Amazon Web Service
01.
What Amazon Web Service?
아마존 웹 서비스(AWS)란 아마존이 자사의 노하우를 살려 제공하고 있는 ‘클라우드 컴퓨팅 서비스’를 의미합니다. AWS는 대부분의 컴퓨팅 서비스가 준비되어 있으며, AWS의 다양한 서비스를 조합하여 사용이 가능합니다.
1. Cloud Computing
가상화 기술의 발전과 함께 등장했으며 기존의 물리적 컴퓨터로 만들어진 데이터 센터와 다르게 가상의 컴퓨터를 사용자에게 대여해주는 서비스입니다.이로 인해 공간의 제약과 주기적인 관리가 필요했던 물리적 한계를 넘어 클라우드 컴퓨팅 서비스를 확장시켰습니다.
2. Elastic Compute Cloud
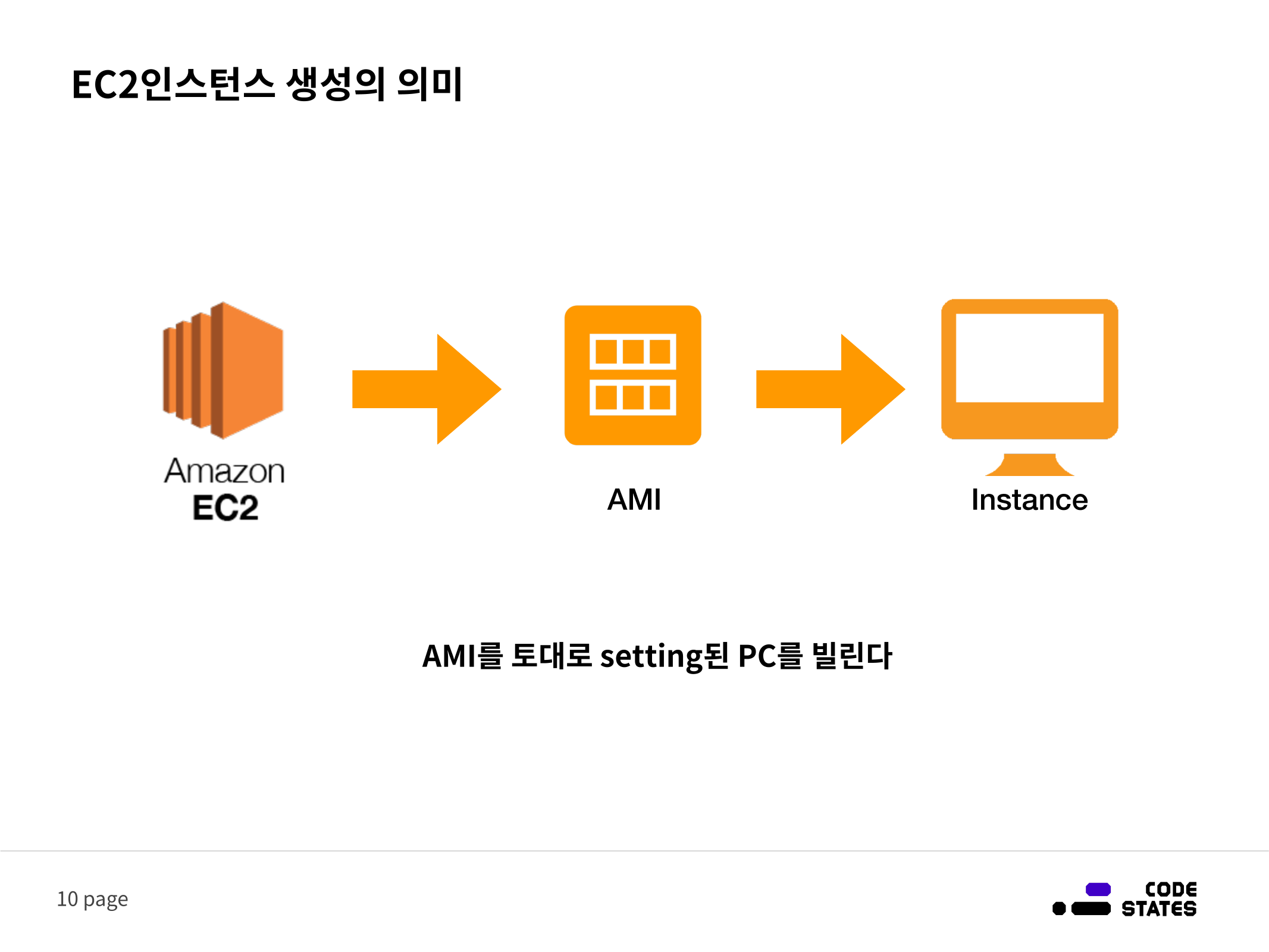
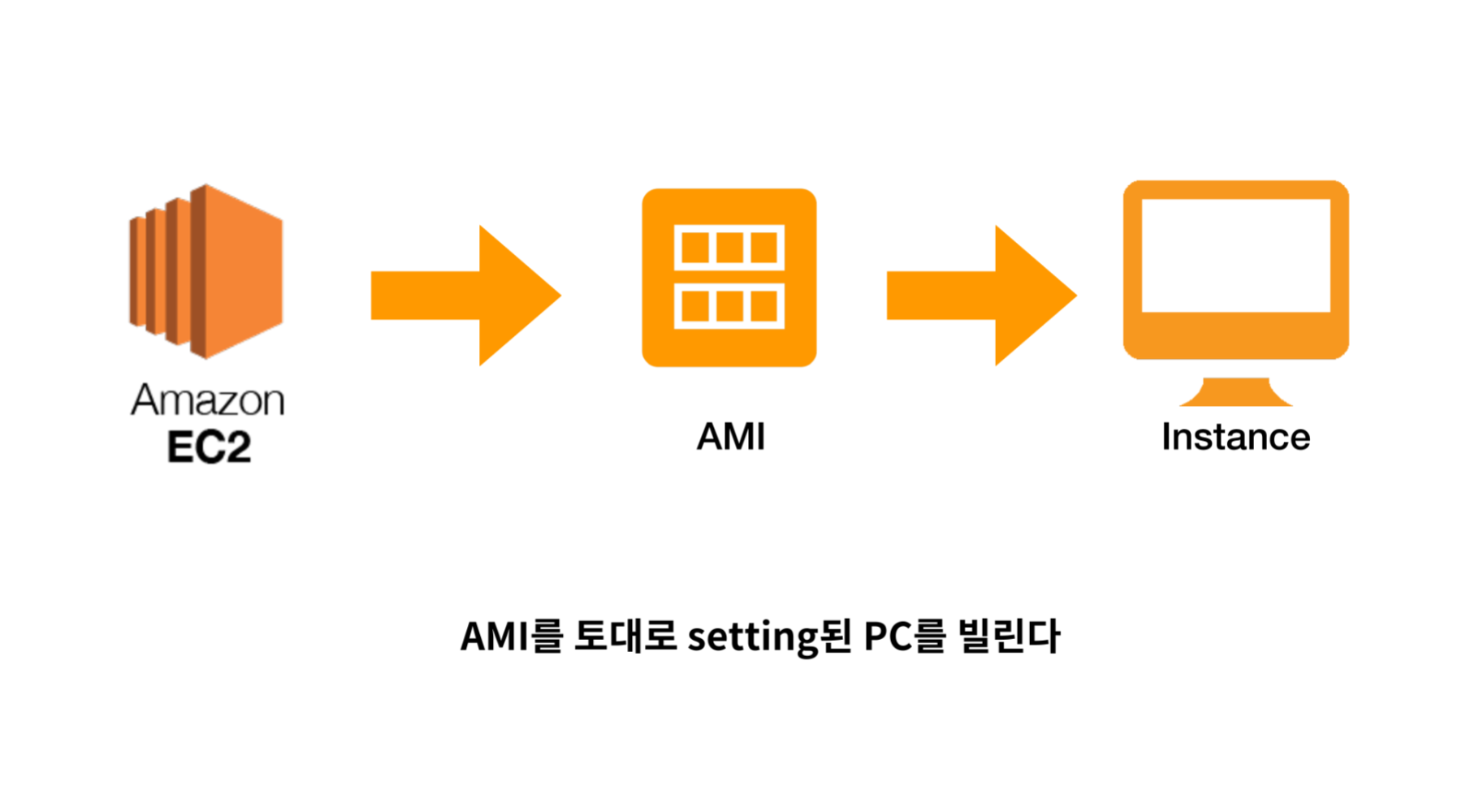
EC2는 필요에 따라 성능, 용량을 자유롭게 조절 가능한 가상의 컴퓨터 대여 서비스입니다. 물리적인 컴퓨터 대여 및 구매에 비해 구성시간이 짧고 운영체제나 용량 등 다양한 옵션 또한 AMI(템플릿)로 제공되어 선택의 폭이 넓다는 장점이 있습니다. 대여한 컴퓨터는 인스턴스라는 단위로 불리며 EC2를 통해 컴퓨터를 대여하면 인스턴스를 생성한다고 말합니다.Amazon Machine Image
AMI는 소프트웨어로 이루어진 구성과 패키지들의 템플릿입니다.
단순히 운영체제(윈도우, 우분투 리눅스 등)만 깔려있는 템플릿을 선택할 수도 있고, 아예 특정 런타임이 설치되어 있는 템플릿이 제공되는 경우도 있습니다. (우분투 + node.js, 윈도우 + JVM 등)
Instance
Instance는 Instance는 선택한 AMI를 토대로 구성됩니다.
AWS에는 상당히 많은 양의 AMI 세팅이 준비되어 있기 때문에 손쉽게 인스턴스의 운영체제를 구성할 수 있고 사용자가 직접 커스텀해서 사용할 수도 있습니다. AWS EC2 인스턴스를 생성한다는 것은 AMI를 토대로 운영체제, CPU, RAM 혹은 런타임 등이 구성된 컴퓨터를 빌리는 것입니다.
3. Relational Database Service
RDS는 AWS에서 제공하는 관계형 데이터베이스 서비스입니다. RDS를 이용하면 데이터베이스 유지 보수와 관련된 일들을 RDS에서 전적으로 자동 관리합니다. 사용자가 해야 할 일은 초기 설정을 제외하고 데이터베이스에 저장된 데이터를 관리하는 일 밖에 없기에 큰 편의성을 느낄 수 있습니다. 또한 사용자는 데이터베이스 엔진마다 제공하는 기능이 조금씩 다르기에 필요와 목적에 맞게 데이터베이스 엔진을 선택하여 효율성을 높일 수 있습니다.4. Simple Storage Service
S3는 Google Drive, Naver My BOX와 같은 클라우드 스토리지 서비스입니다. S3는 높은 가용성과 높은 내구성을 지니고 있어 데이터를 저장하고 사용함에 있어서 손실율과 장애율이 현저히 낮습니다.Region
AWS는 전세계 각 지역에 물리적으로 독립된 설비로 분산되어 있는 서버 및 데이터 센터를 가지고 있습니다. 이 지역을 리전(Region)이라고 부르며 리전들이 유기적으로 데이터를 보관하며 장애나 오류가 일어나도 다른 리전에서 정상적인 작동이 가능하게끔 상호보완하는 시스템입니다.
Storage Class
다양한 스토리지의 종류 중 대표적으로 Standard와 Glacier 클래스가 있습니다.
Standard 클래스는 범용적인 목적으로 사용하기 좋습니다. 데이터에 빠른 속도로 접근할 수 있고, 데이터 액세스 요청에 대한 처리 속도가 빠릅니다. 대신 데이터를 오래 보관하는 목적으로는 효율적인 선택지가 아닙니다. 보관 비용이 높게 발생하기 때문입니다.
Glacier 클래스는 저장된 데이터에 액세스하는 속도가 느리고, 데이터를 보관하는 비용이 매우 저렴하다는 장점이 있습니다.
Bucket
S3 사용 시 Bucket을 통해 정적 파일을 업로드하여 웹 호스팅이 가능합니다. S3에서 저장되는 모든 파일은 버킷 안에 저장되어야 하고, 버킷에는 무한한 양의 파일을 저장할 수 있습니다. 그리고 각각의 버킷은 이름을 가지고 있는데, 버킷의 이름은 버킷이 속해 있는 리전(버킷이 생성된 지역)에서 유일해야 합니다. 또한 버킷 정책을 생성하여 해당 버킷에 대한 다른 유저의 접근 권한을 수정할 수 있습니다.
버킷에 업로드된 파일은 파일과 메타 데이터로 구성된 객체로 저장됩니다. 파일의 값에는 실제 데이터를 저장되며 파일의 키는 각각의 객체를 고유하게 만들어주는 식별자 역할을 합니다. 파일의 키를 이용하여 원하는 객체를 검색할 수 있습니다.
메타데이터는 객체를 설명하는 데이터입니다.
