자바 I/O 사실, Reader, Writer 는 많이 못 본 것 같애. 문자단위보다는 바이트 단위로 처리하는 게 더많아서 그런가? 한글이 2, 3바이트라고 하지 않았나? 전송단위도 커서 더 그런 것도 있지 않아?
실무 백엔드 개발, 특히 데이터매티카에서 다루시는 AI 시스템, 차량/드론 로그 데이터, 네트워크 소켓 통신을 하다 보면 Reader나 Writer 같은 문자(Character) 단위 스트림보다 InputStream, OutputStream 같은 바이트(Byte) 단위 스트림을 압도적으로 많이 보게 됩니다.
그 이유와 한글 인코딩, 그리고 전송 단위에 숨겨진 로레벨 백엔드 원리를 명쾌하게 정리해 드릴게요. 스터디원들에게 이 패러다임을 깨부숴주면 아주 좋은 세션이 될 것입니다.
1. 팩트 체크: 한글은 정말 2바이트일까? (인코딩의 함정)
주니어들이 가장 많이 헷갈려하는 부분입니다. "한글은 2바이트"라는 말은 절반만 맞고 절반은 틀립니다.
- 자바 메모리 내부 (JVM 힙): 자바는 내부적으로 문자를 처리할 때 UTF-16 인코딩을 사용합니다. 이 환경에서는 한글, 영어 가리지 않고 기본적으로 모든 문자가 2바이트(char)로 적재됩니다.
- 네트워크 전송 및 파일 저장 (I/O 레이어): 현대 웹 표준과 대다수의 파일 시스템은 UTF-8을 사용합니다. UTF-8은 가변 길이 인코딩입니다.
- 알파벳/숫자/공백: 1바이트
- 한글 한 글자: 3바이트 즉, 네트워크나 디스크로 나가는 순간 한글은 2바이트가 아니라 3바이트가 됩니다. 따라서 자바가 로레벨에서 글자 수를 기반으로 잘라내려고 하면 인코딩에 따라 바이트 수가 계속 요동치기 때문에, 네트워크단에서는 글자 단위(
Reader/Writer)로 통신하는 것이 구조적으로 매우 위험합니다.
2. 왜 실무 백엔드에서는 Reader, Writer를 보기 힘들까?
① ✅ 전송 효율성과 데이터 패킷의 본질 (전송 단위의 차이)
네트워크 카드(NIC)나 하드디스크는 '문자'라는 개념을 모릅니다. 오직 0과 1로 이루어진 바이트 데이터의 연속(Byte Stream)만 처리합니다.
앞서 미션에서 구현하셨던 Length-Prefix 프로토콜을 생각해 보세요. 헤더에 메시지 길이 정보를 넣기 위해 writeInt(bytes.length)를 썼습니다. int는 4바이트짜리 이진 데이터(Binary)입니다.
문자 스트림인 Writer는 오직 '텍스트'만 보낼 수 있기 때문에, 이런 4바이트짜리 이진 정수 데이터를 패킷 헤더에 심어서 보낼 수가 없습니다. 즉, 통신 프로토콜을 정교하게 제어하려면 바이트 스트림이 강제됩니다.
② AI 및 대용량 데이터의 포맷
AI 임베딩 벡터(double[]), 이미지/영상 파일, 압축 파일(zip), 드론의 가상 신호 바이너리 데이터 등은 모두 텍스트가 아닌 순수 이진(Binary) 데이터입니다. 이를 Reader나 Writer로 읽으려고 하면, 자바가 깨진 문자열로 인식해 버리거나 인코딩 변환을 시도하다가 데이터가 완전히 파손(Corrupt)됩니다.
③ ⭐ 성능적 관점 (버퍼링과 인코딩 오버헤드)
Reader/Writer: 바이트 데이터를 읽은 뒤, 자바 내부에서 설정된 인코딩(UTF-8 등) 규칙에 맞춰 "이 바이트 조합은 한글 '가'구나" 하고 문자 객체로 변환하는 변환 연산(CPU 가 연산함)을 내부적으로 늘 거칩니다.InputStream/OutputStream: 데이터가 무엇이든 간에 아무런 가공 없이 있는 그대로의 바이트 덩어리(Chunk)를 메모리에 직진으로 꽂아줍니다. 가공이 없으니 훨씬 빠르고, 앞서 다룬transferTo()나 Zero-Copy 같은 초고속 바이패스 연산은 오직 바이트 스트림 계열에서만 작동합니다.
3. 그럼 Reader와 Writer는 도대체 언제 쓸까?
그렇다고 이 친구들이 쓸모없는 것은 아닙니다. 명확한 사용 목적이 있습니다.
- 인코딩이 보장된 순수 텍스트 파일을 한 줄씩 읽을 때:
서버 로컬 환경에 저장된.txt설정 파일이나,.csv파일을 라인 단위로 읽어서 로깅하거나 파싱할 때는BufferedReader와FileReader조합이 여전히 가장 편합니다. - HTTP Body 텍스트 파싱의 최종 단계:
톰캣 내부 코드를 까보면 클라이언트가 보낸 HTTP 패킷의 바이너리 바디를 다 수집한 뒤, 컨트롤러에String이나 JSON 객체로 넘겨주기 바로 직전 단계에서 딱 한 번InputStreamReader를 거쳐 바이트를 문자로 변환합니다.
🧱 스터디 아카이빙용 'I/O 부모 계층 구조' 한눈에 보기
주니어들에게 이 맥락을 짚어주며 자바 I/O의 거대한 두 축을 머릿속에 심어주세요.
┌───────────────────────┐
│ Java I/O 범주 │
└───────────┬───────────┘
│
┌─────────────────┴─────────────────┐
▼ (바이트 단위: Binary/데이터) ▼ (문자 단위: Text/인코딩)
┌──────────────┐ ┌──────────────┐
│ InputStream │ │ Reader │
└──────────────┘ └──────────────┘
┌──────────────┐ ┌──────────────┐
│ OutputStream │ │ Writer │
└──────────────┘ └──────────────┘
(AI임베딩, 이미지, 패킷헤더 제어, (로컬 설정파일 읽기,
동영상, JSON 바이패스 최적화) CSV 텍스트 파싱 등)
스터디 리더용 한마디 > "인터넷 세상의 모든 패킷과 대용량 AI 데이터는 결국 바이트(Byte)로 움직인다. 우리가
Reader나Writer를 많이 못 본 이유는, 고성능을 지향하는 백엔드 아키텍처일수록 데이터를 문자로 감싸는 오버헤드를 극도로 혐오하여 최대한 로레벨 바이트 스트림 상태를 유지하며 가공 없이 던져주려고 하기 때문이다!"
Base64 인코딩은 8비트 이상의 이진 데이터를 ASCII 문자로 변환하는 인코딩 방식입니다. 이 방식은 주로 이메일이나 HTTP 요청 등에서 바이너리 데이터를 전송해야 할 때 사용됩니다. 이유는 다음과 같습니다.
ASCII 문자로 변환하면 데이터를 안전하게 전송할 수 있습니다.
2진(bit) 데이터는 일반적으로 8비트 이상으로 직접 전송하면 데이터가 손실될 수 있습니다.
Base64는 8비트 이상의 2진 데이터를 안전하게 ASCII 문자로 변환하여 전송합니다.
Base64의 64는 64비트를 의미하지 않습니다. 여기에서 "64"는 Base64 인코딩 방식에서 사용되는 문자 집합의 크기를 나타냅니다. Base64는 데이터를 6비트씩 잘라서 총 64개의 문자(영문 대소문자, 숫자 0-9, 그리고 +와 /)로 표현하는 방식을 의미합니다.
💥 짜르는 방식
2진(bit) 데이터를 6bit씩 자른 뒤, base64 색인표에 따라 치환하여 ASCII 문자열로 바꿔줍니다. 그런데 그냥 ASCII 문자열이 아니라, ASCII 중제어문자와 일부 특수문자를 제외한 64개의 안전한 출력문자만 사용하여 바꿉니다.
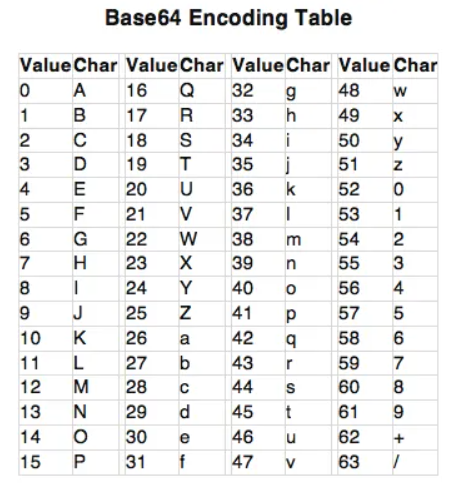
binary data를 바로 ASCII 인코딩을 하면 문제가 발생할 수 있기 때문에, base64 인코딩을 한다.
문자열로 전송하는 게 어떤 게 좋아?
문자열로 변환하면 더 많은 응용 프로그램에서 사용할 수 있습니다.
이진 데이터를 직접 전송하는 것은 어렵기 때문에, 문자열로 변환하여 전송하는 것이 더 쉽습니다.
또한, Base64로 인코딩된 문자열은 문자열로 다루기 쉽기 때문에, 다양한 응용 프로그램에서 사용될 수 있습니다.
데이터 크기는 줄어? x 늘어나!
🧐 네, 그 말은 틀린 설명이에요. 실제로는 Base64 인코딩을 하면 데이터 크기가 약 33% 증가합니다 — 줄어드는 게 아니라요!
📌 왜 크기가 늘어날까?
Base64는 3바이트의 이진 데이터를 4바이트의 ASCII 문자로 변환하는 방식이에요. 이 과정에서:
- 3바이트 → 4바이트로 변환 → 약 33% 증가
- 예를 들어, 300KB 이미지 → Base64 인코딩 시 약 400KB로 커짐
이건 Base64의 구조적 특성 때문이며, 모든 Base64 인코딩은 이 증가율을 갖습니다.
🔍 그럼 왜 쓰는 걸까?
Base64는 텍스트 기반 환경에서 바이너리 데이터를 안전하게 전송하기 위해 사용돼요:
- JSON, XML, HTML 같은 텍스트 포맷에 이미지나 파일을 포함할 때
- 이메일 첨부파일(MIME), JWT 토큰, CSS 인라인 이미지 등에 활용
- 특수 문자나 제어 문자를 피하고, 플랫폼 간 호환성을 높이기 위해
⚠️ 주의할 점
- 대용량 파일에는 비효율적 → 용량 증가 + 디코딩 비용
- 성능 저하 가능성 있음 → 특히 브라우저에서 이미지 처리 시
요약하자면, Base64는 전송 안정성과 호환성을 위해 쓰는 것이지, 용량 최적화를 위한 기술은 아니에요. 오히려 용량이 늘어나기 때문에, 꼭 필요한 경우에만 사용하는 게 좋아요 😄
💥 URL 인코딩이랑 달라.
URL인코딩은 퍼센트인코딩으로, url상에서 문자를 표현하기 위한 인코딩이다. 예를 들어 http://naver.com/에 query=고양이 라는 데이터를 표현하면 http://naver.com/?query=%B%A%C <-대략 이런식으로 바꾸는 처리를 말한다.
웹 브라우저가 URL을 처리할 때 기본적으로 사용하는 인코딩 방식은 Percent Encoding(퍼센트 인코딩) 또는 URL Encoding(URL 인코딩)이라고 합니다.
🏷️ Percent Encoding의 특징
- URL에서 사용할 수 없는 문자(예: 공백, 특수문자)를 특정 코드(%)와 함께 변환하여 안전하게 전송
- 예를 들어, 공백(
" ") →%20으로 변환 "@","#","?"같은 특수문자도%기호와 함께 인코딩됨
🛠 예제
hello world→hello%20worldC++→C%2B%2B서울&부산→%EC%84%9C%EC%9A%B8%26%EB%B6%80%EC%82%B0
특히 GET 방식에서 브라우저는 자동으로 사용자가 입력한 데이터를 Percent Encoding 방식으로 변환하여 서버로 전송합니다.
서버는 이를 디코딩하여 원래 문자열로 복원합니다.
그럼 이미지 또는 영상은 어떤 값으로 나오게 돼? 이것도 ASCII code 로 처리하나?
이미지와 영상은 기계어 이진수(0과 1)로 표현(이진(binary) 데이터)되며, ASCII 코드로 처리되지는 않습니다!
ASCII 코드는 문자와 기호를 표현하는 데 사용되는 방식이고, 이미지나 영상은 훨씬 더 복잡한 구조를 가지고 있습니다.
이미지의 데이터 표현
이미지는 픽셀 단위로 구성됩니다. 각 픽셀은 특정 색상 정보를 나타내며, 색상은 보통 RGB(Red, Green, Blue) 모델로 표현됩니다. 예를 들어:
- RGB 이미지의 경우 각 픽셀이 3개의 값(빨강, 초록, 파랑)으로 구성됩니다.
- 색상 정보는 8비트(256단계)로 표현되며, 이를 통해 총 16,777,216개의 색상을 나타낼 수 있습니다.
이미지는 파일로 저장될 때 비트맵(Bitmap), JPEG, PNG 같은 형식으로 압축되거나 처리됩니다. 이런 파일들은 픽셀 데이터를 이진수로 변환하여 저장합니다.
영상의 데이터 표현
영상은 이미지 프레임의 연속으로 이루어져 있으며, 각 프레임은 위와 같은 방식으로 픽셀 단위로 표현됩니다.
- FPS (Frame Per Second): 초당 몇 개의 이미지를 보여줄지 결정합니다.
- 영상은 추가적으로 오디오 데이터와 함께 압축됩니다.
이미지/영상 파일의 저장 방식
- RAW 파일: 압축되지 않은 데이터로, 각 픽셀의 RGB 값을 이진수로 저장.
- 압축 파일(JPEG, MP4): 데이터를 효율적으로 저장하기 위해 특정 알고리즘을 사용해 압축.
결론적으로 이미지와 영상은 ASCII 코드보다는 바이너리 데이터, 즉 이진수로 처리되며, 디지털 세계에서는 이 값을 다양한 방식으로 해석하여 표현합니다.
문자열, 이미지, 영상에서는 스트리밍이라는 용어가 있어. 스트리밍이라는 것은 이진수를 어떻게 처리해?
스트리밍은 문자열, 이미지, 영상 등 디지털 데이터를 네트워크를 통해 실시간으로 전송하고 처리하는 기술을 의미합니다. 이진수로 표현된 데이터를 스트리밍하는 과정은 다음과 같은 방식으로 이루어집니다:
1. 이진수로 데이터 인코딩
모든 디지털 데이터는 결국 0과 1로 이루어진 이진수로 변환됩니다. 예를 들어:
- 문자열은 텍스트를 ASCII 또는 UTF-8과 같은 문자 인코딩 방식으로 변환합니다.
- 이미지는 픽셀 정보를 압축 알고리즘(JPEG, PNG 등)으로 처리하여 전송 가능한 이진 데이터로 만듭니다.
- 영상은 프레임 단위로 데이터를 압축하며, H.264와 같은 코덱으로 처리하여 효율적으로 이진수로 변환합니다.
2. 네트워크를 통한 전송
이진수로 변환된 데이터는 작은 단위(패킷)로 쪼개져 인터넷 프로토콜(IP)을 통해 전송됩니다.
- 데이터 패킷은 원본 파일을 작은 조각으로 나눈 형태로, 각각 고유의 헤더를 가지고 있어 목적지에서 올바른 순서로 재조립될 수 있습니다.
3. 스트리밍 기술
스트리밍 과정에서는 실시간 처리가 중요합니다. 이를 위해 다음과 같은 방법이 사용됩니다:
- 버퍼링: 데이터를 잠시 저장하여 끊김 없이 재생되도록 합니다.
- 비트 레이트: 전송 속도에 맞춰 데이터 품질을 조정합니다. 네트워크 상황에 따라 고화질/저화질로 동적 변경됩니다.
- 코덱: 데이터를 압축하고 복원하는 방식으로, 스트리밍에서 효율성을 높이는 핵심 역할을 합니다.
4. 클라이언트 측 처리
스트리밍된 데이터는 클라이언트(사용자의 기기)에서 디코딩되어 사용자가 읽거나 재생할 수 있는 형태로 복원됩니다:
- 문자열은 다시 문자로 변환됩니다.
- 이미지는 픽셀로 복구됩니다.
- 영상은 프레임과 오디오 데이터를 결합하여 보여줍니다.
스트리밍의 중요성
스트리밍은 실시간 데이터를 효율적으로 전달하기 위해 개발된 기술로, 현대의 인터넷 환경에서 가장 핵심적인 기술 중 하나입니다. YouTube, Netflix, Twitch 같은 플랫폼은 이 기술을 활용해 대용량 데이터(영상, 음악 등)를 빠르게 제공하고 있습니다.
✅ 그래서 이미지는
- 이미지 자체는 바이트 스트림으로 처리됨
- 내부를 보면 문자열처럼 보이는 건 Base64 인코딩 때문
- 원래는 사람이 읽을 수 없는 이진 데이터임
🔍 왜 이미지를 Base64로 인코딩할까?
이미지는 본래 바이너리 데이터인데, 웹에서 사용하는 JSON, XML, HTML 같은 포맷은 텍스트 기반이라 바이너리를 직접 담을 수 없어요. 그래서...
✅ Base64 인코딩의 이유
- 텍스트 기반 환경에서 안전하게 전송하기 위해
- 특수 문자나 제어 문자 문제 방지 (예:
\0,\n,\r등) - 이메일, JSON, URL 등에서 호환성 확보
- 이미지를 HTML/CSS에 직접 삽입 가능 (
data:image/png;base64,...형태)
Base64는 3바이트를 4바이트로 변환하므로 약 33% 용량 증가가 생기지만, 텍스트 환경에서는 안정성이 더 중요할 때가 많아요.
🧪 바이트 스트림 vs Base64 인코딩
| 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 바이트 스트림 전송 | 이미지 파일을 그대로 바이너리로 전송 | 빠르고 효율적 | JSON 등 텍스트 기반에서는 사용 불가 |
| Base64 인코딩 후 전송 | 바이너리를 텍스트로 변환해 JSON 등에 포함 | 텍스트 환경에서 안전 | 용량 증가, 디코딩 필요 |
⏳ 인코딩 시점은 언제일까?
✅ 일반적인 흐름
-
클라이언트 측 (브라우저):
- 사용자가 이미지를 선택하면
FileReader또는Blob을 통해 바이트로 읽음 - 필요 시
Base64로 인코딩 (readAsDataURL()사용)
- 사용자가 이미지를 선택하면
-
서버 측 (Spring, Node 등):
multipart/form-data로 전송된 이미지를InputStream또는byte[]로 처리- 서버에서 Base64로 인코딩하는 경우는 응답에 JSON으로 포함할 때가 많음
즉, 인코딩 시점은 전송 목적에 따라 다르며, JSON에 포함하거나 HTML에 직접 삽입할 때 주로 Base64 인코딩이 사용돼요.
💡 언제 Base64를 쓰면 좋을까?
- 이미지가 작고 빠르게 삽입되어야 할 때 (예: 아이콘, 프로필 사진)
- 서버 없이 HTML/CSS에 직접 포함하고 싶을 때
- API 응답에 이미지 포함해야 할 때
반대로, 대용량 이미지나 영상은 Base64보다 파일 업로드 방식(multipart)이 훨씬 효율적이에요.
🖼️ 이미지 자체를 데이터베이스에 저장할 수 있을까?
이미지 자체를 데이터베이스(DB)에 저장할 수는 있지만, jsonb 타입은 적절하지 않습니다. 이미지처럼 바이너리(binary) 데이터를 저장할 때는 다른 타입을 사용하는 게 맞아요.
📦 이미지 저장 방식 2가지
| 방식 | 설명 | 추천 타입 |
|---|---|---|
| DB에 직접 저장 | 이미지 파일을 DB에 저장 | BLOB, BYTEA, LONGBLOB, VARBINARY 등 |
| 파일 시스템에 저장 + DB에 경로 저장 | 이미지 파일은 서버에 저장하고, DB에는 경로(URL)만 저장 | VARCHAR, TEXT 등 |
❌ 왜 jsonb는 부적절할까?
jsonb는 구조화된 텍스트 데이터를 저장하기 위한 타입이에요 (예: 설정값, 메타데이터 등).- 이미지 데이터를 Base64로 인코딩해서
jsonb에 넣을 수는 있지만:- 용량이 33% 이상 증가하고
- 쿼리 성능이 저하되며
- 인덱싱이나 검색이 어려움 → 특히 대용량 이미지에 불리함
- jsonb는 주로, 메타데이터로 저장할시 사용합니다!
예시
INSERT INTO products (name, metadata)
VALUES (
'Laptop',
'{
"brand": "Dell",
"model": "XPS 13",
"specs": {
"cpu": "i7",
"ram": "16GB",
"storage": "512GB SSD"
}
}'
);✅ 올바른 타입 예시
- PostgreSQL:
BYTEA또는OID(대용량 객체) - MySQL:
BLOB,LONGBLOB - Oracle:
BLOB - SQL Server:
VARBINARY(MAX)
💡 실무에서는 어떻게 할까?
대부분의 경우, 이미지 파일은 파일 시스템이나 클라우드 스토리지(AWS S3 등)에 저장하고, DB에는 파일 경로(URL)만 저장해요. 이유는:
- DB 백업/복구가 간편해짐
- 성능과 확장성에 유리
- 이미지 처리(썸네일, CDN 등)에 유연함
