세그먼테이션(segmentation)
path = untar_data(URLs.CAMVID_TINY)
dls = SegmentationDataLoaders.from_label_func(
path, bs=8, fnames = get_image_files(path/"images"),
label_func = lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
codes = np.loadtxt(path/'codes.txt', dtype=str)
)
learn = unet_learner(dls, resnet50)
learn.fine_tune(8)(코드에 대한 자세한 설명은 바로 전 게시글을 참고해주세요)
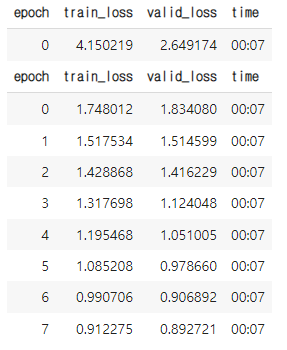
learn.show_results(max_n=3, figsize=(7,10))
텍스트 (자연어 처리 NLP)
-텍스트 생성, 언어 번역, 댓글 분석, 문장 성분 분석...
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test', bs=16)
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(2, 1e-2)영화 리뷰(텍스트)에 실린 감정을 분류하는 모델


doc 함수
ex) doc(text_classifier_learner)
-fastai 메서드에 대해 궁금한 점이 있으면, doc함수에 전달하면 간단한 한 줄 설명을 포함한 창이 나타난다.
테이블형 데이터
from fastai.tabular.all import *
path = untar_data(URLs.ADULT_SAMPLE)
dls = TabularDataLoaders.from_csv(path/'adult.csv', path=path, y_names="salary",
cat_names = ['workclass', 'education', 'marital-status', 'occupation',
'relationship', 'race'],
cont_names = ['age', 'fnlwgt', 'education-num'],
procs = [Categorify, FillMissing, Normalize])
learn = tabular_learner(dls, metrics=accuracy)-범주형열과 연속형열이 무엇인지 알려주어야 한다.
추천 시스템
-좋아할만한 영화를 예측하는 모델 학습
from fastai.collab import *
path = untar_data(URLs.ML_SAMPLE)
dls = CollabDataLoaders.from_csv(path/'ratings.csv')
learn = collab_learner(dls, y_range=(0.5,5.5))
learn.fine_tune(10)
learn.show_results()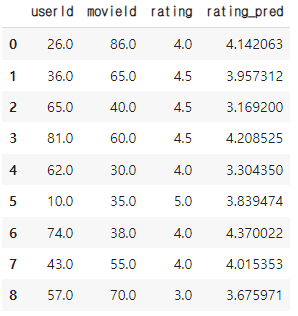

후회없이