kubectl을 더 쉽게 사용하기
쿠버네티스를 다루기 위해 가장 많이 사용하는 명령어는 kubectl입니다.
하지만 kubectl을 사용할 때 키보드를 7번이나 입력해야 하는 불편함이 있습니다.
또한 리눅스에서 자주 용하는 배시 셸처럼 Tab을 통해 입력 가능한 명령이 확인되지 않아
모든 명령을 암기하고 있어야 합니다.
이런 불편함을 해소하고, 자주 쓰는 명령을 편하게 구현하는 방법을 알아봅시다!
kubectl 명령 자동 완성하기
쿠버네티스는 배시 셸의 명령을 자동으로 완성하기 위해 bash-completion이라는 패키지를 제공합니다.
bash-completion은 배시의 내장(Built-in) 명령 중 하나인 complete을 이용해 특정 명령에 대한 자동 완성 목록을 표시합니다.
kubectl은 kubectl completion bash 명령을 제공하고, 이를 실행하면 complete에 맞게 자동 완성에 필요한 목록을 생성합니다.
따라서 kubectl 명령에 대한 자동 완성 목록을 구현하면 kubectl 이후에 입력하는 명령들은 tab을 이용해 사용할 수 있습니다.
kubectl 을 입력하고 Tab을 눌러보세요!

kubectl을 자동 완성형으로 쓰기 위해서는 kubectl completion bash로 나온 결과를
설정(/etc/bash_completion.d/kubectl)에 저장하고 이것을 접속 시에
배시 셸 설정(~/.bashrc)에서 불러오도록 하면 됩니다.
이와 같은 목적으로 작성된 코드는 다음과 같습니다.
#!/usr/bin/env bash
#Usage:
#1. bash <(curl -s https://raw.githubusercontent.com/sysnet4admin/IaC/master/manifests/bash-completion.sh)
# install bash-completion for kubectl
yum install bash-completion -y
# kubectl completion on bash-completion dir
kubectl completion bash >/etc/bash_completion.d/kubectl
# alias kubectl to k
echo 'alias k=kubectl' >> ~/.bashrc
echo 'complete -F __start_kubectl k' >> ~/.bashrc
#Reload rc
su - kubectl 명령 자동 완성은 이미 이전 포스팅에서 멀티스테이지를 위한 새로운 쿠버네티스를 배포할 때 설정이 포함돼 들어갔습니다.
따라서 포스팅은 순서대로 따라오며 실습하셨다면 추가로 실행할 필요는 없으나,
바로 이번 포스팅을 보신다면 2~3번째 줄에 나온 사용법(usage) 또는 다음과 같은 명령을 실행하면 순쉽게 설정됩니다.
~/_Book_k8sInfra/app/A.kubectl-more/bash-completion.sh
혹은
curl -s https://raw.githubusercontent.com/sysnet4admin/IaC/master/manifests/bash-completion.sh
설정하고 나면 다음과 같이 kubectl <특정 명령어> 이후로 tab을 누르면 명령어 이후에 사용할 수 있는 명령어가 어떤 것이 있는지 확인할 때 유용합니다!
kubectl expose <tab>

특히 자동 완성은 describe 또는 exec와 같이 파드 이름이 필요한 경우에 편리하게 사용할 수 있습니다.
kubectl describe pods <tab>
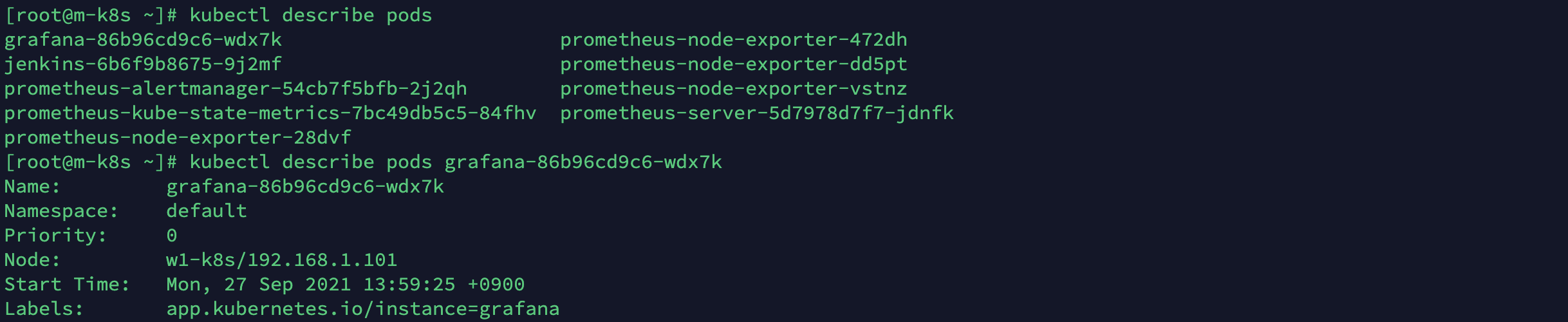
이제 kubectl을 사용할 때 쿠버네티스에서 제공하는 모든 오브젝트를 외울 필요가 없어졌습니다.
하지만 반복적으로 파드의 상태를 확인하거나 파드에 접속하다 보면 kubectl을 입력한 다음에
Tab을 여러 번 눌러야 합니다. 여전히 남아 있는 불편함을 해결할 방법은 없을까요?
kubectl 별칭 사용하기
첫 번쨰로 해결할 것은 kubectl 명령어를 k로 별칭(alias)을 만들어 사용하는 것입니다.
# alias kubectl to k
echo 'alias k=kubectl' >> ~/.bashrc
echo 'complete -F __start_kubectl k' >> ~/.bashrc이렇게 설정되고 나면 다음과 같이 k 또는 k <특정 명렁어> 이후로 Tab을 누르면,
명령어 이후에 사용할 수 있는 명령어가 어떤 것이 있는지 kubectl과 똑같이 나옵니다.
단 k로 시작하는 명령어와 k (별칭)로 시작하는 명령은 다릅니다!

두 번째로 해결할 것은 반복적으로 입력해야 하는 긴 명령 구문입니다.
배시 스크립트를 작성해 명령 구문을 미치 별칭으로 만들고,
필요에 따라 입력 값을 받아오면 원하는 작업을 할 수 있습니다.
배시 스크립트로 어떤 작업을 할 수 있는지 가볍게 테스트해 봅시다!
-
kubectl의 alias 집합이 있는 k8s_rc.sh를 실행합니다.
~/_Book_k8sInfra/app/A.kubectl-more/k8s_rc.sh

-
kgp를 실행해 파드의 상태를 확인합니다.(배포된 파드가 없다면 먼저 파드를 배포하기 바랍니다.)
- 여기서 kgp는 kubectl get pods의 alias입니다.

- 여기서 kgp는 kubectl get pods의 alias입니다.
-
명령 결과로 확인된 파드에 접속하기 위해서 기존에는
kubectl exec를 입력하고 접속할 파드를 추가 입력해야 했지만, 이러한 불편함을 해결한keq를 실행해서 파드에 접속해 보겠습니다.- 명령을 실행하면 접속 가능한 파드가 표시됩니다.
- 이 중에서 접속하려는 파드 번호를 선택하고 본 셸(/bin/sh)에서 접속된 것을 확인합니다.
- 일부 컨테이너의 경우 배시 셸을 지원하지 않으므로 호환성을 위해서 기본 셸을 배시 셸이 아닌 본 셸로 접속합니다.

-
cat /run/nginx.pid를 실행해 동작하는지 확인합니다. 동작하면 pid가 1로 표시됩니다.(nginx pods의 경우)- 저는 그라파나 파드에 접속했기 때문에 간단하게 NOTICE.md를 확인해보겠습니다.
cat /run/systemd/notify NOTICE.md

- 확인이 끝나면 exit를 입력해 빠져나옵니다.
kubectl 약어 사용하기
kubectl을 alias하면 많은 부분을 편하게 사용할 수 있지만, 모든 부분을 alias할 순 없습니다.
떄로는 명령어를 직접 쳐서 확인할 수밖에 없습니다.
그래서 kubectl은 자주 사용하는 구문의 약어(short name)을 지원하고 있습니다.
앞에서 이미 일부 배포 이름에 약어를 사용했습니다.
deploy, hpa, sts처럼요.
몇 가지 약어를 간단히 테스트해 봅시다!
k get no(nodes)로 노드의 상태를 확인합니다.

k get po(pods)로 파드의 상태를 확인합니다.

k delete deploy nginx로 deployment를 삭제합니다.- 저는 nginx 디플로이먼트를 배포해놓지 않았기 때문에 삭제할 디플로이먼트가 없습니다.

- 저는 nginx 디플로이먼트를 배포해놓지 않았기 때문에 삭제할 디플로이먼트가 없습니다.
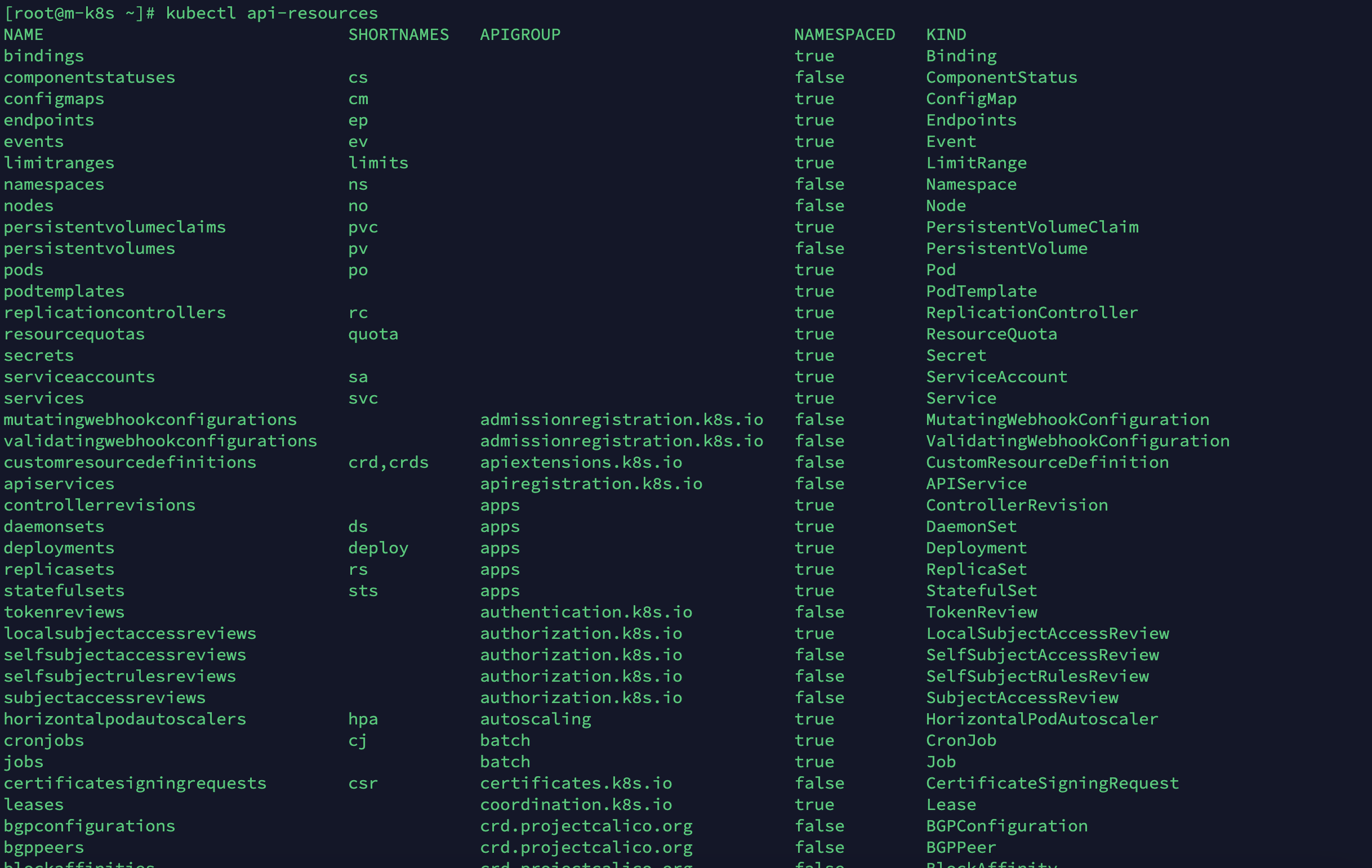
주로 사용하는 약어
주로 사용하는 약어는 다음과 같습니다.
| 구분 | 이름 | 약어 | 오브젝트 이름(Kind) |
|---|---|---|---|
| 자주 사용하는 명령어 | nodes | no | Node |
| namespaces | ns | Namespace | |
| deployments | deploy | Deployment | |
| pods | po | Pod | |
| services | svc | Service | |
| 앞선 포스팅에서 다룬 명령어 | replicasets | rs | ReplicaSet |
| ingresses | ing | Ingress | |
| configmaps | cm | ConfigMap | |
| horizontalpodautoscalers | hpa | HorizontalPodAutoscaler | |
| daemonsets | ds | DaemonSet | |
| persistentvolumeclaims | pvc | PersistentVolumeClaim | |
| persistentvolumes | pv | PersistentVolume | |
| statefulsets | sts | StatefulSet | |
| 참고 명령어 | replicationcontrollers | rc | ReplicationController |
| resourcequotas | quota | ResourceQuota | |
| serviceaccounts | sa | ServiceAccount | |
| cronjobs | cj | CronJob | |
| events | ev | Event | |
| storageclasses | sc | StorageClass | |
| endpoints | ep | Endpoints | |
| limitranges | limits | LimitRange |
약어는 쿠버네티스 버전이 업데이트됨에 따라 변경될 수 있습니다.
현재 쿠버네티스 버전의 약어는 kubectl api-resources 명령어로 확인할 수 있습니다.
쿠버 대시보드 구성하기
이전 포스팅에서 프로메테우스로 메트릭 데이터를 수집하고
그파나로 시각화해 쿠버네티스 클러스터 상태를 확인해 봤습니다.
하지만 작은 프로젝트나 소규모 환경에서는 이렇게까지 모니터링하고 관리할 필요는 없습니다.
그래서 이번에는 쿠버네티스에서 추가적으로 제공하는 기능인
쿠버 대시보드(kube-dashboard) 로 간단한 웹 UI를 구성해 쿠버네티스 클러스터의 상태를 확인하고,
나아가 배포한 쿠버 대시보드를 통해 쿠버네티스 클러스터에 오브젝트를 배포하는 방법도 알아보겠습니다.
쿠버 대시보드 배포하기
쿠버 대시보드(이후 대시보드로 칭합니다)를 기본 설정으로 배포할 경우
웹 브라우저에서 HTTPS(예외: 로컬호스트로 접근하는 경우)로 대시보드에 접속해야 합니다.
여기선 편의를 위해 HTTP로 접근할 수 있게 설정하고 대시보드의 로그인 인증을 생략하는 옵션을 추가하겠습니다.
또한 대시보드에서 쿠버네티스 클러스터의 오브젝트를 관리하기 위해
클러스터의 모든 오브젝트에 접근하고 변경할 수 있는 역할을 추가하겠습니다.
실습에서 다루는 대시보드는 접속할 떄 로그인할 필요가 없어서 누가 접속했는지 알 수 없습니다.
이러한 상태의 대시보드를 실제 환경에서 공개적으로 배포하면
인증되지 않은 사용자가 대시보드를 통해 쿠버네티스 클러스터의
오브젝트를 조회, 수정, 삭제하거나 생성할 수 있습니다.
그러므로 상용 환경에서 대시보드를 공개적으로 배포하는 것은 권장하지 않습니다.
먼저 사전에 구성한 대시보드의 매니페스트 파일을 쿠버네티스 클러스터에 배포하겠습니다.
kubectl apply -f ~/_Book_k8sInfra/app/B.kube-dashboard/dashboard.yaml

```
# Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: v1
kind: Namespace
metadata:
name: kubernetes-dashboard
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 80
targetPort: 9090
# 외부로 접근하기 위해 31000번 포트를 노드 포트로 노출합니다.
nodePort: 31000
selector:
k8s-app: kubernetes-dashboard
type: NodePort
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kubernetes-dashboard
type: Opaque
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-csrf
namespace: kubernetes-dashboard
type: Opaque
data:
csrf: ""
---
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-key-holder
namespace: kubernetes-dashboard
type: Opaque
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-settings
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.0.3
imagePullPolicy: Always
ports:
- containerPort: 9090
protocol: TCP
args:
# 대시보드 접근 시 인증을 생략할 수 있게 합니다.
- --enable-skip-login
- --disable-settings-authorizer=true
# 모든 IP에서 HTTP로 접속할 수 있게 합니다.
- --enable-insecure-login
- --insecure-bind-address=0.0.0.0
- --namespace=kubernetes-dashboard
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
# 대시보드를 마스터 노드에 배포하도록 설정합니다.
nodeSelector:
"kubernetes.io/hostname": m-k8s
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
ports:
- port: 8000
targetPort: 8000
selector:
k8s-app: dashboard-metrics-scraper
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: dashboard-metrics-scraper
name: dashboard-metrics-scraper
namespace: kubernetes-dashboard
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: dashboard-metrics-scraper
template:
metadata:
labels:
k8s-app: dashboard-metrics-scraper
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'runtime/default'
spec:
containers:
- name: dashboard-metrics-scraper
image: kubernetesui/metrics-scraper:v1.0.4
ports:
- containerPort: 8000
protocol: TCP
livenessProbe:
httpGet:
scheme: HTTP
path: /
port: 8000
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- mountPath: /tmp
name: tmp-volume
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsUser: 1001
runAsGroup: 2001
serviceAccountName: kubernetes-dashboard
nodeSelector:
"kubernetes.io/hostname": m-k8s
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
volumes:
- name: tmp-volume
emptyDir: {}
```이제 마스터 노드에 배포된 대시보드로 접근해 보겠습니다.
웹 브라우저에 192.168.0.10:31000으로 접속합니다.
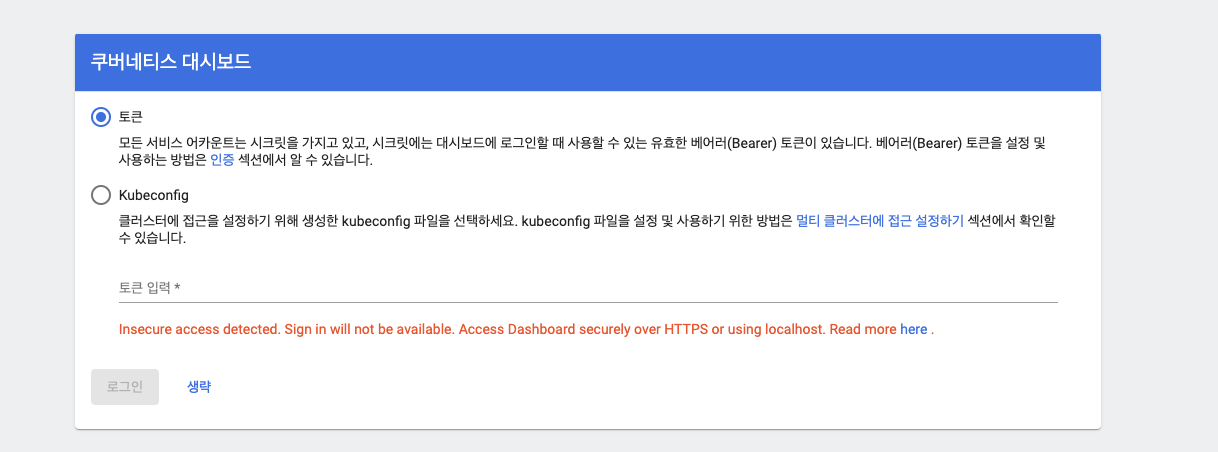
초기 접속 화면에서는 대시보드를 접속할 떄 허용된 사용자가 접근하는 데 필요한 인증 방법을 선택할 수 있습니다.
사용자에게 서비스 어카운트를 제공한 후 토큰을 생성해 사용하게 하거나,
적절한 쿠버네티스 구성 파일(kubeconfig)을 가진 사용자만 접근하게 하는 것이 일반적입니다.
하지만 실습에서는 간단하게 하기 위해 대시보드의 인증 과정을 생략하겠습니다.
생략버튼을 눌러서 인증과 관련된 설정을 생략합니다.
그러면 개요(Overview) 페이지 화면을 확인할 수 있습니다.
(만약 이와 다른 화면이 출력된다면 이미 배포된 파드 또는 서비스가 존재하기 때문입니다.)
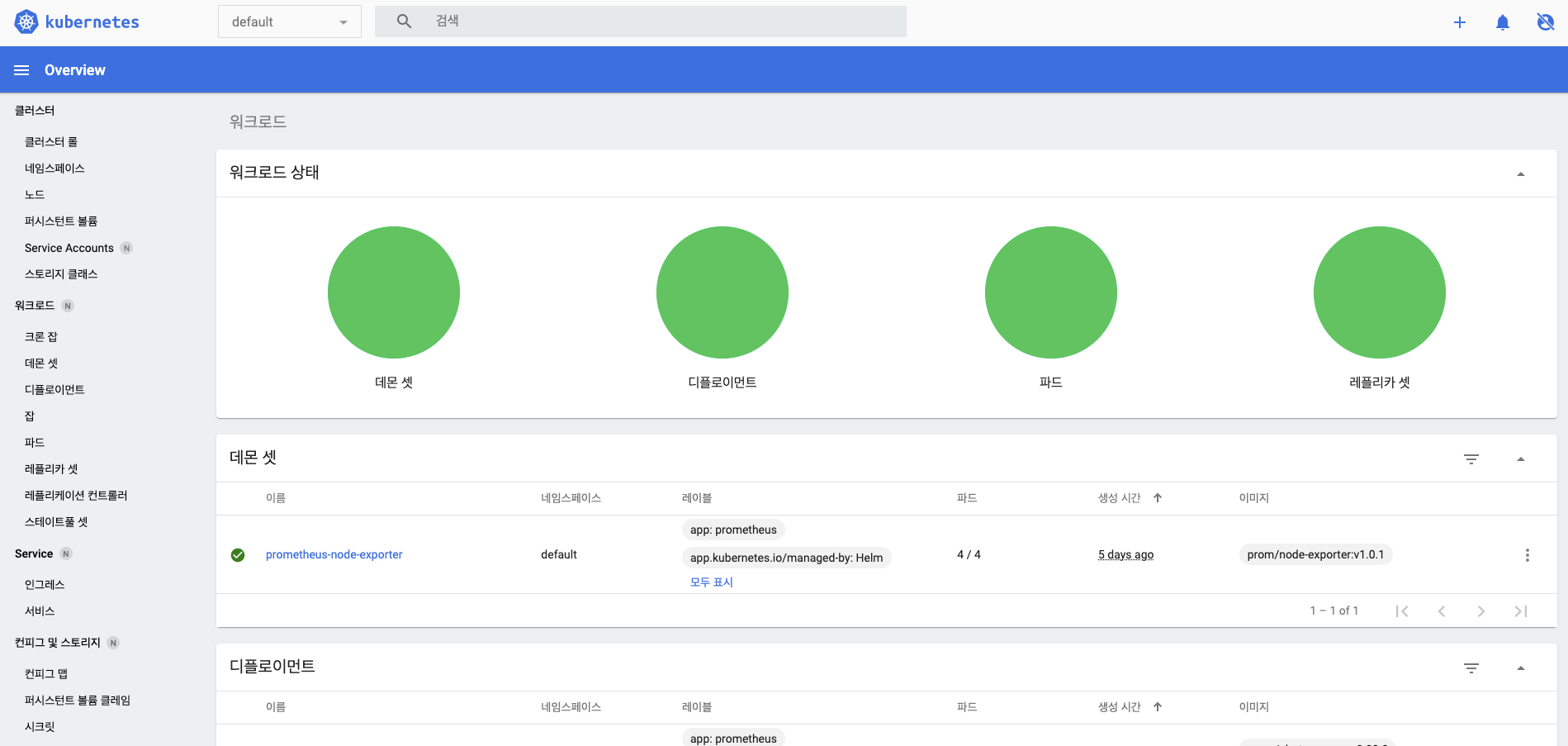
개요 페이지의 각 요소들은 다음과 같은 기능을 제공합니다.
1. 네임 스페이스 : 대시보드에서 작업을 수행할 네임스페이를 선택합니다.
2. 검색창 : 입력한 검색어에 해당하는 오브젝트를 검색할 수 있습니다.
3. 오브젝트 목록 : 대시보드에서 조회할 수 있는 오브젝트의 목록을 표시합니다.
4. 시각화 패널 : 3에서 선택한 오브젝트의 목록과 설정 등을 표시하는 영역입니다.
5. 오브젝트 생성 : 웹 UI를 통해 오브젝트를 만들 수 있는 화면으로 이동합니다. 오브젝트 생성 메뉴로 이동 시 오브젝트를 만들 수 있는 생성, 삭제, 조회 등 적절한 역할 바인딩(rolebinding)이 해당 접속 계정에 필요합니다.
6. 알림 : 쿠버네티스 클러스터에서 발생한 알림을 확인할 수 있습니다.
7. 사용자 정보 : 현재 접속한 사용자 정보를 확인할 수 있습니다.
대시보드의 설치 및 구동을 완료했습니다.
편의를 위해 몇 가지 사항을 생략했지만, 정상적인 설치 단계를 거치더라도 다른 대시보드 도구보단 쉽게 설치하고 구동할 수 있습니다.
이제 설치한 대시보드로 좀 더 직관적이고 편리하게 쿠버네티스의 오브젝트를 생성해 보겠습니다!
쿠버 대시보드에서 오브젝트 생성하기
그동안 kubectl 명령으로 쿠버네티스 클러스터에 디플로이먼트나 서비스 등을 구성했습니다.
kubectl 명령을 사용하려면 서버에 접속하고 오브젝트를 생성하는 데 필요한 옵션을 어느 정도 숙지해야 합니다.
그러나 대시보드는 서버에 접속하거나 명령어를 입력할 필요 없이 사용자가 화면을 보면서
필요한 정보를 입력하면 디플로이먼트와 서비스를 생성할 수 있는 기능을 제공합니다.
-
대시보드 개요 페이지에서 우측 상단에 있는 (+) 모양의 오브젝트 생성 버튼을 눌러 새로운 오브젝트를 생성하는 메뉴로 이동합니다.

-
오브젝트를 생성하는 화면이 나오면 서식을 통해 생성을 선택합니다.
- 입력을 통해 생성 : 브라우저에서 제공하는 편집기에 야믈(YAML)이나 제이슨(JSON) 등의 형식으로 직접 매니페스트 내용을 작성해 생성하는 방식입니다.
- 파일을 통해 생성 : 별도의 파일로 작성된 야믈 또는 제이슨 파일을 업로드해 오브젝트를 생성하는 방식입니다.
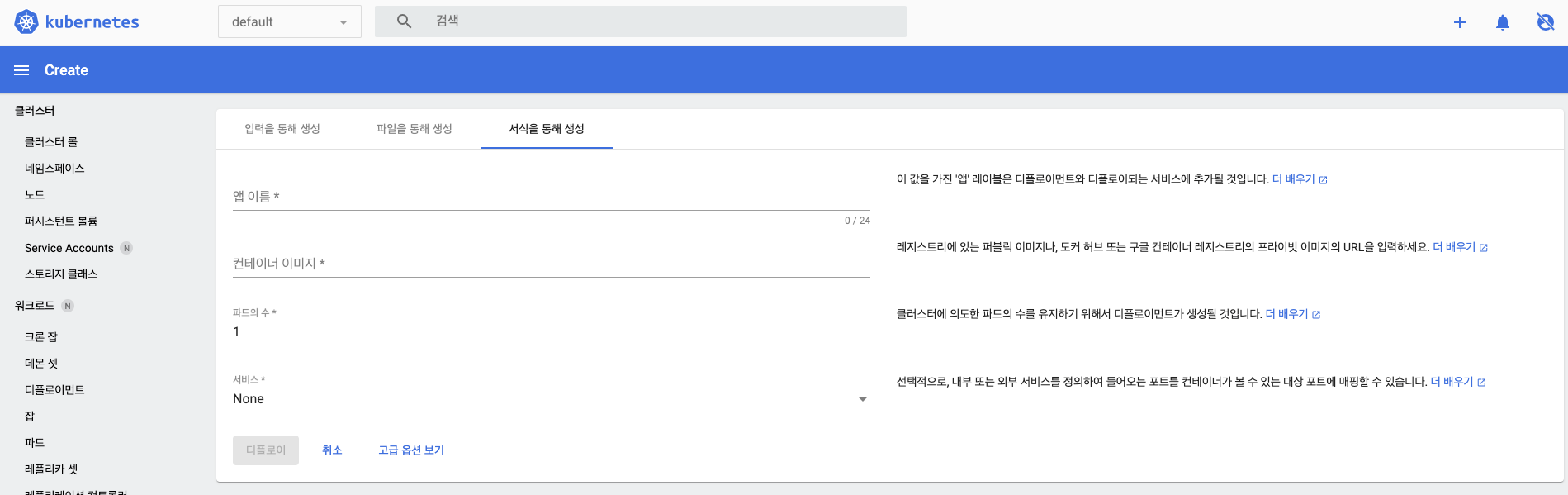
- 서식을 통해 생성 : 디플로이먼트와 서비스를 생성하는 서식이 화면에 표시되면 필요한 값을 입력해 오브젝트를 생성하는 방식입니다.
-
사용자는 사전 지식이 없더라도 화면 안내에 따라 필요한 항목이 무엇인지 알 수 있습니다.
- 여기서는 배포할 이미지로 sysnet4admin.echo-ip를 선택해 파드를 생성하겠습니다.
- 필요한 정보를 화면에 입력하면 입력한 파드로 구성된 디플로이먼트와 서비스가 생성됩니다.
- 앱 이름 : 배포되는 디플로이먼트의 이름입니다.
- 컨테이너 이미지 : 디플로이먼트를 생성할 떄 파드가 사용할 컨테이너 이미지를 설정합니다.
- 파드의 수 : 디플로이먼트가 유지할 파드의 수를 결정합니다.
- 서비스 : 디플로이먼트 내부의 파드로 트래픽을 전달하기 위해 사용하는 서비스를 선택합니다. 서비스/서비스가 사용할 포트/파드가 실제로 트래픽을 받아들일 포트/프로토콜을 설정합니다.
- 디플로이 : 모든 정보 입력이 끝나고 디플로이 버튼을 클릭하면 배포됩니다.
-
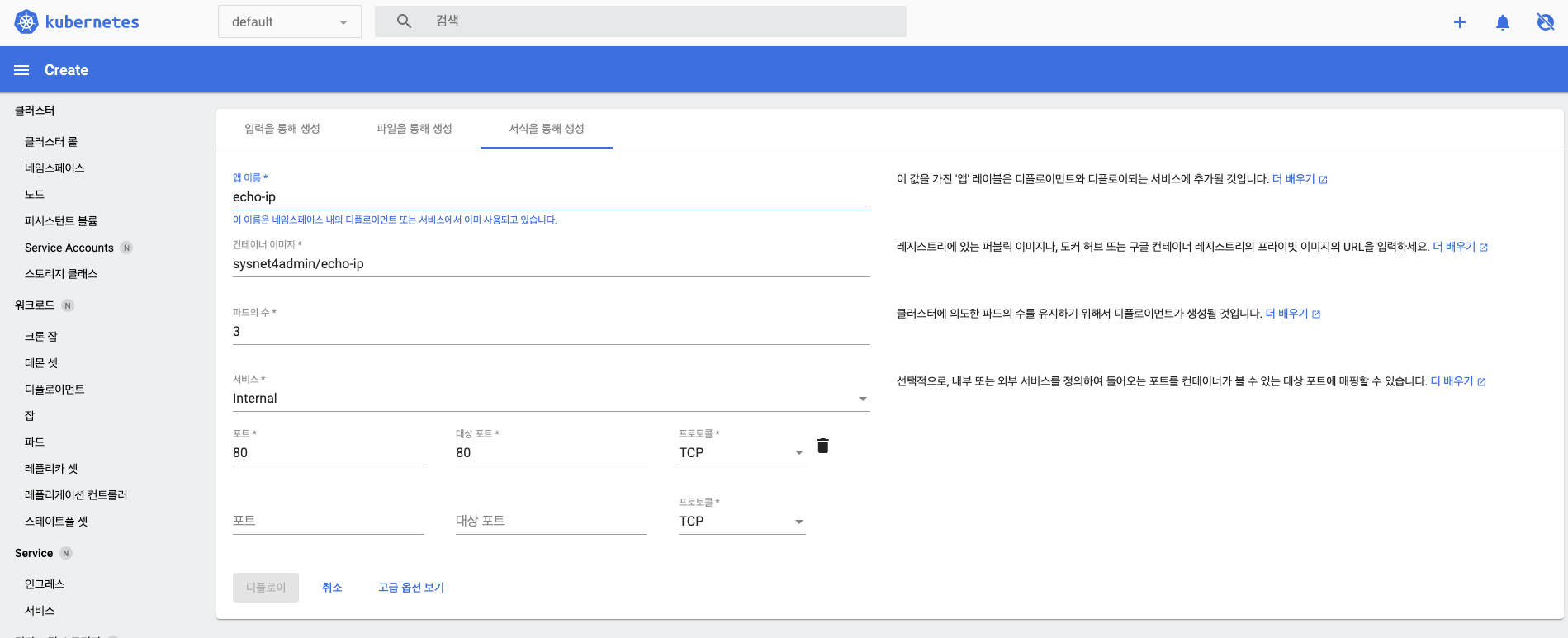
오브젝트가 생성되면 화면이 다음과 같은 개요 페이지로 전환됩니다.
- 대시보드 접속 초기에 보왔던 개요 페이지와 다르게 현재 배포된 디플로이먼트와 파드, 레플리카셋의 상태를 보여주는 원그래프가 나타나고, 그 아래에 배포된 오브젝트들의 목록을 한 번에 보여줍니다.
- 화면 상단의 원 그래프는 배포된 오브젝트에 문제가 없을 경우 전체가 초록색입니다.
- 오브젝트에 문제가 있으면 문제가 있는 오브젝트의 수의 비율만큼 그래프 색깔이 변합니다.
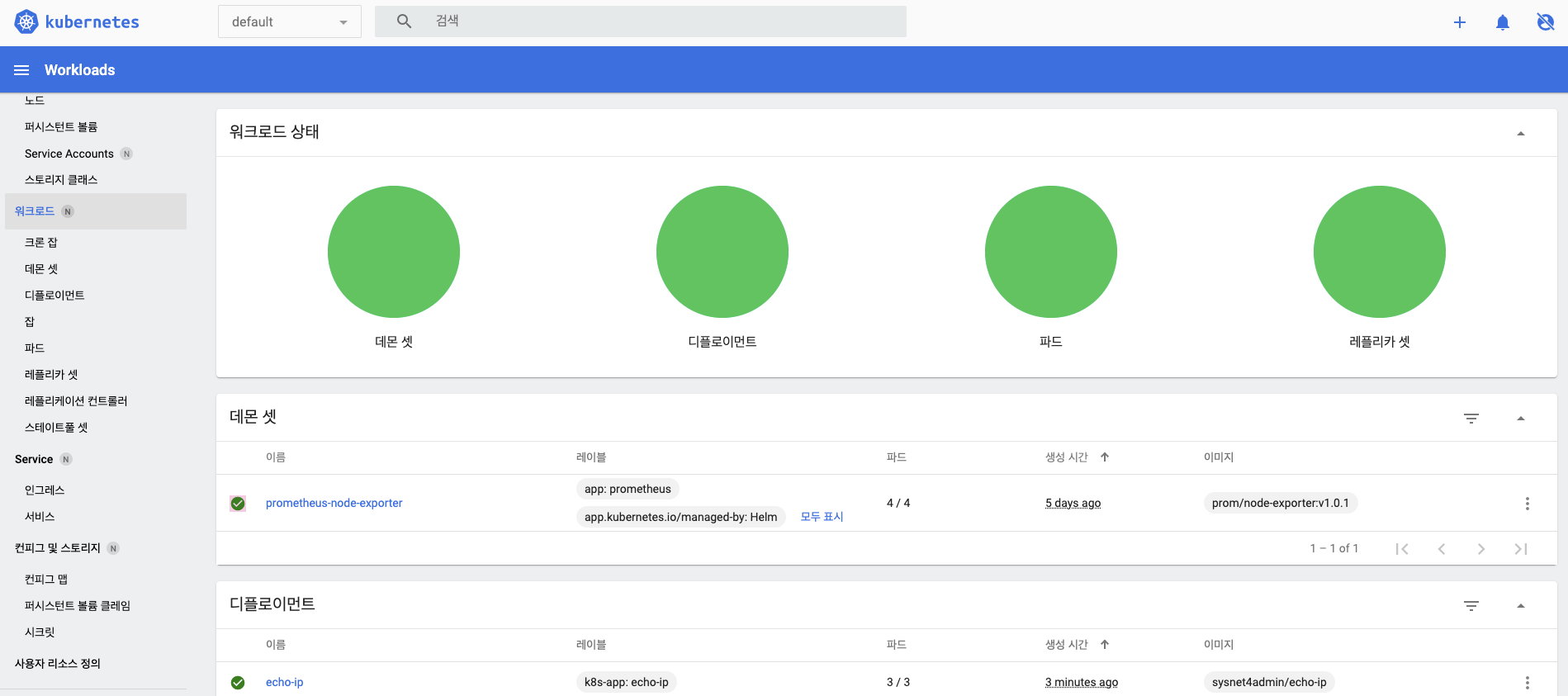
-
왼쪽 메뉴에서 디플로이먼트를 선택하면 시각화 패널에서 디플로이먼트 목록과 상태를 확인할 수 있습니다.
- 오른쪽 창의 이름을 보면 echo-ip 디플로이먼트가 배포된 것을 확인할 수 있습니다.
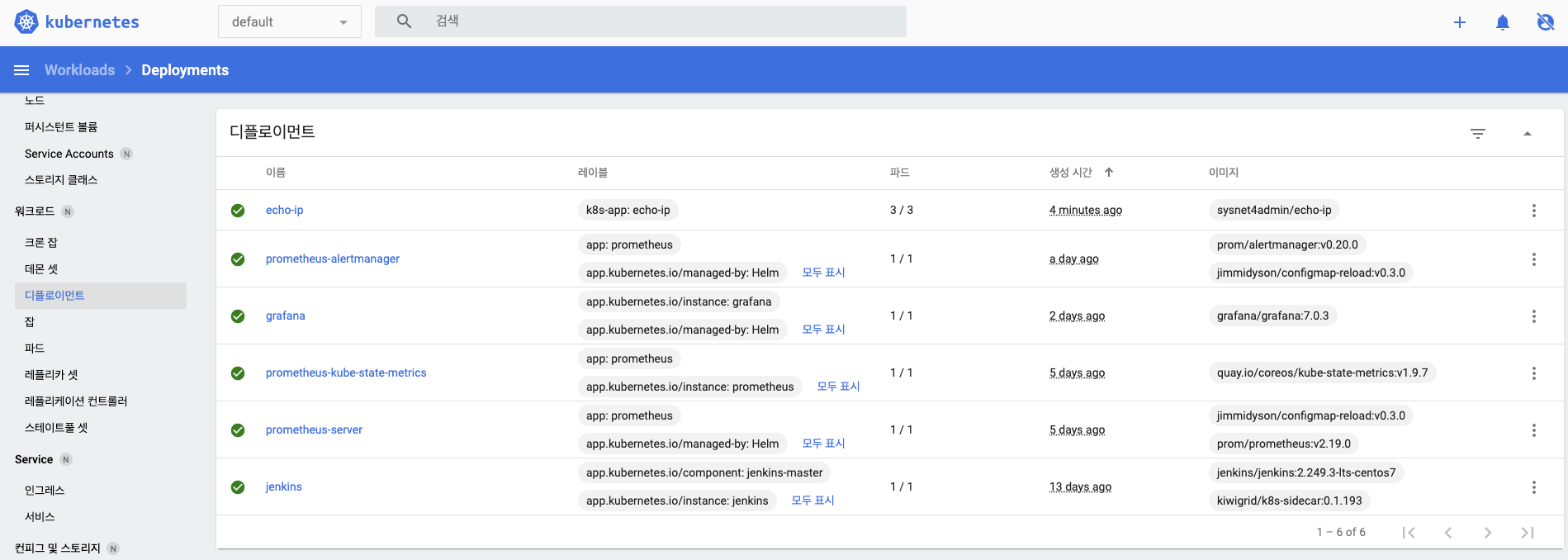
- 오른쪽 창의 이름을 보면 echo-ip 디플로이먼트가 배포된 것을 확인할 수 있습니다.
-
대시보드로 배포한 디플로이먼트가 실제로 쿠버네티스 클러스터에 배포됐는지 확인해보겠습니다.
kubectl get deployment echo-ip

-
kubectl get svc echo-ip명령으로 ClusterIP 타입의 서비스가 생성됐는지 확인합니다.- 서식을 통해 오브젝트를 생성할 떄 서비스의 종류는 internal로 설정했기 때문에 클러스터 내부에서 접근하는 ClusterIP 타입의 서비스가 생성됐습니다.
- 서비스의 종류가 external이었다면 외부에서 접근할 수 있는 IP를 노출하는 LoadBalancer 타입의 서비스가 생성됩니다.
- 또한 NodePort 타입의 서비스가 필요할 경우에는 야믈을 직접 작성해서 배포해야 합니다.

대시보드는 SSH 접속이나 별도의 도구 설치 없이도 웹에서 오브젝트 상태를 확인하고 관리할 수 있습니다.
다만 대시보드는 쿠버네티스 클러스터 내부에 설치되기 때문에 여러 쿠버네티스 클러스터를 한 번에 관리하거나 좀 더 세부적인 배포 설정을 하기는 어렵습니다.
따라서 다양한 기능을 제공하는 대시보드를 원한다면 렌즈(Lens), 옥탄트(Octant), 폴라리스(Polaris)와 같은 전문적인 대시보드 도구를 설치해야 합니다.
또한 프로메테우스와 그라파나 등의 특화된 도구를 사용하는 것도 좋은 방법입니다.
사용자 환경에 따라 도구를 선택해 구성할 수 있다는 것이 쿠버네티스 가장 큰 장점 중 하나입니다!
kubespray로 쿠버네티스 자동 구성하기
시작하기에 앞서 컴퓨터에 충분한 용량을 확보하고 진행하시길 바랍니다. 가상 머신을 추가로 여러개 구성하다보니 용량 부족시 컴퓨터가 다운되고, 설치가 정상적으로 진행되지 않는 문제가 있었습니다.
쿠버네티스 클러스터를 구성하는 대표적인 도구가 4가지(kubeadm, kops, KRIB, kubespray)가 있습니다.
그리고 이 책에서는 kubeadm으로 쿠버네티스 클러스터를 구성했습니다.
하지만 kubeadm은 따로 설정해야 하는 사항이 많습니다.
그래서 실무에서는 좀 더 편리한 방법을 사용하는데, 그 중 하나가 지금 소개할 kubespray입니다!
kubespray는 자동화 도구 중에 가장 많이 사용하는 앤서블을 이용해 쿠버네티스 클러스터를 자동으로 구성하게 합니다.
kubespray는 다음과 같이 설치하는 데 필요한 요구 사항이 있습니다.
- 쿠버네티스 1.16 버전 이상 권고(일반적으로 최신 버전보다 두 단계 아래 버전)
- 앤서블 2.9 버전 이상 권고(일반적으로 최신 버전)
- python-netaar과 jinja(2.11 버전 이상)이 설치돼 있어야 함
- 인터넷이 연결돼 있거나 내부 레지스트리를 통하는 방법 등으로 도커 이미지를 가져올 수 있어야 함
- IPv4 forwarding 설정이 돼 있어야 함
- SSH key가 이미 교환돼 암호 없이 서로 연결될 수 있어야 함
- 방화벽(firewall)이 비활성화(disable)돼 있어야 함
- root 권한 상태에서 실행되거나 앤서블에 become을 사용해 실행해야 함
- 마스터(1500MB)와 워커 노드(1024MB)에 최소 메모리 용량 이상을 지정해야 함
kubespray를 위한 가상 머신 설치하기
kubespray로 쿠버네티스 클러스터를 구성하려면 서버가 필요합니다.
우선 가상 머신을 구성해 보겠습니다.
-
로컬 환경에 git glone해놓은 레지스트리(/Users/noharam/Desktop/k8s/app/C.kubespray)에서 vagrant up을 실행해 kubespray를 실행할 가상 머신을 설치합니다.
-
가상 머신이 모두 설치되면 다음과 같이 Terminus에서 모든 가상 머신에 접속합니다.
- Vagrantfile을 확인해보면 m11~m13은 192.168.1.11~13이고, w101~106은 192.168.1.101~106입니다.
- 해당 설정은 아래와 같이 합니다. 그룹명은 자유롭게 하시고 하나씩 모든 호스트를 연결해줍니다.
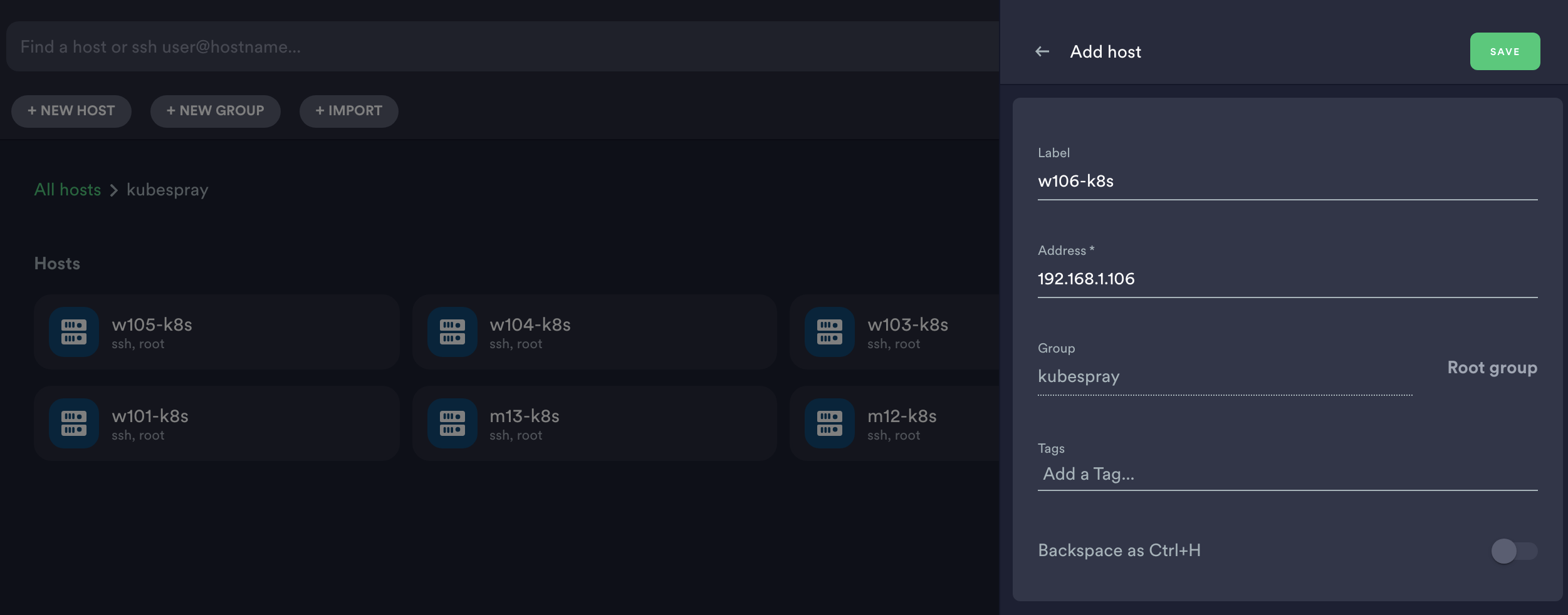
- 라벨은 m11~13, w101~106 모두 등록해주고 address는 위에 입력한 것과 같이 합니다.
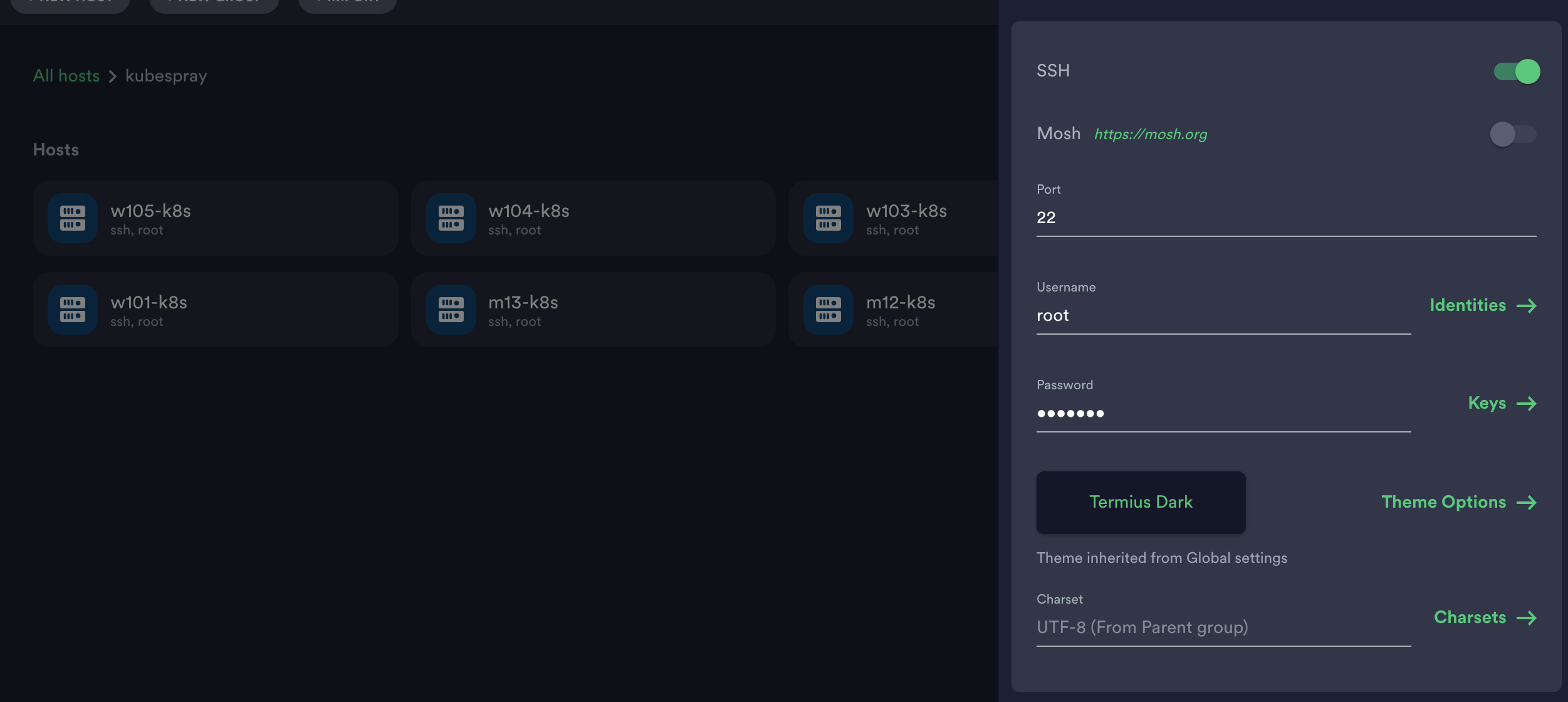
- 포트는 22번으로, Username은 root, Password는 vagrant로 합니다.
- 이후 과정을 진행하기 위해 모두 한번씩 접속해줘야 합니다.
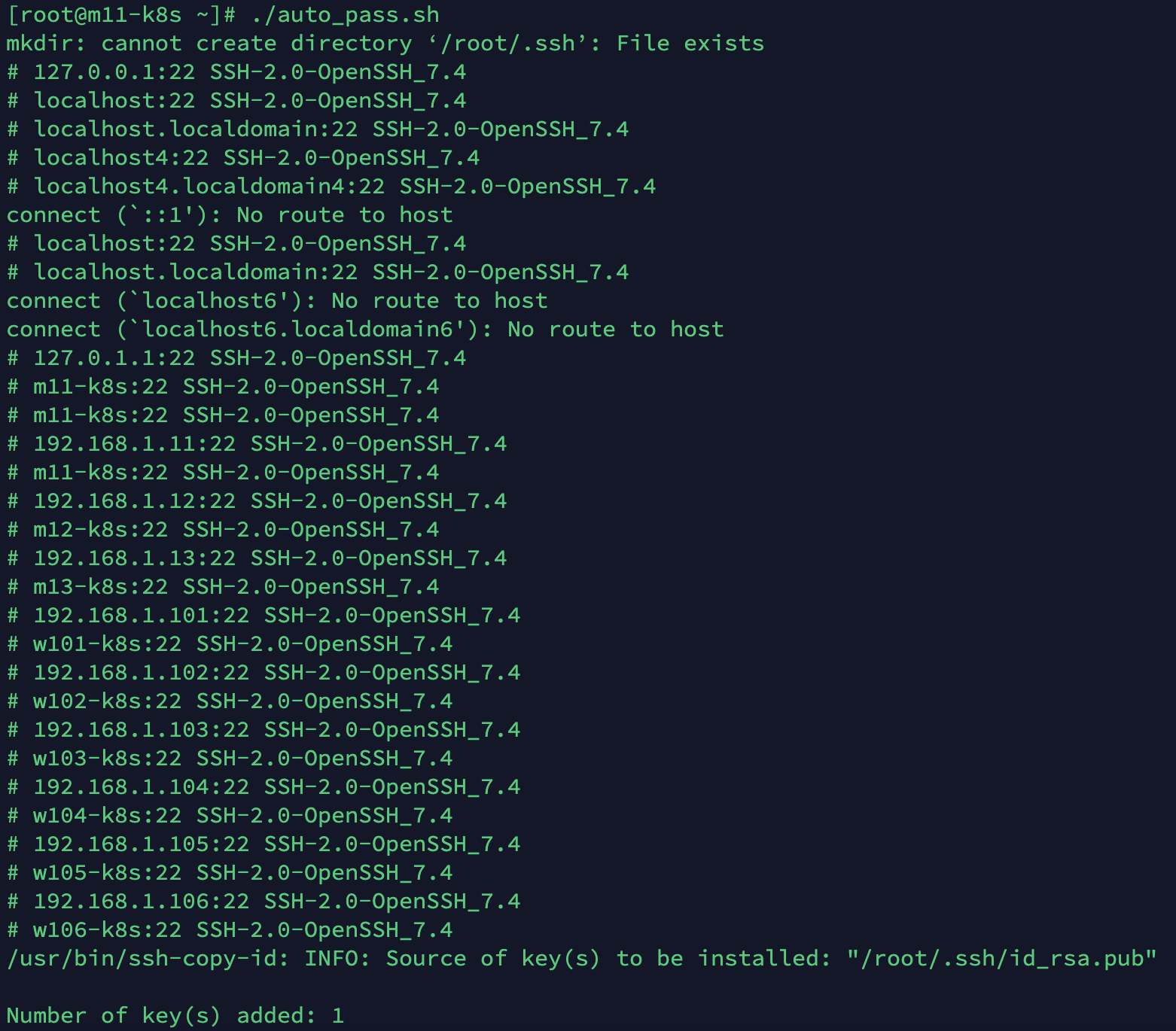
./auto_pass.sh를 실행해 가상 머신 간의 교차 인증(Known_hosts, authorized_keys)를 진행합니다.- 모든 노드에서
./auto_pass.sh를 실행해줍니다.(총 9번 실행해야겠죠?, 그러려면 위 과정에서 먼저 9개의 호스트에 먼저 접속해놔야겠죠?)
- 윈도우의 경우 슈퍼푸티에서 진행하신다면 커맨트 입력 창에 한번의 명령만으로 실행이 가능합니다.
- 모든 노드에서
kubespray 설정 및 실행하기
kubespray는 사용자가 원하는 형태의 쿠버네티스 클러스터를 구성하도록 다음 4가지 사항을 선택할 수 있습니다.
- 마스터 노드의 위치
- etcd의 설치 위치
- 워커 노드의 설치 위치
- 네트워크 플러그인의 선택 및 사용
kubespray는 여러 개의 마스터와 etcd를 구성할 수 있어 이에 대한 수량을 지정할 수 있습니다.
여기서는 다음과 같이 미리 작성된 파일을 실행해 마스터 노드 3개, etcd와 워커 노드 6개, calico 네트워크 플러그인을 설치하겠습니다.
[all]
m11-k8s ansible_host=192.168.1.11 ip=192.168.1.11
m12-k8s ansible_host=192.168.1.12 ip=192.168.1.12
m13-k8s ansible_host=192.168.1.13 ip=192.168.1.13
w101-k8s ansible_host=192.168.1.101 ip=192.168.1.101
w102-k8s ansible_host=192.168.1.102 ip=192.168.1.102
w103-k8s ansible_host=192.168.1.103 ip=192.168.1.103
w104-k8s ansible_host=192.168.1.104 ip=192.168.1.104
w105-k8s ansible_host=192.168.1.105 ip=192.168.1.105
w106-k8s ansible_host=192.168.1.106 ip=192.168.1.106
[etcd]
m11-k8s
m12-k8s
m13-k8s
[kube-master]
m11-k8s
m12-k8s
m13-k8s
[kube-node]
w101-k8s
w102-k8s
w103-k8s
w104-k8s
w105-k8s
w106-k8s
[calico-rr]
[k8s-cluster:children]
kube-master
kube-node
calico-rr이 파일은 m11-k8s 노드 안에 들어있습니다.(ls로 확인)
- m11-k8s에서 ansible-playbook으로 kubespray/cluster.yml을 실행해 쿠버네티스 클러스터를 설치합니다.
- 이때 i 옵션과 목적에 맞는 노드들을 정리한 ansible_hosts.ini 파일을 지정해 설치를 진행합니다.
- 설치하는데 매우 오랜 시간(30~2시간)이 걸리니 여유를 가지고 다른 업무를 보다 오시기 바랍니다.
ansible-playbook kubespray/cluster.yml -i ansible_hosts.ini- 저는 컴퓨터에 용량이 부족하여 진행중에 설치가 멈추어 버렸습니다. 일단 설치가 완료되면 아래 단계를 진행하시면 됩니다.
- 설치가 완료되면
kubectl get nodes로 쿠버네티스 클러스터 구성을 확인합니다.
이렇게 쿠버네티스 클러스터가 kubespray로 자동 구성됐습니다!
컨테이너 깊게 들여다보기
쿠버네티스를 운영하면서 컨테이너와 관련해 논의할 사항이 생겼을 때, 컨테이너에 대한 이해가 없다면 깊게 논의하기가 어렵습니다.
또한 PaaS(Platform as a Service)와 같이 컨테이너를 기반으로 플랫폼을 제공하는 서비스를 만들 때는
컨테이너 런타임을 직접 관리해야 하기 때문에 동작 원리도 알아둬야 합니다!
그러므로 쿠버네티스가 컨테이너를 다루는 과정과 컨테이너의 PID가 무엇인지 살펴보고
도커가 아닌 다른 방법으로 컨테이너를 생성해 보며 컨테이너를 좀 더 깊게 알아보겠습니다.
쿠버네티스가 컨테이너를 다루는 과정
앞선 포스팅에서 파드의 생명 주기로 쿠버네티스 구성 요소 살펴보기에서
쿠버네티스의 구성 요소를 중심으로 파드가 생성되는 과정을 살펴봤습니다.
이번에는 파드 생성 과정을 컨테이너 중심으로 살펴보겠습니다.
도커의 버전마다 약간씩 다르므로 멀티 스테이지 빌드가 되는 docker-ce 18.09.9를 기준으로 알아봅시다.
-
사용자는 kube-apiserver의 URL로 요청을 전달하거나 kubectl을 통해 명령어를 입력해 kube-apiserver에 파드를 생성하는 명령을 내립니다.
-
파드를 생성하는 명령은 네트워크를 통해 kubelet으로 전달됩니다.
- kube-apiserver는 노드에 있는 kubelet과 안전하게 통신하기 위해 인증서와 키로 통신 내용을 암호화해 전달합니다.
- 이때 키는 마스터 노드의 /etc/kubenetes/pki/ 디렉터리에 보관돼 있고, 인증서 파일인 apiserver-kubelet-client.crt와 키 파일인 apiserver-kubelet-client.key를 사용합니다.
ls /etc/kubernetes/pki/apiserver-kubelet-clinet.*- kubelet으로 생성 요청이 전달되면 kubelet은 요청이 적절한 사용자로부터 전달된 것인지를 검증합니다. 전달된 요청을 검증하기 위해서 kubelet 설정이 담겨 있는 /var/lib/kubelet/config.yaml 파일의 clientCAFile 속성에 설정된 파일을 사용합니다.
cat /var/lib/kubelet/config.yaml | grep clientCAFile
-
kubelet에서 요청을 검증하고 나면 컨테이너디에 컨테이너를 생성하는 명령을 내립니다.
- 이때 명령 형식은 컨테이너 런타임 인터페이스(CRI, Container Runtime Interface) 라는 규약을 따릅니다.
- CRI는 컨테이너와 관련된 명령을 내리는 런타임 서비스와 이미지와 관련된 명령을 내리는 이미지 서비스로 이루어져 있습니다.
- 런타임 서비스는 파드의 생성, 삭제, 정지, 목록 조회와 컨테이너 생성, 시작, 정지, 삭제, 목록 조회, 상태 조회 등의 다양한 명령을 내립니다.
- kubelet이 내린 명령은 컨테이너디에 통합된 CRI플러그인이라는 구성 요소에 전달됩니다. CRI 플러그인은 컨테이너디에 통합돼 있으므로 컨테이너디가 컨테이너를 생성하는 명령을 직접 호출합니다.
-
컨테이너디는 containerd-shim이라는 자식(child) 프로세스를 생성해 컨테이너를 관리합니다.
- 저는 위에서 kubespray로 생성한 클러스터가 용량 문제로 제대로 설치되지 않았으므로, 이전 포스팅들에서 사용하던 마스터 노드인 m-k8s에서 진행하겠습니다.
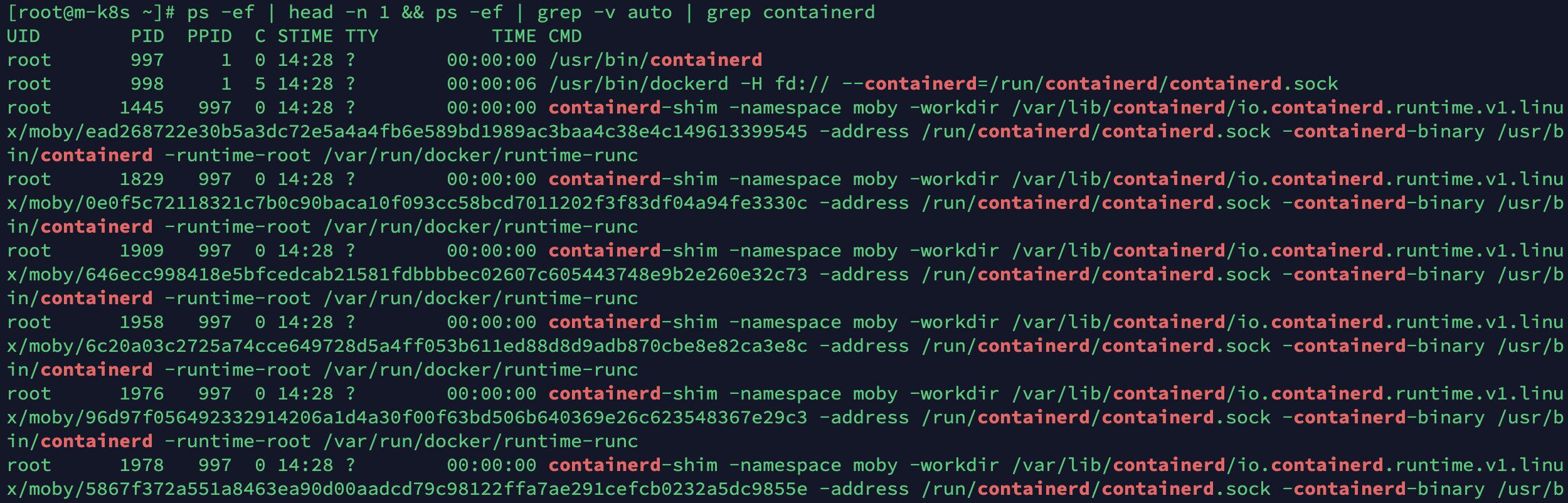
- 다음 출력 예시를 보면 PID가 997인 containerd 프로세스는 PID 1445, 1829등인 자식 프로세스 containerd-shim을 가지고 있습니다.
- 이때 PID 998번 dockerd는 사용자가 입력한 도커 명령을 컨테이너디에 전달하기 위해 도커 엔진 내부에 생성된 프로세스입니다.
ps -ef | head -n 1 && ps -ef | grep -v auto | grep containerd
-
containerd가 생성한 containerd-shim 프로세스는 컨테이너를 조작합니다. 실제로 containerd-shim이 runC 바이너리 실행 파일을 호출해 컨테이너를 생성합니다.
사용자가 파드를 생성하려고 보낸 명령이 어떤 과정을 거치면서 전달되는지 살펴보았습니다.
기억나실지 모르겠지만 이전 포스팅에서 컨테이너의 PID는 항상 1을 가진다고 했습니다.
하지만 containerd와 containerd-shim 어디에도 1은 보이지 않습니다. 어떻게 된걸까요?
컨테이너를 이해하려면 이 관계를 좀 더 살펴봐야 합니다.
컨테이너 PID 1의 의미
리눅스 운영 체제의 PID를 공부해 보면 알겠지만 PID 1은 커널이 할당하는 첫 번째 PID라는 의미의 특수한 PID입니다.
일반적으로 init 또는 systemd에 PID 1이 할당되며 시스템 구동에 필요한 프로세스들을 띄우는 매우 중요한 역할을 합니다.
PID 1번 이외에도 PID 0번 swapper, PID 2번 kthreadd 등이 미리 예약된 PID를 가집니다.

그런데 컨테이너의 PID 1번은 컨테이너에서 실행된 애플리케이션인 nginx 프로세스가 가집니다. 왜일까요?
다시 한 번 예약된 PID의 역할을 읽어 봅시다. 시스템을 구동시키는 역할입니다.
그런데 컨테이너는 이미 구동된 시스템, 즉 커널 위에서 동작한다고 배웠습니다.
뭔가 앞뒤가 맞는 느낌이 들죠?
컨테이너는 운영 체제 시스템을 구동시킬 필요가 없이 바로 동작하기 때문에 시스템에 예약된 PID 1번이 할당되지 않은 상태라서 최초 실행자 nginx에게 할당할 수 있습니다.
그래서 특수한 PID 1번은 컨테이너 시계에서 컨테이너가 실행하는 첫 애플리케이션에게 할당해 사용합니다.
도커로 생성한 컨테이너 PID와 컨테이너 내부의 PID 1번이 연결돼 있는지 실습으로 확인해 봅시다!
-
이번 실습에서 생성할 nginx의 동작을 정확하게 확인하기 위해
ps -ef | grep -v auto | grep nginx명령을 실행해 nginx와 관련된 프로세스가 호스트에 있는지 확인합니다.- 실행한 결과에 표시되는 것이 있다면 docker ps로 구동 중인 nginx 컨테이너를 확인한 다음, docker stop으로 종료합니다.

- 실행한 결과에 표시되는 것이 있다면 docker ps로 구동 중인 nginx 컨테이너를 확인한 다음, docker stop으로 종료합니다.
-
이제 nginx 컨테이너를 구동하고 nginx와 관련된 프로세스를 다시 확인합니다.
- 이떄 별도로 이미지를 내려받지 않더라도
docker run -d nginx명령을 수행하는 과정에서 이미지가 필요하다면 자동으로 내려받게 됩니다.(library/nginx 에서)

ps -ef | grep -v auto | grep nginx을 실행한 결과 PID가 27021인 프로세스가 나타납니다.

- 여기서 자식 프로세스인 27084와 28085는 nginx의 실제 역할을 담당하게 되며 부모 프로세스가 생성될 때 함께 생성됩니다. 따라서 nginx 기능을 하는 프로세스는 27021 1개라고 볼 수 있습니다.
- 현재 생성된 프로세스는 도커가 생성한 것이기 때문에 컨테이너 내부에 격리돼 있습니다. 그런데 호스트에서 ps -ef 명령을 통해 nginx 프로세스를 확인할 수 있습니다. 이는 호스트에서 보이는 프로세스와 컨테이너 프로세스가 연결돼 있음을 추측할 수 있게 합니다! 연결이 어떻게 돼 있는지 확인해 봅시다.
- 이떄 별도로 이미지를 내려받지 않더라도
-
호스트에서 구동 중인 nginx 프로세스를 확인했으니 컨테이너 내부의 nginx 프로세스를 확인해 봅시다.
- 리눅스는 프로세스와 관련된 정보를
/proc/<PID>/디렉터리에 보관하며/proc/<PID>/exe는 해당<PID>를 가지는 프로세스를 생성하기 위해 실제로 실행된 명령어를 보여줍니다. - 컨테이너 내부의 PID가 1인 프로세스의 명령어 정보를 조회한 결과인 /proc/1/exe -> /usr/sbin/nginx는 컨테이너 내부에서 PID 1을 가지고 구동 중인 프로세스가 nginx임을 의미합니다.
docker ps로 구동중인 nginx의 CONTAINER ID를 확인하고 아래 명령어에 활용해주세요!

docker exec 240a ls -l /proc/1/exe

docker exec <컨테이너 ID>를 입력하지 않으면 호스트의 /proc/1/exe의 정보를 확인하는 것이 됩니다(커널을 구동시키는 관련 디렉터리 정보가 나타나겠죠?). 우리는 도커 내부의 컨테이너를 확인하고 싶은 것이니 해당 명령이 추가되어야 합니다.
- 리눅스는 프로세스와 관련된 정보를
-
호스트와 컨테이너 내부에서 nginx가 구동되는 것을 확인했습니다. 그렇다면 이 두개가 동일한 프로세스라는 것을 확인하면 됩니다.(호스트 PID 27021과 컨테이너 PID 1번이 동일하다는 것)
- 확인하는 한 가지 방법은 이 프로세스에 할당된 자원과 관련된 정책을 살펴보는 것입니다. 앞선 포스팅에서 컨테이너는 격리된 공간에서 CPU나 메모리와 같은 자원을 할당받아서 동작한다고 했습니다. 두 PID가 같은 프로세스라면 CPU, 메모리 같은 자원의 할당에 관한 설정이 동일할 것입니다.
- 리눅스는 자원을 그룹별로 나누어서 할당하고 제한을 설정하기 위해 씨그룹(Cgroup) 이라는 기술을 사용합니다. 씨그룹 설정이 동일하다면 두 프로세스는 동일한 환경에서 동작하는 프로세스로 생각할 수 있습니다. 씨그룹과 관련된 설정은
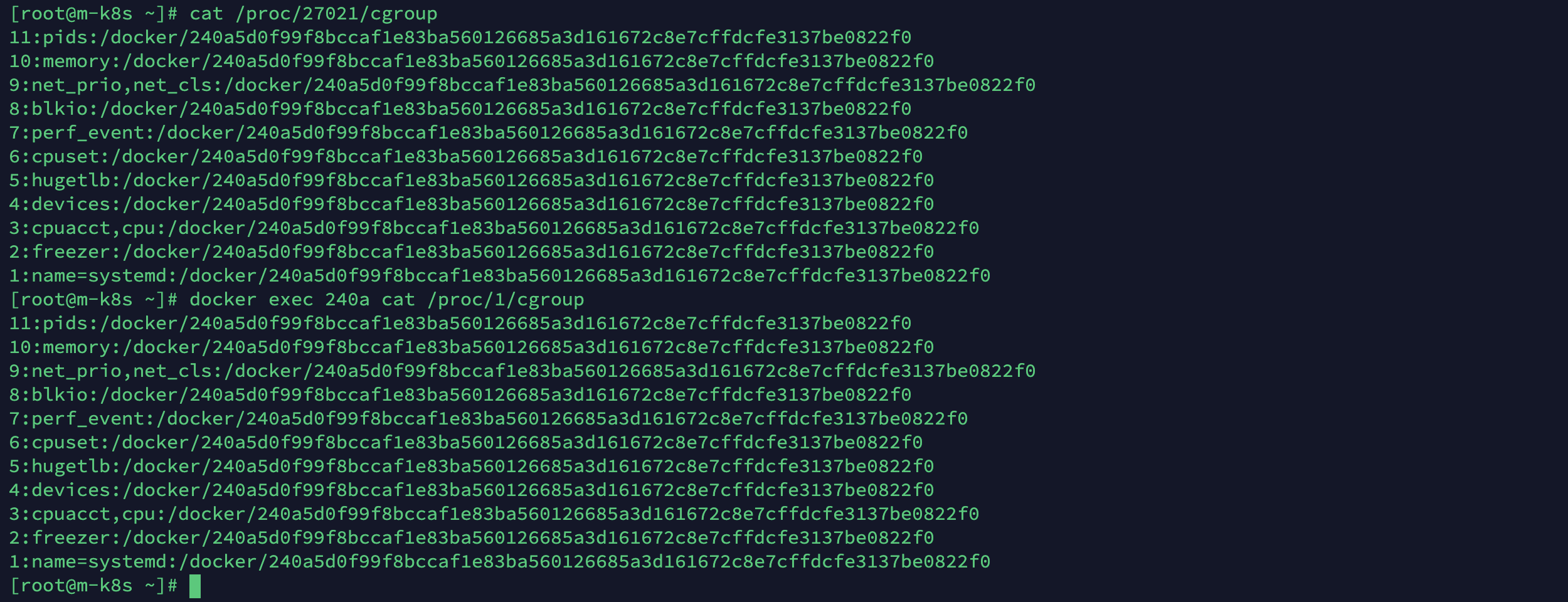
/proc/<PID>/cgroup의 내용을 cat으로 조회하면 알 수 있습니다. - PID가 호스트 27021과 컨테이너 1의 씨그룹 설정을 확인해 봅시다. 실행 결과에 여러 내용이 있지만 씨그룹을 자세하게 다루지는 않으므로 이름(name)만 살펴봅시다. 두 프로세스의 자원 할당을 관리하는 씨그룹 정책의 이름이 동일한 것을 확인할 수 있습니다. 그리고 이름에 나타나는
240a로 시작하는 내용들이 서로 동일한 것으로 모아 두 프로세스는 관련이 있다는 것을 추측할 수 있습니다. cat /proc/27021/cgroupdocker exec 240a cat /proc/1/cgroup
-
이 프로세스가 정말 동일한지 PID 27021번을 강제 종료하고 컨테이너 PID 1번의 상태를 확인해 보곘습니다.
- 강제 종료한 결과 호스트 PID 27021번의 씨그룹은 더 이상 확인되지 않으며, 240a 컨테이너의 PID 1번 또한 확인되지 않습니다. 따라서 두 개의 프로세는 같은 것을 확인할 수 있습니다.
kill -9 27021cat /proc/27021/cgroupdocker exec 240a cat /proc/1/cgroup

동일한 프로세스가 호스트와 컨테이너 내부에서 서로 다른 PID를 가지면서 컨테이너 내부에서는 독립된 것처럼 PID 1번 프로세스로 동작할 수 있는 이유는
컨테이너가 리눅스의 네임스페이스 기술을 활용하기 때문입니다.
네임스페이스는 호스트명, 네트워크, 파일 시스템 마운트, 프로세스 간 통신, 사용자 ID, PID 등의 자원을 격리할 수 있는 기술입니다.
네임스페이스로 격리된 내부에서는 외부가 보이지 않기 때문에 컨테이너 내부는 독립된 공간처럼 느껴집니다.
이때 네임스페이스로 격된 프로세스에 메모리, CPU, 네트워크, 장치 입출력 등의 사용량을 할당하고 제한하는 데 앞에서 설명한 씨그룹 기술을 사용합니다.
그리고 이러한 격리 기술을 쉽게 사용할 수 있게 하는 것이 도커입니다.
그런데 만약에 도커를 사용하지 않는다면 얼마나 번거롭게 컨테이너를 만들어야 할까요?
직접 컨테이너를 만들어보면서 확인해 봅시다.
도커 아닌 runC로 컨테이너 생성하기
앞에서 컨테이너를 만들 떄 실제로는 runC라는 실행 바이너리를 통해 만든다고 했는데,
runC는 무엇일까요?
runC는 오픈 컨테이너 이니셔티브(OCI, Open Container Initiative, 컨테이너 형식과 런타임에 대해 개방된 업계 표준을 만들기 위한 단체)에서 만든 컨테이너 생성 및 관리를 위한 표준 규격입니다.
컨테이너디, 크라이오 등의 다양한 컨테이너 런타임들이 내부적으로 runC를 활용해 표준 규격을 따르는 컨테이너를 생성하고 있습니다.
이 때문에 컨테이너 런타임을 분류할 때 쿠버네티스나 도커 명령을 받아들이는 컨테이너디나 크라이오 같은 구성 요소를 고수준(High-level) 컨테이너 런타임,
실제로 컨테이너를 조작하기 위해 리눅스에 명령을 내리는 runC를 저수준(Low-lebel) 컨테이너 런타임으로 분류합니다.
그러면 지금까지 사용했던 도커와 같은 고수준의 컨테이너 런타임이 아닌 저수준의 컨테이너 런타임을 통해
컨테이너를 생성해 보며 고수준의 컨테이너 런타임이 얼마나 효과적으로 컨테이너를 생성 및 관리하게 도와줬는지 체감해 봅시다.
실습에서는 가능한 복잡하지 않게 씨그룹을 이용한 자원 할당 및 제한에 관해서는 다루지 않고, 네임스페이스를 이용해 프로세스와 네트워크를 분리하는 수준에서만 진행하겠습니다.
- runC로 컨테이너를 구성하는 과정이 복잡하여 시간 관계상 생략합니다. 컨테이너 생성 및 관리는 도커를 이용하도록 합시다 ^^..
본 게시물은 "컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 - 조훈,심근우,문성주 지음(2021)" 기반으로 작성되었습니다.
