Knowledge Neurons in Pretrained Transformers
ACL 2022
분야 및 배경지식
- Transformer
- 오늘날 가장 인기있고 효과적인 NLP 아키텍처
- 인코더의 경우 L 개의 동일한 block이 쌓인 형태이며, 각각의 블럭은 self-attention module과 feed-forward network로 구성되어 있음
- Factual Knowledge
- 대량의 데이터로 사전학습된 Transforemr 모델은 finetuning 없이도 사실적 지식을 기억해낼 수 있는 강력한 능력을 가지고 있음
- attribution method
- 딥러닝 모델의 black box를 이해하기 위해, 모델의 output을 다양한 측정방식을 사용하여 input feature에 귀인시키고자 하는 방법
문제
- 기존 연구는 모델이 가진 지식의 정확성을 측정하는 데에 집중
- 어떻게 factual knowledge가 저장되어 있는지에 대한 연구는 미비
해결책
Knowledge attribution method to identify knowledge neurons that express the fact
: 사실관계를 표현하는 지식뉴런을 찾아낼 수 있는 지식 귀인 방법
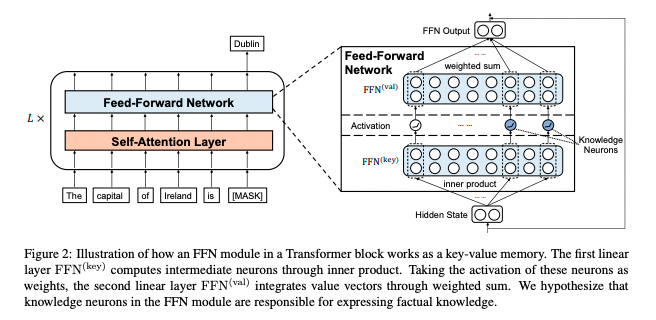
- feed-foward module as key-value memory
- self-attention의 formula와 feed-forward의 formula가 유사하다는 점에서 착안한 아이디어
- hidden states(input)를 쿼리 벡터, 첫번째 linear layer를 key, 두번째 linear layer를 메모리로 여김
- integrated gradients
- 만약 neuron이 사실의 표현에 큰 영향을 끼친다면, gradient가 두드러지며, large integration value를 가짐
- attribution score로 neuron이 factual knowledge에 기여하는 영향도를 측정할 수 있음
- attribution score가 threshold를 넘는 knowledge neuron의 집합을 구함
- refining strategy
- 다양한 propmt들 사이에서 널리 공유되는 knowledge neuron만을 유지
- false-positive neuron 필터링
의의
- open-the-black-box analysis
- 딥러닝의 뛰어난 성능에 대해 아직까진 그 이유를 충분히 설명할 수 없음 = black box
- 다양한 실험을 통해 knowledge neuron의 타당성 증명
- 1) knowledge neuron을 억누르거나(suppress) 확대하면(amplify) 이에 상응하는 지식의 표현에 영향을 미침
- 2) 잘 대응되는 지식을 표현하는 prompt 사용 시 knowledge neuron이 더 잘 활성화
- top-2 activating prompts express exactly the corresponding relational fact. e.g. for relational facts <Ireland, capital, Dublin>, top prompt is "Our trip ... in __, the capital and largest city of Ireland ... "
- 3) updating facts, erasing relations를 통해 다른 지식 예측에는 영향을 덜 미치면서도 지식의 수정 또한 가능하다는 점을 확인
- 대부분의 fact-related neuron들은 사전학습된 Transformer의 topmost layer에 분포
한계
- 정확한 fact editing은 future work로 남겨둠
- knowledge neuron을 fill-in-the-blank cloze task에 기반해 확인하였으나, 지식은 더욱 함축적이고 내재적인(implicit) 방식으로 표현될 수 있음 (reasoning 등에도 generalization이 가능할지)
- knowledge neurons 사이의 interaction에 대한 연구 부족
- single-word 기반으로 분석, 추후 multi-word extension 필요

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab