
SQL 종류
DDL - create, alter, drop, truncate, rename // DDL은 트랜잭션 발생 x
DCL - grant, revoke
DML - select, update, insert, delete
TCL - commit, rollback, SAVEPOINTINSERT
INSERT INTO User(ID, Name, BirthDay) VALUES(1, '김태하', '1992-11-04');-- 벌크성 쿼리: 여러 행을 한 번에 입력 가능
INSERT INTO people
-- (person_id, person_name, age, birthday)
VALUES
(4, '존 스미스', 30, '1991-03-01'),
(5, '루피 D. 몽키', 15, '2006-12-07'),
(6, '황비홍', 24, '1997-10-30');UPDATE
-- SET이 바뀌는 파트
UPDATE User SET Age = 30 WHERE Name = '김태하';DELETE
DELETE FROM User WHERE Name = '김태하';- where 조건절에 pk 등 인덱스가 된 컬럼을 넣어서 확인하는 게 좋음!
SELECT
SELECT
emp.emp_no AS empNo,
1 AS 'number',
'Hello' AS hello,
NULL AS 널
FROM employees emp
LIMIT 100, 10 -- 100번행부터 10개 출력
;LIMIT
LIMIT (n) - n개까지 출력
LIMIT (offset, n) - offset부터 시작해서 n개 출력
- offset: 가져오고자 하는 행 데이터의 시작 지점을 지정, 0부터 시작
SELECT *
FROM departments dep
WHERE 1=1
-- AND dep.dept_no > 1
ORDER BY dep.dept_no ASC
;
-- 범위로 데이터 찾기
select
userID,
name,
height
from userDB
where height >= 170 and height <= 180;
-- === between 숫자 and 숫자
select
userID,
name,
height
from userDB
where height between 170 and 180; -- 기준점을 모두 포함한다. 170부터 180MYSQL 데이타 타입
-- 문자형 데이터타입
CHAR(n) -- 고정 길이 데이터 타입(최대 255byte)- 지정된 길이보다 짦은 데이터 입력될 시 나머지 공간 공백으로 채워진다.
VARCHAR(n) -- 가변 길이 데이터 타입(최대 65535byte)- 지정된 길이보다 짦은 데이터 입력될 시 나머지 공간은 채우지 않는다.
TINYTEXT(n) -- 문자열 데이터 타입(최대 255byte)
TEXT(n) -- 문자열 데이터 타입(최대 65535byte) ~64KB
MEDIUMTEXT(n) -- 문자열 데이터 타입(최대 16777215byte) ~16MB
LONGTEXT(n) -- 문자열 데이터 타입(최대 4294967295byte) ~4GB
JSON -- JSON 문자열 데이터 타입 - JSON 형태의 포맷을 꼭 준수해야 한다.-- 숫자형 데이터타입
TINYINT(n) -- 정수형 데이터 타입(1byte) -128 ~ +127 또는 0 ~ 255수 표현할 수 있다.
SMALLINT(n) -- 정수형 데이터 타입(2byte) -32768 ~ 32767 또는 0 ~ 65536수 표현할 수 있다.
MEDIUMINT(n) -- 정수형 데이터 타입(3byte) -8388608 ~ +8388607 또는 0 ~ 16777215수 표현할 수 있다.
INT(n) -- 정수형 데이터 타입(4byte) -2147483648 ~ +2147483647 또는 0 ~ 4294967295수 표현할 수 있다.
BIGINT(n) -- 정수형 데이터 타입(8byte) - 무제한 수 표현할 수 있다.
DECIMAL(길이, 소수) -- 고정 소수형 데이터 타입고정(길이+1byte) - 더 정확, 소수점을 사용 형태이다.
DOUBLE(길이) -- 부동 소수형 데이터 고정 x
FLOAT(길이, 소수) -- 부동 소수형 데이터 타입(4byte) - 더 작은 범위, 고정 소수점을 사용 형태이다.-- 날짜형 데이터 타입
DATE -- 날짜(년도, 월, 일) 형태의 기간 표현 데이터 타입(3byte)
TIME -- 시간(시, 분, 초) 형태의 기간 표현 데이터 타입(3byte)
DATETIME -- 날짜와 시간 형태의 기간 표현 데이터 타입(8byte)
TIMESTAMP -- 날짜와 시간 형태의 기간 표현 데이터 타입(4byte) -시스템 변경 시 자동으로 그 날짜와 시간이 저장된다.
-- ’2020-03-26 09:30:27’ 이런 식으로 연, 월, 일, 시, 분, 초를 + 타임 존(time_zone) 정보도 함께 저장
YEAR -- 년도 표현 데이터 타입(1byte)✅ DATETIME vs TIMESTAMP 타입 비교
-
DATETIME:
입력된 시간을 그 값 자체로 저장,YYYY-MM-DD HH:MM:SS의 형태로 사용되며, '1001-01-01 00:00:00'부터 '9999-12-31 23:59:59'까지 입력. -
TIMESTAMP:
MySQL이 설치된 컴퓨터의 시간대를 기준으로 저장,YYYY-MM-DD HH:MM:SS(.FFFFFF)의 형태 사용, 타임 존(time_zone) 정보도 함께 저장 -
차이: Datetime 타입과 Timestamp 타입은
타임 존정보 저장 여부에서 차이가 있다.
(타임 존 : MySQL 서버의 시간대 UTC+9, UTC-11...)
만약 타임 존 정보를 굳이 함께 저장할 필요가 없다면 Datetime 타입을,
global하게 time을 저장하고 사용하고 싶다면, 타임존 정보가 필요하기에 Timestamp 타입을 설정하면 된다.
## 예시
예를 들어, 현재 서버의 시간대가 한국 시간대(KST)인 경우, 현재 시간은 2023년 3월 14일 오후 2시 30분입니다.
이 때, Timestamp 값으로 저장되는 시간 정보는 "2023-03-14 05:30:00"이 됩니다. 이는 Unix timestamp 형식으로 저장되어,
1970년 1월 1일 00:00:00 UTC를 기준으로 현재까지의 초 단위의 값으로 표현됩니다.
이렇게 저장된 Timestamp 값은 MySQL 서버와 클라이언트 간의 시간대 차이에 상관없이 일관된 시간 정보를 제공합니다.
즉, 클라이언트가 어떤 시간대에서 Timestamp 값을 조회하더라도, 저장된 값은 동일한 UTC 기준의 Unix timestamp 값으로 표시됩니다.
따라서, Timestamp는 서버와 클라이언트 간의 시간대 차이에 영향을 받지 않는 일관된 시간 정보를 저장할 때 유용한 데이터 타입입니다.-- 이진 데이터 타입
BINARY(n) & BYTE(n) -- CHAR의 형태의 이진 데이터 타입 (최대 255byte)
VARBINARY(n) -- VARCHAR의 형태의 이진 데이터 타입 (최대 65535byte)
TINYBLOB(n) -- 이진 데이터 타입 (최대 255byte)
BLOB(n) -- 이진 데이터 타입 (최대 65535byte)
MEDIUMBLOB(n) -- 이진 데이터 타입 (최대 16777215byte)
LONGBLOB(n) -- 이진 데이터 타입 (최대 4294967295byte)
함수들
형변환
-- CEIL 올림
SELECT CEIL(135.375); -- 136
-- ROUND 반올림
SELECT ROUND(135.375, 2); -- 135.38
-- FLOOR 버림
SELECT FLOOR(135.375); -- 135
-- TRUNCATE 제거
SELECT TRUNCATE(135.375, 2); --135.37-- CAST(expr AS type)
SELECT CAST(NOW() AS SIGNED);
> 20210527135358
SELECT CAST(20200101 AS DATE);
> 2020-01-01
SELECT CAST(20200101030330 AS CHAR);
> 20200101030330
문자열
-- CONCAT()
SELECT
dep.dept_no,
dep.dept_name,
concat(dep.dept_no, '||', dep.dept_name)
FROM departments dep
;
-- CONCAT_WS()
SELECT
CONCAT_WS('||',emp.emp_no, emp.birth_date, emp.hire_date) AS test
FROM employees emp
LIMIT 0, 10
;
-- LIKE `` : 문자열 찾기
SELECT
*
FROM employees emp
WHERE 1=1
AND emp.last_name LIKE 'P___'
AND emp.first_name LIKE 'M%'
AND DATE_FORMAT(emp.hire_date, '%Y%m%d') > '19950000'
;-- 문자열 자르기: SUBSTR(문자열, 시작위치, 길이), LEFT(), RIGHT()
SELECT
emp.emp_no,
LEFT(emp.hire_date, 4) AS YEAR,
SUBSTR(emp.hire_date, 6, 2) AS MONTH,
RIGHT(emp.hire_date, 2) AS DAY
FROM employees emp
;조건식 및 NULL함수
-- IF(조건, 참, 거짓)
SELECT
IF(NAME='HOON', 1, 2) AS NAME
FROM USER
;-- ISNULL(컬럼명, '컬럼이 Null일 경우 대체할 데이터')
-- IFNULL(컬럼명, '컬럼이 Null일 경우 대체할 데이터')
SELECT
ISNULL(NAME, "NO NAME") as NAME
FROM ANIMAL_INS
--
SELECT
IFNULL(moive_type, '모름')
FROM null_table
;-- NULLIF(expr1, expr2) : expr1 = expr2가 True이면 NULL을 리턴하고, 그렇지 않으면 expr1을 리턴한다
CASE WHEN expr1=expr2 THEN NULL
ELSE expr1 END-- CASE WHEN ... THEN .. ELSE .. END
CASE
WHEN 조건식1 THEN 식1
WHEN 조건식2 THEN 식2
...
ELSE 조건에 맞는경우가 없는 경우 실행할 식
END
날짜함수 및 포멧함수
-- 이렇게 간단히 정리가 가능!
SELECT
emp.emp_no,
-- 년, 달, 일, 요일
YEAR(emp.hire_date),
MONTH(emp.hire_date),
DAY(emp.hire_date),
WEEKDAY(emp.hire_date), -- 숫자로 나옴
DAYNAME(emp.hire_date)
FROM employees emp
;
-- TIME Tpye
SELECT CURDATE(), CURTIME(), NOW();
-- DATE_FORMAT: DATE -> STRING 타입으로 변환
SELECT
DATE_FORMAT(NOW(), '%M %D, %Y %T'),
DATE_FORMAT(NOW(), '%y-%m-%d %h:%i:%s %p'),
DATE_FORMAT(NOW(), '%Y년 %m월 %d일 %p %h시 %i분 %s초')
;-- STR_TO_DATE: STRING -> DATE 타입으로 변환
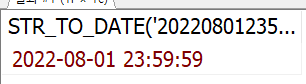
SELECT STR_TO_DATE('20220801235959', '%Y%m%d%H%i%s');
-- DATE_SUB() : 빼기 지난 전일 범위 지정할 때 많이 사용 vs DATE_ADD()
select *
from
TABLE_NAME
where 1=1
AND DATE(TIMESTAMP_COLUMN) >= DATE_SUB(NOW(), INTERVAL 7 DAY);
-- TIMESTAMP() 함수
SELECT TIMESTAMP('2015-11-10'); -- 반환값은 DATETIME
--> 2015-11-09 00:00:00
-- FORMAT() : Query(쿼리) 구문을 통해서 숫자에 3자리에 콤마를 바로 설정하여 출력
SELECT
id,
cnt,
FORMAT(cnt, 0) AS format_cnt
FROM
test_table;
[OUTPUT]
---------------------------------
id cnt format_cnt
---------------------------------
1 10 10
2 100 100
3 1000 1,000
4 10000 10,000
5 100000 100,000 집계함수
-- MAX(), 집계함수를 쓴다? GROUP BY!
SELECT
sal.emp_no,
MAX(sal.salary) AS MaxPrice -- alias
FROM salaries sal
GROUP BY sal.emp_no
-- HAVING : GROUP BY의 조건절, 집계함수 내용의 조건을 걸땐 where x -> HAVING임!
HAVING MAX(sal.salary) > '150000'
ORDER BY MaxPrice DESC
;
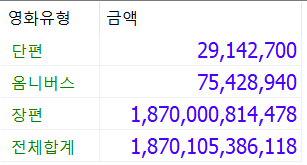
-- WITH ROLLUP, GROUPING()함수를 써서 합계아름 붙이기
SELECT
-- *
IF(GROUPING(movie_type)=1, '전체합계', IFNULL(movie_type, '모름')) 영화유형 , SUM(sale_amt) 금액
FROM box_office
WHERE YEAR(release_date) = 2019
-- AND sale_amt > 10000000
GROUP BY movie_type WITH ROLLUP
;
;
💖
# 가장 결제이력이 많은 사용자 50명의 선호 카테고리 랭크를 조회
select ph.user_id, u.name, ui.favorite_category, count(ph.final_price)
from payment_histories ph join users u on ph.user_id = u.id
join user_infos ui on u.id = ui.user_id
group by ph.user_id, ui.favorite_category
order by count(ph.final_price) desc
limit 50;
쿼리 실제 실행 순서
1) FROM : 각 테이블 확인 -- From절부터 시작!
ON : 조인 조건 확인
JOIN : 테이블 조인 (병합)
2) WHERE : 데이터 추출 조건 확인
3) GROUP BY : 특정 칼럼으로 데이터 그룹화
HAVING : 그룹화 이후 데이터 추출 조건 확인
4) SELECT : 데이터 추출 DISTINCT : 중복 제거
5) ORDER BY : 데이터 정렬은 가장 마지막!활용
여러 id는 JOIN + temp 사용해서 전체 삭제하기
# 안좋은 예시
DELETE FROM product
WHERE id IN (
SELECT p.id FROM product p WHERE p.del_flag = 1
);
☑️ temp 임시 테이블로 설정해야!
DELETE p
FROM product p
INNER JOIN (SELECT id FROM product WHERE del_flag = 1) temp
ON p.id = temp.id;중복되는 항목 찾기
SELECT COLUMN_NAME1 , -- 중복되는 데이터
COLUMN_NAME2 ,
COUNT(*) AS cnt -- 중복 갯수
FROM TABLE_NAME -- 중복조사를 할 테이블 이름
GROUP BY COLUMN_NAME1, COLUMN_NAME2 -- 중복되는 항목 조사를 할 컬럼들, id값은 식별되므로 넣으면 x
HAVING cnt > 1 ; -- 1개 이상 (갯수)예시
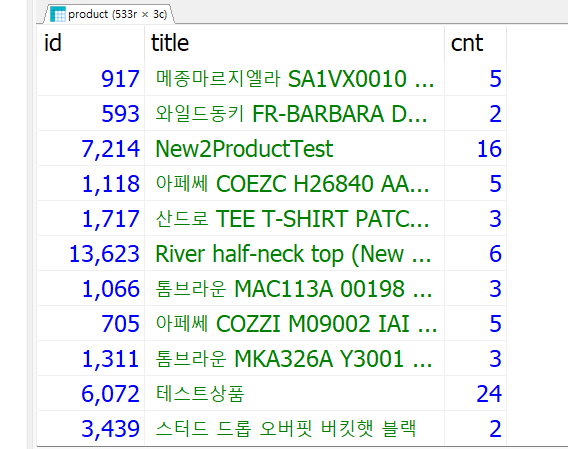
SELECT
p.id,
p.title,
COUNT(*) AS cnt
FROM
product p
GROUP BY p.title
HAVING
cnt > 1;
서브쿼리
-- 스칼라 서브쿼리
# 세글자로 된 과목명을 가진 과목의 그 과목강의를 진행하는 강사를 조회
SELECT id, name, (SELCT name from teachers where id = teacher_id) as teacher_name
FROM subjects
WHERE name like '___'
-- 인라인뷰 서브쿼리
SELECT
T.empNo,
T.salarySum
FROM
(
SELECT
sal.emp_no AS empNo,
SUM(sal.salary) AS salarySum
FROM salaries sal
WHERE 1=1
AND sal.salary > '100000'
GROUP BY sal.emp_no
-- ORDER BY SUM(sal.salary) DESC
) as T
WHERE 1=1
AND T.salarySum > '1200000'
;종류
1) where절에 있는 서브쿼리 - 중첩서브쿼리
2) From절에 있는 서브쿼리 - 인라인뷰 서브쿼리
3) select절에 있는 서브쿼리 - 스칼라(단일) 서브쿼리
JOIN
- 여러 테이블의 데이터의 정보를 한번에 가져오기 위해서 사용
- FK 값을 이용해서 Join 할 수 있다.
- 즉, Relationships 관계 있는 데이블끼리는 Join을 이용해서 한번에 질의할 수 있다.
- Join 은 Select, Delete, Update 문과 함께 사용될 수 있다
서브쿼리와 비교
-- 스칼라 서브쿼리
# 세글자로 된 과목명을 가진 과목의 그 과목강의를 진행하는 강사를 조회
SELECT subjects.name as subject_name, teachers.name as teacher_name
FROM subjects join teachers on subjects.teacher_id = teachers.id
WHERE subjects.name like '___'JOIN 종류
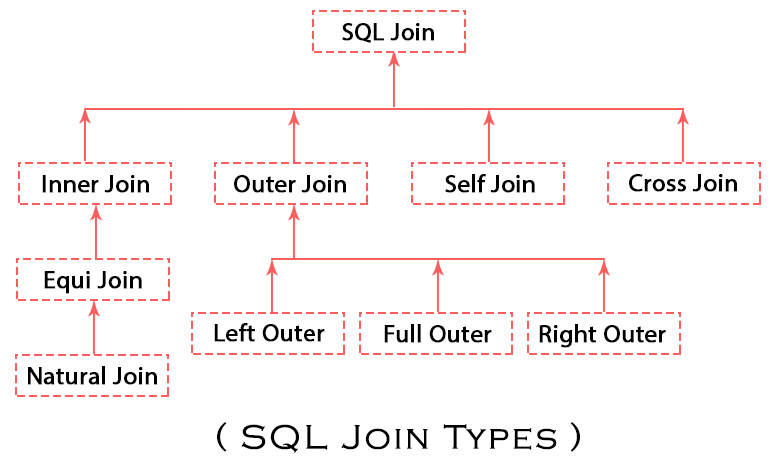
(INNER, LEFT, RIGHT FULL) `JOIN` 조인테이블 이름
`ON` 기준테이블이름.기준키 = 조인테이블이름.기준키
;-
INNER JOIN: 기준이 되는 테이블 (left table)과 join이 걸리는 테이블(right table) 양쪽 모두에 matching되는 row만 select가 됨. -
LEFT[OUTER] JOIN: 기준이 되는 테이블 (left table)의 모든 row와 join이 걸리는 테이블(right table)중 left table과 matching되는 row만 select가 됨.
INTER JOIN (교집합)
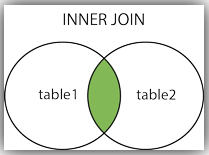
-- (inner) Join
SELECT
count(*)
FROM employees emp
INTER JOIN salaries sal
ON emp.emp_no = sal.emp_no
WHERE 1=1
AND sal.salary > 100000
AND DATE_FORMAT(emp.hire_date, '%Y%m%d') > '19900000'
AND emp.gender = 'M'
ORDER BY sal.from_date DESC
LIMIT 0, 20
;
OUTER JOIN (차집합)
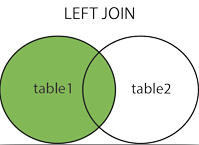
SELECT `index`, l.name as lname, s.name as sname, t.name as tname
FROM lectures l left join subjects s on l.subject_id = s.id
left join teachers t on s.teacher_id = t.id;
-- LEFT (outer) JOIN
SELECT
count(*)
FROM employees emp
LEFT JOIN salaries sal
ON emp.emp_no = sal.emp_no
WHERE 1=1
AND sal.salary > 100000
AND DATE_FORMAT(emp.hire_date, '%Y%m%d') > '19900000'
AND emp.gender = 'M'
ORDER BY sal.from_date DESC
LIMIT 0, 20
;
CROSS JOIN
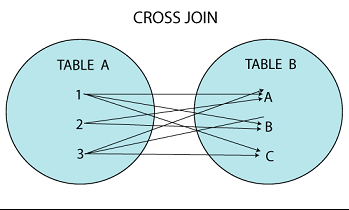
: 조건 없이 모든 조합 반환(A * B)
SELECT
E1.LastName, E2.FirstName
FROM Employees E1
CROSS JOIN Employees E2
ORDER BY E1.EmployeeID;UNION (합집합)
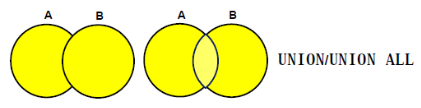
union: 중복값 제거하는 합집합union All: 중복값 있는 합집합- 💥주의사항: 조회하는 칼럼들의 갯수와 종류가 꼭 같아야 한다!
select name, height
from usertbl
where height = (select max(height) from usertbl)
union -- 중복 x
select name, height
from usertbl
where height = (select min(height) from usertbl);
union all
👀 주로 중복값을 제거하는
inner join또는union을 사용해야 한다고 생각할 수 있지만 실무에서는left[outer] join,union All을 더 많이 사용한다.
왜냐하면실제 잘못된 값을 확인하기 위해서다.
Transaction
START TRANSACTIONROLLBACKCOMMIT
START TRANSACTION; //트랜잭션 시작
SELECT * FROM my_table; //초기상태 보여줌
DELETE FROM my_table WHERE gender = 'M'; //데이터의 수정
SELECT * FROM my_table; //수정 후의 상태 보여줌
ROLLBACK; //트랜잭션이 선언되기 전 상태로 되돌아감
SELECT * FROM my_table; //수정 전의 초기 상태를 보여줌
START TRANSACTION; //다시 트랜잭션 시작
DELETE FROM my_table WHERE gender = 'M'; //수정
COMMIT; //트랜잭션 이후 모든 동작을 적용
SELECT * FROM my_table; //적용된 결과 보여줌SAVEPOINT
start transaction;
insert mystudy.test values ('옥수수','미국','심심함');
savepoint a;
insert mystudy.test values ('뽀로로','대구','노는게 제일좋아');
savepoint b;
insert mystudy.test values ('도우넛','서울','글레이즈드 도넛 최고');
rollback to a;
rollback;실습 환경
Database 설치
- File > Open SQL Script > ...
sakila-schema.sql - File > Open SQL Script > ...
sakila-data.sql
SELECT * FROM actor LIMIT 100;SELECT
F.title AS FilmTitle,
CONCAT(A.first_name, ' ', A.last_name) AS ActorName
FROM film F
LEFT JOIN film_actor FA
ON F.film_id = FA.film_id
LEFT JOIN actor A
ON A.actor_id = FA.actor_id
LIMIT 100;CLI로 실행해보기
- 윈도우:
C:\Program Files\MySQL\MySQL Server 8.0\bin - 맥:
/usr/local/mysql/bin
./mysql -u root -puse sakila;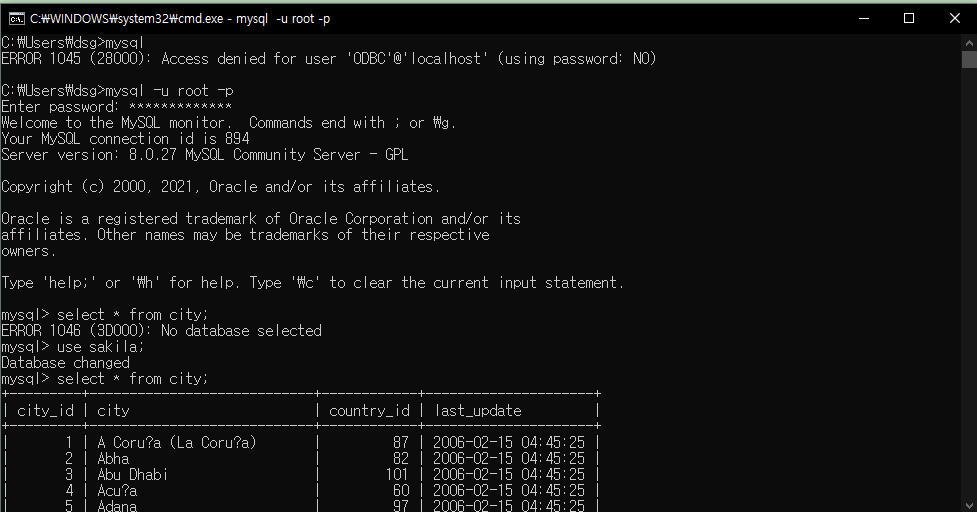
테이블 생성/수정/삭제
CREATE TABLE - 테이블 만들기
CREATE TABLE people (
person_id INT,
person_name VARCHAR(10),
age TINYINT,
birthday DATE
);- 테이블 생성시 제약 넣기
CREATE TABLE people (
person_id INT AUTO_INCREMENT PRIMARY KEY,
person_name VARCHAR(10) NOT NULL,
nickname VARCHAR(10) UNIQUE NOT NULL,
age TINYINT UNSIGNED,
is_married TINYINT DEFAULT 0
);- 제약 설명
AUTO_INCREMENT새 행 생성시마다 자동으로 1씩 증가
PRIMARY KEY중복 입력 불가, NULL(빈 값) 불가
UNIQUE중복 입력 불가
NOT NULLNULL(빈 값) 입력 불가
UNSIGNED(숫자일시) 양수만 가능
DEFAULT값 입력이 없을 시 기본값
✨PRIMARY KEY (기본키)
- 테이블마다 하나만 가능
- 기본적으로 인덱스 생성 (기본키 행 기준으로 빠른 검색 가능)
- 보통 AUTO_INCREMENT와 함께 사용
- ⭐ 각 행을 고유하게 식별 가능 - 테이블마다 하나씩 둘 것
💥insert시 제약조건에 위반한 건 오류남!
-- ex) age에 -2 오류남
INSERT INTO people
(person_name, nickname, age)
VALUES ('이불가', '임파서블', -2);ALTER TABLE - 테이블 변경
-- 테이블명 변경
ALTER TABLE people RENAME TO friends,
-- 컬럼 자료형 변경
CHANGE COLUMN person_id person_id TINYINT,
-- 컬럼명 변경
CHANGE COLUMN person_name person_nickname VARCHAR(10),
-- 컬럼 삭제
DROP COLUMN birthday,
-- 컬럼 추가
ADD COLUMN is_married TINYINT AFTER age;DROP TABLE - 테이블 삭제
DROP TABLE friends;그외
날짜확인
SELECT NOW();
-- 2023-10-19 04:47:59SELECT CURRENT_DATE;
-- 2023-10-19버전확인
SELECT VERSION();
-- > 8.0.21database characterSet, Collation 확인
SELECT SCHEMA_NAME AS 'database',
DEFAULT_CHARACTER_SET_NAME AS 'character_set', DEFAULT_COLLATION_NAME AS 'collation'
FROM information_schema.SCHEMATA
;필드명 확인
SELECT TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME -- 테이블, 컬럼 조회
FROM INFORMATION_SCHEMA.COLUMNS
WHERE 1=1
AND COLUMN_NAME LIKE '%guest_%' -- 필드명 체크
AND TABLE_SCHEMA='GBILLING' -- 스키마 작성
;데이터 확인
만약 데이터에서 찾는다면?
그냥 db 클라이언트 화면단에서 찾는게 더 낮다!

스토리지 엔진 확인
SELECT engine, support FROM information_schema.engines WHERE support='DEFAULT';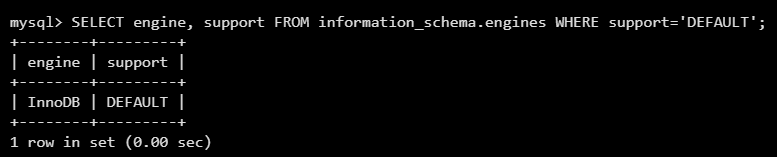
실행계획(Explain)
DB 튜닝이나 쿼리 최적화를 위해서 가장 먼저 해야 하는 것이 실행계획을 살펴보는 것이다.
사용 방법은 EXPLAIN을 쿼리 앞에 붙여주면 된다.
EXPLAIN SELECT * FROM dummy_test WHERE id=3 AND email = 'QS3aYM5YqB@gmail.com'Master & Slave 확인
show master status
show slave status
-- master로 명령어를 입력했을때 출력되면 그 DB서버는 master이고
-- 반대로slave에서 출력되면 그 DB서버는 slave이다.foreign key 무시하고 데이터 삭제하기
mysql> SET foreign_key_checks = 0; // 체크 해제
mysql> DELETE TABLE [테이블명] or TRUNCATE [테이블명]
mysql> SET foreign_key_checks = 1; // 다시 체크 설정AUTO_INCREMENT 초기화
-- 데이터가 없는 상태에서 실행해야
ALTER TABLE shop.items AUTO_INCREMENT=1;
SET @COUNT = 0;
UPDATE shop.items SET shop.items.item_id = @COUNT:=@COUNT+1;MySQL 예약어 막는 방법
@Column(name = "order")
private Long orderNo;
// 백틱(``)으로 이렇게 컬럼 이름을 한번 감싸주자
@Column(name = "`order`")
private Long orderNo;
Excel 축출하기
