Transformer
🗝 Keyword
⏪ Review
-
Attention의 장점에 대해서 생각하고 설명
-
RNN 모델의 단점 2가지
- 병렬화 불가 -> Transformer로 해결
(Time-step이 하나씩 입력돼서 병렬 처리 어려움) - 기울기 소실/폭발 -> LSTM, GRU로 해결
- 병렬화 불가 -> Transformer로 해결
-
장기 의존성(Long-term dependency)
- 처리하고자 하는 시퀀스가 길 때, 앞쪽 토큰의 정보 잃어버리는 문제
- 기울기 소실로부터 나타남
-> 고정된 벡터에 모든 Time-step의 정보가 쌓이기 때문에 첫 번째 정보일수록 소실될 확률 증가
-
Attention의 장점
-
Time-step마다 출력할 단어가 어떤 인코더의 어떤 단어 정보와 연관되어 있는지 => 어떤 단어에 집중(Attention)할 지를 알 수 있음
-> (전체 입력 문장을 전부 다 동일한 비율로 참고하는 게 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 봄) -
장기 의존성 문제 해결
-> 디코더가 인코더에 입력되는 단어 정보 모두 활용하기 때문
-
-
-
Transformer의 장점과 구조에 대해서 생각하고 설명
- "Attention is All You Need" (왜 논문 제목을 이렇게 지었을지에 대해서 생각해봅시다)
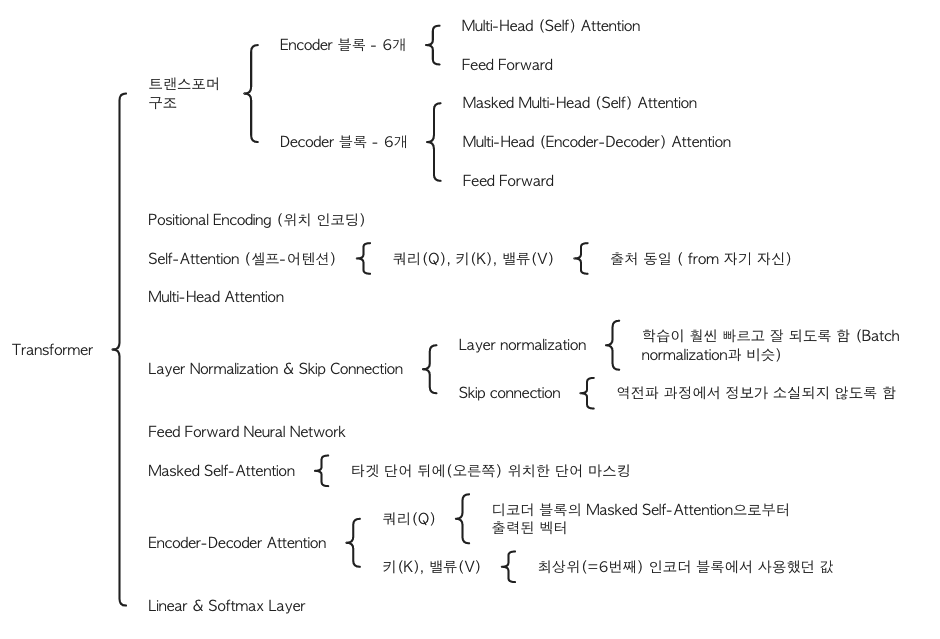
-> RNN을 사용하지 않고, 인코더-디코더 구조를 Attention만으로 구현한 모델이지만 RNN보다 성능이 우수함 - Positional Encoding : 단어의 상대적인 위치 정보를 담은 벡터를 만드는 과정
(트랜스포머 - 병렬화를 위해 모든 단어 벡터를 동시에 입력 받음 -> 컴퓨터가 단어 위치 알 수 X) - Self-Attention
- 트랜스포머 주요 메커니즘
- 문장 내 요소의 관계를 잘 파악하기 위해 문장 자신에 Attention 메커니즘 적용
- Masked Self-Attention
- 디코더 블록에서 사용하기 위해 마스킹 과정이 포함된 Self-Attention
- 타겟 단어 뒤에(오른쪽) 위치한 단어가 Self-Attention에 영향을 주지 않도록 마스킹(Masking)
-> RNN은 단어가 순차적으로 입력되지만, 트랜스포머는 타겟 문장이 한 번에 입력되기 때문 - 마스킹하는 단계: Softmax를 취해주기 전
- 가려줄 요소에만 만큼의 매우 작은 수 더함
- Encoder-Decoder Attention
- 번역할 문장과 번역될 문장의 정보 관계를 엮어주는 부분
- Self-Attention 아님
- 계산 과정은 Self-Attention과 동일
쿼리(Q)- 디코더 블록의 Masked Self-Attention으로부터 출력된 벡터키(K),밸류(V)- 최상위(=6번째) 인코더 블록에서 사용했던 값
- "Attention is All You Need" (왜 논문 제목을 이렇게 지었을지에 대해서 생각해봅시다)
_%20Photo.jpeg)