fast.ai 첫 번째 모델 만들기
제일 간단하게 첫 모델을 만들어보려고 한다.
첫 모델은 고양이와 강아지를 분류하는 모델이다.
- 고양이,개 이미지 데이터셋 불러오기
- 사전 학습된 모델 불러오기
- 전이 학습을 통해서 모델을 미세 조정하기
모델 구성
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
첫번째 문장은 fastai의 다양한 영상 처리 모델을 생성하는데 필요한 함수와 클래스를 불러오는 구문이다.
2번째 문장은 fastai의 데이터셋 컬렉션에서 고양이,강아지 데이터셋을 불러오고(다운로드), 압축해제하고, 추출된 위치를 path 객체로 반환한다.
3번째 문장은 이미지데이터를 fastai 모델에 들어갈 수 있도록 데이터셋의 종류를 알려주고 구조를 설정해주는 코드이다.
is_cat 함수는 파일 첫번째 문자의 대소문자 여부를 통해서 레이블을 정해주는 함수이다.
DataLoader앞에 image,text와 같이 단어를 붙여서 데이터의 유형을 표현한다.
tfms는 transform(변형)의 약자로 두 종류가 있으며, item_tfms와 batch_tfms가 있다.
item_tfms는 개별 데이터 적용되는 변형이고, batch_tfms는 배치에 GPU가 빠르게 한 번에 처리할 변형이다.
224는 일반적인 픽셀 크기이고, 얼마든지 자유롭게 설정할 수 있다.
valid_pct=0.2는 데이터의 20%를 검증용으로 따로 사용하도록 설정하는 코드이다.
seed=42는 코드를 실행할 때마다 동일한 임의성으로 데이터셋을 구성하도록 시드값을 고정한 것이다.
마지막 줄 위의 코드는 이미지 분야에서 널리 쓰이는 CNN(합성공 신경망)모델을 생성한다. 이때 사용할 데이터셋과 모델의 종류 및 평가지표를 설정한다.
우리는 여기서 ResNet이라는 구조의 모델을 사용한다. 여러상황 특히나 이미지와 관련된 상황에서 빠르고 정확하게 작동하는 모델이다. 뒤에붙는 숫자는 계층의 숫자이며, resnet34는 34개의 계층이 있다는 뜻이다.
ResNet이라는 사전 학습된 모델을 사용하여 cnn_learner는 새로 추가된 데이터셋에 맞추어 마지막 부분의 계층(머리)을 업데이트 합니다.
이와 같은 사전 학습된 모델을 사용하는 일을 전이 학습이라고 한다.
마지막 문장은 사전학습된 모델인 resnet34에 아까 구성한 이미지 데이터셋 dls를 적용하여 fine_tune 메소드를 통해서 미세 조정을 한다.
모델 활용(이미지 예측)
학습된 모델을 통해서 새로 들어오는 이미지가 고양이인지 강아지인지 예측한다.
uploader = widgets.FileUpload()
uploader
업로드 위젯을 불러오고, 위젯을 클릭하여 이미지를 업로드
img = PILImage.create(uploader.data[0])
is_cat,_,probs = learn4.predict(img)
print(f"Is this a cat?: {is_cat}.")
print(f"Probability it's a cat: {probs[1].item():.6f}")
Is this a cat?: True.
Probability it's a cat: 0.988204업로드한 이미지를 PILImage 클래스를 통해서 불러오고, predict 메소드를 통해서 예측한다.(하단 부분)
모델 학습 내용(내부)
첫번째 계층
-대각선, 수평선, 수직선 다양한 그라데이션 표현

두번째 계층
-모서리, 선, 원 등의 간단한 패턴 감지

세번째 계층
-바퀴,텍스트,꽃잎과 같은 고차원적인 의미의 요소

이미지 모델의 확장성
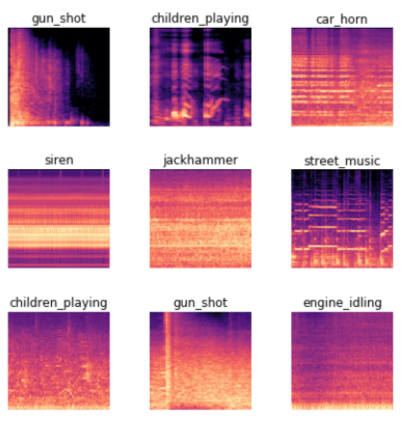
오디오 파일의 이미지화(스펙트럼 그래프)
마우스의 움직임 이미지화

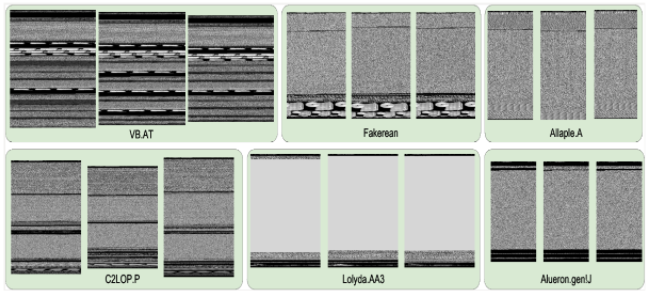
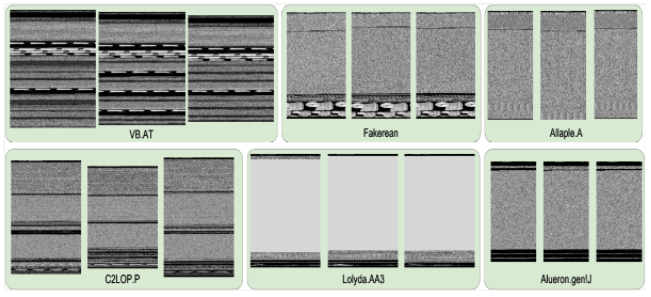
악성 소프트웨어 구성의 이미지화
핵심 요약
머신러닝은 프로그램을 직접 작성하는 것이 아닌 데이터에서 학습하여 프로그램을 만드는 것
딥러닝은 머신러닝의 한 분야로 여러 계층으로 구성된 신경망을 사용한다.
이미지를 분류하려면 라벨링이 된 데이터가 필요하다. 그것을 통해서 새로운 이미지가 무엇인지를 예측하는 모델이라는 프로그램을 만드는 것!
모델을 구성하는 과정은 구조/아키텍처를 고르는 일로 시작된다. 모델을 학습 시키는 과정은 해당 데이터에 잘 작동하게끔 만드는 특정 파라미터 값(가중치)를 찾는 과정이다.
모델의 예측능력은 예측의 성능을 측정하는 손실 함수를 정의해야 한다.
학습을 빠르게 하려면 다른 데이터를 사용해 학습된 적이 있는 사전 학습된 모델을 사용하여 우리의 데이터를 약간 더 학습시키는 미세 조정의 과정을 거치면 된다.
모델은 보지 못했던 앞으로의 데이터를 예측해야하므로 일반화가 잘 되도록 해야한다. 학습 내용에만 함몰되어 새로운 데이터를 잘 예측하지 못하는 것을 과적합이라고 한다.
과적합을 피하려면 데이터를 항상 학습용과 검증용 데이터셋으로 나누어야 한다.
평가지표는 모델이 검증용 데이터에서 얼마나 잘 예측을 하는지 사람이 이해하도록 표현하는 수단이다. 학습 과정에서 학습용 데이터셋의 모든 데이터가 한 번씩 모델에 입력된 시점을 하나의 에포크라고 한다.
