Cache란 자주 사용하는 데이터를 미리 저장해놓고 다시 이 데이터를 필요로 할 때마다 빠르게 참조하여 읽기 기능을 개선하는 기술입니다.
현재 진행 중인 프로젝트에서 성능 개선을 위해 캐시를 도입, 그 기술로 Redis를 선택했습니다.
대규모 트래픽을 처리해야 하는 상황에서 데이터베이스 서버에 동일한 요청을 여러 번 작업요청을 하는 것은 큰 부하가 많이 걸리는 일입니다.
그러나 단순히 트래픽만 많다고 선정하면 곤란합니다. 데이터 정합성 문제도 생각해봐야 했습니다. 왜냐하면, 캐싱처리로 미리 저장한 작업 내용이 update가 안될 때 참조하면 사용자는 잘못된 데이터를 읽게 되기 때문입니다.
그래서 캐싱처리는 업데이트가 느리면서도 읽기 트래픽이 많이 필요한 요건을 갖춘 곳에 처리하는 것이 선택의 중요포인트였습니다.
결국 프로젝트에 캐싱을 진행한 영역은 StudyGroup, Reservation 을 선택하였습니다. 데이터 정합적인 면에선 데이터 update가 많이 일어나지 Reservation도 있지만, StudyGroup도 상대적으로 사용자가 얼마나 update를 할지 가늠할 수 없었습니다. 그래서 향후 검증 테스트를 거치기 전까진 둘 영역 도무 적용하기로 했습니다.
캐시전략으로 Cache-Aside 방식 채택
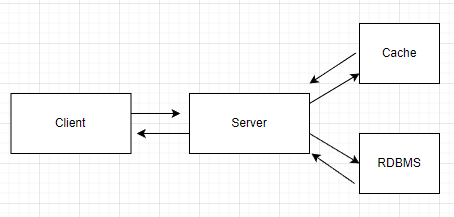
- Server는 Client로부터 요청을 받습니다.
Cache에 데이터가 있는지확인합니다. 만약 존재한다면 해당 데이터를 Client에게 다시 반환합니다.Cache에 데이터가 없다면DBMS를 통해 데이터를 가지고 옵니다.- 그리고 Cache에 데이터를 등록하고, Client에게 다시 반환합니다.
Local Cache vs Global Cache
캐시를 사용하기 전에 먼저 어떤 캐싱 전략을 사용할지 고민했습니다. 캐싱 전략에는 크게 Local Cache, Global Cache가 있습니다.
Local Cache는 서버 내부 저장소에서 데이터를 관리하는 것입니다. 서버 내에서 동작하기 때문에 속도가 빠르지만 각 서버 간의 데이터 공유가 안된다는 단점이 있습니다. 이외에도 서버의 자원을 사용하기 때문에 자원적인 이슈가 발생할 수 있습니다.
Global Cache는 서버 내부 저장소가 아닌 별도의 캐시 서버를 구성하는 방법입니다. 별도의 캐시 서버를 구성함으로써 각 서버들 모두 그 별도의 캐시 서버를 참조하게 됩니다. 네트워크를 타야 해 Local Cache에 비해 속도는 느리지만, 각 서버 간의 데이터를 서로 공유할 수 없다는 단점은 해결할 수 있습니다.
저는 다수의 서버 환경을 구성하는 서버 분산 프로젝트를 기획했기에 이방식을 채택했습니다. 따라서 Global Cache 전략으로 별도의 Redis 서버를 구성했습니다.
캐싱 관련 개념들
-
캐시 적중(Cache Hit): 캐시에 접근해 데이터를 발견함 -
캐시 미스(Cache Miss): 캐시에 접근했으나 데이터를 발견하지 못함 -
캐시 삭제 정책(Evicition Policy)
=> 캐시를 언제 제거할 것인가?- Expiration: 각 데이터에 TTL(Time-To-Live)을 설정해 시간 기반으로 삭제
Eviction Algorithm: 공간을 확보해야 할 경우 어떤 데이터를 삭제할지 결정하는 방식
1)LRU(Least Recently Used): 가장 오랫동안 사용되지 않은 데이터를 삭제
2)LFU(Least Frequently Used): 사용빈도수가 낮은 데이터를 삭제(최근에 사용되었더라도)
3)FIFO(First In First Out): 먼저 들어온 데이터를 삭제
-
캐시 전략: 환경에 따라 적합한 캐시 운영 방식을 선택할 수 있어야 함
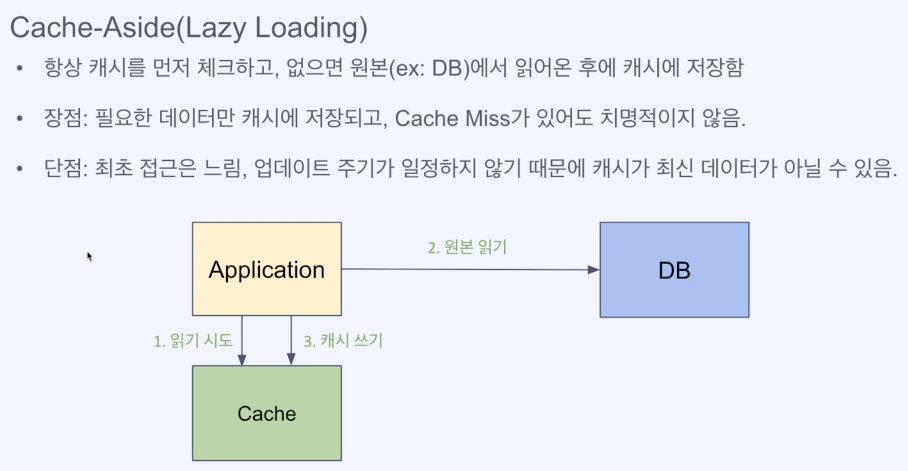
1) Cache-Aside(가장 일반적인 형태), 실제 프로젝트에도 이 방식 사용
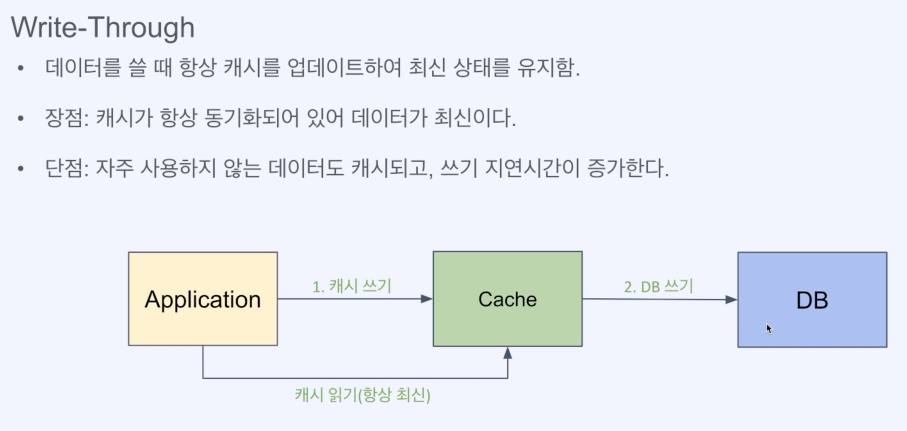
2) Write-Through(캐시가 항상 최신화)
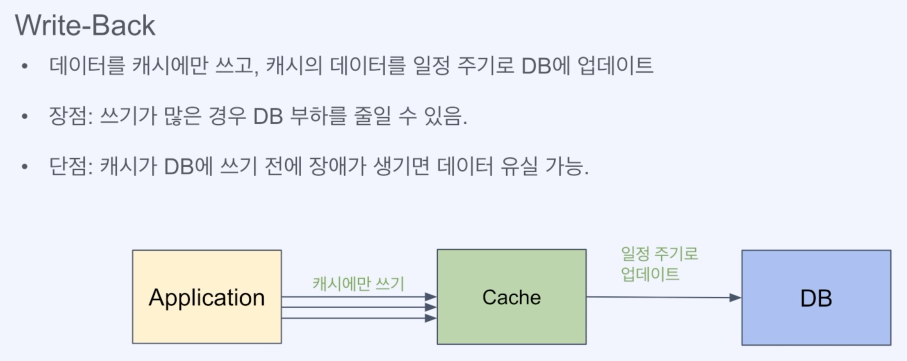
3) Write-Back(완전히 캐시를 DB처럼 사용)
스프링 제공 캐시 어노테이션 @Cacheable, @CacheEvict
스프링은 Redis와 별개로 캐시 추상화해서 제공하는 디팬더시를 제공해줍니다. 이 디팬더시 관련 어노테이션으로 캐시 사용을 쉽게 할 수 있습니다.
자세한 설정은 이 블로그를 참조해주세요.
https://velog.io/@mooh2jj/Redis-Cacheable-CacheEvict
@Cacheable
: @Cacheable은 해당 메서드를 실행하기 전 캐시 저장소를 확인합니다. 캐싱데이터가 있다면메서드를 실행하지 않고캐시 데이터를 반환하고, 캐싱데이터가 없다면메서드를 실행하고 결괏값을캐시저장소에 저장합니다.
@Cacheable(key = "#roomId", value = RESERVATION_LIST, cacheManager = "redisCacheManager")
@Transactional(readOnly = true)
@Override
public List<ReservationDetails> getByRoomId(Long roomId) {
Room room = roomRepository.findById(roomId)
.orElseThrow(() -> {
log.error("room 대상이 없습니다. roomId: {}", roomId);
throw new WSApiException(ErrorCode.NO_FOUND_ENTITY, "can't find a Room by " +
" roomId: " + roomId);
});
return reservationRepository.findByRoomId(room.getId()).stream()
.map(this::mapToDto)
.collect(Collectors.toList());
}@CacheEvict
: @CacheEvict는 해당 키에 해당하는 캐시 데이터를 삭제합니다. 캐싱 대상 데이터의 save작업이나 update작업 이 일어나는 경우 적용하는 것이 좋습니다. 저는 save 작업에 적용했습니다.
@CacheEvict(key = "#roomId", value = RESERVATION_LIST, cacheManager = "redisCacheManager")
@Transactional
@Override
public ReservationDetails create(Long studyGroupId, Long roomId, ReservationCreateRequest reservationRequest) {
Reservation reservation = validateCreateRequest(studyGroupId, roomId, reservationRequest);
Reservation saveReservation = reservationRepository.save(reservation);
return mapToDto(saveReservation);
}
실제 테스트
첫 번째 read요청입니다. 아직 캐시 저장소에 캐싱되지 않은 상태라 응답 시간이 517ms가 걸렸습니다. 요청이 끝나면 캐시가 저장된 것을 확인할 수 있습니다.
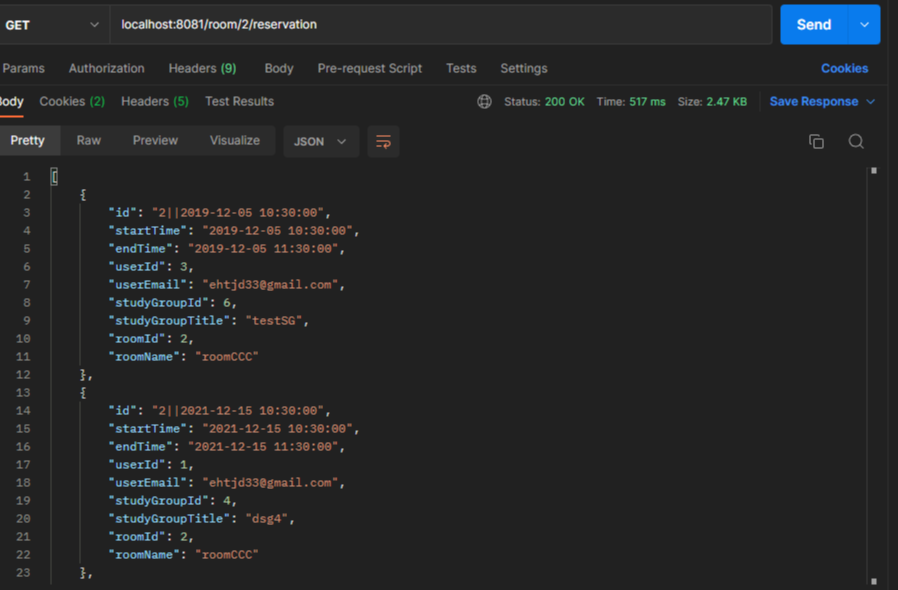
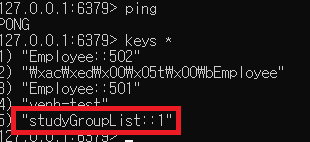
같은 요청입니다. 똑같은 요청이 캐싱처리로 응답 시간이 27ms로 굉장히 빨라진 것을 확인할 수 있었고 조회성능이 94.8% (517-27)/517 * 100나 개선이 된 것입니다.
😮 94.8 % 면 약 20배 빨라졌다는 뜻!