Kubernetes GPU RAM 분할(Extended Resource 이용)
앞선 두 포스팅 (1), (2)에서 얘기햇듯이, 쿠버네티스에서 리소스를 요청할 때 gpu는 제약사항이 많습니다.
그래서 아래와 같은 상황일 때 참고하시라고 GPU RAM을 분할하여 컨테이너에 할당할 수 있는 방법을 함께 진행해보고자 합니다.
-
n개의 컨테이너에 GPU를 공유해서 할당할 수 없다.
- 연속된 파이프라인에 각각 limit으로 GPU를 요청한다면, 순차적으로 실행될 순 있으나 잦은 오류가 발생(Pending, timeout 등)
-
GPU를 분할하여 컨테이너에 할당하고자 하나 NVIDIA MIG는 A100, A30 등의 시리즈만 지원한다.(A5000 등 저가 제품 사용자는 MIG 사용 불가능합니다 - 사실 이게 절대 저가가 아닌데 말이죠...)
-
쿠버네티스에 GPU를 활용하고자 하는데 MIG가 아닌 GPU 분할 할당 방법을 찾고있다!
- Kubernetes에는 리소스 쿼터라는 개념이 있어서, CPU, RAM을 나눠서 사용할 수 있도록 기능을 제공해 준다. -> 오늘 이용할 핵심 개념입니다. 이처럼 VRAM을 나눠서 요청할 겁니다.
서버 스펙 / 컨테이너 요구 스텍 파악
- 서버 스펙부터 파악해봅시다.
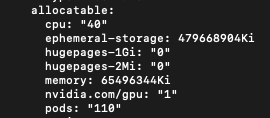
kubectl get nodes -o yaml
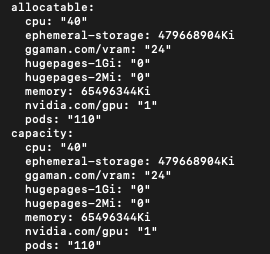
- allocatable 섹션을 보시면 노드에서 할당 가능한 스펙이 나와있습니다.
- 그냥
free -h로 메모리(램)확인,df -h로 용량 확인 하셔는게 파악하기 편합니다. - VRAM은 현재 사용중인 GPU 정보에서 따왔습니다.(NVIDIA RTX A5000 D6 24GB)
- CPU : 40core- Memory(RAM) : 62.47 GiB (available: 52G)
- 임시 스토리지 : 457.44 GiB (Avail: 224G)
- VRAM : 24GB
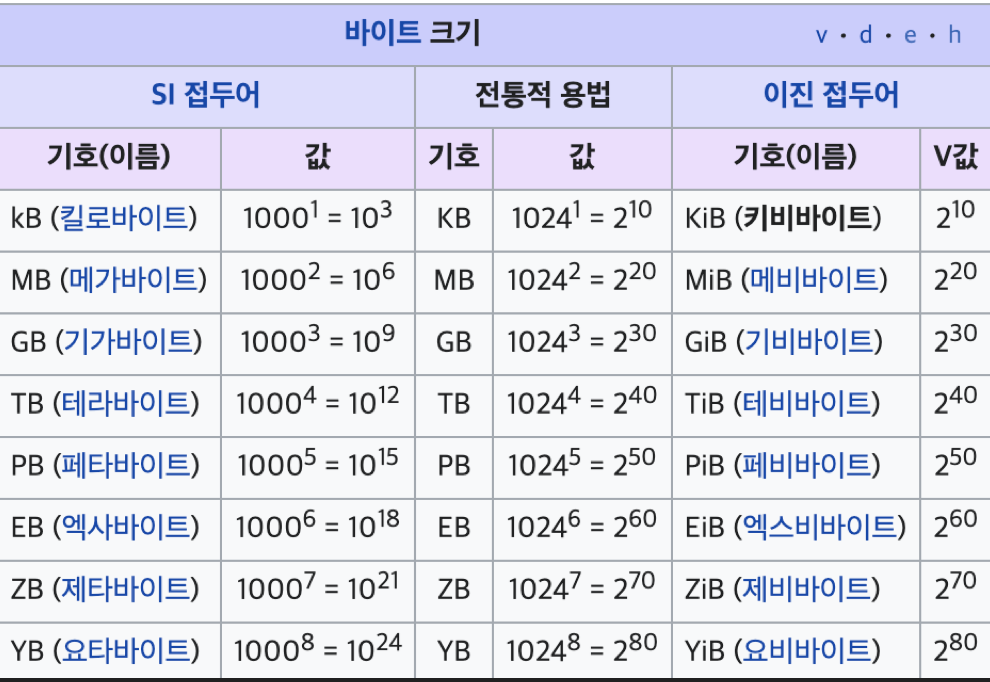
kB, KiB, Ki가 헷갈리시는 분들을 위한 용량 정의

- 컨테이너 요구 스펙
이 부분은 아직 확인하는 방법을 찾지 못했습니다.
해당 컨테이너가 어느 정도의 리소스를 요청해야 정상작동할지 가늠해서 정하시면 될 것 같습니다.
이번 포스팅에선 어차피 CPU/RAM의 리소스 요청량을 지정하지 않고, VRAM에 대해서만 limit을 지정해 줄 예정이니 넘어갑니다!
- 현직자분들께 문의해보니 대부분 실험적으로 pod를 생성해서 돌려보고, 사용량에 따라 VRAM을 다시 할당해주신다고 하더라구요. 저도 아래서 보면 아시겠지만 VRAM을 6개로 나눴다가 VRAM이 사용량에 비해 과하게 설정되어, 24개로 분할해서 1GB씩 하나의 pod에 할당해주었습니다.
Extended Resource 생성
- Kubernetes에서는 "Extended Resource"를 정의해서 사용할 수 있습니다.
- 아래 이미지에 리소스들이 정의되어 있는데, 사용자 정의 리소스를 추가할 수 있다는 뜻입니다.
Extended Resource를 node에 추가 하기
- API를 이용하기 위한 JWT 토큰을 얻어옵니다.
kubectl get serviceaccount default
TOKEN=$(kubectl get secret $(kubectl get sa default \
-ojsonpath="{.secrets[0].name}") \
-ojsonpath="{.data.token}" | base64 -d)
echo $TOKEN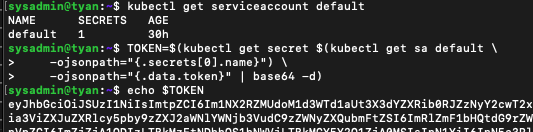
-
default라는 사용자(ServiceAccount)에 적절한 권한을 부여해 봅시다.
- 이번 포스팅에선 편의를 위해 cluster-admin 권한을 부여하도록 하겠습니다. 운영환경에서는 매우 위험한 행위니 적절한 권한을 부여해 주시기 바랍니다.
kubectl create clusterrolebinding default-cluster-admin --clusterrole cluster-admin --serviceaccount kubeflow-user-example-com:default

-
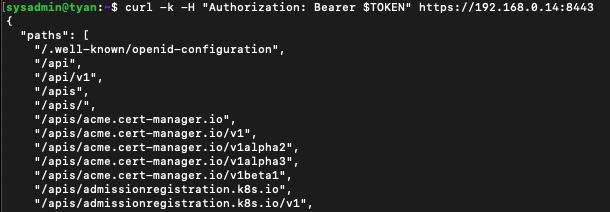
API 서버 주소를 알아봅시다.
kubectl cluster-info

저는 https://192.168.0.14:8443 으로 요청하면 되겠군요! -
이제 토큰도, 서비스 어카운트 권한 부여도 끝났으니 api 결과가 문제없이 나오나 확인해봅시다!
curl -k -H "Authorization: Bearer $TOKEN" https://192.168.0.14:8443
-
노드 이름도 확인합니다.
kubectl get nodes

-
이제 준비가 끝났습니다, kubernetes API Server에 Extended Resource를 위한 http PATCH를 진행합니다.
curl -k -H "Authorization: Bearer $TOKEN" --header "Content-Type: application/json-patch+json" --request PATCH --data '[{"op": "add", "path": "/status/capacity/ggaman.com~1vram", "value": "24"}]' https://192.168.0.14:8443/api/v1/nodes/tyan/status
형식은 아래와 같습니다.
curl -k -H "Authorization: Bearer $TOKEN" --header "Content-Type: application/json-patch+json" --request PATCH --data '[{"op": "add", "path": "/status/capacity/<정의하고자하는 ExtendedResource 이름>", "value": "<VRAM>"}]' <컨트롤플레인 api주소>/api/v1/nodes/<노드이름>/status
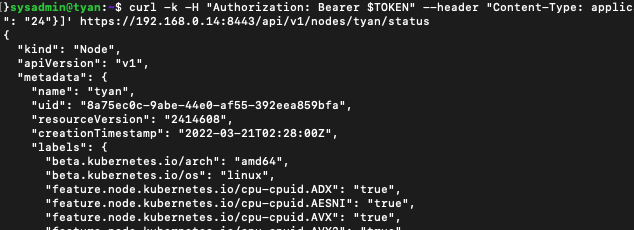
Extended Resource가 적용되었는지 확인해봅시다.
kubectl get nodes -o yaml
- ggaman.com/vram은 정해진 형식입니다. 동일하게 사용해주시면 됩니다.
- 무사히 커스텀 리소스 등록을 마쳤군요!! 이제 해당 리소스를 파드의 리소스 제한에 이용해서 GPU를 분할 사용해봅시다!
Extended Resource 사용하여 GPU 분할 확인하기
사용자체는 기존처럼 pod에 resources.limit을 설정해준 것처럼 간단하게 nvidia.com/gpu를 ggaman.com/vram으로 변경해주시면 됩니다!
"spec": {
"tfReplicaSpecs": {
"Chief": {
"replicas": 1,
"restartPolicy": "OnFailure",
"template": {
"metadata": {
"annotations": {"sidecar.istio.io/inject": "false"}
},
"spec": {
"containers": [
{
"name": "tensorflow",
"image": "docker.io/moey920/train_forecasting_model:latest",
"command": [
"python",
"/code/ecm_forecasting_ar_lstm/main.py",
f"--df_me={df_me}",
"--input_width=${trialParameters.inputWidth}",
"--label_width=${trialParameters.labelWidth}",
"--shift=${trialParameters.shift}",
],
"resources": {
"limits": {
"ggaman.com/vram": 1
}
},
}
]
},
},
},이제 아래처럼 1개의 GPU를 여러 컨테이너에서 VRAM으로 병렬 할당받아 사용하는 것을 확인할 수 있습니다!
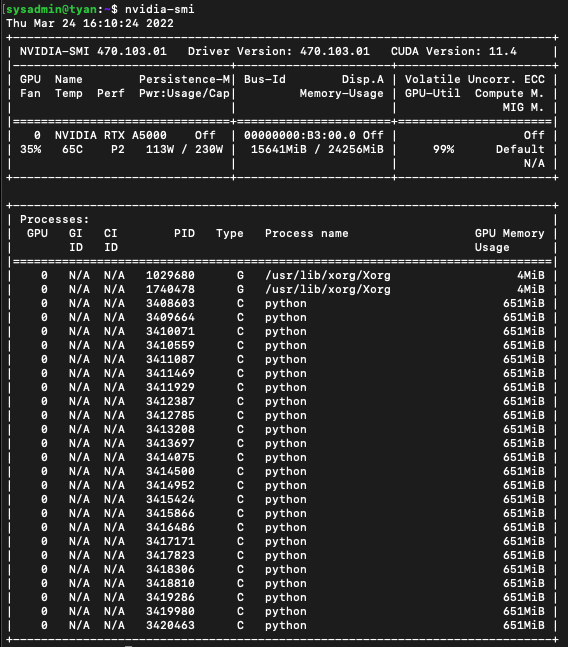
부록
출처 : https://blog.ggaman.com/1025, https://coffeewhale.com/apiserver

안녕하세요. 노하람님 글 잘 읽었습니다.
extended resource를 통해 gpu vram을 분할한다는 내용은 혼동의 소지가 있는 것 같습니다. kubernetes extended resource는 자원에 대한 논리적인 명세입니다. 따라서 extended resource가 논리적인 자원을 스펙상에 명시할 수 있을지 언정, 기본적인 쿠버네티스 리소스인 cpu나 memory와 같은 레벨의 자원 분할과 격리는 되지 않기 때문에 이 글에 설명하는 것과 같이 GPU VRAM에 대한 자원 분할이 된다고 설명하는것은 문제가 될것 같습니다. 유저 별로 제한된 자원을 격리하기 위해선 유저 어플리케이션(tf 혹은 torch) 나 디바이스 레벨에서 격리가 되어야합니다.
kubernetes 에서 gpu를 분할할때 어려운 부분은 격리와 관련된 부분들입니다. 이와 관련된 스타트업들인 run.ai나 backend.ai에서 다루는 부분들도 이 부분들입니다.
제가 이 댓글을 남기는 이유는 https://medium.com/@sunwoopark/%EB%B0%B1%EC%97%94%EB%93%9C-n%EB%85%84%EC%B0%A8-mlops-1%EC%9D%BC%EC%B0%A8-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98-%EC%B5%9C%EC%A0%81%ED%99%94%EC%99%80-gpu-%EA%B4%80%EB%A6%AC-630afb4440e5 이 글에서처럼, 일부 내용이 쿠버네티스를 접하는 사람들에게, 쿠버네티스가 GPU 메모리 자원분할 까지 가능한 것 처럼 이해가 될 소지가 있어보입니다.