2장은 딥러닝 프로젝트를 간단하게 모델 처음부터 제품이라는 끝까지 실습해보는 장이다.
아무것도 잘 모르고 헷갈리는데 어떻게 처음부터 끝까지 실습을해?
라고 생각할수 있는데 그냥 해보는 것이다.
이 책에서 저자는 전체적인 큰 그림을 보는 것, 작은 단위라도 처음부터 끝까지 경험하는 것들을 굉장히 강조한다.
나는 여러가지 프로젝트(딥러닝이 아닌)을 겪으면서 이러한 접근법이 굉장히 도움이 되거나 아쉬운 부분이었고, 그래서 이 책을 2~3번씩 보고 활용하려고 하는거 같다.
딥러닝 프로젝트 실습하기
-딥러닝은 뭐든 가능한 마법은 아니다.
-그렇다고 간단한 딥러닝으로 해결할 수 있는 문제는 극히 일부이다.
열린 마음으로 다가가는 것이 가장 중요하다.
프로젝트 시작하기
-딥러닝 프로젝트의 시작은 데이터로 부터
-완벽한 데이터셋, 그럴듯한 프로젝트를 발굴하는데 시간을 낭비하기보다는 일단 시작할 수 있는 데이터로 시작
-일단 시작한 뒤 지속적으로 개선해나가는 뱡식으로 진행
-프로젝트를 처음부터 끝까지 반복하기
-단순 데이터셋 조정, 미세 조정, 디자인 꾸미기같은 부분에 수개월을 허비하지 말자!
-모든 단계를 적당한 시간 내에 하나씩 수행하여 처음부터 마지막 단계까지 완전히 돌아보기
-> 프로젝트를 처음부터 끝까지 한 번 반복하면 가장 까다로운 부분, 최종 결과물에 가장 영향력을 미치는 부분을 빠르게 파악할 수 있다.
앞으로 나오는 코드의 내용을 조금씩 바꾸며 작은 단위의 실험을 많이 해보고, 동시에 여러분만의 프로젝트를 조금씩 발굴해나가기 바랍니다. 도구와 기법에 대한 지식뿐만 아니라 경험도 함께 쌓아가는 연습이 필요합니다.
실제 작동하는 프로토타입까지 만들기 때문에 아이디어의 가능성을 동료 혹은 기관을 설득하는데도 사용할 수 있다.
가장 시작하기 쉬운 지점은 현재 몸담은 분야입니다. 관련 데이터를 이미 축적했을 가능성이 높아 시작하기 수월합니다.
가끔은 외부에서 창의적인 아이디어를 얻어야 한다. (캐글과 같은) 또한 정확하게 목적에 부합하는 데이터가 없을때는 유사한 문제에 사용된 다른 데이터를 살펴보면 도움이 될 수 있다.
딥러닝 입문자라면 아직 딥러닝이 적용되지 않은 분야로 뛰어들지 않는게 좋다. 시작하자마자 모델이 작동하지 않으면 그것이 입문자의 실수인지, 딥러닝의 아직까지의 한계인지를 알 수 없기 때문이다.
딥러닝의 현 상황 (what can ai do now)
컴퓨터 영상 처리
물체 인식(object recognition) - 이미지 내 물체를 인식하는 작업
물체 탐지(object detection) - 이미지 내 물체의 위치 식별 및 이름과 위치 표시
-> 세그먼테이션(segmentation)
영역 밖 데이터 검증(out of domain) - 학습에서 접하지 않은 예기치 않은 종류의 이미지(데이터)가 등장했을때 해당 이미지(데이터)를 인식하도록 하는 방법
데이터 증강(data augmentation) - 탐지 모델 구축에 필요한 이미지 레이블을 쉽고 빠르게 해주고, 정확도를 높여주는 기법
텍스트(자연어 처리)
-문서 분류
-텍스트 생성(글 쓰기)
-텍스트 번역, 요약
텍스트와 이미지의 결합
-텍스트와 이미지를 하나의 모델로 결합하는 방식
ex) 텍스트와 이미지를 인풋으로 받아 정확도를 올림
ex) 동영상을 입력받아 영어 자막을 출력하는 모델
테이블 데이터
-인기있는 테이블 데이터 모델링 도구인 랜덤포레스트, GBM에 비해 극적인 개선은 어려움
-하지만 포함할 수 있는 입력의 종류를 크게 늘려준다.(자연어와 같은)
추천 시스템
추천 시스템은 특별한 유형의 테이블 데이터
카디널리티가 높은 범주형 범수를 잘처리하는 딥러닝 모델은 추천 시스템에 적합함
번외)
-단백질 사슬은 개별 토큰으로 일련의 수선로 구성되어 있음
-> NLP 딥러닝과 비슷
-소리는 스펙트로그램으로 표현하면 이미지로 표현 가능'
-> 이미지 영상 처리와 비슷
데이터 수집
-여러가지 프로젝트에 필요한 데이터는 대부분 온라인에서 얻을 수 있다.
-빙 이미지 검색을 활용해서 수집해보겠다.
-그러려면 우선 마이크로소프트 빙 이미지 검색 서비스에 가입해서 KEY를 발급 받아야 한다.
key = os.environ.get('AZURE_SEARCH_KEY', 'XXX')키를 설정했다면 search_images_bing 함수를 사용할 수 있다.

간단하게 함수를 사용해보겠다.
results = search_images_bing(key, 'grizzly bear')
ims = results.attrgot('contentUrl')
len(ims)
150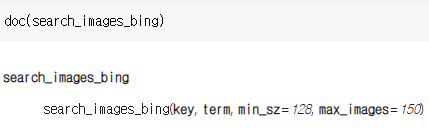
다운로드한 이미지 하나를 살펴보겠다.
dest = 'images/grizzly.jpg'
download_url(ims[0], dest)
im = Image.open(dest)
im.to_thumb(128,128)
다음은 검색어가 이름인 폴더에 각각 저장하도록 사진을 다운로드 한다.
if not path.exists():
path.mkdir()
for o in bear_types:
dest = (path/o)
dest.mkdir(exist_ok=True)
results = search_images_bing(key, f'{o} bear')
download_images(dest, urls=results.attrgot('contentUrl'))fns = get_image_files(path)
fns
(#438) [Path('bears/black/00000112.jpg'),Path('bears/black/00000066.jpg'),Path('bears/black/00000099.jpg'),Path('bears/black/00000044.jpg')다운로드 받은 파일의 오류 확인
failed = verify_images(fns)
failed
(#1) [Path('bears/teddy/00000065.png')]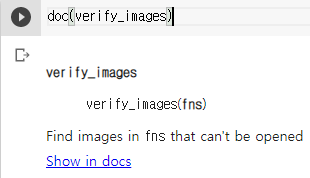
오류가 있는 파일 삭제
failed.map(Path.unlink);주피터 노트북에서 도움을 얻는 법
?verify_images-함수의 원형과 짧은 설명이 화면 하단에 나타난다.
??verify_images-함수의 원형과 짧은 설명, 구현 코드가 화면 하단에 나타난다.
doc(verify_images)-함수의 원형과 짧은 설명, 구현 코드가 노트북 코드 하단에 나타난다.
'Tab' -> 자동 완성 목록
'Shitf+Tab' -> 함수의 원형과 설명이 담긴 팝업창
데이터 구조화(DataLoaders)
class DataLoaders(GetAttr):
def __init__(self, *loaders): self.loaders = loaders
def __getitem__(self, i): return self.loaders[i]
train,valid = add_props(lambda i,self: self[i])DataLoaders
-fastai가 제공하는 여러 DataLoader를 저장하는 클래스
-개수 제한없이 DataLoader를 저장할 수 있지만, 학습용과 검증용으로 보통 두 개를 저장한다.
DataLoader를 만드려면 4가지 요소가 필요하다
1. 데이터 유형
2. 데이터 경로(목록을 가져오는 방법)
3. 데이터 레이블 지정 방법
4. 검증용 데이터셋 만드는 방법
경우에 따라 위에 상황에 맞는 메소드가 없을 수 있고, 그런 경우에 유용하게 사용할 수 있는 것이 데이터블록(datablock) 시스템이다.
bears = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))blocks=(ImageBlock, CategoryBlock),
-독립변수와 종속변수의 데이터 유형을 튜플(tuple)로 지정하는 부분
get_items=get_image_files,
-파일 경로 목록을 가져오는 방법(경로에 포함된 모든 이미지 목록 반환)
splitter=RandomSplitter(valid_pct=0.2, seed=42)
-데이터의 임의성을 고정하기위해 seed 고정
-데이터의 20%를 검증용 데이터셋으로 설정
get_y=parent_label
-parent_label 함수는 파일이 저장된 폴더명을 가져온다. 우리는 각이미지 곰의 유형을 같은 이름의 폴더로 다운로드했으니 폴더 이름이 레이블이 된다.
item_tfms=Resize(128)
-여러 이미지를 한번에 입력(배치)하기 떄문에 이미지의 크기를 똑같이 맞추는 변형
dls = bears.dataloaders(path)앞서만든 DataBlock은 DataLoader를 생성하는 템플릿과 같다. 실제 경로(path)를 만나 실제 객체가 된다.
dls.valid.show_batch(max_n=4, nrows=1)
show_batch 메소드를 통해서 하나의 배치의 요소 중 일부를 화면에 출력해볼 수 있다.
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Squish))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)
bears = bears.new(item_tfms=Resize(128, ResizeMethod.Pad, pad_mode='zeros'))
dls = bears.dataloaders(path)
dls.valid.show_batch(max_n=4, nrows=1)
아까 이미지의 크기를 통일하는 과정에서 이미지를 자르게되는데 이 과정에서 이미지의 중요한 세부사항이 유실될 수 있다. 따라서 찌끄러뜨리거나 혹은 빈 공간을 검은색(0)으로 채우는 방법이다.
데이터 증강
데이터 증강은 입력 데이터에 임의로 변형을 가해서 새로운 데이터를 생성하는 기법이다.
ex) 회전, 뒤집기, 원근 뒤틀기, 명도 변경, 채도 변경...
이 목록은 aug_transform 함수를 통해서 제공된다.
mult=2는 기본값보다 두 배로 데이터 증강을 조정한다는 설정이다.
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True) ![]
![]
모델 훈련과 모델을 이용한 데이터 정리
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(4)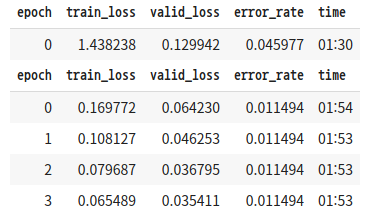
learner 객체를 만들고 미세 조정을 4번 적용
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()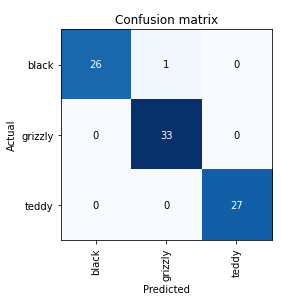
모델의 오류 파악 -> 오차 행렬을 통해서
interp.plot_top_losses(3, nrows=1)
plot_top_losses 메소드를 통해서 가장 손실이 높은 이미지를 출력
-> 딱봐도 레이블(라벨링)이 잘못되어 있음을 파악
cleaner = ImageClassifierCleaner(learn)
cleaner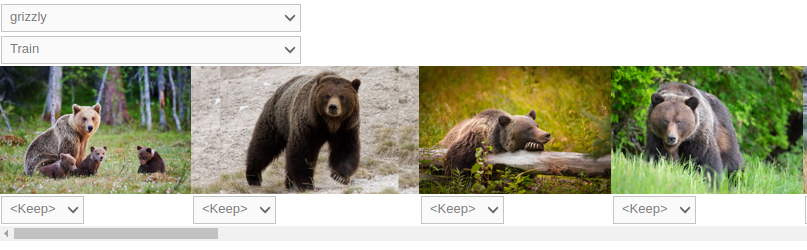
ImageClassifierCleaner - fastai에서 제공하는 간단하게 데이터를 정리할 수 있는 노트북에서의 GUI 도구
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
for idx,cat in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/cat)실제로는 위의 코드를 구동해야 위에 적용사항이 적용됨
모델을 온라인 어플리케이션으로 전환
모델 저장하고 불러오기
모델을 실제 환경에서 사용하려면 파일 형태로 저장하고 필요할때 불러와서 사용해야 된다.
모델은 모델의 구조와 학습된 파라미터로 구성된다.
learn.export()export메소드를 통해서 위에 2가지 핵심내용을 pkl 파일로 저장할 수 있다.
learn_inf = load_learner(path/'export.pkl')load_learner 함수를 통해서 불러온 pkl파일을 바탕으로 추론(예측)용 객체를 생성한다.
learn_inf.predict('images/grizzly.jpg')
('grizzly', TensorBase(1), TensorBase([4.3743e-04, 9.9956e-01, 4.5010e-07]))predict 메소드를 통해서 새로 들어온 데이터를 예측한다. predict는 3가지를 반환하는데, 예측된 범주, 범주의 색인 번호, 예측 확률이다.
모델로 어플리케이션 만들기
- IPython 위젯
- Voila
2가지 도구를 사용해서 쉽고 빠르게 어플리케이션으로 만든다.
IPython 위젯은 자바스크립트와 파이썬을 묶어 웹 브라우저상에서 파이썬을 사용할 수 있도록 만들어주는 GUI 구성 요소이다.
Voila는 사용자가 주피터 노트북을 사용하지 않더라도 노트북 어플리케이션을 이용하도록 변환해주는 도구이다.
btn_upload = widgets.FileUpload()
btn_upload
먼저 이미지 파일을 업로드하는 위젯이다.
img = PILImage.create(btn_upload.data[-1])
위젯으로 업로드된 이미지를 가져온다.
pred,pred_idx,probs = learn_inf.predict(img)predict 메소드를 이용해서 해당 이미지에 대한 예측을 수행한다.
lbl_pred = widgets.Label()
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
lbl_pred
Prediction: black; Probability: 1.0000예측 결과를 화면에 출력한다.
btn_run = widgets.Button(description='Classify')
btn_run이미지 분류를 요청하는 버튼 생성
def on_click_classify(change):
img = PILImage.create(btn_upload.data[-1])
out_pl.clear_output()
with out_pl: display(img.to_thumb(128,128))
pred,pred_idx,probs = learn_inf.predict(img)
lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'
btn_run.on_click(on_click_classify)버튼을 눌렀을때 분류가 시작될 수 있도롟 클릭 이벤트 헨들러 설정
VBox([widgets.Label('Select your bear!'),
btn_upload, btn_run, out_pl, lbl_pred])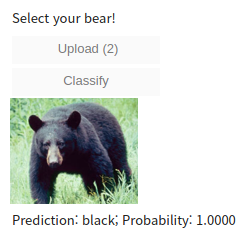
VBox를 통해서 지금까지 만든 위젯을 나열하여 GUI 완성
노트북을 실제 어플리케이션으로 바꾸기
!pip install voila
!jupyter serverextension enable --sys-prefix voila Voila를 설치하고, 주피터 노트북에 확장 프로그램으로 등록한다.
Voila를 통해서 주피터 노트북 서버처럼 주피터 노트북을 실행한다.
어플리케이션 배포하기
모델을 배포하는 상황에서는 데이터가 하나하나 들어오면서 각각의 데이터에 대해서 예측을 하기 때문에 GPU 필요가 거의 없다.
Binder라는 서비스를 통해서 노트북을 간단하게 어플리케이션으로 배포할 수 있다.
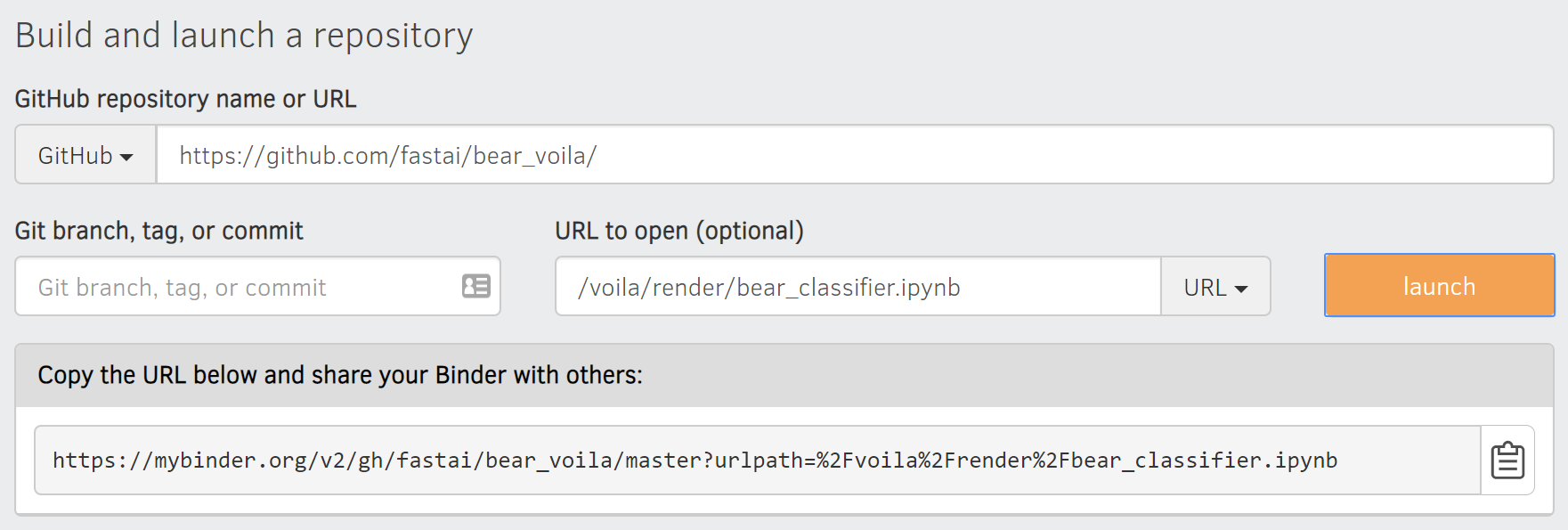
- 깃허브에 주피터 노트북 저장
- Github URL에 저장소 URL 입력
- URL TO OPEN에 URL로 오른쪽 메뉴를 변경하고, /voila/render/노트북이름.ipynb를 입력한다.
- 우측 하단의 url을 저장하고 launch 버튼 클릭
우측 하단의 url을 통해서 어플리케이션 형태로 배포된 노트북을 이용가능하다.
딥러닝 재앙을 피하는 방법
실제 구동 상황에서는 코딩보다 훨씬 어렵고 복잡한 문제가 생길 수 있다.
영역 밖 데이터의 문제
ex) 입력데이터의 종류가 바뀜, 이미지가 야간에 촬영됨, 이미지 해상도가 낮음....
도메인 시프트
ex)시간이 흘러서 데이터의 내용이 변화해서 예전의 데이터로 학습한 내용이 맞지 않게 됨
일반적인 배포 과정 접근법
- 수동적과정
- 모델을 병렬로 순차적으로 실행
- 예측 결과를 사람이 수동으로 검사
- 제한된 범위의 배포
- 사람의 신중한 감독
- 시간과 지리적으로 제약을 두어 관찰
- 점진적 확장
- 좋은 보고 체계 확립
- 잘못될 수 있는 부분에 대한 대책 마련
기술 글쓰기(블로그)의 장점
- 이력서와 비슷하지만 훨씬 낫다
- 배움에 도움을 준다. 무언가를 이해했는지 확인하려면 남에게 설명할 수 있는지 확인하면 된다.
- 새로운 사람을 만날 기회가 생긴다.
- 시간을 절약할 수 있다. 똑같은 내용을 여러번 설명할 필요가 없기 때문
또한 지금 상황에서 한 단계 뒤처진 사람을 돕기 가장 좋은 위치라고 볼 수있다. 전문가들은 초보자,중급자일 때의 느낌을 잊어버렸기 때문에 오히려 우리가 훨씬 설명하는데 있어서 유리하다.
