파티셔닝
파티셔닝 : 대용량 데이터베이스를 의도적으로 작은 단위로 쪼개는 방법 (샤딩)
파티셔닝과 복제
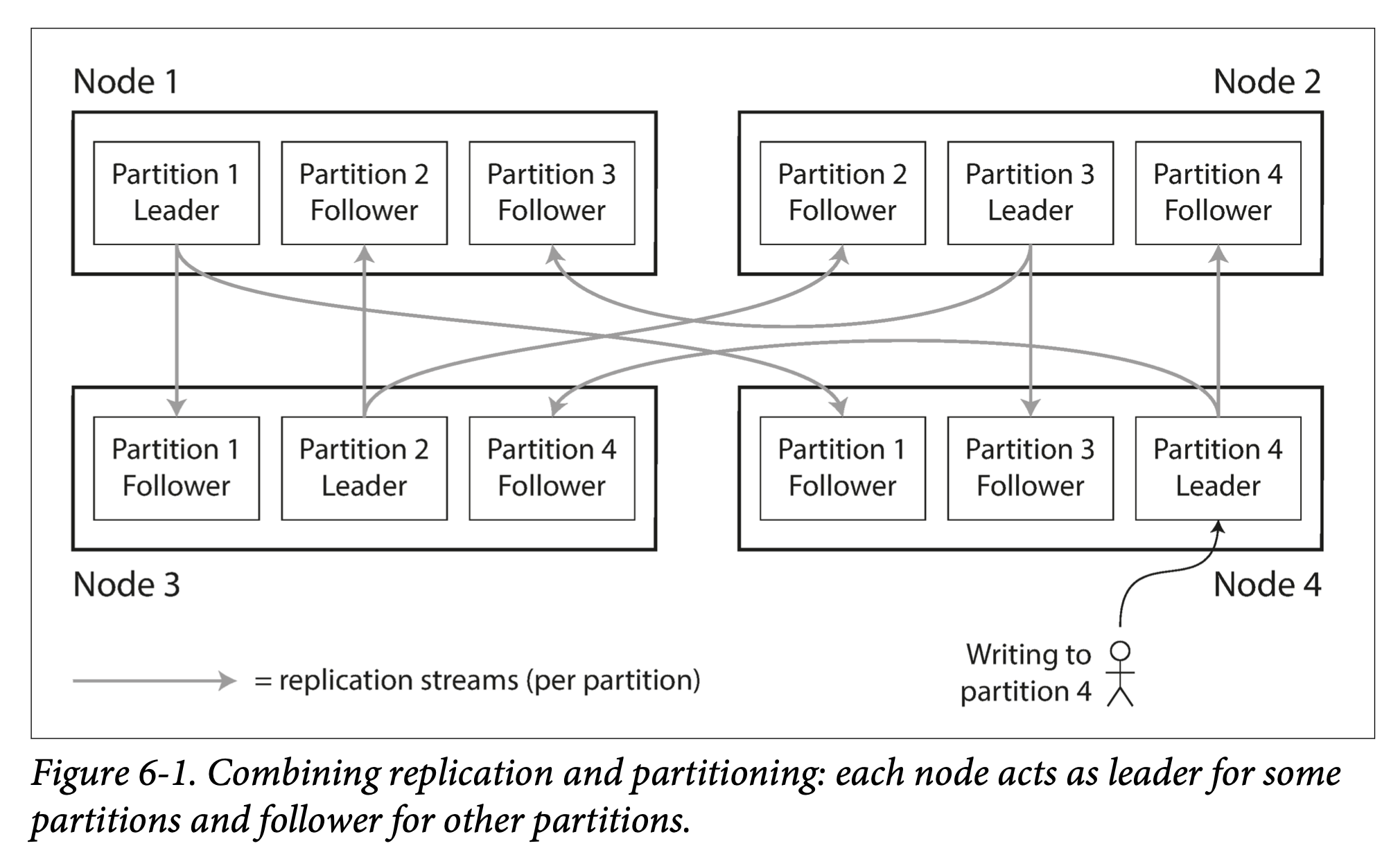
복제와 파티셔닝을 함께 적용해 각 파티션의 복사본을 여러 노드에 저장한다.
각 노드는 여러 파티션으로 구성될 수 있으며, 각 노드는 리더이자 팔로워가 된다.
키-값 데이터 파티셔닝
파티셔닝의 목적은 데이터와 질의 부하를 노드 사이에 고르게 분산시키는 것이다.
파티셔닝이 고르게 이뤄지지 않아 다른 파티션보다 데이터가 많거나 질의를 많이 받는 파티션이 있다면 skewed되었다고 하고 hotspot이라고 부른다.
키 범위 기준 파티셔닝
파티셔닝의 단위를 범위를 가지는 키로 적용한다.
이 경우에도 특정 범위의 키로 질의가 쏠리는 경우가 발생할 수 있다.
이를 회피하고자 한다면 키의 첫번째 요소를 변경할 필요가 있다.
ex)
as-is: timestamp
to-be: type + timestamp
키의 해시값 기준 파티셔닝
데이터가 쏠리는 현상을 막기 위해서 키를 해싱한 값으로 파티셔닝한다.
해시함수는 암호적으로 강력할 필요는 없다.

일관성 해싱 === 해시 파티셔닝
해싱 파티셔닝은 범위 질의를 효율적으로 실행할 수 없고, 재균형화도 잘 동작하지 않는다.
따라서 복합 기본키를 사용하여 1차적으로는 해싱으로 질의를 한 후 2차적으로 범위 질의를 보낼 수 있다. (cassandra, dynamoDB?)
쏠린 작업부화와 핫스팟 완화
해싱을 하더라도 동일 키에 대한 접근이 많아져서 쏠림현상이 발생할 수 있다.
이 경우에는 부하가 걸릴 것으로 예상되는 키를 한번 더 분할함으로써 이를 완화할 수 있다. 해시키 뒤에 임의의 숫자를 붙이는 방법을 사용할 수 있다.
하지만 같은 키를 읽기 위해 조회의 수가 많아지는 trade off가 발생한다.
파티셔닝과 보조색인
엘라스틱서치 등의 검색 서버는 보조색인이 존재의 이유이다.
하지만 보조색인은 파티셔닝에 깔끔하게 대응되지 않는 문제가 발생한다.
문서 기준 보조 색인 파티셔닝
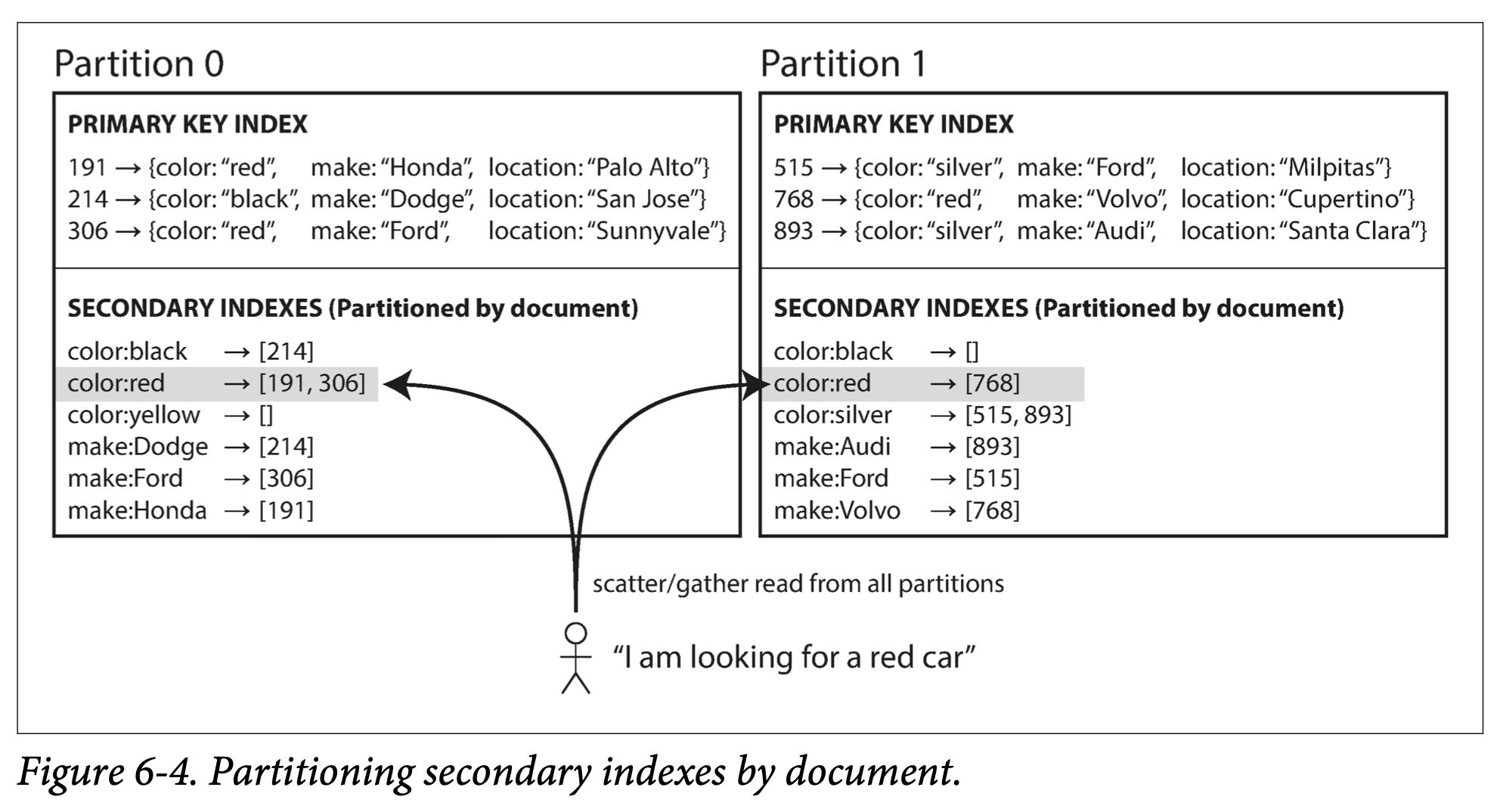
보조 색인에 대한 질의를 위해서는 모든 파티션에 대해 질의를 보내어야 한다. scatter/gatter
용어 기준 보조 색인 파티셔닝
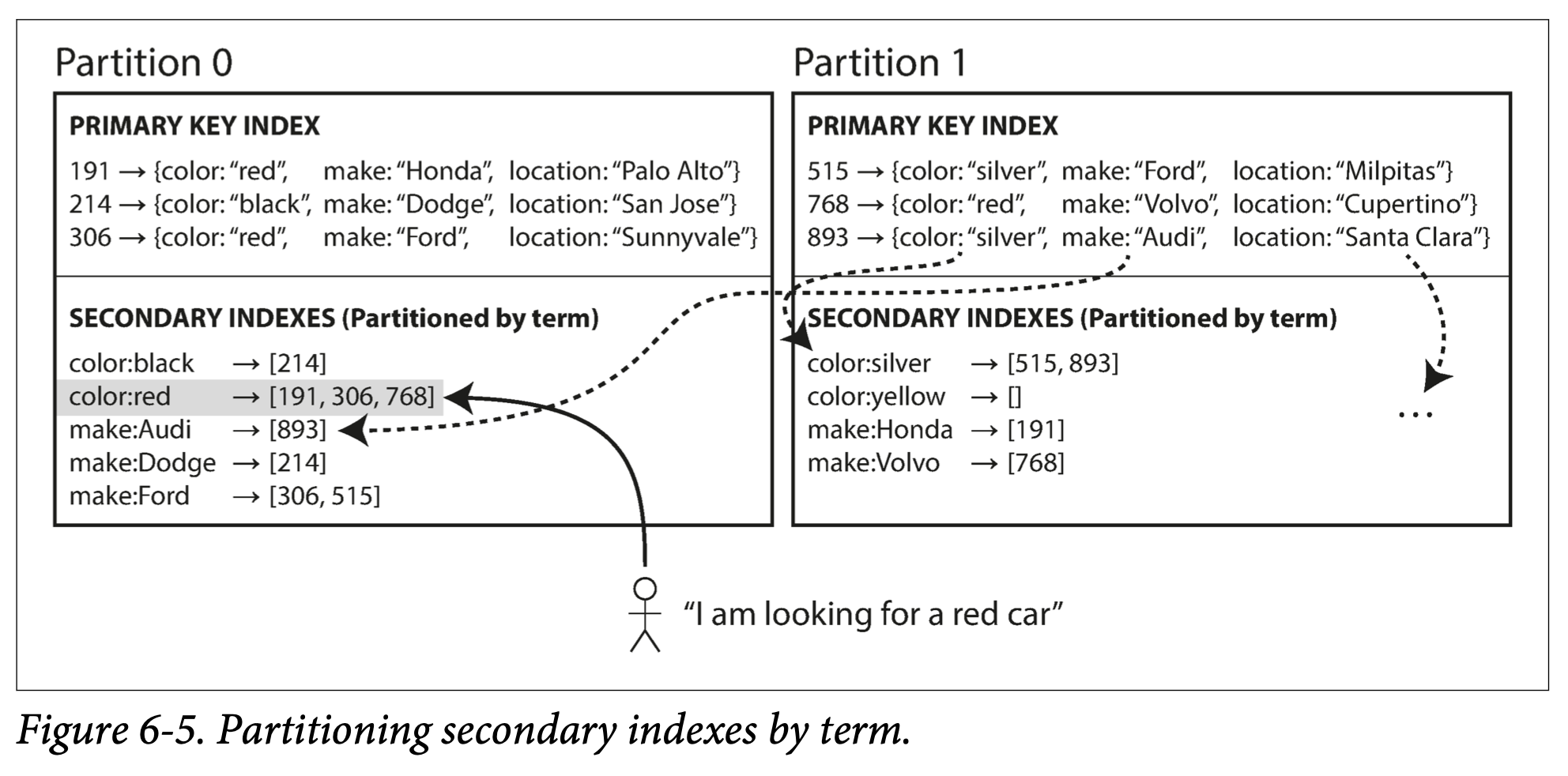
모든 파티션의 데이터를 담당하는 전역 색인을 만든다.
GSI (Global Secondary Index)
파티션 재균형화
클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정
부하는 모든 노드에 균등하게 배분되어야 한다.
재균형화 도중에도 읽기 쓰기 요청을 받아들여야 한다.
부하와 I/O가 최소화될 수 있도록 데이터 이동도 최소화되어야 한다.
재균형화 전략
해시 % N
N의 값이 변경되는 경우 대부분의 데이터가 다른 노드로 이동되어야 하기 때문에 바람직하지 않다.
파티션 개수 고정
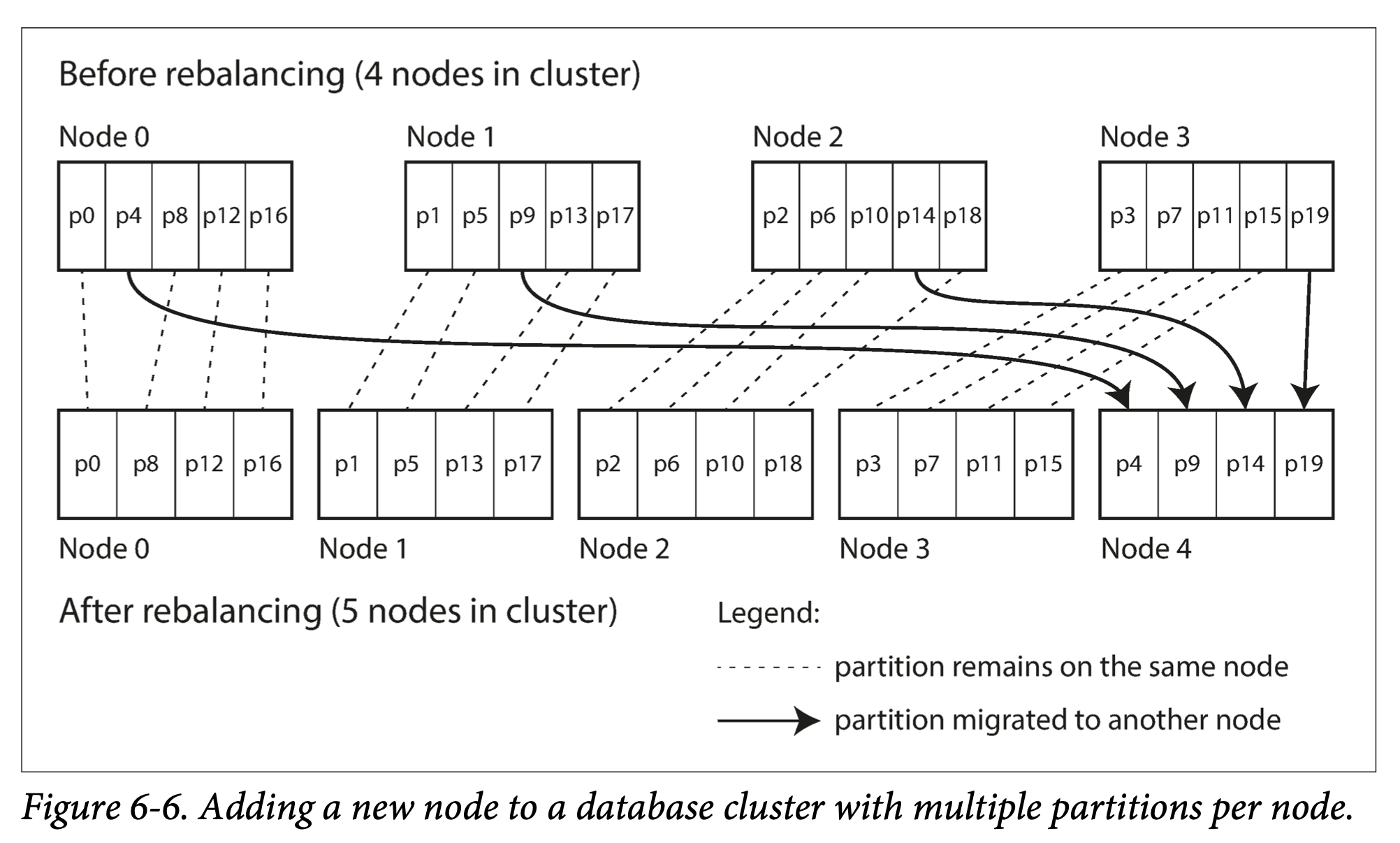
노드당 파티션을 낭낭하게 잡아놓고, 노드가 추가되는 경우 각 노드에서 동일한 개수의 파티션을 이동시킨다.
각 노드의 파티션 개수는 사용가능한 노드의 수의 최대치가 된다.
동적 파티셔닝
파티션의 용량에 따라서 분할 혹은 병합이 된다.
노드 비례 파티셔닝
파티션 개수를 고정하면 데이터셋의 크기에 따라 파티션의 크기가 변한다.
동적 파티셔닝에서는 데이터셋의 크기에 따라 파티션의 개수가 변한다.
파티션의 개수를 노드의 개수에 비례하도록 나눈다.
노드당 파티션의 개수를 고정시키는 방법
요청 라우팅
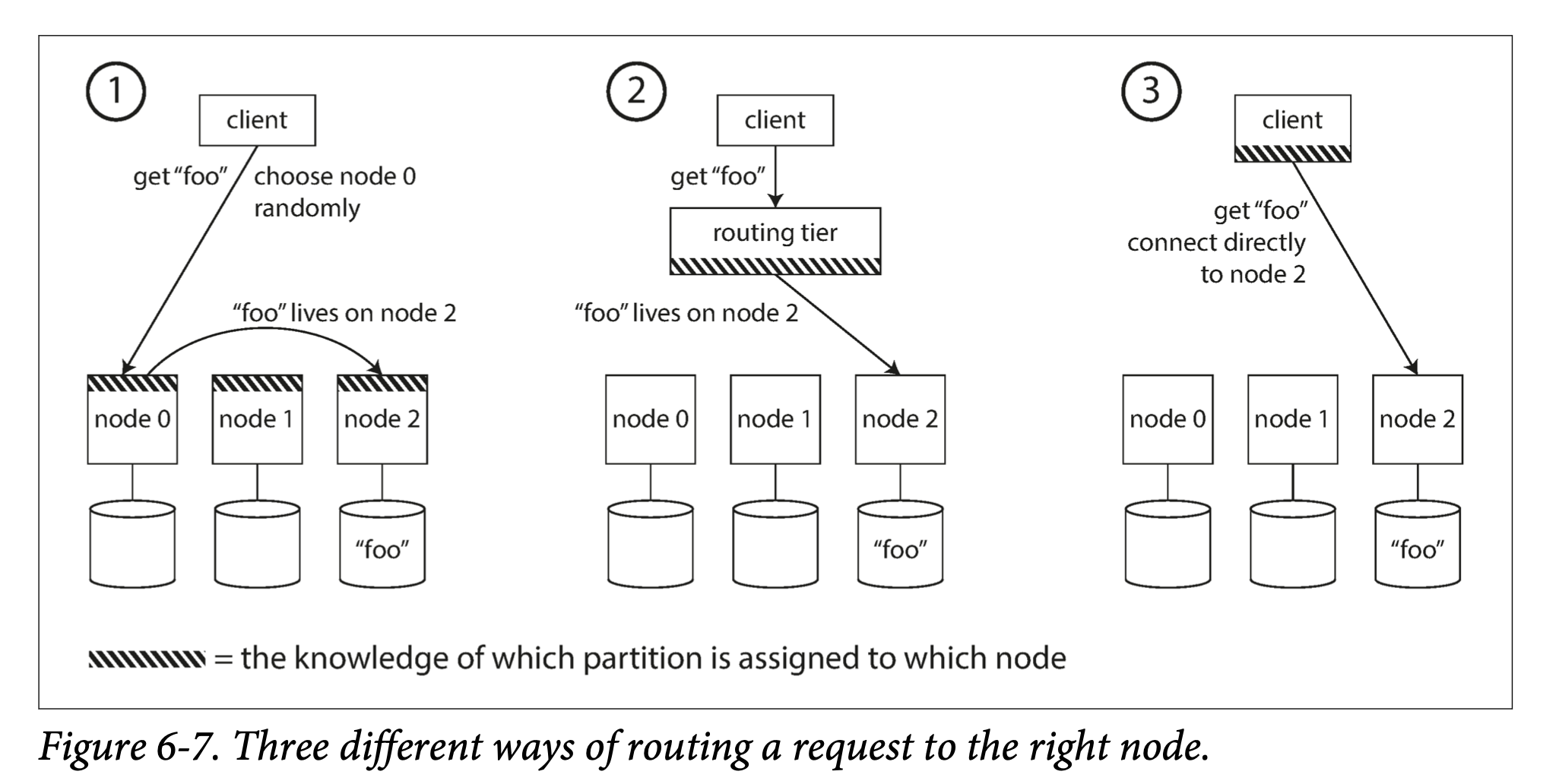
1. 클라이언트에게 아무 노드나 접근하도록 하고 hit이면 return, miss면 요청을 올바른 노드로 보낸다.
2. 라우팅 계층을 두어 요청을 라우팅 계층으로 보내고, 라우팅 계층에서 노드를 안내한다.
3. 클라이언트가 파티션을 알게한다.
병렬 질의 실행
