[PyTorch] Distributed Sampler in evaluation
Multi-GPU 환경에서 PyTorch 학습을 진행할 때 DP(Data Parallel) 혹은 DDP(Distributed Data Parallel)을 사용하게 된다.
파이토치의 공식 DDP 문서에 따르면 Single Machine에서 Multi-GPU 환경으로 학습을 진행할 때도 DP 대신 DDP를 사용하는 것을 권장하고 있다.
일단, DDP를 사용하는 것이 DP를 사용하는 것과 비교해서 월등히 빠르다는 점. 그리고 DDP는 Data Parallel뿐만 아니라 Model Parallel도 적용할 수 있다는 점을 큰 장점으로 소개하고 있다.
DDP는 DP와는 다르게 torch.distributed 환경에서 멀티 프로세스로 동작한다. 따라서 Single Machine 환경에서도 몇 번 프로세스에서 몇 번째 GPU를 쓸 건지 코드 내에서 명시적으로 지정하는 부분이 존재한다. torch.distributed를 사용한 예시 코드는 다음과 같다.
import torch.distributed as dist
import torch.multiprocessing as mp
import torch
def main_worker(rank, world_size):
# mp.spawn의 결과로 실행된 sub process의 순서(rank)가 함수의 첫 번째 인자로 전달됨
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=world_size, rank=rank)
dist.barrier() # 다른 프로세스가 이전 코드 실행을 다 완료할때까지 대기
tensor = torch.Tensor([rank]).to(rank) # rank 번째 GPU에 텐서 생성
print(tensor)
if __name__ == "__main__":
world_size = 4 # 총 노드 개수
mp.spawn(main_worker, args = (world_size,),nprocs=world_size)
#world size만큼의 sub process가 생성되고, main_worker 함수가 각각의 프로세스에서 독립적으로 실행된다. python -m torch.distributed.run (혹은 torchrun) 으로 스크립트를 실행하고자 할 경우 다음과 같다.
python -m torch.distributed.run --nnodes 1 --nproc_per_node 4 script.py
: 한개의 노드(머신)에서 (--nnodes 1) 노드당 4개의 프로세스를 사용하여(--nproc_per_node 4) 스크립트 실행
def main_worker(rank, world_size):
dist.init_process_group(backend='nccl', init_method=None, world_size=world_size, rank=rank)
dist.barrier() # 다른 프로세스가 이전 코드 실행을 다 완료할때까지 대기
tensor = torch.Tensor([rank]).to(rank) # rank 번째 GPU에 텐서 생성
print(tensor)
if __name__ == "__main__":
local_rank = int(os.environ["LOCAL_RANK"]) # 현재 실행되고 있는 프로세스의 순서(rank)가 환경변수 LOCAL_RANK로 전달된다
world_size = int(os.environ["WORLD_SIZE"])
# Single Node에서 torchrun(torch.distributed.run) 실행시 nproc_per_node로 전달한 인자가 환경변수 WORLD_SIZE로 전달된다
main_worker(local_rank, world_size)output:
tensor([1.], device='cuda:1')
tensor([0.], device='cuda:0')
tensor([2.], device='cuda:2')
tensor([3.], device='cuda:3')DDP를 사용해서 본격적으로 학습을 하고자 할 때 기존 학습 코드가 위 예시의 main_worker 함수 내부에 존재한다.
이 때 위와 같은 분산 환경 세팅 외에 다음과 같은 부분이 기존 학습 코드에서 달라질 것이다.
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
...
model = MyModel()
model = model.to(rank)
model = DistributedDataParallel(module=model, device_ids=[rank])
...
...
sample_dataset = ...
dist_sampler = DistributedSampler(dataset=sample_dataset, shuffle=True)
data_loader = DataLoader(dataset=sample_dataset,
batch_size=int(BATCH_SIZE / WORLD_SIZE),
shuffle=False,
num_workers=int(NUM_WORKERS / WORLD_SIZE),
sampler=dist_sampler,
pin_memory=True)위와 같이 분산 환경에서는 DataLoader에 DistributedSampler를 sampler로 사용해야 학습 데이터가 각각의 프로세스에 균일하게 배분된다. DistributedSampler를 사용하지 않고Dataloader를 단순하게 정의하면 모든 프로세스에서 병렬적으로 모든 데이터가 처리되어 Data Parallel하게 학습이 이루어지지 않을 것이다.
(혹시 별도의 샘플러를 함께 쓰고자 할 때는 catalyst에서 제공하는 이 Wrapper을 사용하면 될 것 같다)
사실 이 포스트에서 정리하고자 하는 것은 따로 있다.
인터넷상에 많이 나오는 DDP 예제나, yolov5와 같은 오픈소스 모델을 보면, DDP를 사용할 때 validation phase에서는 (보통 rank == 0 같은 조건문을 붙여서) multi-gpu를 활용하지 않고 단 한 프로세스에서만 validation이 실행되도록 처리하는 경우가 많다.
위에서 언급한 대로 multi GPU를 활용해 Data Parallel하게 validation 을 진행하고자 한다면 한다면 각 프로세스에서 validation loop가 종료된 후, 결과를 한 곳에 모아주는 작업이 추가적으로 필요하다. 이를 위해 Validation Dataloader에서 DistributedSampler를 사용했다고 가정했을 경우, 코드는 다음과 같을 것이다.
#주의 : 이렇게 코드를 짰을 경우 생길 수 있는 문제점이 곧 언급될 것이다.
import torch.distributed as dist
...
local_result = ...
# validation의 결과로써 나온 result(score가 될 수도 있고, prediction 결과가 될 수도 있고..)가
# local result라는 텐서에 저장되어 있다고 가정하자.
global_result = [torch.zeros_like(local_result) for _ in range(WORLD_SIZE)]
global_result = dist.all_gather(local_result, WORLD_SIZE, RANK)
# 각 프로세스의 local_result 텐서를 global_result라는 리스트에 전부 모을 것이다.
global_result_tensor = torch.cat(global_result)
# global_result는 텐서 리스트이기 때문에 torch.cat으로 하나의 텐서로 만든다.
# 이제 global_result_tensor로 원하는 통계를 얻어내고자 할 것이다.
# 통계 내는 부분은 프로세스 하나에서 하면 족하다
if RANK == 0:
something(global_result_tensor)
...
all_gather는 다음 그림과 같이 모든 프로세스에 있는 텐서를 모든 다른 프로세스의 텐서 리스트에 담는 역할을 한다.
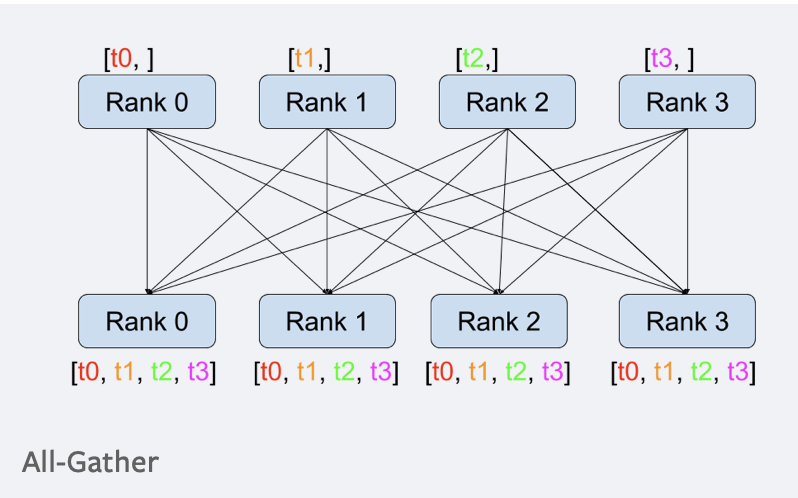
all_gather가 어떻게 작동하는지 코드와 그 결과를 보자.
import torch.distributed as dist
import torch.multiprocessing as mp
import torch
def f(rank):
dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:23456', world_size=4, rank=rank)
t = torch.tensor([rank]).to(rank)
gather_t = [torch.ones_like(t) for _ in range(dist.get_world_size())]
dist.all_gather(gather_t, t)
print("RANK : {} Local Tensor : {} Global Tensor : {}".format(rank, t, gather_t))
if __name__ == '__main__':
mp.spawn(f, nprocs=4, args=())output
RANK : 0 Local Tensor : tensor([0], device='cuda:0') Global Tensor : [tensor([0], device='cuda:0'), tensor([1], device='cuda:0'), tensor([2], device='cuda:0'), tensor([3], device='cuda:0')]
RANK : 3 Local Tensor : tensor([3], device='cuda:3') Global Tensor : [tensor([0], device='cuda:3'), tensor([1], device='cuda:3'), tensor([2], device='cuda:3'), tensor([3], device='cuda:3')]
RANK : 2 Local Tensor : tensor([2], device='cuda:2') Global Tensor : [tensor([0], device='cuda:2'), tensor([1], device='cuda:2'), tensor([2], device='cuda:2'), tensor([3], device='cuda:2')]
RANK : 1 Local Tensor : tensor([1], device='cuda:1') Global Tensor : [tensor([0], device='cuda:1'), tensor([1], device='cuda:1'), tensor([2], device='cuda:1'), tensor([3], device='cuda:1')]Output에서 확인 가능하듯이 all_gather로 얻어진 결과물은 Tensor 자료형의 리스트이다.
이를 하나의 텐서로 만들기 위해 torch.cat()을 사용하면
torch.cat(global_tensor)
>> tensor([0,1,2,3], device='cuda:0')와 같은 결과가 나올 것이다.
왜 벨로그 마크다운은 밑줄이 지원되지 않는 것일까?
이걸로 과연 끝일까?
하나의 프로세스에서만 validation을 진행했을 경우와 위와 같은 방법으로 multi GPU를 사용하여 validation 을 진행했을 경우 validation dataset 길이는 다음과 같다. (nproc = 8)
하나의 프로세스에서만 validation을 진행했을 경우:

Multi Processing을 사용했을 경우

validation dataset 길이가 다르다
이는 DistributedSampler가 데이터셋 길이가 프로세스 개수에 딱 나누어 떨어지도록 (모자란 갯수만큼) 데이터를 추가(정확히 말하면 샘플링)하기 때문이다.
위와 같은 경우에서는 6994개의 데이터가 프로세스 개수인 8로 나누어 떨어지지 않기 때문에 6개의 중복된 데이터가 추가로 생겼다.
구글링을 하던 중, 어떤 분이 기존 DistributedSampler 의 코드를 살짝 손본 Evaluation용 Distributed Sampler 를 공개하신 것을 찾을 수 있었다. 기존 DistributedSampler에서 extra data indices를 추가하는 부분이 빠져 있다.
코드 주석에서 언급하신것과 마찬가지로, Training Phase에서 이 샘플러를 사용하면 문제가 발생할 수 있다.

이 샘플러를 사용했을 경우 multi-process로 validation을 진행해도 데이터 길이가 원본과 같음을 확인할 수 있다.
하지만 각 프로세스에서 처리한 데이터의 길이가 다르기 때문에 단순히 위 예시처럼 dist.all_gather를 사용하면 에러가 발생할 수 있다.
다음 스택오버플로우 게시글에서 이와 관련된 해결책을 찾을 수 있었다.
https://stackoverflow.com/questions/71433507/pytorch-python-distributed-multiprocessing-gather-concatenate-tensor-arrays-of
- DDP와 DP의 구체적인 작동 방식에 대한 차이는 더 공부해서 정리해야 할 것 같다.
