋아진다고 한다. 또한 두 가지의 segment embedding 값으로 고정되지않고, 상대적인 값을 encoding하기 때문에 여러 개의 segment가 입력으로 들어오는 경우에 대해 fine-tuning할 수 있다는 것이 장점이다.
Ablation Study
이번 포스팅에서는 논문의 experiments 부분은 담지않으려 한다. 간략하게 말하자면
- 많은 수의 task에서 XLNet이 기존의 SoTA를 큰 폭으로 뛰어넘었다.
- 긴 context를 갖는 경우에 XLNet이 더 좋은 성능을 나타낸다.
정도로 줄일 수 있을 것 같다.
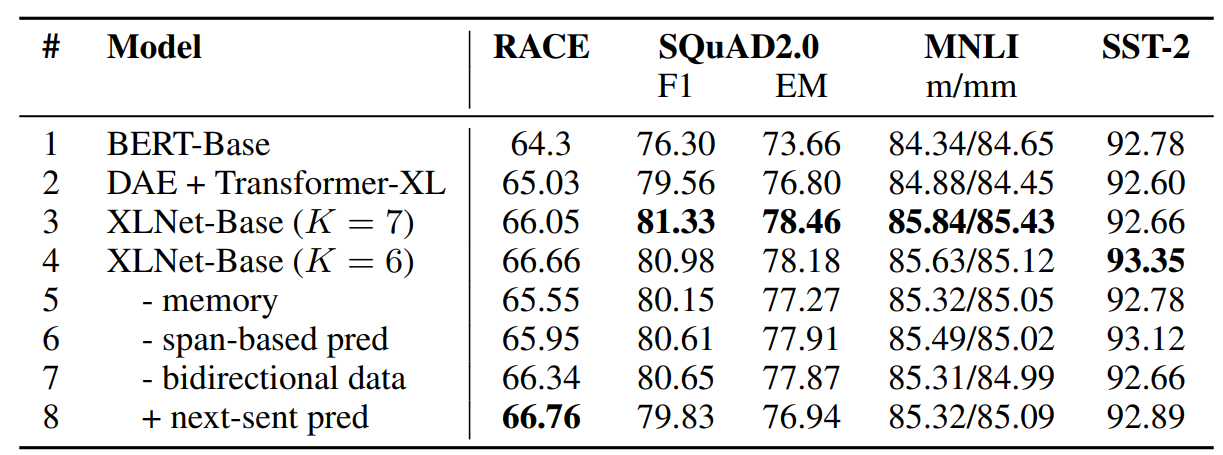
위 사진은 ablation study를 진행한 결과이다. XLNet의 저자가 확인하고자한 것들은
- Permutation language modeling objective의 효과
- Transformer-XL을 backbone으로 사용한 것의 효과
- 기타 다른 기법들의 효과
- NSP objective의 효과
이렇게 볼 수 있다. 결과를 보게 되면 확실히 Transformer-XL, permutation LM objective는 성능의 개선에 큰 기여를 함을 알 수 있고, memory(segment recurrence), span-based prediction, bidirectional input pipeline 또한 XLNet의 성능에 영향을 많이 끼침을 알 수 있다.
하지만 Next sentence prediction의 경우 기존 BERT에서 사용되는 objective였는데 이는 성능 개선에 큰 역할을 하지 못함을 확인해 XLNet에서는 NSP를 objective로 사용하지 않게 되었다.
소감
작년에 한번 읽고 다시 읽는 논문이다. 다른 논문들은 두번째 읽을 때 훨씬 더 잘 이해할 수 있었는데 XLNet은 여전히 어려운 논문이다.
Permutation을 objective에 접목한다는 생각은 정말 신박한 아이디어라고 본다. 그런데 사실 생각해보면 그냥 ELMo처럼 forward, backward 두 종류만 사용해서 모델링해도 괜찮은 결과가 나오지않을까 생각이 들긴한다. 결국에 AR 모델이 unidirectional context information 문제만 제외하면 더 좋다는 것이 저자의 생각인 것 같은데 굳이 더 많은 계산이 필요한 permutation을 사용할만큼의 성능 격차가 있었을까 하는 생각이 든다.

안녕하세요 치영님:) XLNet 논문 리뷰글 잘 읽었습니다!
Permutation, LM 각각의 개념은 알고있었는데 Permutation LM이라는 개념을 소개해주셔서 감사합니다.
초반에 XLNet 사전에 알고있어야 할 부분을 간단히 명시해 놓으면 더 수월하게 읽을 수 있을 것 같아요!
그리고 사소하지만 discrepency를 discrepancy로 표기한 단어가 몇군데 있는데 반영하시면 좋을 것 같습니다.