오늘은 모던 자바스크립트 튜토리얼, 자료구조와 자료형의 문자열에 대해 공부하겠습니다.
자바스크립트엔 글자 하나만 저장할 수 있는 별도의 자료형이 없어서 텍스트 형식의 데이터는 길이에 상관없이 문자열 형태로 저장된다.
문자열은 페이지 인코딩 방식과 상관없이 항상 'UTF-16' 형식을 따른다.
따옴표
따옴표의 종류가 무엇이 있었는지 상기해보자. 문자열은 작은, 큰 따옴표나 백틱으로 감쌀 수 있었다.
작은, 큰 따옴표는 기능상 차이가 없다. 그런데 백틱엔 특별한 기능이 있다.
표현식을 #{...}로 감싸고 이를 백틱으로 감싼 문자열 중간에 넣어주면 해당 표현식을 문자열 중간에 쉽게 삽입할 수 있다. 이런 방식을 '템플릿 리터럴(template literal)'이라고 부른다.

백틱을 사용하면 문자열을 여러 줄에 걸쳐 작성할 수도 있다.

자연스럽게 여러 줄의 문자열이 만들어졌다. 작은, 큰따옴표를 사용하면 위와 같은 방식으로 여러 줄짜리 문자열을 만들 수 없다.
아래 예시를 실행하면 에러가 발생한다.

작은, 큰 따옴표로 문자열을 표현하는 방식은 자바스크립트가 만들어졌을 때부터 있었다.
이때는 문자열을 여러 줄에 걸쳐 작성할 생각조차 못했던 시기였다. 백틱은 그 이후에 등장한 문법이기 때문에 따옴표보다 다양한 기능을 제공한다.
백틱은 '템플릿 함수(template function)'에서도 사용된다. funcstring 같이 첫 번째 백틱 바로 앞에 함수 이름 (func)을 써주면, 이 함수는 백틱 안의 문자열 조각이나 표현식 평가 결과를 인수로 받아 자동으로 호출된다. 이런 기능을 '태그드 템플릿(tagged template)'이라 부르는데, 태그드 템플릿을 사용하면 사용자 지정 템플릿에 맞는 문자열을 쉽게 만들 수 있다. 태그드 템플릿과 템플릿 함수에 대한 자세한 내용은 MDN 문서에서 확인해보자.
특수 기호
'줄 바꿈 문자(newline character)'라 불리는 특수기호 \n을 사용하면 작은, 큰 따옴표로도 여러 줄 문자열을 만들 수 있다.
따옴표를 이용해 만든 여러 줄 문자열과 백틱을 이용해 만든 여러 줄 문자열은 표현 방식만 다를 뿐 차이가 없다.

자바스크립트엔 줄 바꿈 문자를 비롯한 다양한 '특수' 문자들이 있다.
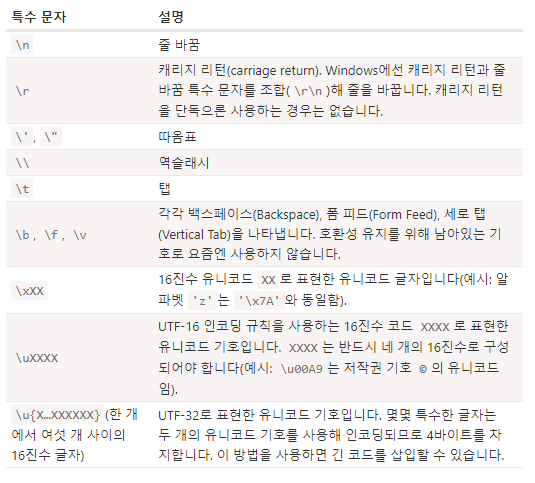
유니코드를 사용한 예시:

모든 특수 문자는 '이스케이프 문자(escape character)'라고도 불리는 역슬래시(backslash character) \로 시작한다.
역슬래시는 문자열 내에 따옴표를 넣을 때도 사용할 수 있다.
예시:

백틱으로 감싸줘도 된다.

역슬래시 \는 문자열을 정확하게 읽기 위한 용도로 만들어졌다. \는 제 역할이 끝나면 사라진다.
메모리에 저장되는 \는 없다.
\를 출력하는 방법은 무엇일까?
\를 \ 두개 붙이면 된다.

문자열의 길이
length 프로퍼티엔 문자열의 길이가 저장된다.
\n은 '특수 문자' 하나로 취급되기 때문에 My\n의 길이는 3이다.
특정 글자에 접근하기
문자열 내 특정 위치인 pos에 있는 글자에 접근하려면 [pos] 같이 대괄호를 이용하거나 str.charAt(pos)라는 메서드를 호출하면 된다. 위치는 0부터 시작한다.
근래에는 대괄호를 이용하는 방식을 사용한다. charAt은 하위 호환성을 위해 남아있는 메서드라고 생각하시면 된다.
두 접근 방식의 차이는 반환할 글자가 없을 때 드러난다. 접근하려는 위치에 글자가 없는 경우 []는 undefined를, charAt은 빈 문자열을 반환한다.

for..of 를 사용하면 문자열을 구성하는 글자를 대상으로 반복 작업을 할 수 있다.

문자열의 불변성
문자열은 수정할 수 없다. 따라서 문자열의 중간 글자 하나를 바꾸려고 하면 에러가 발생한다.직접 실습해보자.

이런 문제를 피하려면 완전히 새로운 문자열을 하나 만든 다음, 이 문자열을 str에 할당하면 된다.

대·소문자 변경하기
메서드 toLowerCase()와 toUpperCase()는 대문자를 소문자로, 소문자를 대문자로 변경(케이스 변경)시켜준다.
글자 하나의 케이스만 변경한느 것도 가능하다.

부분 문자열 찾기
문자열에서 부분 문자열(substring)을 찾는 방법은 여러가지가 있다.str.indexOf
첫 번째 방법은 str.indexOf(substr, pos)메서드를 이용하는 것이다.
이 메서드는 문자열 str의 pos에서부터 시작해, 부분 문자열 substr이 어디에 위치하는지를 찾아준다. 원하는 부분 문자열을 찾으면 위치를 반환하고 그렇지 않으면 -1을 반환해준다.

str.indexOf(substr, pos)의 두번째 매개변수 pos는 선택적으로 사용할 수 있는데, 이를 명시하면 검색이 해당 위치부터 시작된다.
부분 문자열 "id"는 위치 1에서 처음 등장하는데, 두번째 인수에 2를 넘겨 "id"가 두번째로 등장하는 위치가 어디인지 알아보자.

문자열 내 부분 문자열 전체를 대상으로 무언가를 하고 싶다면 반복문 안에 indexOf를 사용하면 된다. 반복문이 하나씩 돌 때마다 검색 시작 위치가 갱신되면서 indexOf가 새롭게 호출된다.
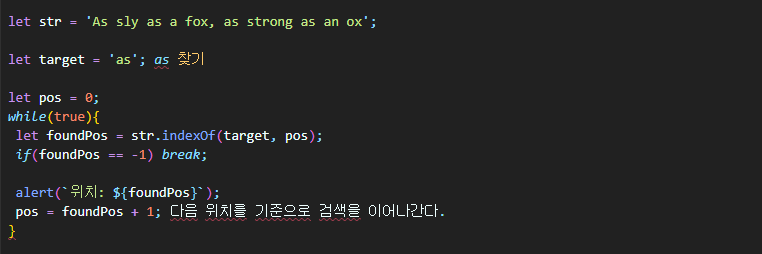
동일한 알고리즘을 사용해 코드만 짧게 줄이면 다음과 같다.

TMI - str.lastIndexOf(substr, position)
str.lastIndexOf(substr, position)는 indexOf와 유사한 기능을 하는 메서드이다. 문자열 끝에서부터 부분 문자열을 찾는다는 점만 다르다.반환되는 부분 문자열 위치는 문자열 끝이 기준이다.
if문의 조건식에 indexOf를 쓸 때 주의할 점이 하나 있다. 아래와 같이 코드를 작성하면 원하는 결과를 얻을 수 없다.

str.indexOf("Widget")은 0을 반환하는데, if문에선 0을 false로 간주하므로 alert창이 뜨지 않는다.
따라서 부분 문자열 여부를 검사하려면 아래와 같이 -1과 비교해야 한다.

부분 문자열 추출하기
자바스크립트엔 부분 문자열 추출과 관련된 메서드가 세 가지 있다. 세 가지 메서드 substring, substr, slice를 하나씩 알아보자.str.slice(start [, end])
문자열의 start부터 end까지(end는 미포함)를 반환한다.

두 번째 인수가 생략된 경우엔, 명시한 위치부터 문자열 끝까지를 반환한다.

start와 end는 음수가 될 수도 있다. 음수를 넘기면 문자열 끝에서부터 카운팅을 시작한다.

str.substring(start [, end])
start와 end 사이에 있는 문자열을 반환한다.
substring은 slice와 아주 유사하지만, start가 end보다 커도 괜찮다는 데 차이가 있다.

substring은 음수 인수를 허용하지 않는다 음수는 0으로 처리한다.
str.substr(start [, length])
start에서부터 시작해 length 개의 글자를 반환한다.
substr은 끝 위치 대신에 길이를 기준으로 문자열을 추출한다는 점에서 substring과 slice와 차이가 있다.

첫 번째 인수가 음수면 뒤에서부터 개수를 센다.

부분 문자열 추출과 관련된 메서드를 요약해 보자.

문자열 비교하기
문자열을 비교할 땐 알파벳 순서를 기준으로 글자끼리 비교가 이뤄진다.그런데 아래와 같이 몇 가지 이상해 보이는 것들이 있다.
- 소문자는 대문자보다 항상 크다.

- 발음 구별 기호(diacritical mark)가 붙은 문자는 알파벳 순서 기준을 따르지 않는다.

이런 예외사항 때문에 이름순으로 국가를 나열할 때 예상치 못한 결과가 나올 수 있었다.
사람들은 Österreich가 Zealand보다 앞서 나올 것이라 예상하는데 그렇지 않다.
자바스크립트 내부에서 문자열이 어떻게 표시되는지 상기하며 원인을 알아보자.
모든 문자열은 UTF-16을 사용해 인코딩되는데, UTF-16에선 모든 글자가 숫자 형식의 코드와 매칭된다. 코드로 글자를 얻거나 글자에서 연관 코드를 알아낼 수 있는 메서드는 다음과 같다.
str.codePointAt(pos)
pos에 위치한 글자의 코드를 반환한다.

String.fromCodePoint(code)
숫자 형식의 code에 대응하는 글자를 만들어준다.

\u 뒤에 특정 글자에 대응하는 16진수 코드를 붙이는 방식으로도 원하는 글자를 만들 수 있다.

이제 이 배경지식을 가지고 코드 65와 220 사이(라틴계열 알파벳과 기타 글자들이 여기에 포함된다.)에 대응하는 글자들을 출력해보자.

대문자 알파벳이 가장 먼저 나오고 특수문자 몇 개가 나온 다음 소문자 알파벳이 나온다.
Ö은 거의 마지막에 출력된다.
이것이 a > Z 인것이다.
글자는 글자에 대응하는 숫자 형식의 코드를 기준으로 비교된다. 코드가 크면 대응하는 글자 역시 크다고 취급된다. 따라서 a(코드:97)는 Z(코드:90)보다 크다는 결론이 도출된다.
문자열 제대로 비교하기
언어마다 문자 체계가 다르기 때문에 문자열을 '제대로' 비교하는 알고리즘을 만드는건 생객보다 간단하지 않다.문자열을 비교하려면 일단 페이지에서 어떤 언어를 사용하고 있는지 브라우저가 알아야 한다.
다행히도 모던 브라우저 대부분이 국제화 관련 표준인 ECMA-402를 지원한다.
(IE10은 아쉽게도 Intl.js 라이브러리를 사용해야 한다.)
ECMA-402엔 언어가 다를 때 적용할 수 있는 문자열 비교 규칙과 이를 준수하는 메서드가 정의되어있다.
str.localeCompare(str2)를 호출하면 ECMA-402에서 정의한 규칙에 따라 str이 str2 보다 작은지, 같은지, 큰지를 나타내주는 정수가 반환된다.
예시:

localeCompare엔 선택 인수 두 개를 더 전달할 수 있다. 기준이 되는 언어를 지정(아무것도 지정하지 않았으면 호스트 환경의 언어가 기준 언어가 됨)해주는 인수와 대·소문자를 구분할지나 "a"와 "á"를 다르게 취급할지에 대한 것을 설정해주는 인수가 더 있다.
