Guiding Generative Language Models for Data Augmentation in Few-Shot Text Classification
Guiding Generative Language Models for Data Augmentation in Few-Shot Text Classification
EMNLP 2022
분야 및 배경지식
Data Augmentation, Synthetic Data Generation
- Data Augmentation
- 데이터 증강 기법
- 클래스의 불균형과 데이터 희소성을 해결하기 위해 딥러닝에서 사용되는 기법
- label(정답)이 있는 기존의 데이터로부터 synthetic training sample을 추가로 생성
- DA methods
- Word replacement-based (WR)
- 단어를 바꿔 추가적인 데이터 생성 (Knowledge base, Language Model(LM) 사용)
- Sentence replacement-based (SR)
- 추가적인 문장을 생성 (back-translation 활용)
- Text Generation (TG)
- 주어진 seed sample을 활용하여 LM이 완전히 새로운 instance를 생성
- Word replacement-based (WR)
문제
- specialized domain(특화된 도메인)에서 few-shot setting의 텍스트 분류 문제를 해결하기 위해 generative language model을 사용하는 연구는 제한적
- few-shot setting이란, task를 풀기 위해 주어진 데이터의 수가 적은 경우를 의미
- seed selection strategy에 따른 augmented data의 텍스트 분류 성능 향상 비교 필요
- 어떤 샘플 데이터를 사용해 LM으로 synthetic data를 생성했을 때 가장 좋은 품질의 데이터를 만들 수 있을까?
해결책
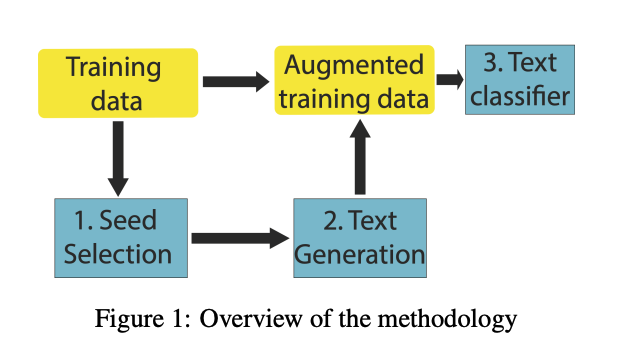
- 테스트 대상 모델
- GPT-2 model + finetune on the entire dataset
- GPT-2 model + finetune for each given class (label preservation 보장 위해)
- pretrained GPT-2 model
- Seed Selection Strategy (샘플 데이터 선택)
- random
- 무작위 선택
- maximum nouns-guided
- 명사가 최대한 많이 포함된 샘플 선택
- 도메인 특화 용어가 풍부하게 사용되었을 것이라 가정
- subclass-guided
- 사람이 만든 데이터셋의 분류 계층 이용 (human-generated classification hierarchy of a dataset)
- subclass마다 비슷한 수의 샘플 선택
- expert-guided
- 전문가가 class를 대표하는 샘플 선택
- random
평가
- Label preservation 중요
- 세 개의 모델 중 label 별로 finetuning된 GPT-2에서 성능이 가장 높았음
- 규모가 큰 unlabeled corpus에 대해 finetuning하는 것보다 작지만 labeled data에 파인튜닝하는 것이 성능 향상에 주효
- seed의 크기가 커질수록 random보다 seed selection이 유효
- seed 크기 작다면 random도 무방
- specialized domain의 경우, expert-guided가 가장 높은 성능
한계
- fastText Classifier라는 단순한 모델 사용
- 최근 많이 사용되는 모델은 Transformer-based model
- SOTA 성능을 달성하기 위해서가 아니라 generated output의 품질을 비교하는 것이 논문의 목적임을 밝히고 있음
- 실제 적용을 생각해봤을 때 text classification 성능 비교 또한 Transformer-based model에서 진행하는 것이 더욱 타당했을 것으로 보임
- seed selection에 대한 특별한 insight를 제공하지 않음
- 일반 도메인에서는 Expert guided seed selection을 진행하지 않았음
- specialized domain에서의 성능을 확인했을 때, 일반 도메인에서도 expert가 가장 좋은 성능을 낼 가능성 존재
- 그렇다면, 사람의 판단을 거치지 않은 좋은 seed selection이란 불가능한지 의문
- manual한 방식에서의 탈피 가능성 혹은 왜 expert-guided가 가장 좋은 품질을 보장하는 지에 대한 충분한 분석이 이루어지지 않음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab