반려동물 품종 분류하기
from fastai.vision.all import *
path = untar_data(URLs.PETS)
Path.BASE_PATH = path반려동물 이미지 데이터 불러오기 그리고
불러온 경로를 기본경로로 설정하기
path.ls()
(#2) [Path('images'),Path('annotations')]이미지폴더와 어노테이션 폴더로 구성되어 있다.
어노테이션은 이미지내의 해당 동물이 위치한 좌표에 대한 정보이므로 무시한다.
(path/"images").ls()
(#7393) [Path('images/Persian_55.jpg'),Path('images/Sphynx_175.jpg'),Path('images/pug_162.jpg'),Path('images/Maine_Coon_47.jpg'),이미지 폴더 내부에는 이미지 폴더들이 담겨있는데, 품종, 밑줄, 숫자, 확장자로 이름이 구성되어 있다.
fname = (path/"images").ls()[0]
fname
Path('images/Persian_55.jpg')re.findall(r'(.+)_\d+.jpg$', fname.name)
['Persian']정규 표현식(regex)은 정규 표현식 언어로 작성된 특별한 규칙이다. 이 규칙을 활용하여 품종을 파일이름에서 분리한다.
pets = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = pets.dataloaders(path/"images")
fastai에서는 정규표현식을 이용한 레이블링 작업에 RegexLabeller 클래스를 제공한다.
이 클래스는 데이터블록API와 함께 사용할 수 있다.
사전크기 조절
item_tfms=Resize(460), batch_tfms=aug_transforms(size=224, min_scale=0.75))
이 코드 두 줄을 통해서 fastai의 데이터 증강 전략인 사전 크기 조절을 구현할 수 있다.
텐서로 포장된 이미지를 GPU에 전달하려면 이미지가 모두 같은 크기여야만 합니다.
아래 2가지 전략을 통해서 이 문제를 해결한다.

전략
1. 이미지 크기를 상대적으로 크게 만든다. 실제 원하는 이미지보다 훨씬 더 크게 만든다.
2. 이미지에 공통저으로 적용할 모든 증강 연상을 하나로 구성해서 마지막 단계에서 GPU가 수행한다.
방법
1. item_tfms - 전체 너비나 높이를 기준으로 잘라낸다. 이 단계를 통해 모든 이미지를 같은 크기로 만듭니다. 검증용 데이터셋은 항상 이미지의 정중앙 정사각형 영역이 선택된다.
2. batch_tfms - 임의의 부분을 잘라낸 후 증강하는 단계

왼쪽은 fastai 접근법, 우측은 확대, 보간, 회전, 재보간을 순차적으로 적용한 이미지
dls.show_batch(nrows=1, ncols=3)

show_batch를 통해서 데이터블록이 정상적으로 작동하는지를 점검
pets1 = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
pets1.summary(path/"images")
Collecting items from /root/.fastai/data/oxford-iiit-pet/images
Found 7390 items
2 datasets of sizes 5912,1478
Setting up Pipeline: PILBase.create
Setting up Pipeline: partial -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
Setting up after_item: Pipeline: ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline: IntToFloatTensor -- {'div': 255.0, 'div_mask': 1}
Building one batch
Applying item_tfms to the first sample:
Pipeline: ToTensor
starting from
(PILImage mode=RGB size=500x375, TensorCategory(24))
applying ToTensor gives
(TensorImage of size 3x375x500, TensorCategory(24))
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
Error! It's not possible to collate your items in a batch
Could not collate the 0-th members of your tuples because got the following shapes
torch.Size([3, 375, 500]),torch.Size([3, 332, 500]),torch.Size([3, 300, 225]),torch.Size([3, 500, 375])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-14-8c0a3d421ca2> in <module>()
4 splitter=RandomSplitter(seed=42),
5 get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
----> 6 pets1.summary(path/"images")
8 frames
/usr/local/lib/python3.7/dist-packages/torch/_tensor.py in __torch_function__(cls, func, types, args, kwargs)
1049
1050 with _C.DisableTorchFunction():
-> 1051 ret = func(*args, **kwargs)
1052 if func in get_default_nowrap_functions():
1053 return ret
RuntimeError: stack expects each tensor to be equal size, but got [3, 375, 500] at entry 0 and [3, 332, 500] at entry 1데이터 볼록 디버깅을 목적으로 summary 메소드를 사용하여 오류 확인
데이터가 모이고 분할된 방식, 파일명으로 샘플을 구성한 방식, 개별 데이터에 적용된 변형의 종류를 알 수 있다.
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2)
Downloading: "https://download.pytorch.org/models/resnet34-b627a593.pth" to /root/.cache/torch/hub/checkpoints/resnet34-b627a593.pth
epoch train_loss valid_loss error_rate time
0 1.550792 0.337589 0.106901 01:07
epoch train_loss valid_loss error_rate time
0 0.517231 0.322718 0.114344 01:09
1 0.331772 0.213772 0.071719 01:09데이터가 올바르다고 판단된 후에 간단한 모델로 학습
교차 엔트로피 손실
장점
1. 종속 변수에 범주가 둘 이상이더라도 작동
2. 더 빠르고 안정적인 학습 결과를 도출
활성 및 레이블 확인
x,y = dls.one_batch()
one_batch 메소드를 통해서 실체 배치 하나를 가져옴
y
TensorCategory([24, 13, 9, 26, 24, 17, 2, 13, 18, 7, 6, 22, 18, 3, 35, 35, 7, 15, 34, 13, 32, 11, 33, 9, 21, 6, 33, 30, 3, 28, 24, 9, 15, 3, 20, 6, 3, 1, 16, 10, 22, 14, 20, 27, 19, 26, 19, 4,
6, 11, 17, 26, 24, 27, 21, 32, 1, 28, 26, 24, 12, 25, 26, 36], device='cuda:0')종속변수 확인 (배치크기가 64이므로 텐서는 64개가 있음)
preds,ne = learn.get_preds(dl=[(x,y)])
preds[0]
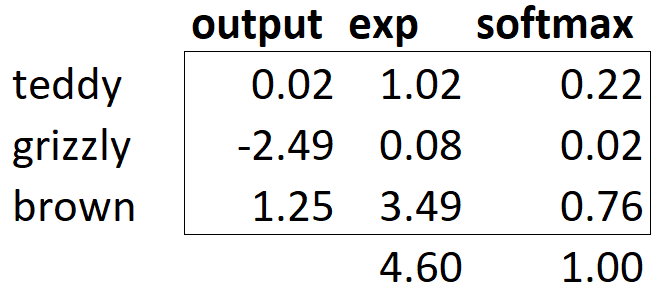
TensorBase([5.2220e-05, 1.1791e-04, 2.0585e-03, 4.4702e-02, 9.6774e-03, 1.0420e-04, 1.2896e-01, 4.1030e-01, 3.4030e-02, 1.3057e-03, 1.0432e-04, 5.4661e-04, 2.7459e-04, 1.5606e-04, 8.3041e-05, 9.7699e-05,
3.4688e-03, 1.1681e-03, 1.5074e-04, 1.3634e-05, 1.5038e-05, 3.3704e-04, 2.8363e-03, 1.6575e-03, 1.8968e-03, 3.2186e-04, 2.9397e-04, 1.0279e-02, 2.9162e-01, 2.7821e-04, 5.0822e-05, 3.2152e-02,
1.5057e-02, 1.9536e-04, 1.3734e-04, 1.3182e-03, 4.1836e-03])learn.get_preds 메소드로 예측값을 확인
len(preds[0]),preds[0].sum()
(37, TensorBase(1.))예측은 0~1 범위의 확률 37개로 구성된다. 이 값을 모두 더하면 1이 된다.
소프트맥스
분류 모델에서는 마지막 계층의 모든 활성값이 0~1이 되고, 모두 더하면 1이 되도록 하기 위해 소프트맥스를 사용한다.
이진 분류가아닌 더 많은 타깃이 필요하므로 범주당 활성 하나가 필요하다.
acts = torch.randn((6,2))*2
acts
tensor([[ 0.5630, 0.1123],
[ 1.0454, -0.4767],
[-0.0998, 1.0527],
[-0.0170, 1.4581],
[ 0.2663, 1.7280],
[-2.0313, -1.7775]])acts가 두 범주 중에 하나에 속하는 이미지 6장을 표현한다고 가정
acts.sigmoid()
tensor([[0.6372, 0.5281],
[0.7399, 0.3830],
[0.4751, 0.7413],
[0.4958, 0.8112],
[0.5662, 0.8492],
[0.1160, 0.1446]])시그모이드 함수 적용
(acts[:,0]-acts[:,1]).sigmoid()
tensor([0.6108, 0.8209, 0.2400, 0.1862, 0.1882, 0.4369])두 활성간의 차이에 대한 시그모이드 함수 적용
def softmax(x): return exp(x) / exp(x).sum(dim=1, keepdim=True)
소프트맥스 함수
sm_acts = torch.softmax(acts, dim=1)
sm_acts
tensor([[0.6108, 0.3892],
[0.8209, 0.1791],
[0.2400, 0.7600],
[0.1862, 0.8138],
[0.1882, 0.8118],
[0.4369, 0.5631]])소프트맥스 함수 적용 -> 두 활성(확률)의 합이 1
-> 시그모이드의 다중 범주 버전
로그 가능도(Log Likelihood)
def mnist_loss(inputs, targets):
inputs = inputs.sigmoid()
return torch.where(targets==1, 1-inputs, inputs).mean()
전에 MNIST에서 사용했던 손실 측정 방법(시그모이드)
이것이 소프트맥스에서는 어떻게 바뀌는지 확인해보자
targ = tensor([0,1,0,1,1,0])
sm_acts
tensor([[0.6108, 0.3892],
[0.8209, 0.1791],
[0.2400, 0.7600],
[0.1862, 0.8138],
[0.1882, 0.8118],
[0.4369, 0.5631]])소프트맥스 활성값
idx = range(6)
sm_acts[idx, targ]
tensor([0.6108, 0.1791, 0.2400, 0.8138, 0.8118, 0.4369])
3 7 targ idx loss
0.610808 0.389191 0 0 -0.610808
0.820854 0.179146 1 1 -0.179146
0.240036 0.759964 0 2 -0.240036
0.186166 0.813834 1 3 -0.813834
0.188212 0.811788 1 4 -0.811788
0.436876 0.563124 0 5 -0.436876
targ와 idx의 열의 값으로 행렬을 색인하면 나오는 값 -> 둘 이상의 열에서도 잘 작동한다.(targ에 0~9의 숫자가 할당된다고 상상) -> 파이토치의 nll_lossgkatnrk 하는일이 sm_acts[idx, targ]와 동일하다.
nll - 음의 로그 가능도 ( negative log likelihood )
-sm_acts[idx, targ]
tensor([-0.6108, -0.1791, -0.2400, -0.8138, -0.8118, -0.4369])F.nll_loss(sm_acts, targ, reduction='none')
tensor([-0.6108, -0.1791, -0.2400, -0.8138, -0.8118, -0.4369])nll_loss함수는 로그를 적용하지는 않는다.
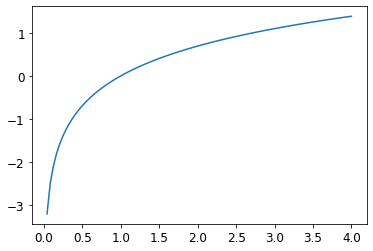
로그 취하기
plot_function(torch.log, min=0,max=4)
소프트맥스 다음에 로그 가능도를 적용하는 조합 - 교차 엔트로피 손실
loss_func = nn.CrossEntropyLoss()
파이토치에서는 nn.CrossEntropyLoss로 교차엔트로피를 사용할 수 있다. (실제로는 log_softmax 다음에 nll_loss 적용)
loss_func(acts, targ)
tensor(0.8137)클래스 형식
F.cross_entropy(acts, targ)
tensor(0.8137)네임스페이스에서 사용하는 일반 함수 형식
nn.CrossEntropyLoss(reduction='none')(acts, targ)
tensor([0.4930, 1.7196, 1.4270, 0.2060, 0.2085, 0.8281])기본적으로 적용되는 평균 손실이 아닌 각각의 손실 보여주는 옵션(reduction='none')
모델 해석
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)

오차행렬로 모델 확인 -> 품종이 너무 많아 행렬이 복잡함
interp.most_confused(min_val=5)
[('staffordshire_bull_terrier', 'american_pit_bull_terrier', 9),
('boxer', 'american_bulldog', 7),
('Egyptian_Mau', 'Bengal', 6),
('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5),
('miniature_pinscher', 'chihuahua', 5)]most_confused 메소드를 통해서 가장 올바르지 못한 예측만 보여준다.
모델 성능 향상
학습률 발견자
모델의 학습에서 올바른 학습률을 고르는 일은 굉장히 중요하다.
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1, base_lr=0.1)
epoch train_loss valid_loss error_rate time
0 2.595850 5.320202 0.435047 01:12
epoch train_loss valid_loss error_rate time
0 4.397612 3.253060 0.833559 01:14학습률이 너무 높아서 오히려 결과가 좋지 않음 -> 너무 많이 움직여서 최소 손실 지점을 비껴나갔음
learn = cnn_learner(dls, resnet34, metrics=error_rate)
lr_min = learn.lr_find()
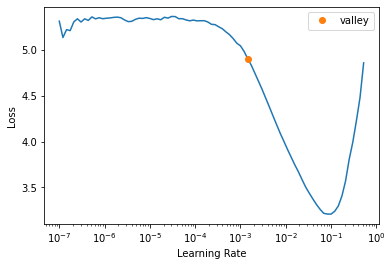
학습률 발견자(learning rate finder) - fastai에서 제공하는 학습률 찾는 도구. 매우 작은 학습률에서 시작해서 미니 배치 하나에 학습을 적용해보면서 학습률을 점점 늘리다가 손실이 나빠지기 직전까지 반복
- 최소 손실이 발생한 지점보다 한자리 낮은 학습률
- 손실이 명확히 감소하는 마지막 지점
lr_min
SuggestedLRs(valley=0.0014454397605732083)learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2, base_lr=3e-3)
epoch train_loss valid_loss error_rate time
0 1.305833 0.328975 0.104195 01:13
epoch train_loss valid_loss error_rate time
0 0.521001 0.343636 0.111637 01:15
1 0.313414 0.209282 0.064953 01:15학습률 도표에서 추천하는 3e-3 학습률로 학습 진행
동결 해제 및 전이 학습
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
epoch train_loss valid_loss error_rate time
0 1.119267 0.339131 0.108931 01:12
1 0.524958 0.281527 0.088633 01:11
2 0.339331 0.212908 0.071719 01:12fit_one_cycle은 낮은 학습률로 시작하여 첫 번째 부분까지 점진적으로 학습률을 증가시키고 두 번째 부분부터 점진적으로 감소시킨다.
learn.unfreeze()
learn.lr_find()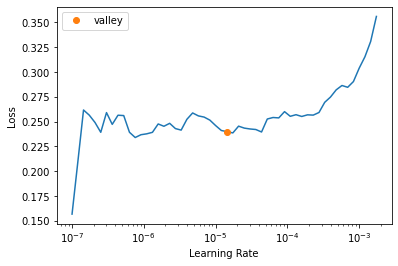
모델 동결을 해제한다.
그리고 다시 학습률을 찾는다.(학습할 계층이 많아졌기때문에)
learn.fit_one_cycle(6, lr_max=1e-5)
epoch train_loss valid_loss error_rate time
0 0.276745 0.211278 0.069012 01:13
1 0.252707 0.207137 0.064276 01:14
2 0.219428 0.196273 0.060217 01:14
3 0.219673 0.201343 0.060893 01:13
4 0.193119 0.195810 0.059540 01:14
5 0.194109 0.196321 0.059540 01:15그래프상 적당한 학습률도 다시 학습을 시킨다.
차별적 학습률(Discriminative Learning Rates)
신경망 초기 계층에는 작은 학습률을 사용하고, 후기 계층에는 높은 학습률을 사용한다는 단순한 기법
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(4, 1e-3)
learn.unfreeze()
learn.fit_one_cycle(15, lr_max=slice(1e-6,1e-3))
epoch train_loss valid_loss error_rate time
0 1.947677 0.365324 0.120433 01:08
1 0.739147 0.256330 0.075101 01:08
2 0.443512 0.210775 0.068336 01:07
3 0.337699 0.210543 0.066306 01:08
epoch train_loss valid_loss error_rate time
0 0.309220 0.210335 0.064953 01:10
1 0.290271 0.230975 0.078484 01:09
2 0.283832 0.249661 0.081191 01:09
3 0.239838 0.221256 0.071719 01:09
4 0.213812 0.235603 0.072395 01:09
5 0.163575 0.248850 0.066982 01:09
6 0.131565 0.228116 0.064953 01:09
7 0.104759 0.234551 0.069689 01:09
8 0.081144 0.233172 0.064953 01:09
9 0.072472 0.232980 0.064953 01:10
10 0.066499 0.245994 0.069012 01:09
11 0.050979 0.224140 0.060893 01:09
12 0.045743 0.217748 0.060893 01:09
13 0.040883 0.221827 0.058863 01:09
14 0.036595 0.221182 0.058863 01:10초기계층은 1e-6으로 시작하고, 다른 계층은 1e-3까지 일정하게 증가하여 설정하여 학습
learn.recorder.plot_loss()
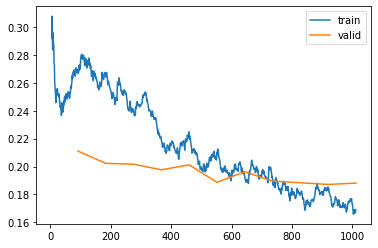
학습용 데이터셋 손실은 계속햇 나아지지만, 검증용 데이터셋은 개선이 매우 더디고, 때로는 나빠지는 모습을 보인다.
에포크 회수 정하기(the Number of Epochs)
에포크 회수에 주로 제약받는 부분은 학습 가능한 시간이다.
보통은 에포크마다 모델을 저장하고 저장된 모델 중 정확도가 가장 높은 모델을 선택한다.(조기 종료)
하지만, 최고의 결과를 찾는 학습률에 도달하기전에 끝날수도 있다.
차라리 더 많은 파라미터 학습에 시간을 투자하는 즉 깊은 구조의 모델을 사용하는게 결과가 좋을 수 있다.
깊은 구조의 모델
심층적인 구조의 모델은 더 많은 GPU메모리를 요구하므로 메모리 부족 오류(Cuda runtime error: out of memory error) 를 피하려면 배치 크기를 줄여줘야만 한다. 이는 보유한 GPU의 용량을 초과하는 많은 데이터를 한 번에 학습시킬 때 발생하는데, 이를 위해서는 더 작은 배치크기를 이용하거나, 주피터 노트북을 재 시작해야 한다.
from fastai.callback.fp16 import *
learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16()
learn.fine_tune(8, freeze_epochs=3)
epoch train_loss valid_loss error_rate time
0 1.261725 0.277990 0.095399 01:10
1 0.563309 0.292472 0.103518 01:11
2 0.426865 0.255019 0.081191 01:11
epoch train_loss valid_loss error_rate time
0 0.255053 0.219606 0.068336 01:14
1 0.285945 0.270363 0.081191 01:14
2 0.290364 0.308230 0.083221 01:14
3 0.206793 0.262537 0.074425 01:14
4 0.137228 0.212967 0.064276 01:13
5 0.083522 0.190605 0.047361 01:14
6 0.052282 0.191465 0.052097 01:14
7 0.043122 0.181003 0.050744 01:14혼합 정밀도 학습(mixed-precision training) - 학습 시 가능한 한 덜 정밀한 숫자를 사용하는 기법
fasiai에서는 이를 위해서는 to_fp16 메소드를 사용한다.
결과만 놓고 보면 더 깊은 모델이 항상 더 좋다고 보기는 어렵다. 모델의 크기를 키우기 전 작은 모델부터 시작해보는게 좋다.
